版本控制工具介绍:Git基础和工作流程
发布时间: 2024-03-20 13:29:03 阅读量: 45 订阅数: 22 

Git版本控制工具介绍
# 1. 版本控制工具概述
版本控制工具在软件开发中扮演着至关重要的角色。它们能够跟踪文件的更改,使团队协作更加高效,同时也能够帮助开发人员更好地管理代码和项目。在本章中,我们将介绍版本控制工具的概念和重要性,以及一些常见的版本控制工具的简介,同时解释为何Git成为了如今最流行的版本控制工具之一。接下来,让我们深入了解这一主题。
# 2. Git基础
Git是目前最流行的分布式版本控制系统之一,它具有强大的版本控制能力,灵活的分支管理和高效的协作功能。在这一章节中,我们将重点介绍Git的基础知识,包括安装配置、基本概念解析、常用命令介绍和代码回滚与撤销等内容。
### 2.1 Git的安装和配置
首先,我们需要在本地计算机上安装Git并进行基本的配置。以下是在Linux系统上安装Git的示例代码:
```bash
sudo apt update
sudo apt install git
git --version
git config --global user.name "Your Name"
git config --global user.email "your_email@example.com"
```
这段代码演示了如何在Linux系统上安装Git,并配置用户信息。通过`git --version`命令可以查看安装的Git版本。在实际应用中,也可以根据不同操作系统的安装方法进行操作。
### 2.2 Git基本概念解析
Git中有一些基本概念是需要理解的,比如仓库、提交、分支等。仓库(Repository)是Git用来存储项目的地方,提交(Commit)是保存工作成果的操作,而分支(Branch)则是用来管理不同功能或版本的代码。理解这些概念可以更好地使用Git进行版本控制。
### 2.3 Git常用命令介绍
在日常使用Git时,有一些常用命令是必须掌握的,比如`git add`用于将文件添加到暂存区,`git commit`用于将暂存区的文件提交到本地仓库,`git push`用于将本地提交推送到远程仓库等。这些命令可以帮助我们有效地管理代码版本。
### 2.4 Git代码回滚与撤销
有时候我们需要回滚或撤销一些操作,Git提供了相应的命令来实现这个功能。例如,`git reset`可以回滚至某个提交版本,`git checkout`可以撤销对某个文件的修改,`git revert`可以撤销某个提交并生成新的提交等。合理运用这些命令可以帮助我们更好地维护代码版本的稳定性。
通过学习Git的基础知识,我们可以更好地利用这一强大的版本控制工具来管理和协作代码。掌握Git的基本概念和常用命令不仅能提高工作效率,还能减少代码冲突和错误,从而更好地保障代码质量和团队协作效率。
# 3. Git工作流程
版本控制工具Git的工作流程是开发过程中非常重要的一部分,它涉及到本地仓库和远程仓库的关系,团队协作,以及不同的工作流程模型。深入了解Git的工作流程可以帮助团队更高效地协作开发,管理代码变更。
### 3.1 本地仓库和远程仓库的关系
在使用Git时,每个开发者都会有一个本地仓库(Local Repository),用于存储代码的修改记录和历史。而远程仓库(Remote Repository)则是团队共享的中央仓库,用于协作开发和代码的备份。本地仓库和远程仓库之间通过Git命令进行数据同步,开发者可以将本地的修改推送到远程仓库,或者将远程仓库的更新拉取到本地仓库。
### 3.2 分布式版本控制的优势
Git是一种分布式版本控制系统,与集中式版本控制系统相比,具有诸多优势。分布式版本控制系统允许每个开发者在本地拥有完整的代码仓库,可以独立工作,即使没有网络连接也能进行代码修改和提交。另外,分布式系统不依赖单点故障,灵活性更高,更适合团队协作和开发。
### 3.3 如何在团队中协作使用Git
团队协作是Git的一个重要应用场景,为了保证团队成员之间协作顺畅,需要遵循一些最佳实践:
- 每个团队成员应当熟练使用Git的基本命令,了解分支管理与代码合并的操作;
- 使用分支进行功能开发,保持主分支(通常是`master`)的稳定性;
- 定期进行代码合并,避免分支较长时间的孤岛状态;
- 处理代码冲突时,应当及时解决,保持团队协作的高效性。
### 3.4 掌握常见的Git工作流程模型
在团队协作中,常见的Git工作流程模型有集中式工作流、功能分支工作流、Git Flow等。不同的工作流程适用于不同的团队和项目需求,其中Git Flow工作流程广泛应用于中大型团队和项目中,结合特定的分支管理策略,能够有效管理复杂的代码变更和发布流程。
以上是Git工作流程章节的内容,希望能对您有所帮助。
# 4. Git高级应用
版本控制工具Git在软件开发中扮演着至关重要的角色,除了基本的提交、拉取、推送等功能外,Git还提供了许多高级应用来帮助开发团队更高效地管理项目代码。本章将深入探讨Git的高级应用,包括分支管理策略、标签的使用、子模块和子树的应用,以及Git的钩子机制与自定义操作。
### 4.1 Git分支管理策略
在多人协作开发的项目中,合理的分支管理策略可以有效地提高团队的工作效率。Git提供了各种分支管理策略,如主线分支、特性分支、发布分支等。其中,主线分支通常是`master`,用于保存稳定的代码版本;特性分支则用于开发新功能,每个功能对应一个特性分支;发布分支则用于发布正式版本,通常从特性分支中合并代码生成。常见的分支管理流程包括:
- **主线开发流**:所有开发都在同一个分支上进行,适用于小型项目或个人开发。
- **特性分支开发流**:每个新功能在单独的特性分支开发,开发完成后合并到主线分支。
- **Git Flow流**:包括主线分支、开发分支、特性分支、发布分支和修复分支,适用于中大型项目。
通过合理选择和组合这些分支管理策略,可以更好地组织团队的开发工作,并确保代码的质量和稳定性。
### 4.2 Git标签的使用
除了分支,Git还支持标签的使用。标签是一个指向特定提交的指针,通常用于标记版本发布或重要里程碑。Git的标签分为轻量标签和附注标签两种:
- **轻量标签**:仅包含提交的校验和,类似于分支,但不会改变仓库状态。
- **附注标签**:可以包含标签者的信息、标签消息等,更丰富,推荐在发布版本时使用。
使用标签可以方便开发人员快速定位重要版本,也有助于团队合作和版本控制管理。
### 4.3 Git的子模块和子树
Git还提供了子模块(Submodule)和子树(Subtree)的功能,用于管理项目中的子项目或库文件。通过子模块和子树,可以将其他Git仓库作为当前仓库的子目录引入,便于版本管理和协作开发。
使用子模块可以避免将外部项目完全合并到当前仓库中,减轻代码仓库的维护压力,同时保持子项目的独立性。而子树则更倾向于将外部项目完全并入当前项目,使其成为当前项目的一部分,适用于需要频繁修改子项目代码的场景。
### 4.4 Git的钩子机制与自定义操作
Git的钩子(hooks)是一种可自定义的脚本功能,可以在特定的Git操作时触发执行。常见的Git钩子包括`pre-commit`、`post-commit`、`pre-push`等,可以在提交之前检查代码格式、在推送之前运行测试等操作。
通过自定义Git钩子脚本,开发团队可以根据项目的实际需求添加额外的操作,实现自动化测试、代码审查等功能,进一步提升项目质量和开发效率。
在本章中,我们深入探讨了Git的高级应用,包括分支管理策略、标签的使用、子模块和子树,以及Git的钩子机制与自定义操作。这些高级功能的合理应用可以帮助团队更好地组织和管理项目代码,提升开发效率和代码质量。
# 5. Git与持续集成
持续集成(Continuous Integration)是一种软件开发实践,通过频繁地将代码集成到共享存储库中,然后自动构建和测试代码,从而快速发现和解决集成错误。Git作为流行的版本控制工具,在持续集成中发挥着重要作用。本章将介绍Git与持续集成的相关内容。
### 5.1 Git与持续集成工具的集成
在持续集成中,通常会使用一些自动化构建工具(如Jenkins、Travis CI、CircleCI等)来实现代码的自动化构建、测试和部署。这些持续集成工具与Git集成紧密,可以轻松地与Git仓库进行交互,并可以根据Git提交的变化执行相应的构建和测试任务。
#### 场景说明:
假设我们使用Jenkins作为持续集成工具,需要将Git仓库与Jenkins进行集成,实现代码提交后自动触发Jenkins构建任务。
#### 代码示例(Jenkins Pipeline脚本):
```groovy
pipeline {
agent any
stages {
stage('Git Checkout') {
steps {
git branch: 'main', url: 'https://github.com/your-repo.git'
}
}
stage('Build') {
steps {
sh 'mvn clean package'
}
}
stage('Test') {
steps {
sh 'mvn test'
}
}
stage('Deploy') {
steps {
sh 'bash deploy.sh'
}
}
}
}
```
#### 代码说明:
- 该Pipeline定义了一系列阶段(stages),包括从Git中检出代码、构建、测试和部署。
- `agent any`指定任何可用的代理来运行Pipeline。
- 在`Git Checkout`阶段中,通过Git插件从指定的仓库中检出代码。
- `Build`阶段使用Maven进行项目构建。
- `Test`阶段运行单元测试。
- `Deploy`阶段执行部署脚本。
#### 结果说明:
当代码提交到Git仓库时,Jenkins会根据定义的Pipeline自动触发构建任务,执行构建、测试和部署操作,实现持续集成的自动化流程。
### 5.2 使用Git进行自动化部署
除了与持续集成工具集成外,Git本身也可以用于实现自动化部署。通过Git Hooks(钩子)机制,可以在代码提交到特定分支时触发自定义的部署脚本,实现自动部署应用程序到生产环境。
#### 场景说明:
假设我们有一个部署脚本`deploy.sh`,需要在代码提交到`main`分支时自动执行该脚本进行部署。
#### Git Hooks示例:
创建名为`post-receive`的钩子文件,位于Git仓库的`hooks`目录下:
```bash
#!/bin/bash
while read oldrev newrev refname
do
branch=$(git rev-parse --symbolic --abbrev-ref $refname)
if [ "$branch" == "main" ]; then
bash deploy.sh
fi
done
```
#### 结果说明:
当有新的提交推送到Git仓库时,Git会触发`post-receive`钩子,检查提交的分支,如果是`main`分支,则执行部署脚本`deploy.sh`,实现自动化部署的过程。
### 5.3 Git在DevOps实践中的应用
DevOps是一种将软件开发(Dev)和IT运维(Ops)相结合的文化、实践和工具,旨在加速软件交付和提高软件质量。Git作为版本控制工具在DevOps实践中扮演着重要角色,通过持续集成、持续交付等实践,帮助团队更高效地开发和交付软件。
以上是Git与持续集成相关的内容,包括与持续集成工具的集成、使用Git进行自动化部署以及Git在DevOps实践中的应用。通过合理运用Git工具和流程,可以提升团队的开发效率和软件质量,推动项目顺利进行。
# 6. Git最佳实践与故障处理
在软件开发过程中,Git作为一个强大的版本控制工具,能够有效地帮助团队协作、版本管理和代码回滚等操作。然而,要充分发挥Git的作用,需要遵循一些最佳实践,并学会处理可能出现的故障情况。
### 6.1 Git最佳实践分享
在使用Git时,有一些最佳实践可以帮助团队更高效地使用版本控制工具,提高工作效率和代码质量。以下是一些Git最佳实践的分享:
1. **合理使用分支**:合理使用Git分支可以使团队成员同时开发不同功能,将代码隔离开来,降低冲突的概率。主分支一般用来部署稳定版本,开发新功能和修复bug可在其他分支上进行。
2. **频繁提交代码**:频繁提交代码可以帮助团队成员快速了解项目进展,及时发现问题并进行修复。推荐将每次提交的内容控制在一个逻辑单元内,保持提交的清晰和有意义。
3. **代码审查**:代码审查是保证代码质量的有效手段。通过Git提供的Pull Request功能,可以进行代码审查并及时反馈意见,提升团队合作和代码质量。
4. **定期合并主分支**:定期合并主分支可以确保团队开发的功能与主线保持同步,避免出现大量冲突。建议团队成员每天至少合并一次主分支。
### 6.2 解决常见的Git操作问题
在使用Git过程中,可能会遇到一些常见的操作问题,例如丢失提交、错误合并等。以下是一些常见问题的解决方法:
1. **丢失提交**:如果不小心丢失了提交,可以通过`git reflog`命令查看历史操作记录,找回丢失的提交ID,然后使用`git checkout <commit ID>`进行切换。
2. **错误合并**:如果发生了错误的合并,可以使用`git reset --hard HEAD~1`回退到上一个提交,然后重新进行合并操作。
### 6.3 避免和解决Git冲突
在团队协作开发过程中,经常会遇到代码冲突的情况。处理Git冲突的方法如下:
1. **拉取最新代码**:在提交代码之前,先拉取最新的代码并解决可能的冲突,确保代码同步。
2. **手动解决冲突**:当发生冲突时,Git会提示冲突的文件,手动解决冲突后使用`git add`将修改后的文件标记为已解决。
### 6.4 如何处理Git仓库的损坏情况
如果出现Git仓库损坏的情况,可以尝试以下方法进行修复:
1. **使用Git fsck命令**:通过`git fsck --full`命令检查仓库中的错误对象,并尝试修复损坏的对象。
2. **备份和恢复**:在修复之前,建议先备份仓库数据,然后尝试使用备份数据进行恢复,避免造成更大的损失。
以上是关于Git最佳实践与故障处理的内容,希望对你在使用Git时有所帮助!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏名为“DevOps工具链与持续集成”,涵盖了广泛且深入的主题,旨在帮助读者全面了解DevOps文化与持续集成的重要性和实践方法。从DevOps的概念与历史发展,到持续集成与CI/CD流程的优化,再到版本控制工具如Git的基础与高级用法,以及自动化构建工具、容器化技术、容器编排工具等的介绍与实践,专栏覆盖了全面的知识体系。读者不仅可以学习到如何使用具体工具如Jenkins、Docker、Kubernetes等来构建自己的持续集成与部署流程,还能了解到相关的安全性管理、测试环境搭建、日志管理与监控等方面的最佳实践。通过该专栏,读者将获得丰富的知识和实践经验,为构建高效的DevOps工作流程提供强有力的支持。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【个性化控制仿真工作流构建】:EDA课程实践指南与技巧

# 摘要
本文介绍了电子设计自动化(EDA)课程中个性化控制仿真领域的概述、理论基础、软件工具使用、实践应用以及进阶技巧。首先,概述了个性化控制仿真的重要性和应用场景。随后,深入探讨了控制系统的理论模型,仿真工作流的构建原则以及个性化控制仿真的特点。接着,重点介绍EDA仿真软件的分类、安装、配置和操作。进一步地,通过实践应用章节,本文阐述了如何基于EDA软件搭建仿真工作流,进行仿真结果的个性化调整与优
计算机图形学中的阴影算法:实现逼真深度感的6大技巧
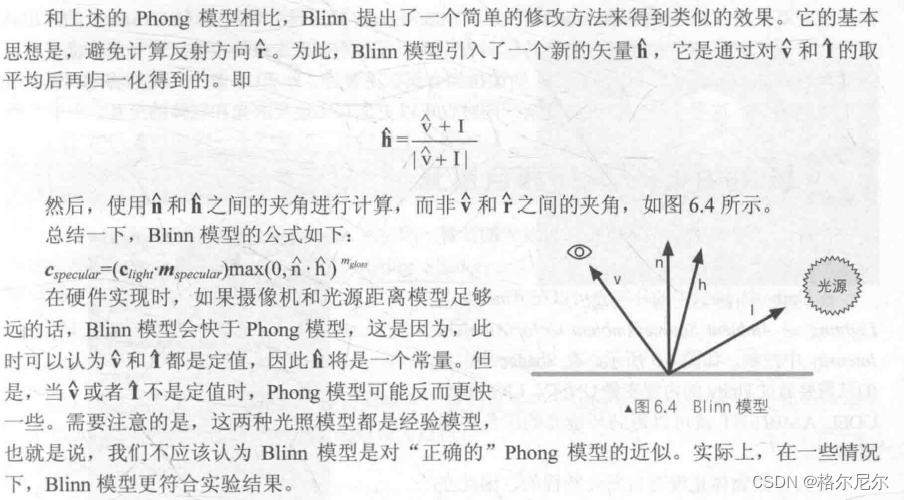
# 摘要
计算机图形学中,阴影效果是增强场景真实感的重要手段,其生成和处理技术一直是研究的热点。本文首先概述了计算机图形学中阴影的基本概念与分类,随后介绍了阴影生成的基础理论,包括硬阴影与软阴影的定义及其在视觉中的作用。在实时渲染技术方面,本文探讨了光照模型、阴影贴图、层次阴影映射技术以及基于GPU的渲染技术。为了实现逼真的深度感,文章进一步分析了局部光照模型与阴影结合的方法、基于物理的渲染以及动态模糊阴
网络配置如何影响ABB软件解包:专家的预防与修复技巧
# 摘要
本文系统地探讨了网络配置与ABB软件解包的技术细节和实践技巧。首先,我们介绍了网络配置的基础理论,包括网络通信协议的作用、网络架构及其对ABB软件解包的影响,以及网络安全和配置防护的重要性。接着,通过网络诊断工具和方法,我们分析了网络配置与ABB软件解包的实践技巧,以及在不同网络架构中如何进行有效的数据传输和解包。最后,我们探讨了预防和修复网络配置问题的专家技巧,以及网络技术未来的发展趋势,特别是在自动化和智能化方面的可能性。
# 关键字
网络配置;ABB软件解包;网络通信协议;网络安全;自动化配置;智能化管理
参考资源链接:[如何应对ABB软件解包失败的问题.doc](http
磁悬浮小球系统稳定性分析:如何通过软件调试提升稳定性
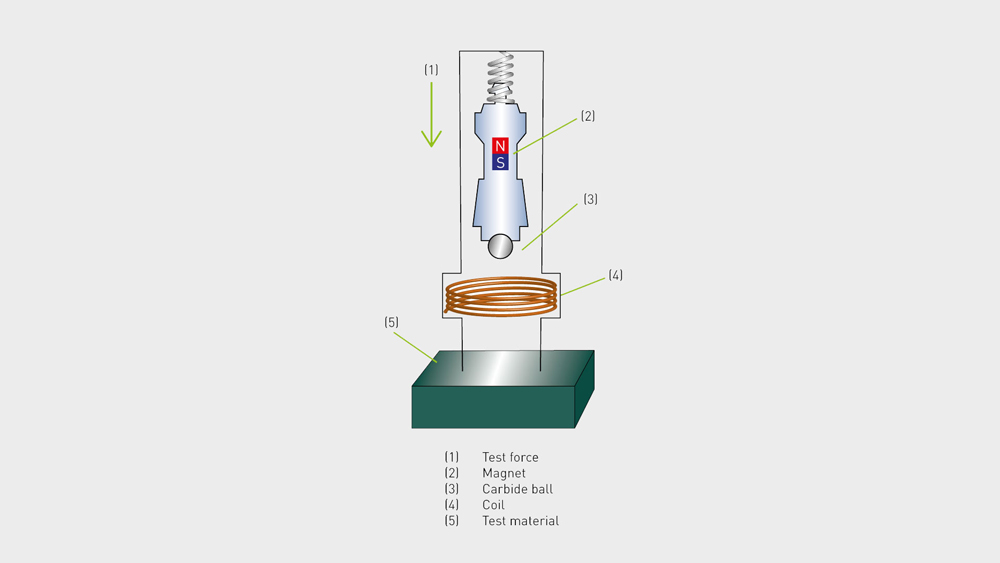
# 摘要
本文首先介绍了磁悬浮小球系统的概念及其稳定性理论基础。通过深入探讨系统的动力学建模、控制理论应用,以及各种控制策略,包括PID控制、神经网络控制和模糊控制理论,本文为理解和提升磁悬浮小球系统的稳定性提供了坚实的基础。接着,本文详细阐述了软件调试的方法论,包括调试环境的搭建、调试策略、技巧以及工具的使用和优化。通过对实践案例的分析,本文进一步阐释了稳定性测试实验、软件调试过程记录和系统性能评估的重要性。最后,本文提出了提升系统稳
DSPF28335 GPIO定时器应用攻略:实现精确时间控制的解决方案

# 摘要
本论文重点介绍DSPF28335 GPIO定时器的设计与应用。首先,概述了定时器的基本概念和核心组成部分,并深入探讨了与DSPF28335集成的细节以及提高定时器精度的方法。接着,论文转向实际编程实践,详细说明了定时器初始化、配置编程以及中断服务程序设计。此外,分析了精确时间控制的应用案例,展示了如何实现精确延时功能和基于定时器的PWM
深入RML2016.10a字典结构:数据处理流程优化实战

# 摘要
RML2016.10a字典结构作为数据处理的核心组件,在现代信息管理系统中扮演着关键角色。本文首先概述了RML2016.10a字典结构的基本概念和理论基础,随后分析了其数据组织方式及其在数据处理中的作用。接着,本文深入探讨了数据处理流程的优化目标、常见问题以及方法论,展示了如何
【MAX 10 FPGA模数转换器硬件描述语言实战】:精通Verilog_VHDL在转换器中的应用
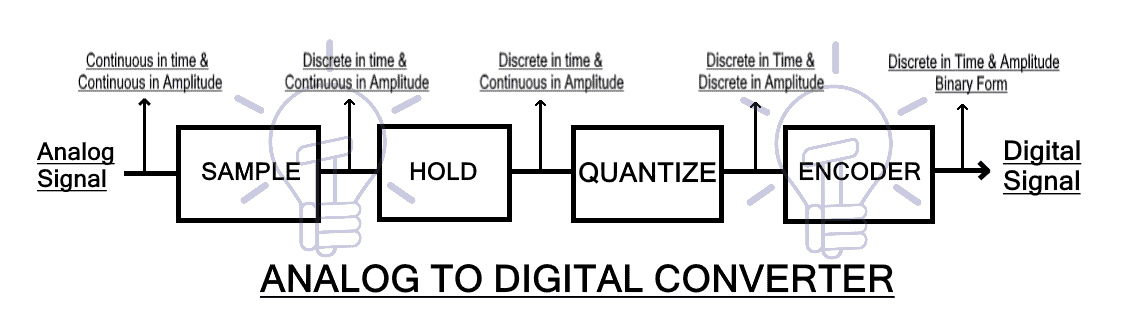
# 摘要
本文主要探讨了FPGA模数转换器的设计与实现,涵盖了基础知识、Verilog和VHDL语言在FPGA设计中的应用,以及高级应用和案例研究。首先,介绍了FPGA模数转换器的基础知识和硬件设计原理,强调了硬件设计要求和考量。其次,深入分析了Verilog和VHDL语言在FPGA设计中的应用,包括基础语法、模块化设计、时序控制、仿真测试、综合与优化技巧,以及并发和
【Typora与Git集成秘籍】:实现版本控制的无缝对接
# 摘要
本文主要探讨了Typora与Git的集成方法及其在文档管理和团队协作中的应用。首先,文章介绍了Git的基础理论与实践,涵盖版本控制概念、基础操作和高级应用。随后,详细解析了Typora的功能和配置,特别是在文档编辑、界面定制和与其他工具集成方面的特性。文章深入阐述了如何在Typora中配置Git,实现文档的版本迭代管理和集成问题的解决。最后,通过案例分
零基础配置天融信负载均衡:按部就班的完整教程
.webp)
# 摘要
天融信负载均衡技术在现代网络架构中扮演着至关重要的角色,其作用在于合理分配网络流量,提高系统可用性及扩展性。本文首先对负载均衡进行概述,介绍了其基础配置和核心概念。随后深入探讨了负载均衡的工作原理、关键技术以及部署模式,包括硬件与软件的对比和云服务的介绍。在系统配置与优化章节中,本文详细描述了配置流程、高可用性设置、故障转移策略、性能监控以及调整方法。此外,高级功能与实践应用章节涉及内容交换、
Ansoft HFSS进阶:掌握高级电磁仿真技巧,优化你的设计

# 摘要
本文系统地介绍了Ansoft HFSS软件的使用,从基础操作到高级仿真技巧,以及实践应用案例分析,最后探讨了HFSS的扩展应用与未来发展趋势。第一章为读者提供了HFSS的基础知识与操作指南。第二章深入探讨了电磁理论基础,包括电磁波传播和麦克斯韦方程组,以及HFSS中材料特性设置和网格划分策略。第三章覆盖了HFSS的高级仿真技巧,如参数化建模、模式驱动求解器和多物
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )