配置NFS自动挂载与自动共享
发布时间: 2024-03-07 22:24:32 阅读量: 46 订阅数: 33 
# 1. 概述NFS自动挂载与自动共享
NFS(Network File System)是一种分布式文件系统协议,允许远程计算机通过网络共享文件。自动挂载和自动共享是NFS中常见的需求,能够提高文件共享的便利性和效率。
## 什么是NFS
NFS是一种基于客户端-服务器模型的分布式文件系统协议,允许用户在不同的计算机系统之间共享文件和目录。通过NFS,用户可以像访问本地文件一样访问远程系统上的文件,实现文件共享和协作。
## 为什么需要自动挂载与自动共享
- **便利性**:自动挂载和自动共享可以避免用户手动进行挂载和共享操作,节省时间和工作量。
- **效率**:自动挂载可以确保系统启动时自动连接到远程共享,提高文件访问的效率和连通性。
- **一致性**:自动共享可以确保共享目录在所有客户端上的一致性,避免手动配置导致的不一致性和错误。
通过配置NFS服务器和客户端,以及设置自动挂载和自动共享,可以实现更加便捷和高效的文件共享和管理。接下来将介绍如何配置NFS服务器和客户端,并实现自动挂载和自动共享功能。
# 2. 配置NFS服务器
Network File System(NFS)是一种允许不同的计算机之间共享文件系统的协议。通过配置NFS服务器,您可以轻松地共享文件资源给网络上的其他计算机。
### 2.1 安装并配置NFS服务器
首先,您需要安装NFS服务器软件。在大多数Linux发行版中,您可以使用以下命令安装NFS服务器:
```bash
sudo apt install nfs-kernel-server # Ubuntu/Debian
sudo yum install nfs-utils # CentOS/RHEL
```
安装完成后,您需要配置NFS服务器以指定要共享的目录。编辑`/etc/exports`文件,并添加类似以下内容:
```bash
/path/to/share IP(rw,sync,no_subtree_check)
```
在这里,`/path/to/share`是您要共享的目录的路径,`IP`是允许访问该共享的客户端IP地址(或者使用`*`表示所有客户端),`rw`表示读写权限,`sync`表示同步写入,`no_subtree_check`用于提高性能。
### 2.2 设置共享目录和权限
确保NFS共享目录的权限设置正确,可以使用以下命令:
```bash
sudo chown nobody:nogroup /path/to/share
sudo chmod 755 /path/to/share
```
通过以上步骤,您已成功配置了NFS服务器并设置了共享目录的权限。接下来,您可以继续配置NFS客户端并测试NFS的功能。
# 3. 配置NFS客户端
NFS客户端是需要连接到NFS服务器以访问共享

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
晶体三极管噪声系数:影响因素深度剖析及优化(专家级解决方案)
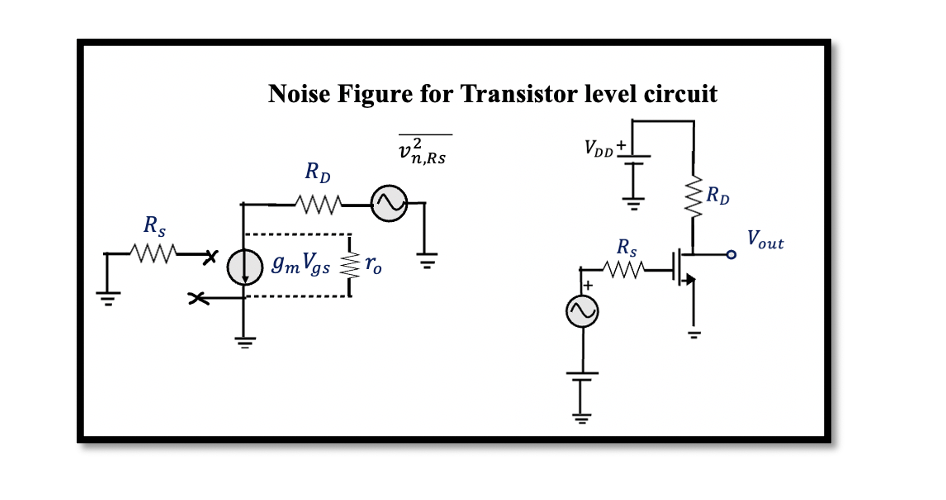
# 摘要
晶体三极管噪声系数是影响电子设备性能的关键参数。本文系统阐述了噪声系数的理论基础,包括其定义、重要性、测量方法和标准,并从材料工艺、设计结构、工作条件三个角度详细分析了影响噪声系数的因素。针对这些影响因素,本文提出了在设计阶段、制造工艺和实际应用中的优化策略,并结合案例研究,提供了噪声系数优化的实践指导和评估方法。研究成果有助于在晶体三极管的生产
MATLAB®仿真源代码深度解析:电子扫描阵列建模技巧全揭露
_0_itok=vqPKU6MD.jpg)
# 摘要
本文综合探讨了MATLAB®在电子扫描阵列仿真中的应用,从基础理论到实践技巧,再到高级技术与优化方法。首先介绍MATLAB®仿真的基本概念和电子扫描阵列的基础理论,包括阵列天线的工作原理和仿真模型的关键建立步骤。然后,深入讲解了MATLAB®
RK3308多媒体应用硬件设计:提升性能的3大要点

# 摘要
本论文详细介绍了RK3308多媒体应用硬件的各个方面,包括硬件概述、性能优化、内存与存储管理、多媒体编解码性能提升、电源管理与热设计,以及设计实例与技术趋势。通过对RK3308处理器架构和硬件加速技术的分析,本文阐述了其在多媒体应用中的性能关键指标和优化策略。本文还探讨了内存和存储的管理策略,以及编解码器的选择、多线程优化、音频处理方案,并分析了低功耗设计和热管理技术的应用。最后,通过实
Matlab矩阵操作速成:速查手册中的函数应用技巧

# 摘要
本文系统地介绍了Matlab中矩阵操作的基础知识与进阶技巧,并探讨了其在实际应用中的最佳实践。第一章对矩阵进行了基础概述,第二章深入讨论了矩阵的创建、索引、操作方法,第三章则聚焦于矩阵的分析、线性代数操作及高级索引技术。第四章详细解释了Matlab内置的矩阵操作函数,以及如何通过这些函数优化性能。在第五章中,通过解决工程数学问题、数据分析和统计应用,展示了矩阵操作的实际应用。最后一章提供了矩阵操作的编码规范
DVE中的数据安全与备份:掌握最佳实践和案例分析
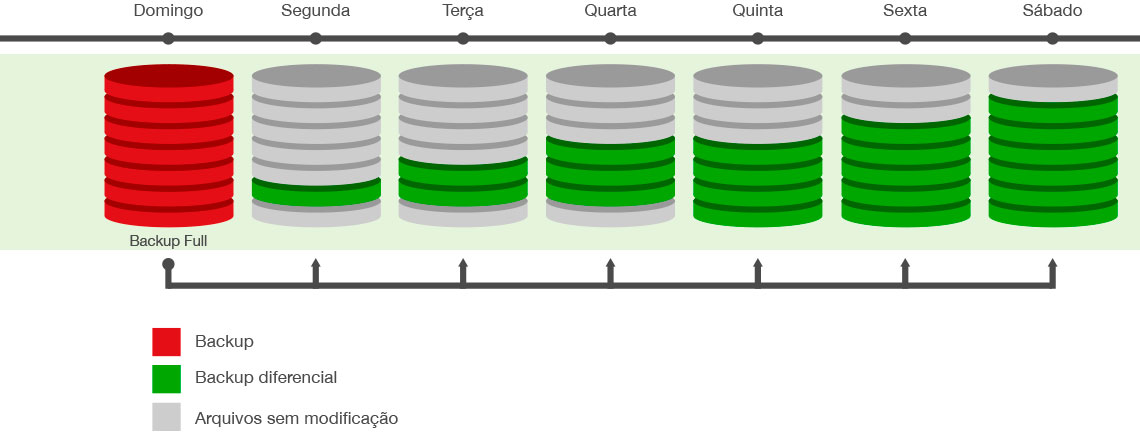
# 摘要
随着信息技术的飞速发展,数据安全与备份成为了企业保护关键信息资产的核心问题。本文首先概述了数据安全的基本理论和备份策略的重要性,然后深入探讨了数据加密与访问控制
自动化图层融合技巧:ArcGIS与SuperMap脚本合并技术
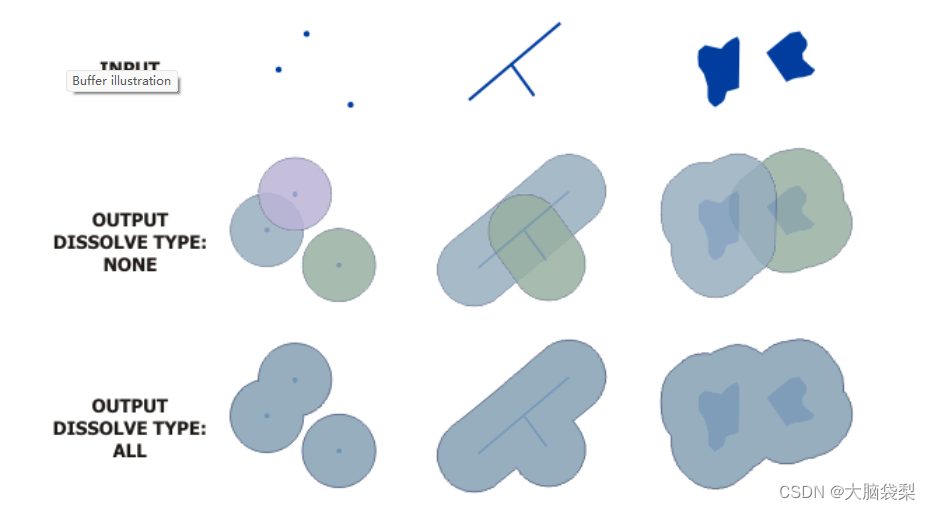
# 摘要
自动化图层融合技术是地理信息系统中重要的技术手段,它能够高效地处理和整合多源空间数据。本文对自动化图层融合技术进行了全面概述,并深入探讨了ArcGIS和SuperMap两种主流地理信息系统在自动化脚本合并基础、图层管理和自动化实践方面的具体应用。通过对比分析,本文揭示了ArcGIS和SuperMap在自动化处理中的相似之处和各自特色,提出了一系列脚本合并的理论基础、策略流程及高级应用
AMESim案例分析:汽车行业仿真实战的20个深度解析
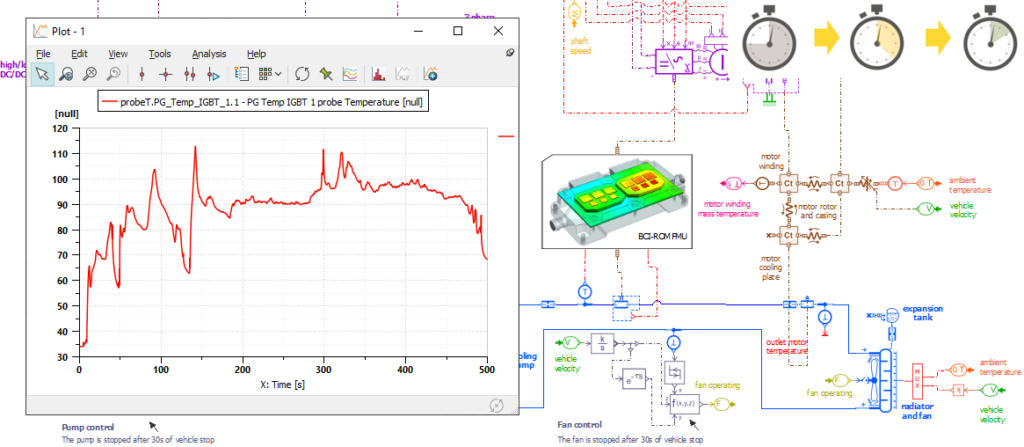
# 摘要
AMESim软件作为一种高级仿真工具,在汽车行业中的应用日益广泛,涵盖了从动力传动系统建模到车辆动力学模拟,再到燃油经济性与排放评估等各个方面。本文详细介绍了AMESim的基础理论、操作界面和工作流程,并深入探讨了在构建和分析仿真模型过程中采用的策略与技巧。通过对不同应用案例的分析,例如混合动力系统和先进驾驶辅助系统的集成,本文展示了
【云基础设施快速通道】:3小时速成AWS服务核心组件

# 摘要
本文全面介绍了云基础设施的基础知识,并以亚马逊网络服务(AWS)为例,详细解读了其核心服务组件的理论基础和实操演练。内容涵盖AWS服务模型的构成(如EC2、S3、VPC)、核心组件间的交互、运行机制、安全性和合规性实践。进一步,文章深入探讨了AWS核心服务的高
CRC16校验码:实践中的理论精髓,数据完整性与性能优化的双重保障
# 摘要
本文全面探讨了CRC16校验码的理论基础、实际应用、实践实现以及性能优化策略。首先介绍了CRC16的数学原理、常见变种以及在数据完整性保障中的作用。接着,详细阐述了CRC16算法在不同编程语言中的实现方法、在文件校验和嵌入式系统中的应用实例。文章第四章专注于性能优化,探讨了算法优化技巧、在大数据环境下的挑战与对策,以及CRC16的性能
【异常处理】:Python在雷电模拟器脚本中的实战应用技巧

# 摘要
本文探讨了Python在雷电模拟器脚本中异常处理的应用,从基础理论到高级技巧进行了全面分析。第一章介绍了Python异常处理的基础知识,为后续章节的深入理解打下基础。第二章重点讨论了异常处理机制在雷电模拟器脚本中的实际应用,包括异常类结构、常见异常类型、捕获与处理技巧以及对脚本性能的影响。第三章进一步阐述了多线程环境下的异常处理策略和资源管理问题,还提供了优化异常处理性能的实践经验。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )