揭秘MATLAB数据处理技巧:从新手到熟练,提升数据分析效率
发布时间: 2024-05-25 21:52:03 阅读量: 88 订阅数: 27 

MATLAB 从入门到精通

# 1. MATLAB 数据处理基础
MATLAB 是一种强大的技术计算语言,广泛用于数据处理、建模和可视化。本节将介绍 MATLAB 数据处理的基础知识,包括数据类型、变量创建和基本操作。
### 1.1 数据类型
MATLAB 支持多种数据类型,包括数值(整数、浮点数)、字符、逻辑和结构。数据类型决定了数据的存储方式和操作。
### 1.2 变量创建
变量用于存储数据。要创建变量,请使用以下语法:
```
variable_name = value;
```
例如,要创建一个名为 `x` 的变量并存储值 10,可以使用以下命令:
```
x = 10;
```
# 2. MATLAB 数据处理技巧
### 2.1 数据输入和输出
#### 2.1.1 文件导入和导出
MATLAB 提供了多种函数来导入和导出数据文件,包括:
* `load`:从 MAT 文件加载数据
* `save`:将数据保存到 MAT 文件
* `importdata`:从文本文件、CSV 文件或 Excel 文件导入数据
* `exportdata`:将数据导出到文本文件、CSV 文件或 Excel 文件
**代码块:**
```
% 从 MAT 文件加载数据
data = load('data.mat');
% 将数据保存到 MAT 文件
save('data.mat', 'data');
% 从 CSV 文件导入数据
data = importdata('data.csv');
% 将数据导出到 Excel 文件
exportdata(data, 'data.xlsx');
```
**逻辑分析:**
* `load` 函数以 MAT 文件名作为输入,将数据加载到工作区中。
* `save` 函数以 MAT 文件名和要保存的数据变量作为输入,将数据保存到 MAT 文件中。
* `importdata` 函数以文件路径和文件类型作为输入,将数据导入到工作区中。
* `exportdata` 函数以数据变量和文件路径作为输入,将数据导出到指定的文件类型中。
#### 2.1.2 数据类型转换
MATLAB 提供了多种函数来转换数据类型,包括:
* `double`:将数据转换为双精度浮点数
* `int32`:将数据转换为 32 位整数
* `char`:将数据转换为字符数组
* `logical`:将数据转换为逻辑数组
**代码块:**
```
% 将数据转换为双精度浮点数
data_double = double(data);
% 将数据转换为 32 位整数
data_int32 = int32(data);
% 将数据转换为字符数组
data_char = char(data);
% 将数据转换为逻辑数组
data_logical = logical(data);
```
**逻辑分析:**
* `double` 函数以数据变量作为输入,将数据转换为双精度浮点数。
* `int32` 函数以数据变量作为输入,将数据转换为 32 位整数。
* `char` 函数以数据变量作为输入,将数据转换为字符数组。
* `logical` 函数以数据变量作为输入,将数据转换为逻辑数组,其中非零元素为真,零元素为假。
### 2.2 数据操作和分析
#### 2.2.1 数组操作
MATLAB 提供了丰富的数组操作函数,包括:
* `size`:获取数组的大小
* `reshape`:改变数组的形状
* `cat`:连接数组
* `find`:查找数组中的元素
* `sort`:对数组进行排序
**代码块:**
```
% 获取数组的大小
size_data = size(data);
% 改变数组的形状
data_reshaped = reshape(data, [10, 10]);
% 连接数组
data_cat = cat(1, data1, data2);
% 查找数组中的元素
index = find(data > 10);
% 对数组进行排序
data_sorted = sort(data);
```
**逻辑分析:**
* `size` 函数以数组变量作为输入,返回一个包含数组维度的向量。
* `reshape` 函数以数组变量和目标形状作为输入,改变数组的形状。
* `cat` 函数以多个数组变量作为输入,将它们连接成一个新的数组。
* `find` 函数以数组变量和条件作为输入,返回满足条件的元素的索引。
* `sort` 函数以数组变量作为输入,返回一个按升序或降序排序的新数组。
#### 2.2.2 矩阵运算
MATLAB 提供了广泛的矩阵运算函数,包括:
* `inv`:求矩阵的逆
* `det`:求矩阵的行列式
* `eig`:求矩阵的特征值和特征向量
* `svd`:求矩阵的奇异值分解
* `chol`:求矩阵的 Cholesky 分解
**代码块:**
```
% 求矩阵的逆
inv_A = inv(A);
% 求矩阵的行列式
det_A = det(A);
% 求矩阵的特征值和特征向量
[eig_val, eig_vec] = eig(A);
% 求矩阵的奇异值分解
[U, S, V] = svd(A);
% 求矩阵的 Cholesky 分解
L = chol(A);
```
**逻辑分析:**
* `inv` 函数以矩阵变量作为输入,返回矩阵的逆。
* `det` 函数以矩阵变量作为输入,返回矩阵的行列式。
* `eig` 函数以矩阵变量作为输入,返回矩阵的特征值和特征向量。
* `svd` 函数以矩阵变量作为输入,返回矩阵的奇异值分解,其中 U 和 V 是正交矩阵,S 是对角矩阵。
* `chol` 函数以对称正定矩阵变量作为输入,返回矩阵的 Cholesky 分解,其中 L 是下三角矩阵。
#### 2.2.3 统计分析
MATLAB 提供了多种统计分析函数,包括:
* `mean`:计算数据的平均值
* `std`:计算数据的标准差
* `var`:计算数据的方差
* `max`:计算数据的最大值
* `min`:计算数据的最小值
**代码块:**
```
% 计算数据的平均值
mean_data = mean(data);
% 计算数据的标准差
std_data = std(data);
% 计算数据的方差
var_data = var(data);
% 计算数据的最大值
max_data = max(data);
% 计算数据的最小值
min_data = min(data);
```
**逻辑分析:**
* `mean` 函数以数据变量作为输入,返回数据的平均值。
* `std` 函数以数据变量作为输入,返回数据的标准差。
* `var` 函数以数据变量作为输入,返回数据的方差。
* `max` 函数以数据变量作为输入,返回数据的最大值。
* `min` 函数以数据变量作为输入,返回数据的最小值。
# 3. MATLAB 数据可视化
### 3.1 基本绘图函数
MATLAB 提供了一系列基本绘图函数,用于创建各种类型的图表和图形。这些函数包括:
- `plot`:创建折线图和散点图。
- `bar`:创建条形图。
- `hist`:创建直方图。
- `pie`:创建饼图。
**代码块:创建折线图**
```matlab
% 生成数据
x = 1:10;
y = rand(1, 10);
% 创建折线图
plot(x, y);
xlabel('x');
ylabel('y');
title('折线图');
```
**逻辑分析:**
* `plot(x, y)` 函数创建折线图,其中 `x` 指定 x 轴值,`y` 指定 y 轴值。
* `xlabel` 和 `ylabel` 函数分别设置 x 轴和 y 轴的标签。
* `title` 函数设置图形的标题。
### 3.1.2 直方图和饼图
**代码块:创建直方图**
```matlab
% 生成数据
data = randn(100, 1);
% 创建直方图
hist(data);
xlabel('值');
ylabel('频率');
title('直方图');
```
**逻辑分析:**
* `hist(data)` 函数创建直方图,其中 `data` 指定要绘制的向量。
* `xlabel` 和 `ylabel` 函数分别设置 x 轴和 y 轴的标签。
* `title` 函数设置图形的标题。
**代码块:创建饼图**
```matlab
% 生成数据
data = [30, 40, 20, 10];
labels = {'类别 A', '类别 B', '类别 C', '类别 D'};
% 创建饼图
pie(data, labels);
title('饼图');
```
**逻辑分析:**
* `pie(data, labels)` 函数创建饼图,其中 `data` 指定每个扇区的面积,`labels` 指定扇区的标签。
* `title` 函数设置图形的标题。
### 3.2 高级可视化技术
MATLAB 还提供了高级可视化技术,用于创建更复杂的图表和图形,包括:
- 三维绘图
- 交互式可视化
### 3.2.1 三维绘图
**代码块:创建三维表面图**
```matlab
% 生成数据
[X, Y] = meshgrid(-2:0.1:2);
Z = X.^2 + Y.^2;
% 创建三维表面图
surf(X, Y, Z);
xlabel('x');
ylabel('y');
zlabel('z');
title('三维表面图');
```
**逻辑分析:**
* `meshgrid` 函数生成网格数据。
* `surf` 函数创建三维表面图,其中 `X`, `Y`, `Z` 指定表面上的点。
* `xlabel`, `ylabel`, `zlabel` 和 `title` 函数分别设置 x 轴、y 轴、z 轴和图形的标签。
### 3.2.2 交互式可视化
MATLAB 提供了交互式可视化工具,允许用户与图表和图形进行交互。这些工具包括:
- `pan`:平移图形。
- `zoom`:缩放图形。
- `rotate`:旋转图形。
**代码块:创建交互式折线图**
```matlab
% 生成数据
x = 1:10;
y = rand(1, 10);
% 创建折线图
plot(x, y);
xlabel('x');
ylabel('y');
title('交互式折线图');
% 启用交互式功能
pan on;
zoom on;
rotate3d on;
```
**逻辑分析:**
* `pan on`, `zoom on` 和 `rotate3d on` 函数启用交互式功能。
* 用户可以通过拖动鼠标来平移、缩放和旋转图形。
# 4. MATLAB 数据处理实践
### 4.1 数据清洗和预处理
数据清洗和预处理是数据处理中的重要步骤,可以提高后续分析和建模的准确性和效率。
**4.1.1 缺失值处理**
缺失值是数据集中常见的问题,处理不当会影响后续分析。MATLAB 提供了多种处理缺失值的方法:
* **删除缺失值:**如果缺失值的数量较少且不影响分析结果,可以将其删除。
* **插补缺失值:**使用其他数据点来估计缺失值。MATLAB 中常用的插补方法包括:
* `nanmean()`:用数组中非缺失值的平均值填充缺失值。
* `nanmedian()`:用数组中非缺失值的中值填充缺失值。
* `nanmin()`:用数组中非缺失值的最小值填充缺失值。
* `nanmax()`:用数组中非缺失值的最大值填充缺失值。
```
% 导入数据
data = importdata('data.csv');
% 处理缺失值
data(isnan(data)) = nanmean(data);
% 输出处理后的数据
disp(data);
```
**4.1.2 数据标准化**
数据标准化可以将不同量纲的数据转换为具有相同量纲的数据,便于后续分析和建模。MATLAB 中常用的标准化方法包括:
* **均值归一化:**将数据减去其均值并除以其标准差。
* **最大最小归一化:**将数据缩放到 [0, 1] 范围内。
* **小数定标:**将数据缩放到 [0, 1] 范围内,但保留数据的分布。
```
% 均值归一化
data_normalized = (data - mean(data)) / std(data);
% 最大最小归一化
data_normalized = (data - min(data)) / (max(data) - min(data));
% 小数定标
data_normalized = data / max(data);
```
### 4.2 特征工程和模型构建
特征工程和模型构建是机器学习中的关键步骤,可以提高模型的性能。
**4.2.1 特征选择**
特征选择可以从原始数据中选择最具信息量和预测力的特征,从而提高模型的准确性和效率。MATLAB 中常用的特征选择方法包括:
* **相关性分析:**计算特征与目标变量之间的相关性,选择相关性较高的特征。
* **信息增益:**计算特征对目标变量的信息增益,选择信息增益较高的特征。
* **卡方检验:**计算特征与目标变量之间的卡方值,选择卡方值较高的特征。
```
% 相关性分析
[corr_matrix, p_values] = corr(data, target);
selected_features = find(abs(corr_matrix) > 0.5 & p_values < 0.05);
% 信息增益
ig = infoGain(data, target);
selected_features = find(ig > 0.5);
% 卡方检验
[chi2, p_values] = chi2test(data, target);
selected_features = find(p_values < 0.05);
```
**4.2.2 模型训练和评估**
模型训练和评估是机器学习中不可或缺的步骤,可以确定模型的性能并进行优化。MATLAB 中常用的模型训练和评估方法包括:
* **线性回归:**用于预测连续型目标变量。
* **逻辑回归:**用于预测二分类目标变量。
* **决策树:**用于预测分类和连续型目标变量。
* **支持向量机:**用于预测分类目标变量。
```
% 线性回归
model = fitlm(data, target);
% 评估模型
rmse = sqrt(mean((model.predict(data) - target).^2));
r2 = 1 - sum((model.predict(data) - target).^2) / sum((target - mean(target)).^2);
% 决策树
model = fitctree(data, target);
% 评估模型
accuracy = sum(model.predict(data) == target) / length(target);
```
# 5.1 并行计算和分布式处理
MATLAB 提供了强大的并行计算和分布式处理功能,可以显著提高数据处理速度和效率。
### 5.1.1 并行处理工具箱
MATLAB 的并行处理工具箱提供了丰富的函数和工具,支持多核和多处理器并行计算。
- **parfor 循环:**并行执行 for 循环,将任务分配给多个工作进程。
```matlab
parfor i = 1:10000
% 执行并行任务
end
```
- **spmd 块:**创建并行代码块,允许在多个工作进程中同时执行代码。
```matlab
spmd
% 执行并行任务
end
```
- **并行池:**创建并行池,管理工作进程并分配任务。
```matlab
pool = parpool;
parfor i = 1:10000
% 执行并行任务
end
delete(pool);
```
### 5.1.2 云计算平台
MATLAB 支持与云计算平台集成,如 Amazon Web Services (AWS) 和 Microsoft Azure。
- **AWS Parallel Computing SDK:**使用 AWS Parallel Computing SDK,可以在 AWS 云上创建和管理并行计算作业。
```matlab
% 创建并行作业
job = createJob(cluster, 'MyJob');
% 提交任务
submit(job, @myFunction, 10000);
% 等待作业完成
waitFor(job);
```
- **Azure Batch 服务:**使用 Azure Batch 服务,可以在 Azure 云上提交和管理大规模并行作业。
```matlab
% 创建 Batch 客户端
batchClient = batch('SubscriptionId', '...', 'ResourceGroup', '...');
% 创建作业
job = createJob(batchClient, 'MyJob', 'Standard_D2_v2', 10);
% 添加任务
addTask(job, 'MyTask', @myFunction, 10000);
% 提交作业
commit(job);
% 等待作业完成
waitForTasks(job);
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 MATLAB 使用教程专栏!本专栏将带您踏上 MATLAB 数据处理、绘图、算法、图像处理、深度学习、并行计算、错误定位、代码质量、性能优化和并发编程的精彩旅程。
从新手到熟练,您将掌握 MATLAB 的数据处理技巧,提升数据分析效率。通过实战案例,您将学会绘制精美图表,让数据可视化。深入探索 MATLAB 算法,从基础到高级,解锁算法潜力。揭秘 MATLAB 图像处理奥秘,从图像增强到目标检测,让您轻松处理图像数据。
解锁 MATLAB 深度学习潜力,开启人工智能时代,开启深度学习之旅。加速 MATLAB 并行计算,提升效率,缩短计算时间。快速定位 MATLAB 错误,提升开发效率,减少调试时间。确保 MATLAB 代码质量,单元测试,提升可靠性。优化 MATLAB 性能,提升代码效率,减少计算时间。探索 MATLAB 并发编程,多线程和多进程,提升程序并发性。
准备好提升您的 MATLAB 技能了吗?加入我们,开启 MATLAB 使用之旅,成为一名熟练的数据科学家和程序员!
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
NModbus性能优化:提升Modbus通信效率的5大技巧
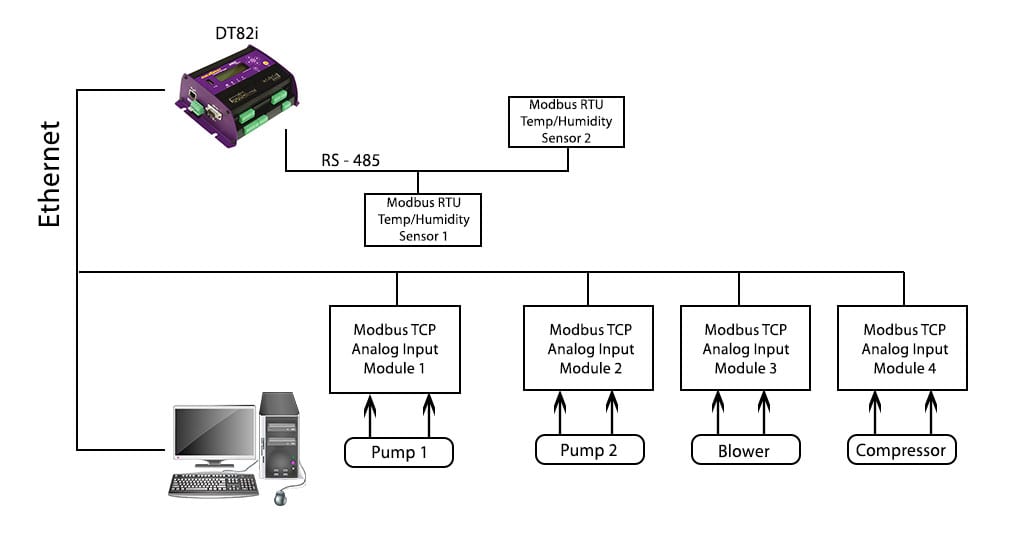
# 摘要
本文综述了NModbus性能优化的各个方面,包括理解Modbus通信协议的历史、发展和工作模式,以及NModbus基础应用与性能瓶颈的分析。文中探讨了性能瓶颈常见原因,如网络延迟、数据处理效率和并发连接管理,并提出了多种优化技巧,如缓存策略、批处理技术和代码层面的性能改进。文章还通过工业自动化系统的案例分析了优化实施过程和结果,包括性能对比和稳定性改进。最后,本文总结了优化经验,展望了NModbus性能优化技术的发展方向。
【Java开发者效率利器】:Eclipse插件安装与配置秘籍

# 摘要
Eclipse插件开发是扩展IDE功能的重要途径,本文对Eclipse插件开发进行了全面概述。首先介绍了插件的基本类型、架构及安装过程,随后详述了提升Java开发效率的实用插件,并探讨了高级配置技巧,如界面自定义、性能优化和安全配置。第五章讲述了开发环境搭建、最佳实践和市场推广策略。最后,文章通过案例研究,分析了成功插件的关键因素,并展望了未来发展趋势和面临的技
【性能测试:基础到实战】:上机练习题,全面提升测试技能

# 摘要
随着软件系统复杂度的增加,性能测试已成为确保软件质量不可或缺的一环。本文从理论基础出发,深入探讨了性能测试工具的使用、定制和调优,强调了实践中的测试环境构建、脚本编写、执行监控以及结果分析的重要性。文章还重点介绍了性能瓶颈分析、性能优化策略以及自动化测试集成的方法,并展望了
SECS-II调试实战:高效问题定位与日志分析技巧

# 摘要
SECS-II协议作为半导体设备通信的关键技术,其基础与应用环境对提升制造自动化与数据交换效率至关重要。本文详细解析了SECS-II消息的类型、格式及交换过程,包括标准与非标准消息的处理、通信流程、流控制和异常消息的识别。接着,文章探讨了SECS-II调试技巧与工具,从调试准备、实时监控、问题定位到日志分析
Redmine数据库升级深度解析:如何安全、高效完成数据迁移

# 摘要
随着信息技术的发展,项目管理工具如Redmine的需求日益增长,其数据库升级成为确保系统性能和安全的关键环节。本文系统地概述了Redmine数据库升级的全过程,包括升级前的准备工作,如数据库评估、选择、数据备份以及风险评估。详细介绍了安全迁移步骤,包括
YOLO8在实时视频监控中的革命性应用:案例研究与实战分析

# 摘要
YOLO8作为一种先进的实时目标检测模型,在视频监控应用中表现出色。本文概述了YOLO8的发展历程和理论基础,重点分析了其算法原理、性能评估,以及如何在实战中部署和优化。通过探讨YOLO8在实时视频监控中的应用案例,本文揭示了它在不同场景下的性能表现和实际应用,同时提出了系统集成方法和优化策略。文章最后展望了YOLO8的未来发展方向,并讨论了其面临的挑战,包括数据隐私和模型泛化能力等问题。本文旨在为研究人员和工程技术人员提供YOLO8
UL1310中文版深入解析:掌握电源设计的黄金法则

# 摘要
电源设计在确保电气设备稳定性和安全性方面发挥着关键作用,而UL1310标准作为重要的行业准则,对于电源设计的质量和安全性提出了具体要求。本文首先介绍了电源设计的基本概念和重要性,然后深入探讨了UL1310标准的理论基础、主要内容以及在电源设计中的应用。通过案例分析,本文展示了UL1310标准在实际电源设计中的实践应用,以及在设计、生产、测试和认证各阶段所面
Lego异常处理与问题解决:自动化测试中的常见问题攻略

# 摘要
本文围绕Lego异常处理与自动化测试进行深入探讨。首先概述了Lego异常处理与问题解决的基本理论和实践,随后详细介绍了自动化测试的基本概念、工具选择、环境搭建、生命周期管理。第三章深入探讨了异常处理的理论基础、捕获与记录方法以及恢复与预防策略。第四章则聚焦于Lego自动化测试中的问题诊断与解决方案,包括测试脚本错误、数据与配置管理,以及性
【Simulink频谱分析:立即入门】
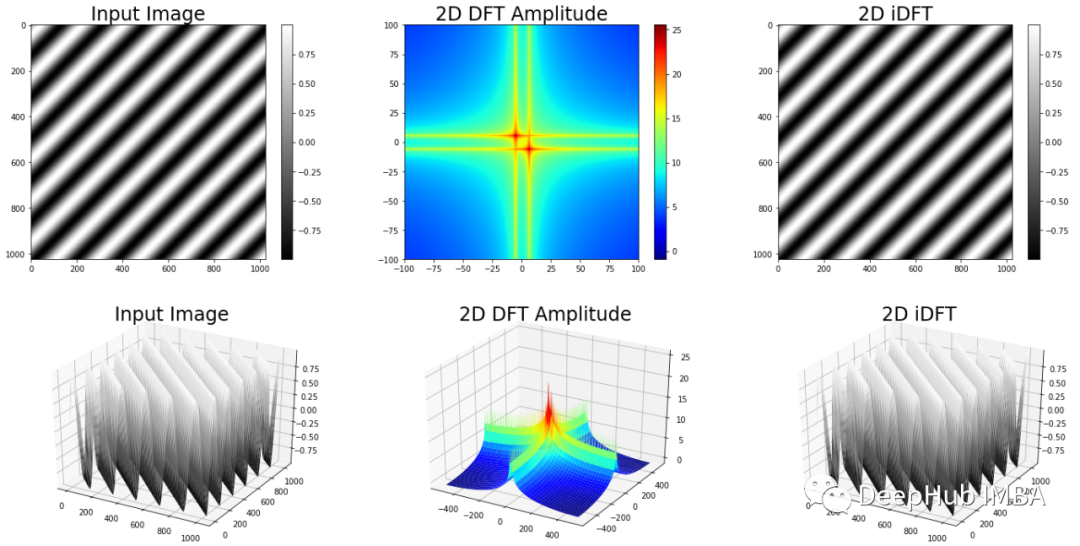
# 摘要
本文系统地介绍了Simulink在频谱分析中的应用,涵盖了从基础原理到高级技术的全面知识体系。首先,介绍了Simulink的基本组件、建模环境以及频谱分析器模块的使用。随后,通过多个实践案例,如声音信号、通信信号和RF信号的频谱分析,展示了Simulink在不同领域的实际应用。此外,文章还深入探讨了频谱分析参数的优化,信号处理工具箱的使用,以及实时频谱分析与数据采
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )