探索ML.NET:基础概念解析
发布时间: 2024-02-20 20:21:28 阅读量: 14 订阅数: 20 
# 1. 简介
## 1.1 机器学习概述
在当今信息爆炸的时代,数据已经成为了无处不在的资源。机器学习作为人工智能的一个分支,在数据科学和软件工程中扮演了至关重要的角色。它通过训练模型并利用数据来做出预测、发现模式、进行分类,从而帮助人们做出更明智的决策。通常来说,机器学习分为监督学习、无监督学习和强化学习等不同类型,而这些类型又包含了各种算法,如回归、分类、聚类等。机器学习已经被广泛应用于金融、医疗、营销、推荐系统等各个领域,极大地推动了相关行业的发展。
## 1.2 ML.NET 简介
ML.NET 是一个开源、跨平台的机器学习框架,由微软推出。作为 .NET 平台上的一部分,ML.NET 提供了简单易用的 API 和工具,使得 .NET 开发人员能够在他们熟悉的环境中进行机器学习模型的开发和部署。ML.NET 支持监督学习、无监督学习和强化学习,还提供了大量的预构建算法,方便开发者快速搭建模型。
## 1.3 ML.NET 的优势和应用领域
ML.NET 的优势在于它与 .NET 生态系统的完美结合,使得 .NET 开发者能够在不离开自己熟悉的环境下进行机器学习应用的开发。此外,ML.NET 还支持在 Windows、Linux 和 macOS 等多种平台上进行开发和部署。ML.NET 的应用领域涵盖了各种领域,如企业业务、物联网、游戏开发、移动应用以及云服务等。
接下来我们将深入探讨 ML.NET 的基础概念,以及如何应用这些概念来构建机器学习模型。
# 2. ML.NET 基础概念
在本章中,我们将深入探讨 ML.NET 的基础概念,包括数据预处理、特征工程、模型训练与评估等内容。让我们一起来了解 ML.NET 中重要的核心概念以及它们在机器学习中的作用。
#### 2.1 数据预处理
数据预处理是机器学习中至关重要的一步。在 ML.NET 中,数据预处理的任务包括数据清洗、缺失值处理、数据转换等。针对不同类型的数据(数值型、分类型、文本型等),我们需要采取不同的数据预处理方法,以便为模型训练做好准备。
```python
# 示例代码
from sklearn.preprocessing import StandardScaler
from sklearn.impute import SimpleImputer
# 数据缺失值处理
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
# 数据标准化
scaler = StandardScaler()
```
在上面的示例代码中,我们展示了使用 scikit-learn 库进行数据预处理的示例。其中,SimpleImputer 用于处理数据缺失值,而 StandardScaler 则用于数据标准化处理。
#### 2.2 特征工程
特征工程是指对原始数据进行转换,以便更好地适应机器学习模型的特征处理过程。在 ML.NET 中,特征工程包括特征编码、特征选择、特征合成等操作,通过这些操作我们可以提取和构建更有意义的特征,从而提高模型的泛化能力。
```java
// 示例代码
import org.apache.spark.ml.feature.{VectorAssembler, StringIndexer}
// 字符串类型特征编码
val indexer = new StringIndexer()
.setInputCol("category")
.setOutputCol("categoryIndex")
// 向量组装
val assembler = new VectorAssembler()
.setInputCols(Array("categoryIndex", "features"))
.setOutputCol("indexedFeatures")
```
上面的示例代码展示了在 Spark ML 中进行特征工程的示例。其中,StringIndexer 用于对字符串类型的特征进行编码,而 VectorAssembler 则用于将多个特征组装成一个向量。
#### 2.3 模型训练与评估
在 ML.NET 中,模型训练与评估是机器学习流程的关键环节。在进行模型训练时,我们需要选择合适的模型算法,并利用训练数据进行模型参数的学习;而在模型评估阶段,我们需要利用测试数据对模型进行评估,以验证模型的泛化能力和预测性能。
```go
// 示例代码
import (
"github.com/sjwhitworth/golearn/base"
"github.com/sjwhitworth/golearn/evaluation"
"github.com/sjwhitworth/golearn/trees"
)
// 创建决策树模型
cls := trees.NewID3DecisionTree(0.6)
cls.Fit(trainData)
// 模型评估
evaluation := evaluation.GenerateConfusionMatrix(testData, cls)
```
在上述示例中,我们使用了 golearn 包中的决策树模型进行模型训练,并通过混淆矩阵进行了模型评估。
通过以上对 ML.NET 的基础概念的解析,我们可以看到数据预处理、特征工程和模型训练与评估的重要性和必要性。在接下来的章节中,我们将更深入地探讨这些内容,并结合实际案例进行详细讲解。
# 3. 数据集成与处理
在使用ML.NET进行机器学习任务时,数据集成与处理是非常重要的一步,它涉及到数据的获取、清洗、转换以及特征选择等内容。下面我们将详细讨论ML.NET中数据集成与处理的相关内容。
#### 3.1 数据集获取与导入
在使用ML.NET时,我们首先需要准备好训练数据。数据可以来自于各种数据源,比如CSV文件、数据库、云存储等。ML.NET提供了丰富的API来帮助我们轻松地从各种数据源中导入数据。下面是一个从CSV文件中导入数据的示例:
```csharp
// 创建数据读取器
var mlContext = new MLContext();
var dataPath = "path/to/your/data.csv";
var reader = mlContext.Data.CreateTextLoader(new TextLoader.Options
{
Separators = new[] { ',' },
HasHeader = true,
Columns = new[]
{
new TextLoader.Column("Label", DataKind.Single, 0),
new TextLoader.Column("Feature1", DataKind.Single, 1),
new TextLoader.Column("Feature2", DataKind.Single, 2),
// 更多特征列定义
}
});
// 读取数据
var dataView = reader.Load(dataPath);
```
#### 3.2 数据清洗与转换
在导入数据后,通常需要进行数据清洗与转换操作,以使数据适合用于模型训练。这包括处理缺失值、处理异常值、对数据进行标准化等。ML.NET提供了丰富的数据处理API来帮助我们完成这些任务,下面是一个示例:
```csharp
// 数据清洗与转换
var pipeline = mlContext.Transforms.Conversion.MapValueToKey("Label")
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Feature1", "Feature2" }))
.Append(mlContext.Transforms.NormalizeMinMax("Features", "Features"));
// 应用数据处理管道
var transformedData = pipeline.Fit(dataView).Transform(dataView);
```
#### 3.3 数据集划分与特征选择
在数据处理完成后,一般需要将数据集划分为训练集和测试集,并进行特征选择以减少模型训练的复杂度。ML.NET提供了方便的API来完成这些任务,下面是一个示例:
```csharp
// 数据集划分
var trainTestData = mlContext.Data.TrainTestSplit(transformedData, testFraction: 0.2);
var trainData = trainTestData.TrainSet;
var testData = trainTestData.TestSet;
// 特征选择
var featureSelectionPipeline = mlContext.Transforms.DropColumns("Feature1")
.Append(mlContext.Transforms.Concatenate("Features", new[] { "Feature2" }));
var transformedTrainData = featureSelectionPipeline.Fit(trainData).Transform(trainData);
var transformedTestData = featureSelectionPipeline.Transform(testData);
```
通过以上步骤,我们完成了数据集成与处理的过程,为接下来的模型训练做好了准备。
希望这部分内容对您有所帮助。
# 4. 模型开发与实践
在本章中,我们将深入探讨如何在 ML.NET 中进行模型的开发与实践。我们将从选择适当的模型算法开始,然后进行模型的训练与调优,最后介绍如何将训练好的模型部署并应用于实际场景中。
#### 4.1 选择适当的模型算法
在模型开发的初期,选择合适的模型算法是非常重要的。ML.NET 提供了丰富的分类、回归和聚类等算法,包括决策树、逻辑回归、支持向量机、神经网络等。根据任务的性质和数据的特点,我们需要选择最适合的算法来构建模型。
```python
# 示例代码: 选择适当的模型算法
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# 使用随机森林算法
model = RandomForestClassifier()
# 使用逻辑回归算法
model = LogisticRegression()
# 使用支持向量机算法
model = SVC()
```
在实际选择模型算法时,需要考虑数据的特征、样本量、任务类型等因素,综合考虑选择最合适的算法。
#### 4.2 模型训练与调优
选定模型算法后,就需要进行模型的训练和调优。在 ML.NET 中,可以使用交叉验证、网格搜索等技术来对模型进行调优,以提高模型的表现。
```python
# 示例代码: 模型训练与调优
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score, classification_report
# 使用网格搜索进行参数调优
parameters = {'kernel':('linear', 'rbf'), 'C':[1, 10]}
svc = SVC()
clf = GridSearchCV(svc, parameters)
clf.fit(X_train, y_train)
# 对模型进行评估
y_pred = clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
```
在模型训练与调优的过程中,需要关注模型的准确率、召回率、F1 值等指标,以便全面评估模型的表现。
#### 4.3 模型部署与应用
完成模型训练和调优后,接下来就可以将训练好的模型部署到生产环境中,并应用于实际场景中。ML.NET 提供了丰富的部署选项,包括将模型导出为 API、嵌入到应用程序中等。
```python
# 示例代码: 模型部署与应用
import joblib
# 将训练好的模型保存为文件
joblib.dump(clf, 'trained_model.pkl')
# 加载模型并应用
loaded_model = joblib.load('trained_model.pkl')
result = loaded_model.predict(new_data)
```
在实际应用中,需要考虑模型的稳定性、性能等因素,并不断优化模型以适应实际场景的需求。
通过本章的讲解,我们深入了解了在 ML.NET 中进行模型开发与实践的流程,包括选择合适的模型算法、模型训练与调优,以及模型部署与应用。这些步骤将帮助我们构建出高效、稳定的机器学习模型,为实际问题的解决提供有力支持。
# 5. 实战案例分析
在本章中,我们将通过具体的案例分析,深入探讨如何通过ML.NET解决真实问题,并进行数据挖掘与预测分析。我们将结合代码示例和结果说明,帮助读者更好地理解ML.NET在实际应用场景中的应用。
接下来,让我们通过以下实战案例来深入了解ML.NET的应用。
- 5.1 通过ML.NET解决真实问题的案例分析
- 5.2 数据挖掘与预测分析案例解析
- 5.3 将ML.NET应用于实际应用场景的案例探讨
在接下来的内容中,我们将逐一展开对这些案例的详细分析和讨论。
# 6. 展望与总结
在这一部分,我们将探讨ML.NET的未来发展趋势、总结其基础概念与应用,并提出对ML.NET的展望与建议。
#### 6.1 ML.NET 的未来发展趋势
ML.NET作为.NET生态系统中的机器学习框架,在微软的持续投入下,将会继续发展壮大。未来,我们可以期待以下发展趋势:
- **增加更多内置算法与模型**:随着ML.NET的发展,将会不断增加更多的内置算法和模型,丰富用户选择,提供更多灵活性与便利性。
- **优化性能与稳定性**:未来版本将会加强对性能与稳定性的优化,提高训练与推理速度,降低资源消耗,提升整体用户体验。
- **加强与Azure云的集成**:作为微软的产品,ML.NET将会更深入地与Azure云服务相结合,提供更多云端的机器学习解决方案。
#### 6.2 总结ML.NET的基础概念与应用
通过本文的介绍,我们了解到ML.NET作为一个开源的机器学习框架,具有以下基础概念与应用特点:
- **数据预处理**:对原始数据进行清洗、转换,使之适合模型训练的要求。
- **特征工程**:通过特征选择、降维等操作,提取出有价值的特征,优化模型性能。
- **模型训练与评估**:选择合适的算法,进行模型训练与优化,并通过评估指标对模型性能进行评估。
#### 6.3 对ML.NET的展望与建议
针对ML.NET的未来发展,我们提出以下建议与展望:
- **加强社区建设**:积极扩大ML.NET的用户社区,鼓励更多开发者参与贡献,共同推动框架的发展。
- **提高文档与教程质量**:优化ML.NET的官方文档和教程,使之更加易读易懂,方便新手快速上手开发。
- **持续增加应用场景**:不断探索机器学习在不同领域的应用,并提供相应解决方案,拓展ML.NET的应用范围。
通过对ML.NET未来发展的展望与对基础概念与应用的总结,我们可以更好地了解这一机器学习框架的潜力与可能性,期待ML.NET在未来能够取得更大的成就。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在深入探索ML.NET机器学习框架,旨在为读者提供对ML.NET的全面理解和实际运用。从基础概念解析开始,逐步引导读者了解数据准备与清洗在ML.NET中的重要性,以及使用ML.NET进行数据预处理的最佳实践。随后针对模型评估与选择、模型训练与优化策略进行详细讨论,涵盖了经典算法解析,如逻辑回归和支持向量机(SVM),以及深度学习简介。此外,还探讨了在ML.NET中实现文本分类、推荐系统和异常检测等实践内容。本专栏旨在为读者提供系统全面的ML.NET学习手册,使其能够深入理解ML.NET的核心概念、技术细节和实际应用,从而更好地运用机器学习技术解决问题。
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python字典常见问题与解决方案:快速解决字典难题
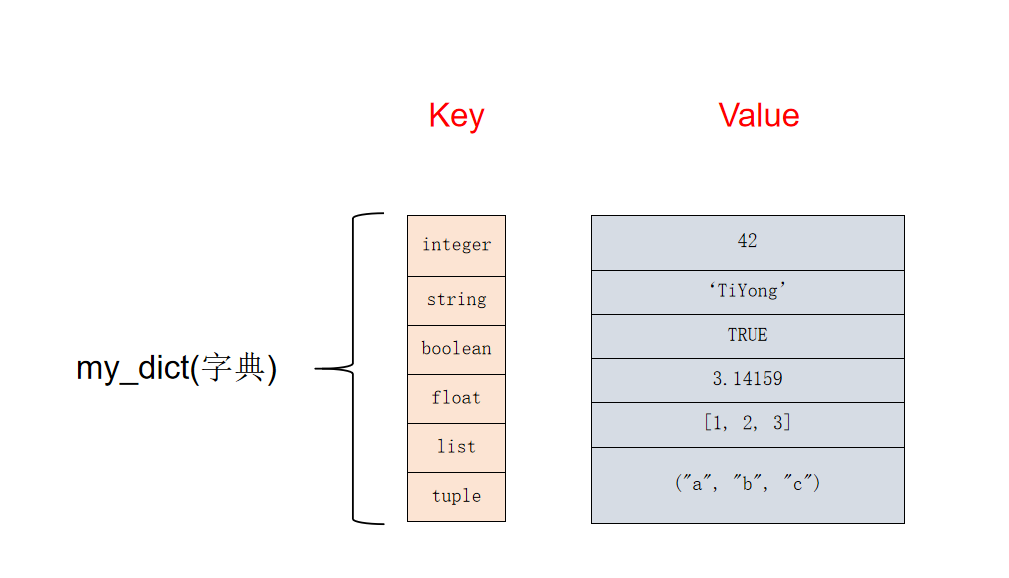
# 1. Python字典简介
Python字典是一种无序的、可变的键值对集合。它使用键来唯一标识每个值,并且键和值都可以是任何数据类型。字典在Python中广泛用于存储和组织数据,因为它们提供了快速且高效的查找和插入操作。
在Python中,字典使用大括号 `{}` 来表示。键和值由冒号 `:` 分隔,键值对由逗号 `,` 分隔。例如,以下代码创建了一个包含键值对的字典:
```py
【实战演练】构建简单的负载测试工具

# 1. 负载测试基础**
负载测试是一种性能测试,旨在模拟实际用户负载,评估系统在高并发下的表现。它通过向系统施加压力,识别瓶颈并验证系统是否能够满足预期性能需求。负载测试对于确保系统可靠性、可扩展性和用户满意度至关重要。
# 2. 构建负载测试工具
### 2.1 确定测试目标和指标
在构建负载测试工具之前,至关重要的是确定测试目标和指标。这将指导工具的设计和实现。以下是一些需要考虑的关键因素:
Python列表操作的扩展之道:使用append()函数创建自定义列表类

# 1. Python列表操作基础
Python列表是一种可变有序的数据结构,用于存储同类型元素的集合。列表操作是Py
OODB数据建模:设计灵活且可扩展的数据库,应对数据变化,游刃有余

# 1. OODB数据建模概述
对象-面向数据库(OODB)数据建模是一种数据建模方法,它将现实世界的实体和关系映射到数据库中。与关系数据建模不同,OODB数据建模将数据表示为对象,这些对象具有属性、方法和引用。这种方法更接近现实世界的表示,从而简化了复杂数据结构的建模。
OODB数据建模提供了几个关键优势,包括:
* **对象标识和引用完整性
Python Excel数据分析:统计建模与预测,揭示数据的未来趋势
# 1. Python Excel数据分析概述**
**1.1 Python Excel数据分析的优势**
Python是一种强大的编程语言,具有丰富的库和工具,使其成为Excel数据分析的理想选择。通过使用Python,数据分析人员可以自动化任务、处理大量数据并创建交互式可视化。
**1.2 Python Excel数据分析库**
Python map函数在代码部署中的利器:自动化流程,提升运维效率

# 1. Python map 函数简介**
map 函数是一个内置的高阶函数,用于将一个函数应用于可迭代对象的每个元素,并返回一个包含转换后元素的新可迭代对象。其语法为:
```python
map(function, iterable)
```
其中,`function` 是要应用的函数,`iterable` 是要遍历的可迭代对象。map 函数通
Python脚本调用与区块链:探索脚本调用在区块链技术中的潜力,让区块链技术更强大

# 1. Python脚本与区块链简介**
**1.1 Python脚本简介**
Python是一种高级编程语言,以其简洁、易读和广泛的库而闻名。它广泛用于各种领域,包括数据科学、机器学习和Web开发。
**1.2 区块链简介**
区块链是一种分布式账本技术,用于记录交易并防止篡改。它由一系列称为区块的数据块组成,每个区块都包含一组交易和指向前一个区块的哈希值。区块链的去中心化和不可变性使其
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】大规模机器学习:Dask实现分布式计算

# 2.1 Dask的架构和组件
### 2.1.1 Scheduler和Worker
Dask的分布式计算架构主要由两个组件组成:Scheduler和Worker。
- **Scheduler**:负责管理任务调度、资源分配和任务监控。它接收来自客户端的计算任务,并将其分解为更小的子任务
【实战演练】综合自动化测试项目:单元测试、功能测试、集成测试、性能测试的综合应用

# 2.1 单元测试框架的选择和使用
单元测试框架是用于编写、执行和报告单元测试的软件库。在选择单元测试框架时,需要考虑以下因素:
* **语言支持:**框架必须支持你正在使用的编程语言。
* **易用性:**框架应该易于学习和使用,以便团队成员可以轻松编写和维护测试用例。
* **功能性:**框架应该提供广泛的功能,包括断言、模拟和存根。
* **报告:**框架应该生成清
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )