Python进阶神器:彻底征服计算机二级考试的高级题型
发布时间: 2024-12-28 13:02:42 阅读量: 7 订阅数: 9 

# 摘要
本论文详细介绍了Python的高级编程技术,覆盖了数据结构的高级应用、文件操作和数据处理、错误处理和调试技术,以及面向对象编程的核心概念和设计原则。进一步,文章深入探讨了Python在网络编程和多线程领域的应用,包括socket编程、HTTP通信、线程管理和异步编程的原理与实现。最后,论文针对数据分析和机器学习的基础知识,提供了NumPy和Pandas库的深入应用,以及基本机器学习算法的实践案例。整篇论文旨在通过理论与实践相结合的方式,帮助读者全面掌握Python的高级功能,并应用于解决实际问题。
# 关键字
Python高级编程;数据结构;面向对象编程;网络编程;多线程;数据分析;机器学习
参考资源链接:[计算机二级Python真题解析与练习资料](https://wenku.csdn.net/doc/b5f52xpxm4?spm=1055.2635.3001.10343)
# 1. Python高级编程概览
## 1.1 编程语言的进化与Python的崛起
Python作为一门功能强大的编程语言,自20世纪90年代诞生以来,已发展成为业界广泛采用的技术。它以其简洁明了的语法、强大的库支持以及跨平台的特性,赢得了包括Web开发、数据分析、人工智能等多个领域的青睐。本章将为读者提供一个Python编程的高级概览,揭示其成为全球最受欢迎的编程语言之一的原因。
## 1.2 Python的高级特性简介
Python高级编程并不仅仅是代码的堆砌,更多的是对语言特性的深入理解和运用。这一部分将简述一些高级特性,如动态类型、内存管理和垃圾回收机制、以及面向对象编程(OOP)的高级概念,这些都是深入学习Python所必备的基础知识。本章的目的是激发读者深入探索Python世界的兴趣,为后续章节的学习打下坚实的基础。
以上为第一章内容,提供了一个关于Python的高级编程概览,强调了Python在众多领域中的应用及地位,并简介了高级特性的重要性。接下来的章节将会对这些高级特性进行更深入的探讨和实例分析。
# 2. 深入理解Python高级特性
## 2.1 数据结构的高级应用
### 2.1.1 字典和集合的高级操作
Python中的字典和集合是极其高效的数据结构,尤其在处理大量数据时,它们提供了独特的操作优势。在这一部分,我们将深入探讨这些结构的高级使用技巧,包括自定义对象作为键、集合的运算以及集合推导式等。
#### 自定义对象作为字典键
字典的键必须是不可变的,这通常意味着它们是字符串、数字或者元组。然而,在某些情况下,我们可能需要使用自定义对象作为键。为了实现这一点,自定义类必须实现 `__hash__()` 和 `__eq__()` 方法:
```python
class CustomKey:
def __init__(self, name):
self.name = name
def __hash__(self):
return hash(self.name)
def __eq__(self, other):
return self.name == other.name
# 使用自定义对象作为字典的键
dict_with_custom_keys = {CustomKey('key1'): 'value1', CustomKey('key2'): 'value2'}
```
逻辑分析:创建一个类 `CustomKey`,其中 `__hash__` 方法返回属性 `name` 的哈希值,`__eq__` 方法比较两个 `CustomKey` 对象的 `name` 属性是否相等。然后我们创建了一个字典 `dict_with_custom_keys`,其键是 `CustomKey` 的实例。
#### 集合的运算
集合提供了非常有用的运算符,如并集(`|`)、交集(`&`)、差集(`-`)和对称差集(`^`),这些运算符极大地简化了集合间的运算:
```python
set_a = {1, 2, 3}
set_b = {3, 4, 5}
# 并集
union_set = set_a | set_b
# 交集
intersection_set = set_a & set_b
# 差集
difference_set = set_a - set_b
# 对称差集
symmetric_difference_set = set_a ^ set_b
```
参数说明:`set_a` 和 `set_b` 是两个集合对象,使用运算符 `|` 获取它们的并集,`&` 获取交集,`-` 获取差集,`^` 获取对称差集。
#### 集合推导式
集合推导式是列表推导式在集合中的类似形式,它提供了一种简洁的方式来创建集合:
```python
squared_set = {x*x for x in range(10)}
```
逻辑分析:这段代码创建了一个包含0到9每个数字平方的集合 `squared_set`。集合推导式比等效的for循环要简洁得多,并且由于集合本身是无序的,使用集合推导式更为合适。
### 2.1.2 列表推导式和生成器表达式
列表推导式和生成器表达式是Python中处理列表和其他序列类型的强大工具,它们让代码更加简洁和高效。这部分将探讨它们的高级用法和最佳实践。
#### 多重循环的列表推导式
列表推导式不仅限于单一循环,还可以包含多个嵌套循环,它们通常用于生成多维数据结构:
```python
matrix = [[j for j in range(3)] for i in range(3)]
```
逻辑分析:这段代码通过嵌套的列表推导式创建了一个3x3的矩阵,其中内部的列表推导式生成每一行,外部的列表推导式生成每一列。
#### 条件过滤
在列表推导式中可以使用条件过滤来排除不需要的元素:
```python
even_numbers = [x for x in range(10) if x % 2 == 0]
```
逻辑分析:这段代码生成了一个包含0到9之间所有偶数的列表 `even_numbers`。其中 `if x % 2 == 0` 条件过滤确保只包含偶数。
#### 生成器表达式
生成器表达式与列表推导式类似,但不是立即生成整个列表,而是返回一个生成器对象,这在处理大数据时更加内存高效:
```python
sum_of_squares = sum(x*x for x in range(10))
```
逻辑分析:这段代码计算了0到9每个数字的平方和。使用生成器表达式而不是列表推导式可以节省内存,因为它在计算过程中不需要存储整个列表。
总结:在本节中,我们探索了Python字典和集合的高级操作,以及列表和生成器表达式的多种使用场景。通过这些高级特性,我们能够编写更加高效和优雅的代码,处理复杂的数据结构和操作。
# 3. Python面向对象编程
在Python中,面向对象编程(OOP)是一种强大的编程范式,它允许开发者设计出结构化和模块化的代码。这一章节将深入探讨类与对象的深层原理,高级面向对象概念,以及面向对象设计原则。通过本章节的学习,你将能够编写更加高效、可维护和可扩展的代码。
## 3.1 类和对象的深入理解
### 3.1.1 类的继承和多态性
在Python中,继承是实现代码复用的重要机制。子类可以继承父类的属性和方法,同时也可以有自己的独特属性和方法。多态性则是指相同的消息发送给不同的对象,可能会得到不同的响应,这是通过方法重写实现的。
#### 继承的示例代码
```python
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
pass
class Dog(Animal):
def speak(self):
return f"{self.name} says woof!"
class Cat(Animal):
def speak(self):
return f"{self.name} says meow!"
# 创建对象并调用方法
dog = Dog("Buddy")
cat = Cat("Whiskers")
print(dog.speak()) # 输出: Buddy says woof!
print(cat.speak()) # 输出: Whiskers says meow!
```
在这个例子中,`Dog` 和 `Cat` 类继承自 `Animal` 类。它们各自重写了 `speak` 方法以提供不同的输出。
#### 多态性的示例代码
多态性通过抽象基类(ABC)来实现,我们可以创建一个方法,它接受不同子类的对象作为参数,并调用相应的方法。
```python
from abc import ABC, abstractmethod
class Animal(ABC):
@abstractmethod
def speak(self):
pass
# 其他类的定义与上述相同...
def animal_sound(animal: Animal):
print(animal.speak())
animal_sound(dog) # 输出: Buddy says woof!
animal_sound(cat) # 输出: Whiskers says meow!
```
这里,`Animal` 类是一个抽象基类,`speak` 方法被标记为抽象方法,这要求所有继承自 `Animal` 的子类都必须实现这个方法。
### 3.1.2 封装、继承与多态的应用实例
#### 封装的应用实例
封装通过私有和公有成员实现,它允许数据隐藏和访问控制。Python中通过在变量或方法前加双下划线实现私有成员。
```python
class Vehicle:
def __init__(self, brand):
self.__brand = brand # 私有属性
def get_brand(self):
return self.__brand
def set_brand(self, brand):
self.__brand = brand
my_vehicle = Vehicle("Toyota")
print(my_vehicle.get_brand()) # 输出: Toyota
# my_vehicle.__brand = "Honda" # 这将引发错误,因为 __brand 是私有的
```
通过封装,我们可以控制如何访问和修改对象的内部状态。
#### 继承与多态的应用实例
通过创建一个基类,并让多个子类继承它,我们可以展示如何在不同子类中实现相同的方法。以下是一个简单的员工管理系统的例子。
```python
class Employee:
def __init__(self, name, department):
self.name = name
self.department = department
def get_details(self):
return f"{self.name} works in {self.department} department."
class Manager(Employee):
def get_details(self):
return f"{self.name} is a manager in {self.department} department."
class Developer(Employee):
def get_details(self):
return f"{self.name} is a developer in {self.department} department."
employees = [Employee("Alice", "HR"), Manager("Bob", "Engineering"), Developer("Charlie", "Engineering")]
for emp in employees:
print(emp.get_details())
```
这个例子展示了如何通过继承实现子类拥有父类的基本功能,同时每个子类也能够提供特定的信息,体现了多态性。
在本节中,我们探讨了类的继承和多态性,并通过示例代码演示了这些概念。下一节我们将深入了解迭代器和生成器,以及装饰器的原理与应用。
# 4. Python网络编程与多线程
## 4.1 网络编程基础
网络编程是Python编程中非常实用的技能,特别是在涉及到客户端和服务器之间通信的应用场景。在本章节中,我们将深入探讨如何使用Python的socket库来进行网络通信,并实现简单的HTTP客户端和服务器。
### 4.1.1 使用socket进行网络通信
Python的`socket`模块是进行网络编程的基础。它提供了一系列的函数和方法,使得我们能够轻松地创建网络连接、发送和接收数据。我们将从最基本的TCP(传输控制协议)和UDP(用户数据报协议)套接字开始。
首先,我们来看一个TCP套接字的例子。TCP是一种面向连接的协议,保证了数据的可靠传输。TCP套接字的编程模型包括创建套接字、连接、发送/接收数据、断开连接等步骤。以下是一个简单的TCP服务器和客户端的例子。
```python
import socket
# TCP服务器端示例代码
def tcp_server(ip, port):
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((ip, port))
server_socket.listen(5)
conn, addr = server_socket.accept()
print("Connected by", addr)
while True:
data = conn.recv(1024)
if not data:
break
print(f"Received data: {data}")
conn.sendall(data) # Echo back the received data
conn.close()
# TCP客户端示例代码
def tcp_client(ip, port):
client_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client_socket.connect((ip, port))
message = "Hello, server!"
client_socket.sendall(message.encode())
data = client_socket.recv(1024)
print(f"Received back: {data}")
client_socket.close()
if __name__ == "__main__":
SERVER_IP = '127.0.0.1'
SERVER_PORT = 12345
# Start the server in a separate thread or process
# Start the client here
```
该TCP服务器代码监听本地的指定端口,等待客户端的连接。一旦有客户端连接,它就会接收客户端发送的消息,并将相同的消息发送回客户端。
接下来,我们将介绍UDP套接字。UDP协议是无连接的,数据包可能会丢失、重复或乱序。UDP适用于实时性要求高、可以容忍一定丢包的应用场景。以下是UDP套接字的一个简单使用示例:
```python
import socket
# UDP服务器端示例代码
def udp_server(ip, port):
server_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
server_socket.bind((ip, port))
while True:
data, addr = server_socket.recvfrom(1024)
print(f"Received from {addr}: {data}")
server_socket.sendto(data, addr) # Echo back the received data
# UDP客户端示例代码
def udp_client(ip, port):
client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
message = "Hello, server!"
client_socket.sendto(message.encode(), (ip, port))
data, addr = client_socket.recvfrom(1024)
print(f"Received back from {addr}: {data}")
if __name__ == "__main__":
SERVER_IP = '127.0.0.1'
SERVER_PORT = 12345
# Start the server in a separate thread or process
# Start the client here
```
UDP服务器代码设置了一个可以接受数据包的套接字,并简单地将收到的数据包回传给发送者。UDP客户端发送数据后,等待服务器的响应。
在实现网络通信时,我们需要注意以下几点:
- **异常处理**:网络编程中经常涉及到网络异常处理。例如,如果网络出现问题,客户端可能无法成功连接到服务器。此时,应该捕获异常并进行相应处理。
- **资源管理**:网络资源是有限的,特别是在网络编程中使用套接字时,应当在不再需要时及时关闭套接字。
- **安全性**:在互联网上进行通信时,数据的隐私和完整性非常重要。可以考虑使用SSL/TLS等安全协议来加强数据传输的安全性。
### 4.1.2 实现简单的HTTP客户端与服务器
HTTP(超文本传输协议)是互联网上使用最广泛的协议之一。Python的`http.client`模块可以用来创建HTTP客户端,而`http.server`模块可以用来创建简单的HTTP服务器。下面我们将展示如何使用这些模块。
#### 简单的HTTP服务器
```python
import http.server
import socketserver
PORT = 8080
Handler = http.server.SimpleHTTPRequestHandler
with socketserver.TCPServer(("", PORT), Handler) as httpd:
print(f"Serving at port {PORT}")
httpd.serve_forever()
```
这段代码创建了一个简单的HTTP服务器,它监听本地的8080端口,并能够处理对文件的HTTP请求。
#### 简单的HTTP客户端
```python
import http.client
conn = http.client.HTTPConnection("localhost", 8080)
conn.request("GET", "/")
response = conn.getresponse()
data = response.read()
print(data.decode("utf-8"))
conn.close()
```
这段代码通过HTTP连接到我们之前创建的服务器,并请求了根目录的资源,然后打印了响应的内容。
在创建HTTP服务器和客户端时,需要考虑如下几个方面:
- **并发处理**:HTTP服务器通常需要处理多个客户端请求。在Python中,我们可以使用多线程或异步IO来处理并发连接。
- **请求和响应处理**:HTTP服务器需要能够解析HTTP请求并生成正确的HTTP响应。需要处理不同类型的HTTP请求(如GET、POST、PUT等)。
- **错误处理**:需要妥善处理如404(未找到)、500(服务器内部错误)等HTTP状态码的返回。
通过本节内容的介绍,我们对Python的网络编程有了一个基础的了解。接下来,我们将深入探讨多线程编程,这是一种在单个进程内实现并行处理的技术。
# 5. Python在数据分析中的应用
数据分析是利用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。Python因其强大的数据处理库而在数据分析领域拥有广泛的应用。
## 5.1 NumPy库的深入应用
NumPy是Python中用于科学计算的核心库,提供了高性能的多维数组对象及处理这些数组的工具。它的多维数组结构为数据分析提供了一个极为便利的平台。
### 5.1.1 多维数组操作技巧
在数据分析中,多维数组操作是基础也是核心。以下是一些提升NumPy多维数组操作效率的技巧。
- **数组的索引和切片**:NumPy数组支持高级索引和切片功能,允许快速访问特定元素或子数组。
```python
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 通过索引访问
print("Element at (1, 2):", arr[1, 2])
# 通过切片访问
print("Sub-array:\n", arr[1:, :2])
```
- **数组的形状操作**:通过改变数组的形状可以为不同的数据操作做准备。
```python
# 改变数组形状
reshaped_arr = arr.reshape(1, -1)
print("Reshaped array:\n", reshaped_arr)
```
- **合并和分割数组**:合并是指将多个数组合并成一个数组;分割是指将一个数组分割成多个数组。
```python
arr1 = np.array([1, 2, 3])
arr2 = np.array([4, 5, 6])
# 合并数组
concatenated_arr = np.concatenate((arr1, arr2))
print("Concatenated array:\n", concatenated_arr)
# 分割数组
split_arr = np.split(reshaped_arr, 3, axis=1)
print("Split arrays:\n", split_arr)
```
### 5.1.2 高级索引和数据处理
NumPy的高级索引功能允许你同时使用整数和切片对象、布尔数组等多种索引方法。这些方法可用于高效地提取复杂数据集中的特定部分。
```python
# 创建一个更复杂的三维数组
arr3d = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]], [[9, 10], [11, 12]]])
# 使用高级索引选择特定元素
print("Elements at [1][0][1]:", arr3d[1, 0, 1])
# 使用布尔索引
mask = arr > 5
filtered_elements = arr[mask]
print("Elements greater than 5:\n", filtered_elements)
```
NumPy还提供了许多数组操作的函数,比如数学计算、统计分析等。例如,`np.sum(arr)`、`np.mean(arr)`、`np.std(arr)`分别用于计算数组的和、平均值和标准差。
## 5.2 Pandas库的数据分析
Pandas是基于NumPy构建的一个开源Python库,它提供了易于使用的数据结构和数据分析工具。Pandas的两个主要数据结构是Series和DataFrame。
### 5.2.1 数据结构和数据清洗
Series和DataFrame分别用于处理一维和二维数据结构。数据清洗是分析工作前的准备过程,是保证数据分析质量的关键步骤。
```python
import pandas as pd
# 创建Series和DataFrame
s = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
df = pd.DataFrame([[1, 2], [3, 4], [5, 6]], index=['row1', 'row2', 'row3'], columns=['col1', 'col2'])
# 数据清洗操作
# 填充缺失数据
df_filled = df.fillna(value=0)
# 删除缺失数据
df_dropped = df.dropna()
# 数据类型转换
df['col2'] = df['col2'].astype(float)
# 数据排序
df_sorted = df.sort_values(by='col1', ascending=False)
```
### 5.2.2 数据分组与聚合操作
数据分组和聚合操作是数据分析中不可或缺的部分,Pandas通过`groupby`和`agg`函数提供了强大而灵活的数据操作能力。
```python
# 分组聚合示例
grouped = df.groupby('col1')
aggregated = grouped.agg(['mean', 'sum'])
print("Aggregated data:\n", aggregated)
```
## 5.3 机器学习基础知识
机器学习作为数据分析的重要分支,主要涉及到对数据进行预测和决策。Python中广泛使用的机器学习库scikit-learn能够帮助实现各种机器学习算法。
### 5.3.1 常见机器学习算法简介
机器学习算法种类繁多,其中一些常见的算法包括线性回归、逻辑回归、决策树、随机森林和支持向量机等。
### 5.3.2 使用scikit-learn实现简单模型
scikit-learn库使得机器学习算法的实现变得简单。下面是一个使用scikit-learn实现线性回归模型的示例。
```python
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 加载数据
iris = datasets.load_iris()
X, y = iris.data[:, :2], iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error: ", mse)
```
通过这些章节的深入介绍,我们不仅学习了Python在数据分析中的具体应用,而且还掌握了从数据清洗到模型建立的全过程。这将为读者解决实际问题打下坚实的基础。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘PUBG:罗技鼠标宏的性能与稳定性优化术

# 摘要
罗技鼠标宏作为提升游戏操作效率的工具,在《绝地求生》(PUBG)等游戏中广泛应用。本文首先介绍了罗技鼠标宏的基本概念及在PUBG中的应用和优势。随后探讨了宏与Pergamon软件交互机制及其潜在对游戏性能的影响。第三部分聚焦于宏性能优化实践,包括编写、调试、代码优化及环境影响分析。第四章提出了提升宏稳定性的策略,如异常处理机制和兼容性测试。第五章讨论了
【LS-DYNA高级用户手册】:材料模型调试与优化的终极指南
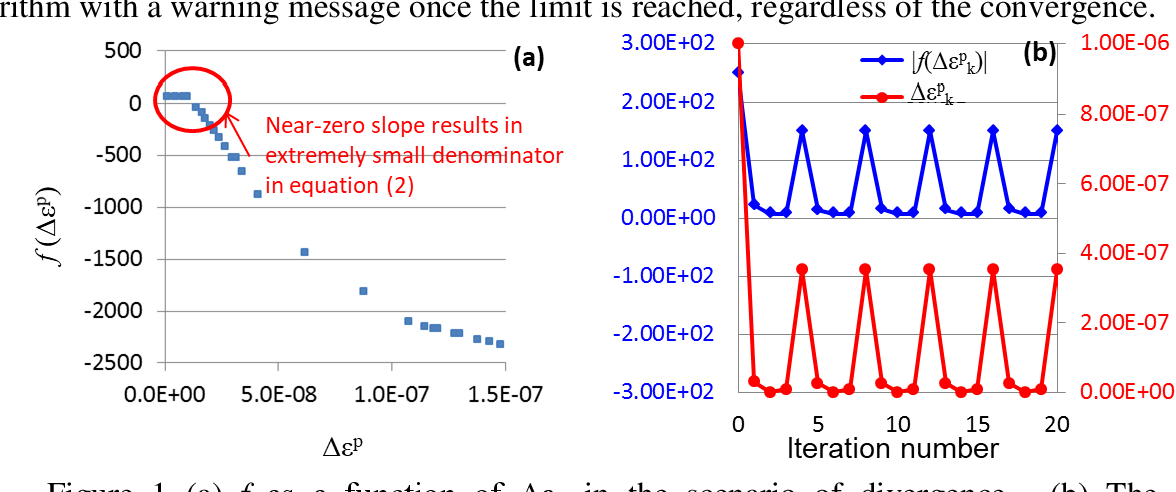
# 摘要
LS-DYNA作为一种先进的非线性动力分析软件,广泛应用于工程模拟。本文首先介绍了LS-DYNA中的材料模型及其重要性,随后深入探讨了材料模型的基础理论、关键参数以及调试和优化方法。通过对不同材料模型的种类和选择、参数的敏感性分析、实验数据对比验证等环节的详细解读,文章旨在提供一套系统的
【FPGA时序分析】:深入掌握Spartan-6的时间约束和优化技巧

# 摘要
本文深入探讨了Spartan-6 FPGA的时序分析和优化策略。首先,介绍了FPGA时序分析的基础知识,随后详细阐述了Spar
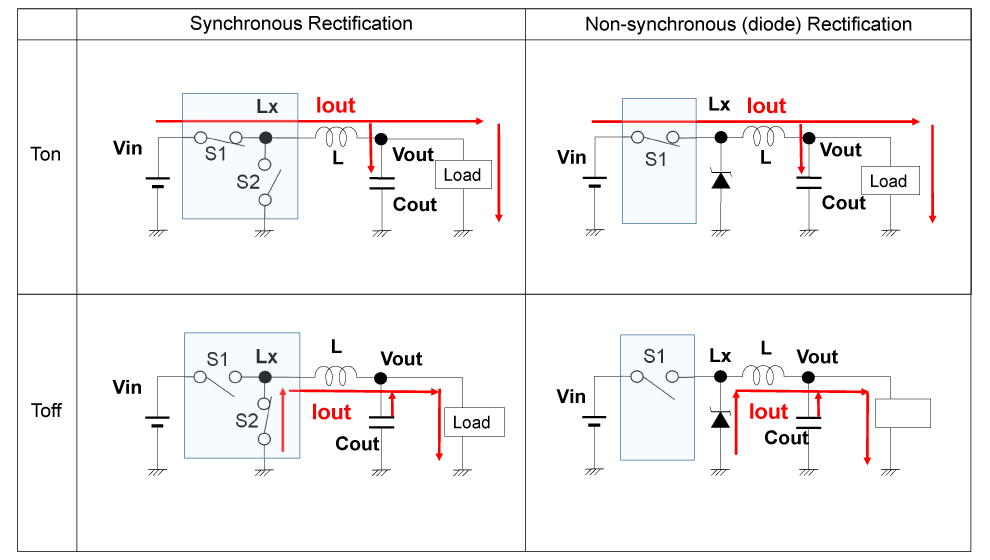
【节能关键】AG3335A芯片电源管理与高效率的秘密
# 摘要
AG3335A芯片作为一款集成先进电源管理功能的微处理器,对电源管理的优化显得尤为重要。本文旨在概述AG3335A芯片,强调其电源管理的重要性,并深入探讨其电源管理原理、高效率实现以及节能技术的实践。通过对AG3335A芯片电源架构的分析,以及动态电压频率调整(DVFS)技术和电源门控技术等电源管理机制的探讨,本文揭示了降低静态和动态功耗的有效策略。同时,本文还介绍了高效率电源设计方案和电源管理
编译原理实战指南:陈意云教授的作业解答秘籍(掌握课后习题的10种方法)

# 摘要
本文回顾了编译原理的基础知识,通过详细的课后习题解读技巧、多种学习方法的分享以及实战案例的解析,旨在提高读者对编译过程各阶段的理解和应用能力。文章
Swatcup性能提升秘籍:专家级别的优化技巧
# 摘要
本文深入探讨了Swatcup这一性能优化工具,全面介绍了其系统架构、性能监控、配置管理、性能调优策略、扩展与定制以及安全加固等方面。文章首先概述了Swatcup的简要介绍和性能优化的重要性,随后详细分析了其系统架构及其组件功能和协同作用,性能监控工具及其关键性能指标的测量方法。接着,本文重点讲解了Swatcup在缓存机制、并发处理以及资源
PDM到PCM转换揭秘:提升音频处理效率的关键步骤

# 摘要
本文对PDM(脉冲密度调制)和PCM(脉冲编码调制)这两种音频格式进行了全面介绍和转换理论的深入分析。通过探讨音频信号的采样与量化,理解PCM的基础概念,并分析PDM
【大规模线性规划解决方案】:Lingo案例研究与处理策略
:quality(75)/arc-anglerfish-arc2-prod-elcomercio.s3.amazonaws.com/public/6JGOGXHVARACBOZCCYVIDUO5PE.jpg)
# 摘要
线性规划是运筹学中的一种核心方法,广泛应用于资源分配、生产调度等领域。本文首先介绍了线性规划的基础知识和实际应用场景,然后详细讨
【散热优化】:热管理策略提升双Boost型DC_DC变换器性能

# 摘要
本文详细阐述了散热优化的基础知识与热管理策略,探讨了双Boost型DC_DC变换器的工作原理及其散热需求,并分析了热失效机制和热损耗来源。基于散热理论和设计原则,文中还提供了散热优化的实践案例分析,其中包括热模拟、实验数据对比以及散热措施的实施和优化。最后,本文展望了散热优化技术的未来趋势,探讨了新兴散热技术的应用前景及散热优化面临的挑战与未来
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )