Python AST入门指南:7天精通代码的抽象表示
发布时间: 2024-10-13 04:47:26 阅读量: 98 订阅数: 35 

Python 编程入门指南:从环境搭建到第一个程序
# 1. Python AST概述
Python AST(抽象语法树)是Python代码的树状结构表示,它在程序的执行过程中扮演着至关重要的角色。本章节将深入探讨Python AST的定义、作用以及它在Python编程中的应用实例。
## Python AST的定义和作用
Python AST是源代码的内部表示,由Python解释器在执行代码前自动构建。它将代码分解为节点,每个节点代表源代码中的一个构造,如语句、表达式、函数定义等。
### AST在Python编程中的应用实例
一个常见的应用实例是代码格式化工具,如`black`和`autopep8`,它们依赖于AST来理解代码结构并进行重构。此外,AST也被用于代码质量检查工具,如`flake8`和`mypy`,它们通过分析AST来识别潜在的错误和代码风格问题。
## Python AST与编译原理的关系
AST是编译原理中的一个核心概念,它在Python解释器的编译阶段扮演着桥梁的角色,连接源代码和底层字节码。理解AST不仅有助于编写更高效的代码,还能帮助开发者深入理解Python语言的工作原理。
# 2. 理解Python AST的结构
在本章节中,我们将深入探讨Python AST(Abstract Syntax Tree,抽象语法树)的内部结构。我们首先会介绍AST节点的类型和属性,然后分析Python语法结构在AST中的映射,最后讲解解析代码生成AST的过程。
## 2.1 AST节点的类型和属性
### 2.1.1 常见AST节点的分类
Python的AST是由各种不同的节点构成的,每个节点代表源代码中的一个语法结构。这些节点可以分为多种类型,例如表达式节点、语句节点、函数定义节点等。以下是一些常见节点的分类:
- **表达式节点**:这些节点代表表达式,如二元操作符(加、减、乘等)、一元操作符(正、负)、变量引用、函数调用、常量等。
- **语句节点**:这些节点代表语句,如赋值语句、导入语句、return语句、if语句等。
- **函数定义节点**:这些节点代表函数定义,包括函数名、参数列表、函数体等。
### 2.1.2 节点属性的含义和用法
每个AST节点都有其特定的属性,这些属性提供了节点的详细信息。例如,表达式节点通常有一个`value`属性来存储表达式的值,而语句节点可能有一个`targets`属性来存储赋值的目标。以下是一些常见的属性及其用法:
- **value**:用于存储节点的值,如数字、字符串、变量名等。
- **targets**:用于存储赋值的目标,可以是一个节点列表。
- **children**:子节点列表,用于存储直接子节点。
- **lineno** 和 **col_offset**:分别表示节点在源代码中的行号和列号,对于调试和错误处理非常有用。
#### 代码块示例
```python
import ast
# 解析一段Python代码
code = """
def my_function(x):
return x + 1
# 解析代码并打印AST节点类型和属性
parsed_code = ast.parse(code)
for node in ast.walk(parsed_code):
print(f"Node Type: {type(node).__name__}, Attributes: {node._attributes}")
```
在上述代码中,我们首先导入了`ast`模块,然后解析了一段简单的Python代码。通过遍历AST节点并打印出每个节点的类型和属性,我们可以更好地理解AST节点的结构。
#### 逻辑分析和参数说明
在上面的代码块中,我们使用`ast.parse()`函数来解析一段Python代码,并通过`ast.walk()`函数遍历AST中的所有节点。对于每个节点,我们打印出它的类型和属性列表。`type(node).__name__`用于获取节点的类型名称,而`node._attributes`是一个包含节点所有属性的集合。
## 2.2 Python语法结构在AST中的映射
### 2.2.1 表达式、语句和函数定义的AST表示
Python语法结构在AST中的表示与其在源代码中的形式紧密相关。以下是一些常见的语法结构及其在AST中的表示:
- **表达式**:例如,`a + b` 在AST中会被表示为一个`BinOp`节点,其`op`属性是一个操作符节点,`left`和`right`属性是子表达式节点。
- **语句**:例如,`a = 1` 在AST中会被表示为一个`Assign`节点,其`targets`属性是一个包含变量名节点的列表,`value`属性是右侧表达式节点。
- **函数定义**:例如,`def my_function(x): return x + 1` 在AST中会被表示为一个`FunctionDef`节点,其`name`属性是函数名,`args`属性是参数列表节点,`body`属性是函数体中的语句列表。
### 2.2.2 控制流语句和异常处理的AST结构
控制流语句和异常处理在AST中也有其特定的表示:
- **if语句**:在AST中,`if`语句会被表示为一个`If`节点,其`test`属性是条件表达式节点,`body`属性是真值块中的语句列表,`orelse`属性是假值块中的语句列表。
- **异常处理**:在AST中,`try`语句会被表示为一个`Try`节点,其`body`属性是`try`块中的语句列表,`handlers`属性是异常处理器列表。
#### 代码块示例
```python
# 示例代码
code = """
try:
x = 1 / 0
except ZeroDivisionError:
print("Cannot divide by zero")
# 解析并打印AST节点
parsed_code = ast.parse(code)
for node in ast.walk(parsed_code):
print(f"Node Type: {type(node).__name__}, Attributes: {node._attributes}")
```
在上述代码块中,我们解析了一个包含`try`语句的Python代码,并打印出AST中的节点类型和属性。通过这种方式,我们可以观察到控制流语句和异常处理在AST中的结构。
#### 逻辑分析和参数说明
在这个代码块中,我们使用`ast.parse()`函数来解析包含`try`语句的Python代码,并通过遍历AST中的所有节点来打印节点的类型和属性。这有助于我们理解控制流语句和异常处理是如何在AST中表示的。
## 2.3 解析代码生成AST的过程
### 2.3.1 解析器的工作原理
Python的解析器工作原理是将源代码转换成AST。这个过程涉及两个主要步骤:
1. **词法分析**:将源代码字符串分解成一系列的标记(tokens)。例如,标识符、关键字、操作符、括号等。
2. **语法分析**:根据Python的语法规则,将标记组织成一个AST。
### 2.3.2 从源码到AST的转换实例
为了更深入地理解从源码到AST的转换过程,我们可以使用一个简单的例子来演示这一过程。
#### 代码块示例
```python
import ast
# 示例代码
code = "a = 1"
# 解析代码
parsed_code = ast.parse(code)
# 打印AST
print(ast.dump(parsed_code, indent=4))
```
#### 逻辑分析和参数说明
在上述代码块中,我们使用`ast.parse()`函数来解析一段简单的赋值语句,并使用`ast.dump()`函数打印出生成的AST。`indent=4`参数用于美化输出格式,使得AST的结构更易于阅读。
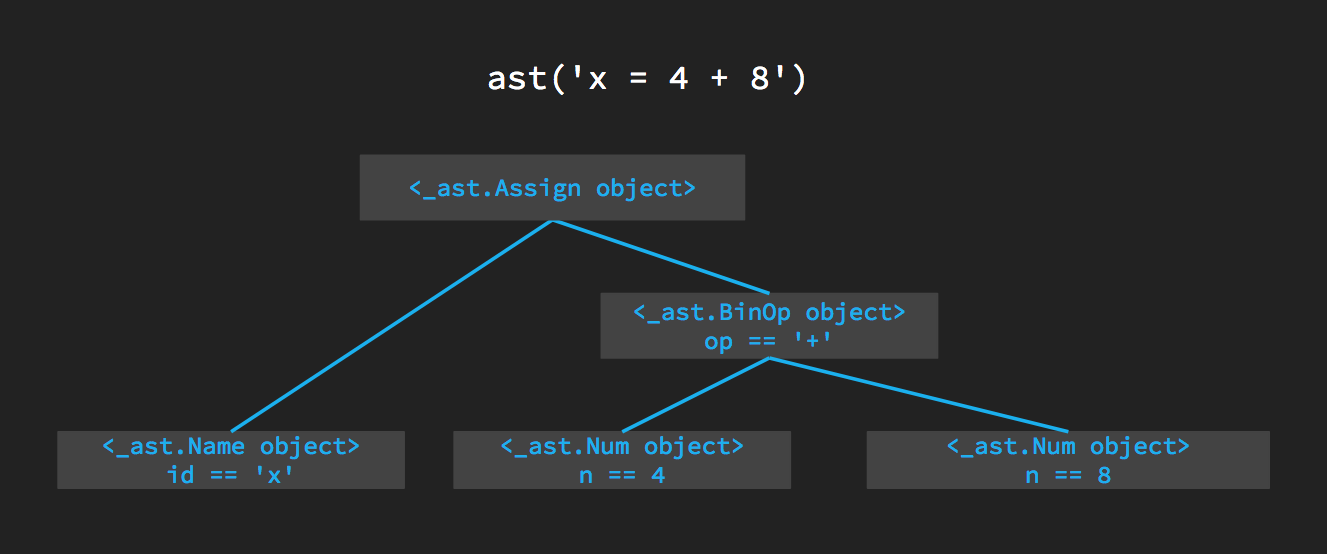
通过分析输出的AST,我们可以看到,源代码中的赋值语句被转换成了一个`Assign`节点,其中包含了`Name`和`Num`节点作为子节点。这演示了从源代码到AST的转换过程。
### 表格展示
为了更直观地展示AST节点的类型和属性,我们可以创建一个表格来展示这些信息。
| Node Type | Attributes | Description |
| --------- | ---------- | ----------- |
| Assign | targets, value | 用于表示赋值语句 |
| BinOp | left, right, op | 用于表示二元操作 |
| FunctionDef | name, args, body | 用于表示函数定义 |
| If | test, body, orelse | 用于表示if语句 |
| Try | body, handlers | 用于表示try语句 |
### mermaid格式流程图
我们还可以使用mermaid流程图来展示从源代码到AST的转换过程。
```mermaid
graph TD;
A[源代码] --> B[词法分析];
B --> C[语法分析];
C --> D[生成AST];
D --> E[AST];
```
### 代码逻辑解读分析
在上述流程图中,我们展示了从源代码到AST的转换过程。首先,源代码经过词法分析,分解成一系列的标记。然后,这些标记经过语法分析,按照Python的语法规则组织成AST。最终,我们得到了一个结构化的AST,它代表了源代码的语法结构。
### 参数说明
在这个流程图中,每个步骤都有明确的说明。例如,"词法分析"步骤将源代码分解成标记,而"语法分析"步骤则将标记组织成AST。这个流程图帮助我们理解了AST生成的过程。
### 小结
在本章节中,我们深入了解了Python AST的结构,包括AST节点的类型和属性、Python语法结构在AST中的映射以及解析代码生成AST的过程。通过具体的代码示例、表格和流程图,我们展示了AST的内部工作原理和如何生成AST。这些知识对于理解和操作AST至关重要,为后续章节中介绍的操作和修改AST、以及AST在代码分析中的应用打下了坚实的基础。
# 3. 操作和修改Python AST
在本章节中,我们将深入探讨如何操作和修改Python的抽象语法树(AST)。我们将介绍如何使用Python标准库中的`ast`模块来分析AST,编写代码生成器,以及修改和重构现有代码。
## 3.1 使用Python标准库分析AST
### 3.1.1 ast模块的基本用法
`ast`模块是Python标准库的一部分,它提供了一系列工具来处理AST。通过使用`ast`模块,我们可以遍历AST节点,访问其属性,以及执行各种与AST相关的操作。下面是一个简单的例子,展示了如何使用`ast`模块来分析一个简单的表达式。
```python
import ast
# 定义一个简单的Python表达式
code = '3 + 4 * (2 - 1)'
# 解析代码并生成AST
parsed_code = ast.parse(code)
# 打印AST的结构
ast.dump(parsed_code, indent=4)
```
上述代码将输出AST的结构,其中包含了表达式的各个组成部分,例如`Add`和`Mult`节点。`ast.dump`函数能够以缩进的形式打印AST的内容,让我们更容易理解和分析。
### 3.1.2 常见的AST节点访问和遍历技巧
在处理AST时,我们经常需要访问特定类型的节点。`ast`模块提供了多种方法来遍历AST,并允许我们检查节点的类型和其他属性。以下是一个示例,它遍历AST并找到所有的数字节点。
```python
class NumberVisitor(ast.NodeVisitor):
def visit_Num(self, node):
print(f'NumberNode: {node.n}')
visitor = NumberVisitor()
visitor.visit(parsed_code)
```
在这个例子中,我们定义了一个`NumberVisitor`类,它继承自`ast.NodeVisitor`。我们重写了`visit_Num`方法,这个方法会在遍历过程中被调用,每次遇到`Num`类型的节点时。`ast.NodeVisitor`提供了一种结构化的方式来遍历AST,使得我们可以根据节点类型执行不同的操作。
## 3.2 编写代码生成器
### 3.2.1 从AST生成Python代码
有时我们需要将AST反向转换回Python代码。这在编写代码生成器时尤其有用,例如,当我们想要自动生成一些重复性的代码模式时。`astor`库是一个可以将AST转换回源代码的第三方库。以下是如何使用`astor`从AST生成Python代码的示例。
```python
import astor
# 生成源代码
source_code = astor.to_source(parsed_code)
print(source_code)
```
在这个例子中,我们使用`astor.to_source`函数将之前解析得到的AST转换回Python代码。输出的结果将是我们最初定义的表达式`3 + 4 * (2 - 1)`。
### 3.2.2 代码生成器的应用场景和技巧
代码生成器可以用于多种场景,例如自动化生成数据模型代码、批量生成测试用例、或实现代码模板的快速生成。编写代码生成器时,我们需要考虑代码的可读性、灵活性以及可维护性。
在编写代码生成器时,一个常见的技巧是定义代码模板,这些模板包含了将AST转换为源代码时需要遵循的规则。通过这种方式,我们可以将代码生成器的设计与具体的AST结构解耦,使得生成器更加通用和可重用。
## 3.3 修改和重构现有代码
### 3.3.1 重构代码的AST策略
重构代码时,AST提供了一种强大的手段来自动化许多复杂的任务。例如,我们可以编写一个工具来自动修改函数参数的顺序,或者将一个函数调用替换为另一个等。以下是一个示例,它展示了如何修改AST来将一个函数调用的参数顺序进行反转。
```python
class SwapArguments(ast.NodeTransformer):
def visit_Call(self, node):
if isinstance(node.func, ast.Name):
# 反转参数
node.args = list(reversed(node.args))
return node
# 应用转换
transformer = SwapArguments()
transformed_code = transformer.visit(parsed_code)
# 打印修改后的AST
ast.dump(transformed_code, indent=4)
```
在这个例子中,我们定义了一个`SwapArguments`类,它继承自`ast.NodeTransformer`。这个类重写了`visit_Call`方法,这个方法会在遍历过程中被调用,每次遇到`Call`类型的节点时。我们修改了`Call`节点的`args`属性,将参数列表反转。
### 3.3.2 代码风格调整和代码优化的实例
通过操作AST,我们可以对代码进行风格调整和优化。例如,我们可以移除未使用的变量,优化表达式,或者重写代码以提高其性能。以下是一个简单的例子,它展示了如何移除一个表达式中的冗余操作。
```python
class SimplifyExpressions(ast.NodeTransformer):
def visit_BinOp(self, node):
if isinstance(node.op, ast.Add) and isinstance(node.left, ast.Num) and isinstance(node.right, ast.Num):
# 简化常数加法
return ast.Num(node.left.n + node.right.n)
return node
# 应用转换
transformer = SimplifyExpressions()
transformed_code = transformer.visit(parsed_code)
# 打印修改后的AST
ast.dump(transformed_code, indent=4)
```
在这个例子中,我们定义了一个`SimplifyExpressions`类,它继承自`ast.NodeTransformer`。这个类重写了`visit_BinOp`方法,这个方法会在遍历过程中被调用,每次遇到`BinOp`类型的节点时。如果`BinOp`节点的操作是一个加法,并且左右操作数都是数字,我们就直接计算结果并返回一个新的数字节点。
通过上述示例,我们可以看到如何使用`ast`模块来分析、修改和重构代码。这些操作对于代码分析工具、代码生成器以及自动化重构工具的开发都是非常有用的。在本章节的介绍中,我们介绍了如何使用`ast`模块进行代码分析和修改,并提供了一些实用的示例。这些知识将为我们深入理解Python AST的高级主题奠定基础。
# 4. Python AST在代码分析中的应用
在本章节中,我们将深入探讨Python AST在代码分析中的广泛应用,包括代码静态分析、代码插桩和覆盖率分析,以及自动修复和代码审查。通过这些应用实例,我们将展示如何利用Python AST的强大功能来增强我们的编程实践和提高代码质量。
## 4.1 代码静态分析
代码静态分析是指在不运行代码的情况下,对代码进行分析的技术。这种分析可以揭示代码中的潜在错误、风格问题、安全漏洞等。在Python中,AST为代码静态分析提供了强大的支持。
### 4.1.1 静态分析工具的原理
静态分析工具通常通过分析源代码的AST来工作。这些工具会遍历AST的每一个节点,检查节点的类型、属性以及节点之间的关系。通过这种方式,工具可以检测到代码中的语法错误、不规范的编程习惯、潜在的运行时异常等情况。
例如,一个典型的静态分析流程可能包括以下几个步骤:
1. 解析源代码生成AST。
2. 遍历AST节点,对每个节点进行检查。
3. 根据预定义的规则,识别代码中的问题。
4. 生成分析报告。
### 4.1.2 使用AST进行代码质量检查
Python中的静态分析工具如`flake8`和`pylint`都利用了AST来进行代码质量检查。这些工具通过定义一系列的规则来分析AST,并报告代码中的问题。
例如,`flake8`会报告不必要的空格、超过最大行长度的代码、未使用的变量等。而`pylint`则会更深入地分析代码,报告未使用导入的模块、变量命名不规范、重复代码等问题。
### 代码逻辑解读分析
```python
import ast
# 定义一个简单的Python代码字符串
code = """
def example_function():
x = 10
y = 20
z = x + y
return z
# 解析代码生成AST
parsed_code = ast.parse(code)
# 遍历AST节点
for node in ast.walk(parsed_code):
print(node)
```
在上面的代码逻辑中,我们首先导入了`ast`模块,然后定义了一个包含函数的Python代码字符串。通过`ast.parse`函数,我们将这个代码字符串解析成AST。最后,我们遍历这个AST的所有节点,并打印出来。
通过这种方式,我们可以手动检查AST节点,并根据需要编写规则来检测代码中的问题。
### 表格:静态分析工具对比
| 工具名称 | 主要功能 | 特点 | 使用场景 |
| --- | --- | --- | --- |
| flake8 | 代码风格检查 | 检查代码风格,简单易用 | 个人代码审查 |
| pylint | 代码质量检查 | 提供丰富的代码质量检查规则 | 团队代码审查 |
| bandit | 安全漏洞检查 | 检查Python代码的安全漏洞 | 安全审计 |
## 4.2 代码插桩和覆盖率分析
代码插桩是将额外的代码插入到原有代码中,以便进行分析或测试的过程。在Python中,我们可以通过修改AST来实现代码插桩。
### 4.2.1 插桩技术的概念和应用
插桩技术通常用于以下几个方面:
1. **性能分析**:插入代码来测量函数调用的性能。
2. **错误检测**:插入代码来检测运行时错误,如内存泄漏。
3. **测试**:插入断言或日志记录代码来增强测试用例。
### 4.2.2 基于AST的代码覆盖率分析工具
代码覆盖率分析工具用于评估测试用例覆盖了代码的多少。在Python中,`coverage.py`是一个流行的工具,它通过分析AST来确定哪些代码被执行了。
### 代码逻辑解读分析
```python
import ast
# 定义一个简单的Python代码字符串
code = """
def example_function():
print("Hello, World!")
return 1
# 解析代码生成AST
parsed_code = ast.parse(code)
# 插桩AST:在每个函数调用后插入日志记录
class AstTransformer(ast.NodeTransformer):
def visit_Call(self, node):
# 在函数调用节点上添加日志记录
log_call = ast.Expr(value=ast.Call(
func=ast.Attribute(value=ast.Name(id='print', ctx=ast.Load()),
attr='format',
ctx=ast.Load()),
args=[ast.Str(s='Function called: {}'.format(node.func.id)), node],
keywords=[]
))
ast.copy_location(log_call, node)
self.generic_visit(node)
return log_call
transformer = AstTransformer()
transformed_code = transformer.visit(parsed_code)
# 打印修改后的AST
ast.dump(transformed_code, indent=4)
```
在上面的代码逻辑中,我们首先定义了一个简单的Python代码字符串。然后,我们创建了一个`AstTransformer`类,它继承自`ast.NodeTransformer`。在`visit_Call`方法中,我们添加了一个日志记录调用,以便在每次函数调用时记录信息。
通过这种方式,我们可以对源代码进行插桩,以满足特定的分析需求。
### 表格:代码插桩工具对比
| 工具名称 | 主要功能 | 特点 | 使用场景 |
| --- | --- | --- | --- |
| coverage.py | 代码覆盖率分析 | 基于AST,易于集成 | 测试覆盖率分析 |
| pytest | 测试框架 | 支持代码插桩 | 单元测试 |
## 4.3 自动修复和代码审查
代码审查是确保代码质量的重要环节。通过自动化的工具,我们可以减少人为审查的工作量,并提高审查的效率和准确性。
### 4.3.1 代码自动修复工具的设计思路
代码自动修复工具通常基于静态分析结果来自动修复代码中的问题。这些工具的设计思路包括:
1. **规则驱动**:定义一系列的修复规则。
2. **AST操作**:在AST层面上进行修改。
3. **代码生成**:将修改后的AST转换回Python代码。
### 4.3.2 AST在代码审查中的应用案例
在代码审查中,我们可以使用`ast`模块来分析代码,并根据分析结果给出建议。
### 代码逻辑解读分析
```python
import ast
# 定义一个简单的Python代码字符串
code = """
x = 1
y = 2
z = x + y
# 解析代码生成AST
parsed_code = ast.parse(code)
# 定义一个函数用于检查和修复潜在的问题
def check_and_repair(ast_tree):
for node in ast.walk(ast_tree):
if isinstance(node, ast.Assign) and isinstance(node.targets[0], ast.Name):
name = node.targets[0].id
if name.startswith('x') or name.startswith('y'):
# 这里可以添加自动修复逻辑
print(f"Found assignment to {name}, consider renaming to avoid confusion.")
# 执行检查和修复
check_and_repair(parsed_code)
```
在上面的代码逻辑中,我们首先定义了一个包含变量赋值的Python代码字符串。然后,我们解析这段代码生成AST。通过`check_and_repair`函数,我们可以遍历AST,并对潜在的问题进行检查和修复。
通过这种方式,我们可以实现一个简单的代码审查工具,它可以帮助我们发现代码中的问题并给出修复建议。
### 表格:代码自动修复工具对比
| 工具名称 | 主要功能 | 特点 | 使用场景 |
| --- | --- | --- | --- |
| autopep8 | 代码格式化 | 自动修复代码格式问题 | 代码格式化 |
| black | 代码格式化 | 严格的代码格式化标准 | 代码格式化 |
在本章节中,我们展示了Python AST在代码分析中的广泛应用,包括代码静态分析、代码插桩和覆盖率分析,以及自动修复和代码审查。通过这些实例,我们可以看到AST不仅是一个强大的工具,而且在提高代码质量和维护性方面发挥着关键作用。通过学习和掌握AST的应用,开发者可以更有效地编写高质量的Python代码。
# 5. 深入探究Python AST的高级主题
## 5.1 AST与元编程
元编程(Metaprogramming)是指编写能够操作其他程序的代码。在Python中,元编程可以通过多种方式实现,而AST是实现元编程的一个强大工具。本节将深入探讨元编程的基本概念以及如何使用AST来实现元编程技术。
### 元编程的基本概念
元编程是一种在程序运行之前或运行时,对程序的结构进行操作的技术。它可以让你编写出更为通用和灵活的代码。例如,元类(metaclass)就是一种高级的元编程技术,它允许你控制类的创建过程。
### 使用AST实现元编程技术
AST可以用于实现元编程的几种方式包括但不限于:
- **动态创建代码**:使用`ast`模块动态构建AST节点,并将其转换回代码执行。
- **代码转换**:分析现有代码的AST,然后生成修改后的AST,再将其转换为新的代码。
- **装饰器**:编写可以接收函数AST并修改它的装饰器。
下面是一个使用AST动态创建简单函数的示例:
```python
import ast
import sys
# 创建一个AST节点,表示函数定义
def create_function(name, body):
return ast.FunctionDef(
name=name,
args=ast.arguments(args=[], vararg=None, kwarg=None, defaults=[]),
body=[ast.Expr(value=ast.Call(
func=ast.Name(id='print', ctx=ast.Load()),
args=[ast.Str(s='Hello, world!')],
keywords=[]))],
decorator_list=[]
)
# 将AST节点转换为代码
def compile_and_execute(node, filename="<ast>", mode="exec"):
code = compile(node, filename, mode)
exec(code, globals(), locals())
# 创建函数的AST
my_function_ast = create_function('my_function', [
ast.Expr(value=ast.Str(s='This is a dynamically created function!'))
])
# 编译并执行
compile_and_execute(my_function_ast)
```
执行上述代码后,会动态创建并执行一个名为`my_function`的函数,该函数打印出字符串`This is a dynamically created function!`。
## 5.2 Python AST的扩展和限制
### AST模块的局限性和潜在扩展
Python的`ast`模块提供了AST节点的基本构建块,但它并不是完全灵活的。某些复杂的操作可能需要手动操作AST节点,这可能导致代码的复杂性和错误的可能性增加。此外,`ast`模块可能不支持一些最新的Python语法特性,这意味着它可能不会捕获所有可能的代码模式。
### AST操作的最佳实践和性能考虑
在操作AST时,最佳实践包括:
- **最小化修改**:尽量减少对AST的修改,以降低引入错误的风险。
- **测试**:始终为AST操作编写测试,确保它们按预期工作。
- **性能**:对于大型代码库,AST操作可能很慢。考虑缓存结果或使用更高效的实现。
## 5.3 实战项目:构建一个AST工具
### 项目需求分析和设计
假设我们需要构建一个AST工具,该工具能够分析Python代码并自动修复常见的代码质量问题。需求分析可能包括:
- **输入**:源代码文件或代码片段。
- **输出**:修改后的代码或报告。
- **功能**:代码格式化、错误修复、代码优化建议。
### 实现AST工具的步骤和代码示例
实现一个简单的AST工具可以分为以下步骤:
1. **解析源代码**:将源代码解析成AST。
2. **遍历和分析**:遍历AST,分析代码质量问题。
3. **修改AST**:根据分析结果修改AST。
4. **生成代码**:将修改后的AST转换回代码。
下面是一个简单的AST工具示例,它自动修复了未使用的变量定义:
```python
import ast
# AST工具类
class ASTFixer(ast.NodeTransformer):
def visit_Name(self, node):
# 如果是变量定义且未使用,则移除
if isinstance(node.ctx, ast.Store) and not isinstance(node.parent, (ast.FunctionDef, ast.ClassDef)):
# 检查是否在当前函数或类中使用
for parent in node.parent.walk():
if isinstance(parent, (ast.FunctionDef, ast.ClassDef)):
if node.id in [n.id for n in parent.body]:
break
else:
return None
return node
# 示例代码
code = """
def example():
a = 10
return a
# 解析代码
parsed_code = ast.parse(code)
# 应用ASTFixer
transformer = ASTFixer()
fixed_code = transformer.visit(parsed_code)
# 输出修复后的代码
print(ast.unparse(fixed_code))
```
执行上述代码后,会输出修复后的代码,其中未使用的变量定义`a`被移除了。
通过这些步骤和代码示例,我们可以构建一个基本的AST工具来自动修复代码问题。这个过程涉及到了AST的解析、遍历、修改和代码生成,展示了AST在代码分析和修改中的强大能力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python AST(抽象语法树)库,它是一种用于表示 Python 代码结构的强大工具。通过一系列深入的文章,专栏涵盖了广泛的主题,包括 AST 入门、静态分析、代码漏洞检测、元编程、代码审计、反作弊系统、编译器设计、函数式编程、依赖注入和设计模式。通过提供实际案例和高级技巧,专栏旨在帮助读者充分利用 AST 库,以提高代码理解、分析和修改的能力。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入理解单站架构:平衡客户体验与服务可靠性的终极指南

# 摘要
随着企业数字化转型的加速,单站架构因其简洁高效的设计而备受青睐。本文首先对单站架构进行定义,阐述其优势,并在理论框架下详细介绍了单站架构的设计原则、技术选型、组件集成、数据管理、用户界面设计、性能优化策略、用户个性化服务、系统可靠性保障、监控机制以及持续集成与部署等多个方面。本文还通过案例研究分析了单站架构在不同行业的成功应用,并提出了应对隐私与合规性挑战的策略。最后,本文展望了单站架构未来可能的发展趋势,特别是新兴技术如何融合进单站架构中,以及服务
PCI Geomatica高级玩家进阶:环境配置优化秘籍

# 摘要
PCI Geomatica是一个功能强大的遥感和地理信息系统(GIS)软件,广泛应用于地球科学数据处理。本文首先介绍了PCI Geomatica的基本概念、安装流程,并重点分析了环境配置的重要性,包括操作系统兼容性、硬件要求以及软件依赖和版本控制。文章还探讨了优化PCI Geomatica性能的实践技巧,涉及性能测试、环境优化及常见错误排除方法。此外,本文深入阐述了集群与分布式计算环境配置、内存与存储管理优化、自
【FANUC与S7-1200数据交换终极指南】:提升效率的关键秘诀

# 摘要
本文详细探讨了FANUC与S7-1200在工业自动化领域进行数据交换的概念、原理、实践指南和案例分析,并对提升效率及维护数据交换的安全性与规范性进行了深入研究。首先解析了FANUC与S7-1200数据交换的基本概念,并介绍了实现数据交换的通信协议基础和硬件连接细节。随后,本文提供了详细的编程交互指南,包括编程环境的准备、实例
TestU01进阶技巧大公开:定制化测试套件的开发与应用指南

# 摘要
本论文对TestU01测试工具进行了全面介绍,并详细阐述了定制化测试套件的理论基础、开发实践以及高级应用。首先,我们探讨了测试套件的设计原则、类型选择和维护更新,为开发高质量的测试套件奠定了理论基础。随后,介绍了TestU01测试套件开发环境的搭建、测试用例的编写、集成和测试过程。在此基础上
【SERDES故障诊断】:一文解决信号完整性问题

# 摘要
本文首先概述了SERDES技术及其在故障诊断中的重要性,接着深入探讨了信号完整性(SI)的基础理论,包括其定义、影响因素、问题表现与分类,以及测量技术。第三章着重于SERDES故障诊断的实践技巧,涵盖诊断流程、工具和案例分析,并讨论了信号完整性问题的定位与修复。第四章介绍了高级故障诊断技术与工具,包括信号完整性分析工具、信号仿真软件的使用
【i386架构与现代编程实践】:融合与创新的5种方法

# 摘要
本文深入探讨了i386架构的历史和技术细节,分析了现代编程语言的发展及与i386架构的兼容性,并讨论了操作系统层面对i386架构的支持与创新融合。同时,本文还考察了i386在嵌入式开发领域的应用,以及软硬件协同设计的实践。最后,本文展望了i386架构的未来挑战与转型策略,特别是在云计算、大数据、人工智能等新兴技术冲击下的适应性与安全
【上位机安全防护】:实战指南教你如何设计固若金汤的安全性策略

# 摘要
上位机安全防护是确保信息技术系统可靠运行的关键领域。本文首先概述了上位机安全防护的概念及其重要性,随后详细探讨了安全策略设计的基础,包括安全性需求分析、理论框架的建立和风险管理。第三章着重于实用安全防护技术,涵盖了端点防护、网络安全和访问控制等领域。第四章阐述了安全策略实施和监控的流程,包括策略的部署、安全监控和事件响应以及审计和合规性。第五章通过案例研究提供了行业安全策略的深入分析和最佳实践。最后,第六章展望了未
【系统稳定关键】:IBM x3650 RAID监控与报警的全面指南
# 摘要
本文详细探讨了IBM x3650服务器中RAID技术的监控和报警机制。首先提供了RAID基础的概览,并阐述了监控RAID系统稳定性的理论与实践。随后,本文深入分析了硬件RAID卡和软件工具的监控参数,以及如何解读监控数据。进一步,文章介绍了设置RAID报警阈值的重
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )