GS+数据挖掘技巧:如何从大数据中提取宝贵知识
发布时间: 2024-12-15 17:57:19 阅读量: 1 订阅数: 3 

GS+Win10.zip

参考资源链接:[GS+软件入门教程:地统计学分析详解](https://wenku.csdn.net/doc/5x96ur27gx?spm=1055.2635.3001.10343)
# 1. 数据挖掘概述与应用场景
数据挖掘是一项从大量数据中通过算法搜索隐藏信息的过程,它能够帮助人们发现数据背后的重要模式或趋势,为决策提供支持。随着信息技术的飞速发展,数据挖掘技术已被广泛应用于零售、金融、医疗、互联网等多个领域。
在零售行业中,数据挖掘可帮助企业分析顾客购买行为,从而优化库存管理和精准营销策略。在金融领域,通过挖掘历史交易数据,可以预测市场趋势或识别潜在的欺诈行为。在医疗领域,数据挖掘有助于分析病人健康记录,从而提供个性化治疗方案。
本章将探讨数据挖掘的基本概念,以及它如何在不同行业发挥其独特的作用。我们将通过实例来阐述数据挖掘的应用场景,以期让读者对数据挖掘的价值有一个全面而直观的认识。
# 2. 数据预处理与探索性数据分析
## 2.1 数据清洗
数据清洗是数据挖掘过程中不可或缺的一环,涉及到发现并纠正数据集中的错误或不一致,从而提高数据的质量。良好的数据清洗流程可以显著提升后续分析的准确性和可靠性。
### 2.1.1 缺失值的处理
缺失值是数据集中常见的问题,它指的是数据集中的某些记录值未被记录或获取。处理缺失值的方法有很多,主要分为删除记录、数据插补、估算等。
#### 删除记录
删除包含缺失值的记录是一种简单但有时过于激进的处理方法。当缺失值占数据集比例不大时,直接删除缺失值所在的行,可以防止对分析结果造成较大影响。
```python
import pandas as pd
# 假设df为我们的数据集
# 删除含有缺失值的行
df_cleaned = df.dropna()
```
#### 数据插补
数据插补是用某种特定的值或统计方法来填充缺失值。它包括平均数插补、中位数插补和众数插补等。
```python
# 使用列的平均值进行插补
df_filled = df.fillna(df.mean())
```
### 2.1.2 异常值的检测与处理
异常值是指在数据集中与其他数据行为不一致的点,可能是由于错误或罕见事件引起的。异常值的检测可以使用标准差、IQR(四分位距)等方法。
#### IQR方法
四分位距(IQR)是指第一四分位数(Q1)与第三四分位数(Q3)之间的差值。通常定义异常值为小于Q1-1.5*IQR或者大于Q3+1.5*IQR的值。
```python
Q1 = df.quantile(0.25)
Q3 = df.quantile(0.75)
IQR = Q3 - Q1
# 找到异常值
outliers = df[~((df >= (Q1 - 1.5 * IQR)) & (df <= (Q3 + 1.5 * IQR))).all(axis=1)]
```
处理异常值可以包括删除、修正或进行异常值标记。
## 2.2 数据转换
数据转换的目的是将原始数据转换为适合进行数据挖掘的形式。这一阶段的关键在于数据的标准化和编码。
### 2.2.1 数据标准化和归一化
标准化和归一化是调整数值特征尺度的方法,使它们具有可比性。标准化通常指将数据转化为均值为0,标准差为1的分布。归一化是指将数据调整到一定范围,通常是0到1之间。
```python
from sklearn.preprocessing import StandardScaler, MinMaxScaler
# 标准化
scaler_standard = StandardScaler()
df_standardized = scaler_standard.fit_transform(df)
# 归一化
scaler_minmax = MinMaxScaler()
df_normalized = scaler_minmax.fit_transform(df)
```
### 2.2.2 编码方法:独热编码、标签编码
在数据挖掘中,非数值型数据需要转换为数值型数据,以便用于大多数算法模型。独热编码和标签编码是常见的转换方法。
#### 独热编码
独热编码(One-Hot Encoding)适用于分类变量,它将每个类别值转换为一个新的二进制列,与原变量无关。
```python
from sklearn.preprocessing import OneHotEncoder
# 假设有一个分类变量 'category'
encoder = OneHotEncoder(sparse=False)
category_encoded = encoder.fit_transform(df[['category']])
```
#### 标签编码
标签编码(Label Encoding)将每个类别值映射为一个整数。
```python
from sklearn.preprocessing import La
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【USB2.0数据传输加速】:从原理到应用的深度剖析

参考资源链接:[USB2.0协议中文详解:结构、数据流与电气规范](https://wenku.csdn.net/doc/2mpprnjccu?spm=1055.2635.3001.10343)
# 1. USB2.0技术概述
USB2.0作为一项广泛应
【短信服务用户行为分析】:用数据驱动的策略优化营销
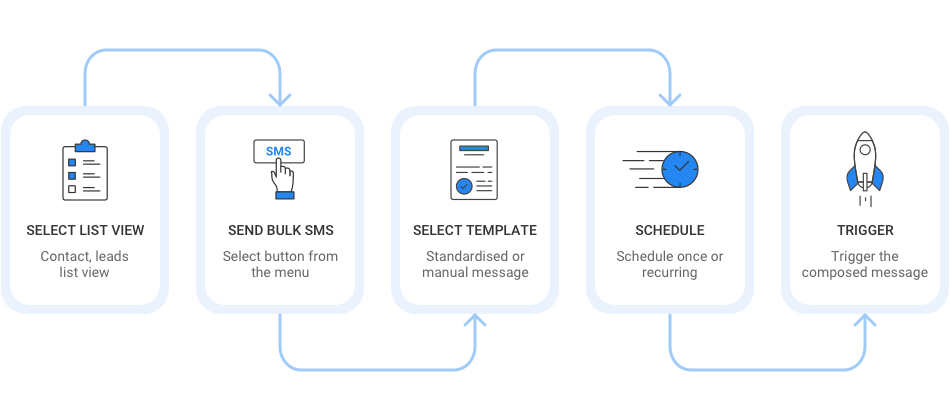
参考资源链接:[SMS网格生成实战教程:岸线处理与ADCIRC边界调整](https://wenku.csdn.net/doc/566peujjyr?spm=1055.2635.3001.10343)
# 1. 短信服务用户行为分析概述
在当今信息爆炸的时代,短信作为快速直达的通信方式,在营销中占据着举足轻重的地位。**用户行为分析**对于
HyperMesh网格质量优化:从入门到进阶的实用技巧
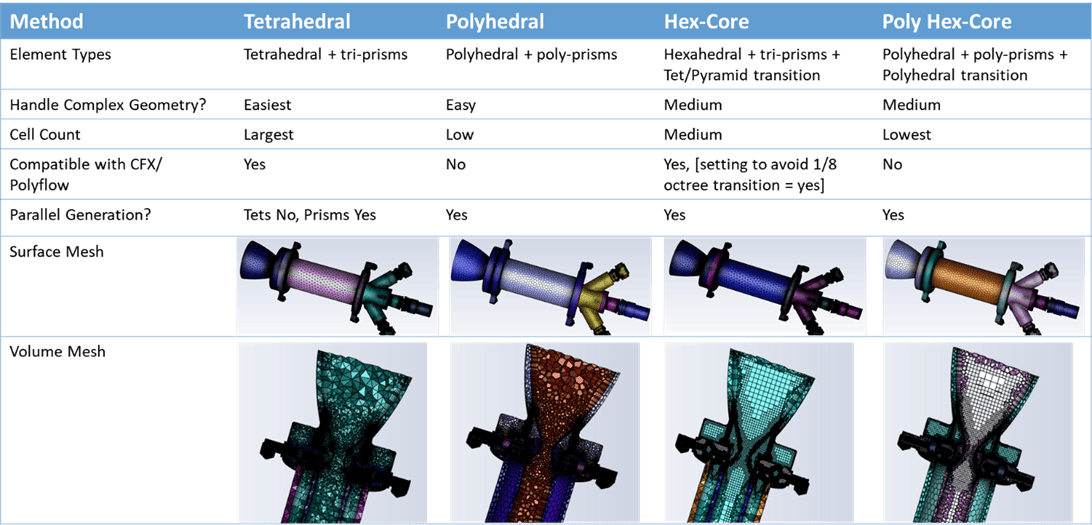
参考资源链接:[Hypermesh网格划分教程:从几何建模到3D网格生成](https://wenku.csdn.net/doc/1feyo6tkwb?spm=1055.2635.3001.10343)
# 1. HyperMesh网格质量优化概述
在本章中,我们将对HyperMesh的网格质量优化进行初步的介绍。HyperMesh是一款强大的有限元
零停机迁移:VMware虚拟机迁移的高级技术与实践

参考资源链接:[VMware产品详解:Workstation、Server、GSX、ESX和Player对比](https://wenku.csdn.net/doc/6493fbba9aecc961cb34d21f?spm=1055.2635.3001.10343)
# 1. 虚拟化技术概述与零停机迁移的重要性
在当今IT行业,随着业务的快速发展和技术的不断演进,企业的数据中心面临着前所未有的
Marc基础操作教程:一步一个脚印
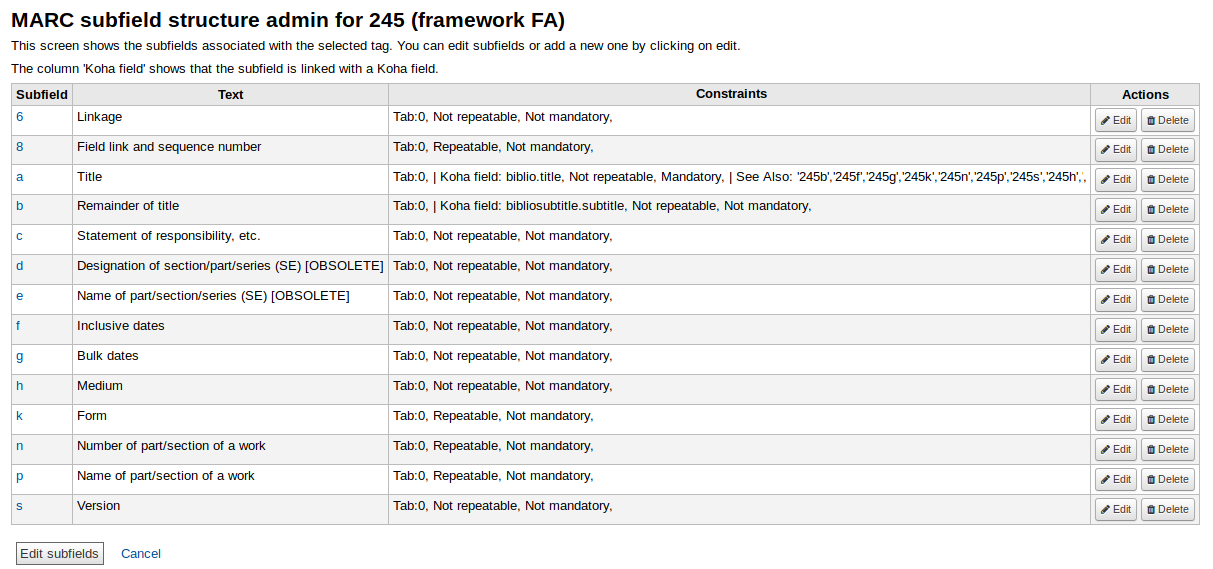
参考资源链接:[Marc中文版使用手册:强大的结构分析工具详解](https://wenku.csdn.net/doc/6401ad03cce7214c316edf98?spm=1055.2635.3001.10343)
# 1. Marc语言入门指南
## Marc语言简介
Marc语言是一种面向文本处理和数据操作的编程语言,它具有简洁的语法和强大的数据处理能力。入门Marc语言,首先需要了解它的基本特性和适用场景,这
量子化学基础与实践:从头算到密度泛函理论的Gaussian 16 B.01应用

参考资源链接:[Gaussian 16 B.01 用户指南:量子化学计算详解](https://wenku.csdn.net/doc/6412b761be7fbd1778d4a187?spm=1055.2635.3001.10343)
# 1. 量子化学的理论基础与历史发展
## 理论基础
量子化学作为化学与量子力学交叉的学科,提供了分子和原子尺度物质特性的理解。它的发展始于20世纪初,主要借助薛
【Excel转PDF终极秘籍】:一步实现文档格式转换的秘诀
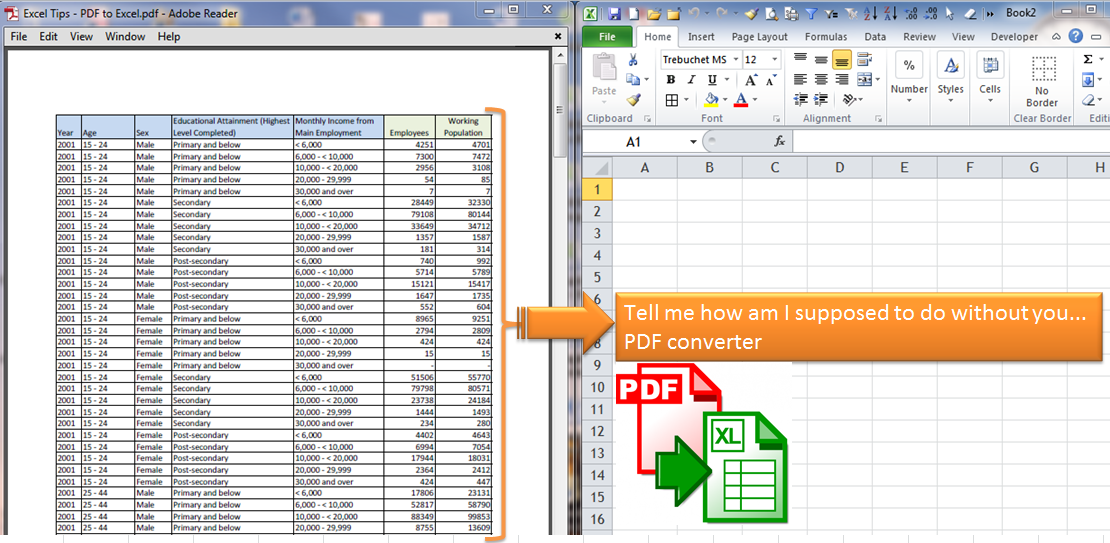
参考资源链接:[使用C#将Excel转换为PDF的方法](https://wenku.csdn.net/doc/2h17089otk?spm=1055.2635.3001.10343)
# 1. Excel转PDF概述
在数据报告和业务文档的处理中,Excel到PDF的转换是一个常见的需求。Excel,作为广泛使用的电子表
Vofa+ 1.3.10 x64 调试速查手册:快速定位安装问题的技巧
参考资源链接:[vofa+1.3.10_x64_安装包下载及介绍](https://wenku.csdn.net/doc/2pf2n715h7?spm=1055.2635.3001.10343)
# 1. Vofa+ 1.3.10 x64简介与安装问题概述
## 简介
Vofa+ 1.3.10 x64是一种先进的企
PSAT-2.0.0-ref故障排查与问题解决:遇到问题时的应对策略

参考资源链接:[PSAT 2.0.0 中文使用指南:从入门到精通](https://wenku.csdn.net/doc/6412b6c4be7fbd1778d47e5a?spm=1055.2635.3001.10343)
# 1. PSAT-2.0.0-ref概述及安装配置
## 1.1 PSAT-2.0.0-ref简介
PSA
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )