




C++模板与异构编程:融合不同编程范式的高级技术


C++模板与泛型编程入门教程:代码重用与类型安全
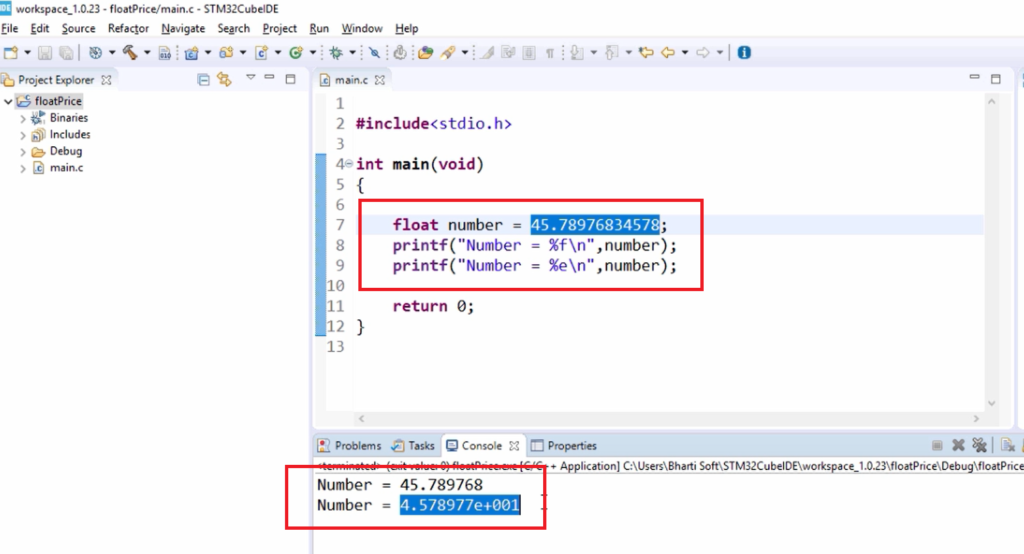
1. C++模板编程概述
1.1 模板编程的重要性
在C++中,模板编程是一种强大的特性,它允许程序员编写与数据类型无关的通用代码。这种编程范式在提高代码复用性、保持类型安全以及优化性能方面起到了关键作用。模板作为C++的核心特性之一,广泛应用于库和框架的设计中,尤其是在STL(标准模板库)的实现上。
1.2 模板编程的起源
模板的概念最早在1988年由Niklaus Wirth引入,而后在C++中得到了彻底的实现。Bjarne Stroustrup,C++的创造者,将模板视为其语言设计的一个重要部分,因此,模板编程成为了C++最为人称道的特性之一。
1.3 模板编程的基本组成
模板编程主要由以下组件构成:函数模板、类模板以及模板特化。函数模板允许函数独立于特定的数据类型;类模板则允许创建与数据类型无关的类结构;模板特化提供了为特定情况定制模板行为的能力。本章节将对这些基础概念进行介绍,为后续章节的深入学习打下基础。
2. 模板的基本原理和语法
2.1 模板的类型和特化
2.1.1 函数模板和类模板
函数模板和类模板是C++中实现泛型编程的核心工具。函数模板允许程序员定义一个函数,它可以用不同的数据类型进行调用。类模板则用于创建可以使用多种数据类型实例化的类。

在上述示例中,max是一个函数模板,它可以接受任意类型的参数,并返回最大值。Stack是一个类模板,它可以创建用于存储任何类型数据的栈。
2.1.2 模板特化的概念和应用
模板特化允许程序员为特定类型提供特殊的模板定义。这在处理特定类型的优化或者当通用模板不能满足特定类型需求时非常有用。
特化可以是全特化,也可以是偏特化。全特化是为所有模板参数提供具体类型或值,而偏特化则是为部分模板参数提供具体类型或值。
2.2 模板参数和模板重载
2.2.1 模板参数的类型和使用
模板参数可以是类型参数、非类型参数和模板模板参数。类型参数使用typename或class关键字指定,非类型参数使用具体类型指定,而模板模板参数则是模板化的模板。
模板参数在模板编写时至关重要,它们提供了泛型编程的灵活性。
2.2.2 函数模板重载的规则和示例
函数模板重载允许创建多个具有相同名称但参数列表不同的函数模板。编译器根据传入的参数类型来决定调用哪个模板。
重载函数模板的参数列表必须不同,否则会导致编译错误。
2.2.3 类模板特化与重载的区别
类模板特化是为特定类型提供特定实现,而类模板重载通常指的是定义多个具有相同名称但不同模板参数的类模板。
特化和重载在类模板中的应用需要严格区分,避免编译错误。
2.3 高级模板技术
2.3.1 模板元编程的概念和技巧
模板元编程是C++中一种利用模板进行编译时计算的技术。它允许在编译时执行复杂的算法,生成优化的代码。
模板元编程可以用来生成编译时的序列、编译时的类型检查、高效的计算以及泛型编程模式的实现。
2.3.2 SFINAE(Substitution Failure Is Not An Error)原理
SFINAE是一种C++编译时特性,它允许在模板实例化时发生替换失败时,并不将该实例化立即视为错误,而是忽略该实例化继续寻找其他可能匹配的模板。
SFINAE可以用于实现重载决策、成员存在性检查等。
2.3.3 抽象返回类型(decltype)和自动类型推导(auto)
在模板编程中,decltype和auto用于抽象返回类型和自动类型推导,这使得模板能够更加灵活地处理不同类型的返回值。
通过使用decltype和auto,模板可以适应不同的表达式返回类型,而无需程序员明确指定类型。
以上便是C++模板编程中的基本原理和语法,它们是构建通用、灵活和高性能C++应用程序的基础。通过本章节的介绍,我们已经深入了解了模板的类型、特化、参数以及高级技术,为以后的深入学习和实践打下了坚实的基础。
3. 异构编程与硬件加速
3.1 异构计算概述
3.1.1 CPU与GPU的协同工作
异构计算的核心是整合不同类型的计算单元以发挥各自的性能优势。在现代计算机架构中,CPU和GPU是两种最重要的计算单元。CPU擅长处理复杂的逻辑任务,能够高效地执行高度顺序化的操作。而GPU则拥有数以百计的核心,适合执行大规模并行计算任务。通过将任务合理分配给CPU和GPU,可以大幅度提升应用程序的计算性能。
CPU-GPU协同工作通常在操作系统层面进行调度。CPU负责程序的主控制流、数据预处理和后处理工作,而将计算密集型任

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方
Cygwin系统监控指南:性能监控与资源管理的7大要点
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
【T-Box能源管理】:智能化节电解决方案详解
【精准测试】:确保分层数据流图准确性的完整测试方法


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















