MATLAB数组排序与时间序列分析:排序在时间序列分析中的作用
发布时间: 2024-06-16 05:13:47 阅读量: 7 订阅数: 18 
# 1. MATLAB数组排序基础**
MATLAB数组排序是时间序列分析中的一项基本操作,它可以帮助我们对数据进行排序、筛选和组织。MATLAB提供了多种排序算法,每种算法都有其独特的特性和适用场景。
**1.1 排序算法**
MATLAB中常用的排序算法包括:
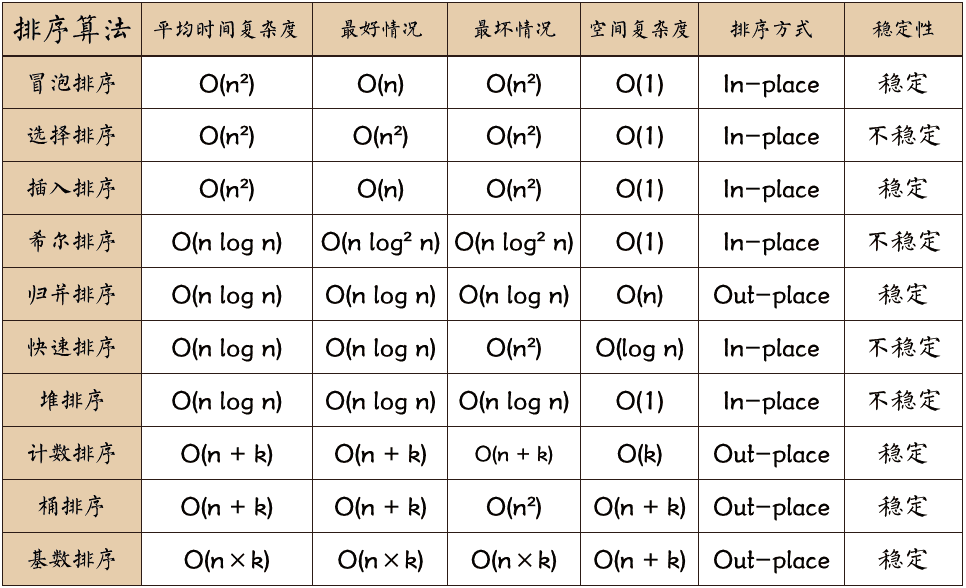
- **冒泡排序:**一种简单的排序算法,通过逐一对元素进行比较和交换来实现排序。
- **快速排序:**一种高效的排序算法,使用分治策略将数组划分为较小的子数组,然后递归地对子数组进行排序。
- **归并排序:**另一种高效的排序算法,使用分治策略将数组划分为较小的子数组,然后合并排序后的子数组。
# 2. 排序算法与时间序列分析
### 2.1 排序算法的种类和特性
排序算法是计算机科学中用于对数据进行排序的基本算法。在时间序列分析中,排序算法可以用于对时间序列数据进行预处理和特征提取。常用的排序算法包括:
#### 2.1.1 冒泡排序
冒泡排序是一种简单的排序算法,它通过逐一对相邻元素进行比较和交换,将较大的元素逐渐移到数组的末尾。冒泡排序的算法步骤如下:
```
for i = 1 to n-1
for j = 1 to n-i
if arr[j] > arr[j+1]
swap(arr[j], arr[j+1])
end
end
```
**参数说明:**
* arr:需要排序的数组
* n:数组的长度
**代码逻辑逐行解读:**
* 第一行:使用一个 for 循环遍历数组,从第一个元素开始,到倒数第二个元素结束。
* 第二行:使用一个嵌套的 for 循环遍历数组,从第一个元素开始,到当前外层循环的末尾元素结束。
* 第三行:比较当前元素 arr[j] 和相邻元素 arr[j+1] 的大小。
* 第四行:如果 arr[j] 大于 arr[j+1],则交换这两个元素的位置。
#### 2.1.2 快速排序
快速排序是一种高效的排序算法,它使用分治策略将数组划分为较小的子数组,然后递归地对这些子数组进行排序。快速排序的算法步骤如下:
```
function quickSort(arr, low, high)
if low < high
pivot = partition(arr, low, high)
quickSort(arr, low, pivot - 1)
quickSort(arr, pivot + 1, high)
end
end
function partition(arr, low, high)
pivot = arr[high]
i = low - 1
for j = low to high - 1
if arr[j] <= pivot
i++
swap(arr[i], arr[j])
end
end
swap(arr[i+1], arr[high])
return i + 1
end
```
**参数说明:**
* arr:需要排序的数组
* low:数组的起始索引
* high:数组的结束索引
**代码逻辑逐行解读:**
* 第一行:定义快速排序函数,它接收数组、起始索引和结束索引作为参数。
* 第二行:如果起始索引小于结束索引,则执行排序操作。
* 第三行:调用 partition 函数对数组进行划分,并返回划分后的基准元素索引。
* 第四行和第五行:递归地对基准元素左边的子数组和右边的子数组进行快速排序。
#### 2.1.3 归并排序
归并排序是一种稳定的排序算法,它通过将数组分成较小的子数组,然后合并这些子数组来进行排序。归并排序的算法步骤如下:
```
function mergeSort(arr, low, high)
if low < high
mid = (low + high) / 2
mergeSort(arr, low, mid)
mergeSort(arr, mid + 1, high)
merge(arr, low, mid, high)
end
end
function merge(arr, low, mid, high)
left = arr[low:mid]
right = arr[mid+1:high]
i = 1
j = 1
k = low
while i <= length(left) and j <= length(right)
if left[i] <= right[j]
arr[k] = left[i]
i++
else
arr[k] = right[j]
j++
end
k++
end
while i <= length(left)
arr[k] = left[i]
i++
k++
end
while j <= length(right)
arr[k] = right[j]
j++
k++
end
end
```
**参数说明:**
* arr:需要排序的数组
* low:数组的起始索引
* high:数组的结束索引
**代码逻辑逐行解读:**
* 第一行:定义归并排序函数,它接收数组、起始索引和结束索引作为参数。
* 第二行:如果起始索引小于结束索引,则执行排序操作。
* 第三行:计算数组的中间索引。
* 第四行和第五行:递归地对数组的左半部分和右半部分进行归并排序。
* 第六行:调用 merge 函数合并两个排序后的子数组。
# 3. MATLAB中的时间序列分析
### 3.1 时间序列数据的处理和可视化
#### 3.1.1 数据读取和预处理
MATLAB提供了多种函数来读取和预处理时间序列数据。最常用的函数是`load`和`importdata
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**专栏简介:**
本专栏深入探讨 MATLAB 数组排序的各个方面,从算法的内部机制到性能优化指南。它涵盖了广泛的主题,包括:
* 快速排序算法的奥秘
* 算法优缺点的性能优化
* 并行计算的排序新境界
* 满足复杂排序需求的自定义规则
* 数据可视化的直观排序结果
* 大数据处理的排序挑战
* 云计算和分布式计算的高效排序
* 优化算法的排序效率提升
* 人工智能、图像处理、信号处理和时间序列分析中的排序应用
* 财务建模、生物信息学、化学建模和材料科学中的排序应用
通过深入的分析和示例,本专栏旨在帮助读者掌握 MATLAB 数组排序的精髓,并利用其强大的功能来解决各种数据处理挑战。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘MySQL数据库性能下降幕后真凶:提升数据库性能的10个秘诀

# 1. MySQL数据库性能下降的幕后真凶
MySQL数据库性能下降的原因多种多样,需要进行深入分析才能找出幕后真凶。常见的原因包括:
- **硬件资源不足:**CPU、内存、存储等硬件资源不足会导致数据库响应速度变慢。
- **数据库设计不合理:**数据表结构、索引设计不当会影响查询效率。
- **SQL语句不优化:**复杂的SQL语句、
云计算架构设计与最佳实践:从单体到微服务,构建高可用、可扩展的云架构

# 1. 云计算架构演进:从单体到微服务
云计算架构经历了从单体到微服务的演进过程。单体架构将所有应用程序组件打
Python在Linux下的安装路径在数据科学中的应用:在数据科学项目中优化Python环境
# 1. Python在Linux下的安装路径
Python在Linux系统中的安装路径因不同的Linux发行版和Python版本而异。一般情况下,Python解释器和库的默认安装路径为:
- **/usr/bin/python**:Python解释器可执行文件
- **/usr/lib/python3.X**:Python库的安装路径(X为Py
【进阶篇】数据可视化优化:Seaborn中的样式设置与调整

# 2.1 Seaborn的默认样式
Seaborn提供了多种默认样式,这些样式预先定义了图表的外观和感觉。默认样式包括:
- **darkgrid**:深色背景和网格线
- **whitegrid**:白色背景和网格线
- **dark**:深色背景,无网格线
- **white**:白色背景,无网格线
- **ticks**:仅显示刻度线,无网格线或背景
这些默认样
Python连接PostgreSQL机器学习与数据科学应用:解锁数据价值

# 1. Python连接PostgreSQL简介**
Python是一种广泛使用的编程语言,它提供了连接PostgreSQL数据库的
Python类方法与静态方法在金融科技中的应用:深入探究,提升金融服务效率
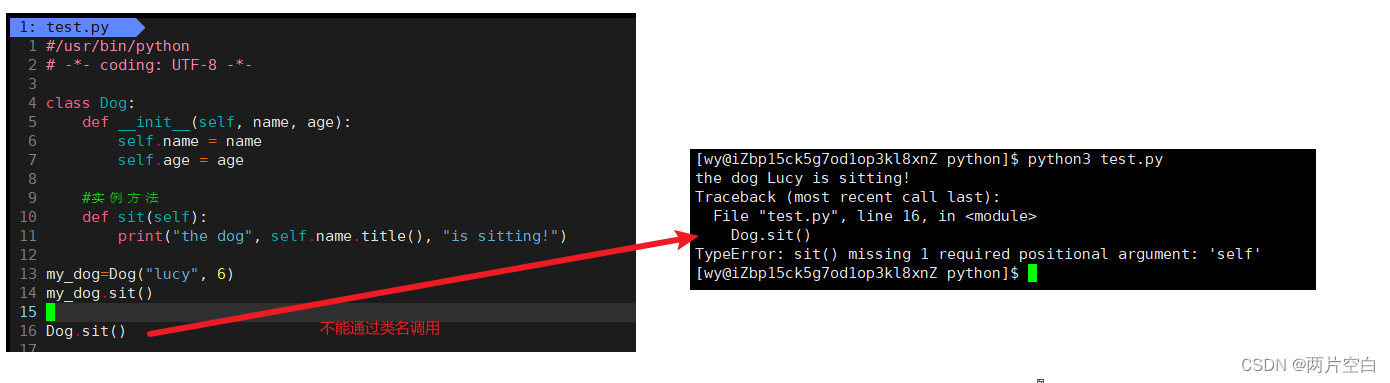
# 1. Python类方法与静态方法概述**
### 1.1 类方法与静态方法的概念和区别
在Python中,类方法和静态方法是两种特殊的方法类型,它们与传统的方法不同。类方法与类本身相关联,而静态方法与类或实例无关。
* **类方法:**类方法使用`@classmethod`装饰器,它允许访问类变量并修改类状态。类方法的第一个参数是`cls`,它代表类本身。
* **静态方法:**静态方法使用`@staticme
Python enumerate函数在医疗保健中的妙用:遍历患者数据,轻松实现医疗分析

# 1. Python enumerate函数概述**
enumerate函数是一个内置的Python函数,用于遍历序列(如列表、元组或字符串)中的元素,同时返回一个包含元素索引和元素本身的元组。该函数对于需要同时访问序列中的索引
实现松耦合Django信号与事件处理:应用程序逻辑大揭秘

# 1. Django信号与事件处理概述**
Django信号和事件是两个重要的机制,用于在Django应用程序中实现松散耦合和可扩展的事件处理。
**信号**是一种机制,允许在应用程序的各个部分之间发送和接收通知。当发生特定事件时,会触发信号,并调用注册的信号处理函数来响应该事件。
**事件**是一种机制,允许应用程序中的对象注册监听器,以在发生特定事件时执行操作。当触发事件时,会调用注册的事
Python连接MySQL数据库:区块链技术的数据库影响,探索去中心化数据库的未来

# 1. 区块链技术与数据库的交汇
区块链技术和数据库是两个截然不同的领域,但它们在数据管理和处理方面具有惊人的相似之处。区块链是一个分布式账本,记录交易并以安全且不可篡改的方式存储。数据库是组织和存储数据的结构化集合。
区块链和数据库的交汇点在于它们都涉及数据管理和处理。区块链提供了一个安全且透明的方式来记录和跟踪交易,而数据库提供了一个高效且可扩展的方式来存储和管理数据。这两种技术的结合可以为数据管
【实战演练】数据聚类实践:使用K均值算法进行用户分群分析
# 1. 数据聚类概述**
数据聚类是一种无监督机器学习技术,它将数据点分组到具有相似特征的组中。聚类算法通过识别数据中的模式和相似性来工作,从而将数据点分配到不同的组(称为簇)。
聚类有许多应用,包括:
- 用户分群分析:将用户划分为具有相似行为和特征的不同组。
- 市场细分:识别具有不同需求和偏好的客户群体。
- 异常检测:识别与其他数据点明显不同的数据点。
# 2
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )