




Mybatis+Geneater深度解析:掌握10个核心功能与使用技巧,让开发效率飞跃提升

摘要
本文旨在介绍Mybatis+Geneater的使用方法和核心功能,涵盖了从入门基础知识到高级特性及性能优化的全面讲解。首先,介绍了Mybatis+Geneater的入门知识和基础概念,随后深入解析了核心配置文件和SQL映射文件,以及插件和拦截器的使用。接着,文章详细探讨了Mybatis+Geneater的核心功能,包括缓存机制、事务管理和连接池配置、延迟加载与批量操作等。高级特性部分讲解了动态SQL的应用、复杂映射关系处理和框架集成与扩展。最后,通过实战案例与性能优化策略,提供了企业级应用的具体实施和问题解决技巧。本文不仅适合初学者了解Mybatis+Geneater的使用,也为经验丰富的开发者提供了深入探讨和性能调优的宝贵信息。
关键字
Mybatis+Geneater;核心配置;SQL映射;缓存机制;事务管理;性能优化
参考资源链接:MyBatis Generator官方中文文档详解与XML配置
1. Mybatis+Geneater入门与基础概念
1.1 Mybatis+Geneater概述
Mybatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。Geneater 则是一个 Mybatis 代码生成工具,可以快速帮助开发者生成基本的 CRUD 操作代码,极大地提高了开发效率。两者的结合可以简化数据库操作和数据访问层的代码编写。
1.2 关键概念和功能
Mybatis 通过使用简单的 XML 或注解用于配置和原始映射,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java 对象)映射成数据库中的记录。Geneater 则是基于 Mybatis 提供的动态生成代码的功能,它能够生成实体类、DAO 接口以及映射文件,从而让开发者专注于业务逻辑的实现。
1.3 入门指南和环境搭建
要开始使用 Mybatis 和 Geneater,首先需要搭建开发环境:
- 下载并配置 Mybatis 和 Geneater。
- 在项目中配置 Mybatis 全局配置文件
mybatis-config.xml。 - 通过 Geneater 生成代码,需要指定数据库连接信息、表名和包名等配置。
- 根据生成的代码调整和实现业务逻辑。

通过以上步骤,可以快速开始使用 Mybatis 和 Geneater,进行数据库交互操作。
2. 核心配置文件与SQL映射深入解析
2.1 Mybatis全局配置详解
2.1.1 配置文件结构
Mybatis的全局配置文件是Mybatis应用的核心,它决定了Mybatis的行为方式。全局配置文件通常由以下几个部分组成:
<configuration>:配置文件的根元素。<properties>:用于加载外部配置文件或定义常量。<settings>:用于配置Mybatis的各种行为。<typeAliases>:用于定义类的别名,简化类的引用。<typeHandlers>:用于定制如何映射Java类型和数据库类型。<objectFactory>:用于创建对象实例。<plugins>:用于定义插件,可以自定义拦截行为。<environments>:配置数据库连接环境,可以配置多个。<databaseIdProvider>:用于配置数据库厂商标识。<mappers>:用于映射接口和映射文件。
例如,一个典型的mybatis-config.xml文件可能如下所示:
2.1.2 核心设置解析
在Mybatis的全局配置文件中,<settings>标签内的配置项是调整Mybatis运行行为的关键。
logImpl:日志输出组件,可选的有STDOUT_LOGGING,SLF4J,LOG4J等,用于输出Mybatis运行时的日志。mapUnderscoreToCamelCase:是否开启自动将数据库列名的下划线转换为驼峰命名,适用于列名与Java属性名不匹配的情况。cacheEnabled:是否开启全局缓存,默认为true。localCacheScope:本地缓存的作用域,有SESSION和STATEMENT两种。jdbcTypeForNull:当列的值为NULL时,数据库驱动的JDBC类型。
每个设置项的具体配置都有其含义和适用场景,开发者需要根据实际需求进行调整,以便更好地控制Mybatis的运行时行为。
2.2 SQL映射文件解析
2.2.1 映射文件基础
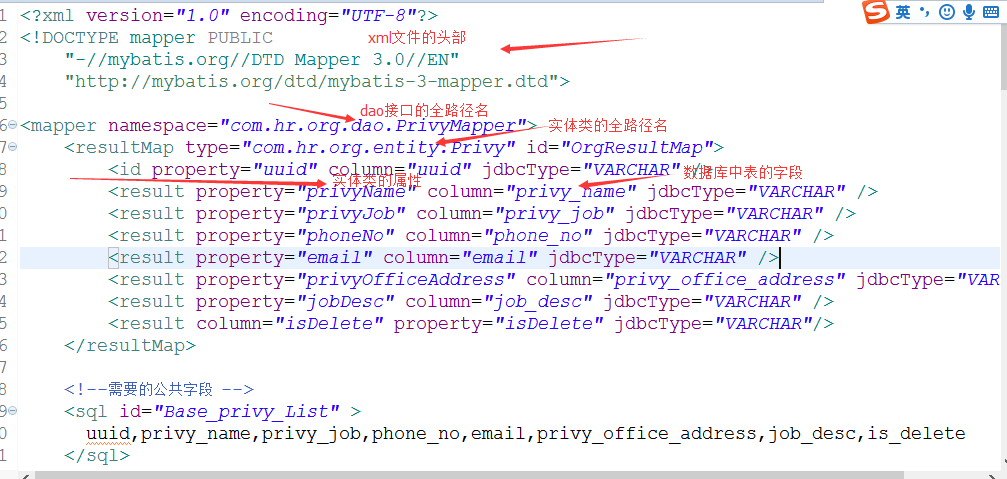
SQL映射文件是Mybatis中定义SQL语句及映射规则的重要部分。一个映射文件通常对应一个DAO接口,文件内容主要包含以下几个部分:
<mapper>:映射文件的根元素,通常需要指定namespace属性,其值为对应的DAO接口的全限定类名。<select>、<insert>、<update>、<delete>:用于定义CRUD操作对应的SQL语句。<resultMap>:用于定义结果映射规则。<parameterMap>:用于定义输入参数的映射规则,已被<parameter>元素替代。
例如,一个简单的UserMapper.xml映射文件可能如下所示:
- <mapper namespace="com.example.dao.UserDao">
- <select id="selectUser" resultType="com.example.model.User">
- SELECT * FROM users WHERE id = #{id}
- </select>
- </mapper>
2.2.2 动态SQL的应用
动态SQL是Mybatis非常强大的特性之一,它允许在SQL语句中加入条件判断和循环等逻辑,从而实现复杂查询条件的灵活构建。
Mybatis提供了多种动态SQL元素,如<if>, <choose>, <when>, <otherwise>, <where>, <set>, <foreach>等。
例如,一个带有动态条件的<select>查询可能如下所示:
- <select id="selectUsers" resultType="com.example.model.User">
- SELECT * FROM users
- <where>
- <if test="name != null">
- AND name = #{name}
- </if>
- <if test="age != null">
- AND age = #{age}
- </if>
- </where>
- </select>
在这个例子中,<where>标签会智能地根据<if>条件的存在与否,动态地构建查询条件。
2.3 插件与拦截器的使用
2.3.1 自定义插件的编写与应用
Mybatis的插件是运行时拦截器的高级特性,可以拦截Mybatis四个核心对象的执行方法:Executor、StatementHandler、ParameterHandler和ResultSetHandler。通过编写自定义插件,开发者可以实现诸如性能监控、SQL审计等高级功能。
一个简单的自定义插件实现可能如下所示:
要使用自定义插件,需要在全局配置文件中注册:
- <plugins>
- <plugin interceptor="com.example.plugin.CustomPlugin"/>
- </plugins>
2.3.2 拦截器在SQL优化中的角色
拦截器是Mybatis中进行SQL优化的一个重要工具。通过拦截器,可以动态地调整SQL语句,实现查询优化、性能监控、日志记录等。
例如,一个拦截器用于监控Mybatis执行的SQL语句的执行时间:
- public class PerformanceInterceptor implements Interceptor {
- @Override
- public Object intercept(Invocation invocation) throws Throwable {
- long start = System.currentTimeMillis();
- try {
- return invocation.proceed();
- } finally {
- long time = System.currentTimeMillis() - start;
- // 输出日志记录SQL执行时间
- System.out.println("Time: " + time);
- }
- }
- }
通过这种方式,开发者可以对执行时间过长的SQL语句进行性能分析和调优,从而优化整体应用性能。
3. ```
第三章:Mybatis+Geneater核心功能详解
3.1 缓存机制与优化
3.1.1 一级缓存与二级缓存机制
Mybatis 提供了两级缓存机制:一级缓存和二级缓存。一级缓存是基于 SqlSession 的,也就是说,同一个 SqlSession 中的查询,会首先从一级缓存中找,如果找到了,直接返回。一级缓存只在 SqlSession 范围内有效,一旦 SqlSession 被关闭,一级缓存的数据也就不存在了。一级缓存的生命周期非常短,但也正是由于生命周期短,所以它的作用范围也比较局限。
二级缓存则是基于 Mapper 的,它可以跨越多个 SqlSession。当配置了二级缓存后,查询的数据会被存储在二级缓存中,可以被同一个 Mapper 的多个 SqlSession 共享。开启二级缓存的步骤如下:
- 在 Mybatis 的全局配置文件中设置
<setting name="cacheEnabled" value="true"/>以启用二级缓存。 - 在 Mapper 配置文件中设置
<cache eviction="LRU" flushInterval="60000" size="512" readOnly="true"/>来配置二级缓存。 - 在需要进行二级缓存操作的 Mapper 接口中,需要标注
@CacheNamespace注解。
需要注意的是,二级缓存的作用范围比一级缓存广泛,但是它并不是在所有情况下都是有效的。只有当数据不经常变化,并且查询操作频繁时,使用二级缓存才能获得较好的性能提升。
3.1.2 缓存策略的选择与应用
Mybatis 缓存策略的配置是通过 cache 元素进行的,可以设置多种属性,如缓存回收策略、刷新间隔、缓存大小和是否只读等。在实践中,开发者需要根据实际业务场景选择合适的缓存策略。比如,LRU(最近最少使用)策略适用于缓存内容较多时,能够快速淘汰掉最长时间未被访问的数据;而 FIFO(先进先出)策略适用于缓存数据访问频率较为均匀的场景。
在实际应用中,开发者可以通过如下方式调整缓存配置:
- <cache
- eviction="LRU"
- flushInterval="60000"
- size="512"
- readOnly="true"/>
这里,eviction 指定了缓存的回收策略,flushInterval 设置了缓存自动刷新的时间间隔,size 为缓存区设置了大小,readOnly 设置为 true 表示缓存返回的是只读对象。
理解了这些策略,开发者就能根据应用场景和性能要求,选择适合的缓存策略并进行配置。在性能要求较高的场景下,合理配置缓存策略可以有效提高数据访问速度,减轻数据库压力。
3.2 事务管理与连接池配置
3.2.1 事务隔离级别
事务隔离级别是指在数据库事务中,为了避免数据不一致等问题,对并发操作设置的隔离程度。Mybatis 遵循 JDBC 的事务隔离机制,有以下四种隔离级别:
- READ_UNCOMMITTED(读未提交):最低的隔离级别,允许读取尚未提交的数据变更,可能导致脏读、不可重复读和幻读。
- READ_COMMITTED(读已提交):允许读取并发事务已经提交的数据,可以避免脏读,但不可重复读和幻读仍然可能发生。
- REPEATABLE_READ(可重复读):对同一字段的多次读取结果都是一致的,除非数据是被本事务自己所修改,可以避免脏读和不可重复读,但幻读可能发生。
- SERIALIZABLE(可串行化):最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。
在 Mybatis 中,可以通过设置 JDBC 连接属性 TransactionIsolation 来指定事务的隔离级别:
- Connection conn = dataSource.getConnection();
- conn.setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE);
3.2.2 连接池的配置与调优
连接池是数据库连接管理的一种机制,通过维护一定数量的数据库连接,并将它们提供给应用程序使用,可以避免频繁地打开和关闭数据库连接带来的性能损耗。
Mybatis 通过与第三方库(如 HikariCP、Apache DBCP)集成,支持连接池的配置。以下是使用 HikariCP 连接池的一个示例配置:
- <dataSource type="POOLED">
- <property name="driver" value="com.mysql.jdbc.Driver"/>
- <property name="url" value="jdbc:mysql://localhost:3306/mydatabase"/>
- <property name="username" value="root"/>
- <property name="password" value="password"/>
- <!-- HikariCP specific settings -->
- <property name="poolName" value="HikariCP"/>
- <property name="maximumPoolSize" value="10"/>
- <property name="autoCommit" value="false"/>
- <property name="connectionTestQuery" value="SELECT 1"/>
- </dataSource>
其中,maximumPoolSize 决定了池内最多可以保留多少个连接,autoCommit 设置了是否开启自动提交,而 connectionTestQuery 是用来检测连接是否有效的 SQL 语句。
在实践中,开发者需要根据实际的应用负载和资源消耗情况对连接池进行调优,例如增加连接池的大小以应对高并发访问,或者调整连接的生命周期以减少资源消耗。为了实现这一点,可使用监控工具来观察连接池的状态,并根据监控结果逐步调整配置参数,直到找到最佳平衡点。
3.3 延迟加载与批量操作
3.3.1 延迟加载的原理及应用场景
延迟加载(Lazy Loading)是指在需要的时候才加载数据,而不是在执行 SQL 语句的时候一次性加载所有相关数据。延迟加载可以减少应用的数据加载量和内存消耗,提高应用程序的性能。Mybatis 支持延迟加载,通常与 association 和 collection 配合使用。
延迟加载的原理是在初次查询时并不直接返回关联对象的数据,而是在访问关联对象的属性时,通过代理机制触发额外的 SQL 查询以加载数据。延迟加载的配置是通过 Mybatis 的全局配置文件或者 Mapper XML 文件的 <setting> 元素来完成的。
- <setting name="lazyLoadingEnabled" value="true"/>
- <setting name="aggressiveLazyLoading" value="false"/>
其中,lazyLoadingEnabled 用于开启或关闭延迟加载;aggressiveLazyLoading 控制是否对所有的延迟加载属性进行预加载。
在实际应用中,延迟加载主要适用于一对多、多对多的关系,如用户和订单的关系。只有在真正访问用户所拥有的订单信息时,才会执行加载订单数据的 SQL 语句,这样可以减少数据库的访问次数和网络传输的数据量。
3.3.2 批量操作的策略与性能优化
批量操作是数据库操作中常见的一种优化手段,它可以减少单个数据项操作的次数,提升整体的处理速度。在 Mybatis 中,批量操作主要涉及到批量插入、更新和删除。
实现批量操作通常有以下几种策略:
- 使用
foreach循环构造批量 SQL 语句; - 使用数据库原生的批量操作功能,比如 MySQL 的
INSERT INTO ... SELECT; - 使用 Mybatis 的
SqlSession的flushStatements()方法强制执行剩余的语句。
下面是一个批量插入的例子:
- <insert id="insertList" parameterType="java.util.List">
- INSERT INTO table_name (column1, column2, ...)
- VALUES
- <foreach collection="list" item="item" index="index" separator=",">
- (#{item.field1}, #{item.field2}, ...)
- </foreach>
- </insert>
使用批量操作时,需要注意以下几点:
- 批量操作可以减少网络往返次数,但同时也会增加单次操作的数据量,导致单次操作的延迟增加;
- 在内存和网络带宽允许的情况下,适当增加批量操作的数据量可以提高效率;
- 某些数据库对批量操作有最大数据量的限制,需要在实际操作中根据具体的数据库平台进行调整。
通过合理地使用批量操作和策略,开发者可以有效地提升数据库操作的性能,减轻系统负载。
上述例子中,state 字段默认会包含在查询条件中。如果title参数被提供,它会被用在LIKE查询中。另外,如果author对象及其name属性被提供,作者的名称也会被包含在查询中。<where>标签确保了当<if>条件都不满足时,不会生成一个带有AND关键字的无效查询。
4.1.2 foreach循环的巧妙运用
<foreach>标签在处理批量操作时非常有用。它可以帮助动态构建IN条件,或者用于拼接SQL中的集合元素。<foreach>标签通常用在SQL语句中进行集合的遍历,比如批量删除或插入记录。
一个使用<foreach>的批量删除例子如下:
- <delete id="deleteByIds" parameterType="list">
- DELETE FROM BLOG WHERE id IN
- <foreach item="id" collection="list" open="(" separator="," close=")">
- #{id}
- </foreach>
- </delete>
在上述的<foreach>标签中,collection指定了传入参数的类型,item是遍历出来的单个元素的别名,open和close定义了遍历的开始和结束字符,而separator定义了元素之间的分隔符。这样,当传入一个ID列表时,<foreach>标签会将其转换为适合的IN子句的形式。
4.2 复杂映射与一对一、一对多关系处理
4.2.1 复杂映射的技术实现
在处理复杂的数据结构时,Mybatis的映射技术能够将数据库表中存储的复杂数据结构映射到Java对象中。这种映射可以是嵌套结果映射,也可以是多结果集映射。嵌套结果映射通常用<resultMap>来定义,其中可以包括<association>和<collection>元素来处理一对一和一对多的关系。
下面是一个使用<resultMap>进行嵌套查询的实例:
- <resultMap id="blogResult" type="Blog">
- <id property="id" column="blog_id" />
- <result property="title" column="blog_title" />
- <collection property="posts" ofType="Post">
- <id property="id" column="post_id" />
- <result property="subject" column="post_subject" />
- </collection>
- </resultMap>
在这个例子中,Blog对象包含一个Post集合属性。<resultMap>定义了如何从查询结果中提取这些信息,并组装成Java对象。
4.2.2 一对一与一对多关系映射策略
处理一对一和一对多关系的关键在于理解如何在映射文件中配置<association>和<collection>元素。一对一关系通常使用<association>标签来处理,它可以将单个相关对象映射到属性上。而一对多关系则使用<collection>标签,它适合将多个相关对象映射到属性上。
一对一映射的示例如下:
- <resultMap id="authorMap" type="Author">
- <id property="id" column="author_id" />
- <result property="firstName" column="first_name" />
- <result property="lastName" column="last_name" />
- <association property="book" column="book_id" javaType="Book" select="selectBookForAuthor"/>
- </resultMap>
- <select id="selectAuthor" resultMap="authorMap">
- SELECT * FROM author WHERE id = #{id}
- </select>
- <select id="selectBookForAuthor" resultType="Book">
- SELECT * FROM book WHERE author_id = #{id}
- </select>
在上面的例子中,我们定义了一个名为authorMap的<resultMap>,其中包含了一个<association>,它通过select属性指定了一个查询来获取与当前作者相关联的书籍信息。
一对多映射的示例如下:
- <resultMap id="authorMap" type="Author">
- <id property="id" column="author_id" />
- <result property="firstName" column="first_name" />
- <result property="lastName" column="last_name" />
- <collection property="books" ofType="Book" select="selectBooksForAuthor"/>
- </resultMap>
- <select id="selectAuthor" resultMap="authorMap">
- SELECT * FROM author WHERE id = #{id}
- </select>
- <select id="selectBooksForAuthor" resultType="Book">
- SELECT * FROM book WHERE author_id = #{author_id}
- </select>
在这个例子中,<collection>标签用于映射作者与书籍的一对多关系。每当查询一个作者时,会通过指定的查询方法selectBooksForAuthor获取其所有书籍。
4.3 Mybatis+Geneater的集成与扩展
4.3.1 与其他框架的集成
Mybatis具有良好的集成性,能够与各种Java框架配合使用,例如Spring、Spring Boot等。集成的主要目的是简化配置并利用框架提供的其他功能,如事务管理、依赖注入等。
集成Mybatis到Spring框架通常涉及以下几个步骤:
- 在Spring配置文件中添加Mybatis的SqlSessionFactoryBean。
- 配置数据源DataSource。
- 指定Mybatis配置文件的位置。
- 扫描Mapper接口,将它们注册到Spring容器中。
Spring Boot为这种集成提供了更为便捷的方式。在Spring Boot应用中,通常只需要添加Mybatis的起步依赖和相关配置即可。
4.3.2 自定义TypeHandler与ResultMap扩展
Mybatis允许开发者自定义TypeHandler和ResultMap来扩展其核心功能,以满足特定的数据类型映射需求。
创建自定义TypeHandler可以按照以下步骤:
- 创建实现了
TypeHandler接口的类。 - 在
TypeHandler类中,覆盖setParameter和getResult方法。 - 在
Mybatis配置文件中注册自定义TypeHandler。
例如,如果需要自定义一个枚举类型与数据库整型值的映射,可以创建如下TypeHandler:
在Mybatis配置文件中,需要指定使用该TypeHandler:
- <typeHandlers>
- <typeHandler handler="com.example.GenderTypeHandler" javaType="com.example.GenderEnum"/>
- </typeHandlers>
通过自定义TypeHandler,开发者可以灵活地处理不同类型的数据转换。同样,ResultMap也可以通过定义复杂的映射关系来扩展Mybatis的功能,这包括一对一、一对多关系的处理,以及复杂类型的嵌套映射。
5. Mybatis+Geneater实战案例与性能优化
5.1 实战案例分析
5.1.1 企业级应用案例
在介绍Mybatis+Geneater的实战案例时,我们先来看一个企业级的应用场景。假设我们正在开发一个电商后台管理系统,涉及到商品信息的增删改查。为了适应快速迭代和业务变化,我们可能会使用Mybatis+Geneater来构建数据访问层。
在这个案例中,首先需要定义商品信息的实体类Product,然后创建对应的Mapper接口ProductMapper和Mybatis的XML映射文件ProductMapper.xml。在映射文件中,我们会定义一系列的CRUD操作以及相关的动态SQL来满足业务需求。比如,我们可能会有按名称、分类或者价格区间检索商品的功能。这时候,foreach和if语句就显得尤为重要。
在实际部署时,我们还需要对数据库连接池进行配置,确保在高并发的情况下,数据库连接依然能够高效地进行管理和分配。
5.1.2 常见问题解决技巧
在开发过程中,我们难免会遇到一些常见问题,下面列举了一些解决方案:
- 慢查询优化: 有时候SQL查询可能因为缺少索引或复杂的查询逻辑导致性能低下。使用
explain命令分析执行计划,根据返回的信息添加必要的索引,简化查询逻辑。 - 缓存失效问题: 当系统中存在大量更新操作时,可能会导致缓存频繁失效。采用合适的缓存策略和合理的过期时间,可以减少缓存失效的情况。
- 并发事务问题: 高并发下的事务隔离级别设置不当可能会导致脏读、不可重复读等问题。通过适当调整事务隔离级别,例如设置为
REPEATABLE_READ,可以避免这些问题。 - 批量操作的内存溢出: 在处理大量数据的批量插入或更新时,可能会出现内存溢出。合理控制每次批量操作的数据量,优化SQL语句,或使用分批处理等策略。
5.2 性能优化策略
5.2.1 SQL优化与索引应用
SQL性能优化是提高数据库响应速度的关键步骤。以下是一些常见的SQL优化策略:
- 索引优化: 根据查询条件的使用频率和数据分布,合理创建索引。例如,对经常用于查询条件的字段创建索引,以加快查询速度。
- 查询改写: 通过重写SQL语句减少不必要的全表扫描,例如使用
exists代替in。 - 连接查询优化: 使用内连接而非全外连接,减少不必要的数据检索。
- 使用合适的函数: 避免在索引字段上使用函数,这会导致索引失效。
例如,为了优化之前商品查询的性能,可以在名称字段上创建索引:
- CREATE INDEX idx_product_name ON products(name);
5.2.2 系统优化与监控工具使用
系统性能优化不仅包括数据库层面的优化,还涉及应用服务器、缓存服务器等的优化。这些优化通常包括但不限于:
- 服务器硬件升级: 升级CPU、内存、磁盘等硬件设备,提高处理能力。
- 应用代码优化: 优化业务逻辑代码,减少不必要的数据库访问。
- 监控工具的应用: 使用像Prometheus、Grafana、Zabbix等监控工具实时监控应用性能,及时发现瓶颈。
例如,可以使用mybatis-plus提供的监控功能,获取SQL执行情况,并进行相应的分析和优化:
- // 在Spring Boot应用中配置MybatisPlusInterceptor监控插件
- @Configuration
- public class MybatisPlusConfig {
- @Bean
- public MybatisPlusInterceptor mybatisPlusInterceptor() {
- MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
- interceptor.addInnerInterceptor(new PerformanceInterceptor());
- return interceptor;
- }
- }
通过监控工具,我们可以清晰地看到哪些SQL语句执行时间过长,哪些接口访问频繁,从而针对性地进行优化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【3D IC互连技术:打破极限】:EDA工具的革新应用
【FPM383C_FPM383F自定义命令开发】:打造个性化指纹解决方案
掌握Zynq-7000 SoC双核架构:软件性能优化的终极武器
【云开发缓存策略】:提升小程序访问速度的数据缓存技术大揭秘!
U-Boot SPI通信协议:原理解析与实现(权威指南)
【功能增强秘籍】:PPT计时器Timer1.2扩展功能的实现
【航空领域的革命】:空气动力学的实践应用与未来趋势
跨平台部署无压力:组态王日历控件的解决方案
鸿蒙系统版网易云音乐国际化战略:多语言与本地化挑战应对之道
【运营流程优化】:HIS工作流管理的核心策略


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















