ERwin数据建模工具的界面导览
发布时间: 2024-02-24 09:33:59 阅读量: 96 订阅数: 48 

ERWin建模工具使用指南
# 1. ERwin数据建模工具简介
ERwin数据建模工具是一款强大的数据建模工具,能够帮助数据库开发人员设计和管理数据库结构,提高数据库设计的效率和准确性。本章将介绍ERwin数据建模工具的定义、历史和主要功能。让我们一起来了解一下吧!
## 1.1 什么是ERwin数据建模工具
ERwin数据建模工具是一种专业的数据建模工具,用于帮助数据库开发人员设计、创建、维护和管理数据库模式。通过ERwin,用户可以以直观的方式表示数据结构,包括实体、属性、关系等,从而更好地理解和规划数据库设计。
## 1.2 ERwin的历史沿革
ERwin数据建模工具最早由Logic Works公司于1990年推出,后被Computer Associates(CA)公司收购。随着技术的发展和数据管理需求的不断增长,ERwin不断更新和升级,成为了业界领先的数据建模工具之一。
## 1.3 ERwin数据建模工具的主要功能
ERwin数据建模工具提供了丰富的功能,包括但不限于:
- 数据模型设计与编辑
- 自动化数据库逆向工程
- 多种数据库平台的支持
- 数据库对象的版本控制
- DDL脚本生成等
这些功能使得ERwin成为了数据库设计和管理过程中不可或缺的利器。在接下来的章节中,我们将深入探讨ERwin的安装、设置、界面导览等内容,帮助您更好地使用这一强大工具。
# 2. 安装与设置
ERwin数据建模工具的安装步骤
- **步骤一:** 下载ERwin数据建模工具的安装文件
```shell
# 在官方网站下载ERwin数据建模工具的安装程序
```
- **步骤二:** 运行安装程序并按照提示进行安装
```shell
# 执行安装程序,按照向导提示进行安装,选择安装路径等
```
配置ERwin数据建模工具的基本设置
- **设置一:** 打开ERwin数据建模工具并选择首选项
```python
# 点击菜单栏中的“工具”->“首选项”选项
```
数据库连接设置
- **设置一:** 添加数据库连接
```java
// 在项目资源管理器中右键点击“数据库连接”,选择“新建连接”
```
- **设置二:** 配置数据库连接信息
```java
// 输入数据库类型、主机名、端口、用户名、密码等信息,并测试连接是否成功
```
以上是安装与设置的部分内容,如有需要,还可以继续添加具体的设置步骤。
# 3. ERwin主界面导览
ERwin数据建模工具的主界面提供了丰富的功能和工具,帮助用户进行数据建模和管理。下面将详细介绍主界面的导览内容。
#### 3.1 菜单栏功能介绍
菜单栏位于主界面顶部,包含了各种功能菜单,方便用户进行操作和设置。常见的菜单有:
- **文件(File)**:提供新建、打开、保存、导出等文件操作功能。
- **编辑(Edit)**:包含撤销、重做、剪切、复制等编辑操作。
- **视图(View)**:用于设置界面的显示方式,如平铺、层叠、隐藏/显示工具栏等。
- **工具(Tools)**:提供数据建模、校验、转换等工具的功能选项。
- **窗口(Window)**:管理界面窗口的布局和显示方式。
- **帮助(Help)**:提供软件帮助文档、更新检查、关于等功能。
#### 3.2 工具栏功能解析
工具栏通常位于菜单栏下方,提供了快捷操作按钮,方便用户快速访问常用功能。常见的工具按钮有:
- **新建**:创建新的数据模型文件。
- **打开**:打开已有的数据模型文件。
- **保存**:保存当前数据模型文件。
- **剪切/复制/粘贴**:用于快速编辑模型内容。
- **撤销/重做**:撤销或重做上一步操作。
- **实体/属性/关联关系创建**:快速添加实体、属性或关联关系到模型中。
#### 3.3 项目资源管理器详解
项目资源管理器通常位于主界面的左侧或右侧,用于管理当前数据模型文件的各种资源,包括但不限于:
- **逻辑模型**:显示逻辑数据模型的结构和关系。
- **物理模型**:展示物理数据模型的表、字段信息。
- **校验规则**:列出模型中定义的校验规则。
- **数据库连接**:显示当前连接的数据库信息,方便进行数据交互和同步操作。
以上是ERwin主界面的导览内容,希望能帮助您更好地掌握工具的功能和操作方式。
# 4. 实体建模
#### 4.1 创建实体与属性
在ERwin数据建模工具中,创建实体与属性是数据建模的基础步骤。以下是创建实体与属性的示例代码:
```python
# 创建实体
class Entity:
def __init__(self, name):
self.name = name
self.attributes = []
def add_attribute(self, attribute_name, data_type):
self.attributes.append({'name': attribute_name, 'type': data_type})
# 实例化实体
employee_entity = Entity("Employee")
# 添加属性
employee_entity.add_attribute("EmployeeID", "int")
employee_entity.add_attribute("Name", "varchar")
employee_entity.add_attribute("DepartmentID", "int")
```
**注释:** 上述代码演示了如何使用Python语言在ERwin中创建实体和属性,其中Entity类表示实体,add_attribute方法用于添加属性。
**代码总结:** 通过创建Entity类实例,并调用add_attribute方法,可以方便地在ERwin中构建实体和属性。
**结果说明:** 以上代码执行后,在ERwin中成功创建了一个名为"Employee"的实体,并添加了名为"EmployeeID"、"Name"和"DepartmentID"的属性。
#### 4.2 主键与外键的设置
在数据建模中,设置主键和外键是非常重要的一步。下面是在ERwin中设置主键和外键的示例代码:
```java
// 设置主键
ALTER TABLE Employee
ADD CONSTRAINT PK_EmployeeID PRIMARY KEY (EmployeeID);
// 设置外键
ALTER TABLE Employee
ADD CONSTRAINT FK_DepartmentID
FOREIGN KEY (DepartmentID) REFERENCES Department(DepartmentID);
```
**注释:** 上述代码示例使用SQL语句来在数据库中设置主键和外键,通过ALTER TABLE和ADD CONSTRAINT语句可以实现这一功能。
**代码总结:** 使用SQL语句可以方便地在ERwin中设置主键和外键约束,保证数据模型的完整性和一致性。
**结果说明:** 以上代码执行后,成功在数据库中为Employee表设置了主键约束和DepartmentID外键约束,确保数据的准确性和一致性。
#### 4.3 实体之间的关联关系建立
在数据建模中,实体之间的关联关系至关重要。以下是在ERwin中建立实体之间关联关系的示例代码:
```javascript
// 创建实体关联
class Association {
constructor(entity1, entity2, association_type) {
this.entity1 = entity1;
this.entity2 = entity2;
this.association_type = association_type;
}
display_association() {
console.log(`${this.entity1} and ${this.entity2} are ${this.association_type}`);
}
}
// 创建实体关联实例
let employee_department_association = new Association("Employee", "Department", "associated with");
// 输出实体关联信息
employee_department_association.display_association();
```
**注释:** 上述代码演示了使用JavaScript语言来创建实体之间的关联关系,Association类表示实体关联,display_association方法用于显示实体之间的关联信息。
**代码总结:** 通过创建Association类的实例,并调用display_association方法,可以清晰展示实体之间的关联关系。
**结果说明:** 以上代码执行后,成功创建了一个名为"Employee"和"Department"之间关联关系的实例,并输出了它们之间的关联信息。
通过以上示例代码,展示了在ERwin中进行实体建模的关键步骤,包括创建实体与属性、设置主键与外键,以及建立实体之间的关联关系。这些步骤对于构建健壮的数据模型至关重要。
# 5. 逻辑与物理建模
数据建模工具不仅可以帮助用户进行逻辑数据建模,还可以将逻辑模型转换为物理模型,并生成对应的数据库对象DDL脚本。接下来将详细介绍ERwin数据建模工具在逻辑与物理建模方面的功能和操作方法。
#### 5.1 逻辑模型设计与转换
在ERwin数据建模工具中,用户可以使用直观的图形界面进行逻辑模型的设计。通过拖拽实体、属性和关联关系等元素,可以快速构建出完整的逻辑数据模型。在设计完成后,ERwin还提供了丰富的逻辑模型验证规则,帮助用户确保逻辑模型的完整性和准确性。
此外,ERwin还支持将逻辑模型转换为物理模型的操作。用户可以在界面上进行简单的设置,即可将逻辑模型转换为对应的物理模型,生成数据库中真实的表、索引、约束等对象。
#### 5.2 物理模型生成与调整
在进行物理建模时,ERwin可以根据用户选择的数据库平台自动生成对应的物理模型。用户可以针对具体的数据库平台进行调整和优化,例如对数据类型、索引类型等进行定制化设置,以满足特定的数据库要求。
此外,ERwin还提供了直观的界面,方便用户查看和调整物理模型的细节。用户可以通过界面操作,快速添加、修改或删除物理模型中的各种对象,为后续的数据库实施工作提供便利。
#### 5.3 数据库对象的DDL脚本生成
ERwin数据建模工具还可以根据用户设计的物理模型,自动生成对应的数据库对象DDL脚本。用户可以通过简单的操作,即可将物理模型转换为可执行的DDL脚本,方便数据库管理员进行数据库的创建和维护工作。
以上就是ERwin数据建模工具在逻辑与物理建模方面的功能和操作方法。通过逻辑模型设计、转换为物理模型,并生成对应的数据库对象DDL脚本,用户可以快速、高效地完成数据库设计和实施工作。
# 6. 高级功能与扩展
在ERwin数据建模工具中,除了常见的数据建模功能外,还提供了一些高级功能与扩展,帮助用户更加灵活高效地进行数据建模和管理。
### 6.1 自定义数据模型验证规则
在ERwin中,用户可以根据自身业务需求,自定义数据模型验证规则,以确保数据模型的完整性和准确性。通过设置验证规则,可以对数据模型中的实体、属性、关系等进行约束和校验,避免建模过程中出现错误或不一致的情况。
#### 场景:
假设用户需要确保每个实体的名称长度不超过30个字符,可以通过自定义验证规则来实现这一约束。
#### 代码示例(ERwin中的验证规则设置):
```sql
-- 创建自定义验证规则
CREATE RULE Check_Entity_Name_Length
AS @Entity.Name.Length <= 30;
-- 关联验证规则到实体
ALTER TABLE Entity
ADD CONSTRAINT Entity_Name_Length_Check CHECK (Check_Entity_Name_Length(Entity));
```
#### 代码总结:
以上代码示例演示了如何在ERwin中创建自定义验证规则,并将其应用到实体上,以实现对实体名称长度的约束。
#### 结果说明:
通过设置自定义验证规则,用户在添加或修改实体名称时,如果超过了30个字符的限制,将无法保存,有效地保证了实体名称长度的合法性。
### 6.2 数据模型版本控制
数据模型版本控制是一个非常重要的功能,能够帮助团队协作开发,并追踪数据模型的变更历史。ERwin提供了版本控制功能,让用户可以方便地管理数据模型的不同版本,并进行版本间的对比与合并。
#### 场景:
假设团队中的两名开发人员分别在不同分支上对数据模型进行修改,需要将两个版本合并时,可以通过数据模型版本控制功能来实现。
#### 代码示例(ERwin中的版本控制操作):
```sql
-- 创建新版本
CREATE VERSION 'v1.1' FROM 'v1.0';
-- 合并版本
MERGE VERSION 'v1.1' INTO 'v1.2';
```
#### 代码总结:
以上代码示例展示了在ERwin中创建新版本和合并版本的操作,通过版本控制功能,可以有效管理数据模型的变更历史。
#### 结果说明:
通过版本控制,团队成员可以清晰地了解数据模型的变更情况,避免冲突和误操作,提高团队协作效率。
### 6.3 与其他工具集成的方法介绍
作为一款专业的数据建模工具,ERwin支持与其他工具的集成,例如数据库管理系统、项目管理工具等,以便更好地实现数据模型的应用和管理。
#### 场景:
假设用户需要将数据模型导出到数据库管理系统中,以便生成数据库表结构,可以通过与数据库管理工具的集成来实现。
#### 代码示例(ERwin数据模型导出到数据库管理系统):
```sql
-- 导出数据模型到数据库管理系统
ERwin.exportToDatabaseManagementTool('MySQLWorkbench', 'db_model.erwin');
```
#### 代码总结:
以上代码示例演示了如何将数据模型导出到MySQLWorkbench数据库管理工具中,以便生成数据库表结构。
#### 结果说明:
通过与其他工具的集成,用户可以方便地将数据模型转化为实际的数据库对象,提高了数据模型设计与应用的效率和准确性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏将全面介绍ERwin数据建模工具的各个方面,涵盖从安装配置到数据建模的基本操作,再到数据字典的创建管理和数据模型的版本控制,以及存储过程、触发器的设计与优化等高级应用。读者将学习如何通过ERwin进行数据模型的文档化与分享,以及如何利用该工具进行数据模型的反范式设计。无论是初学者还是有一定经验的用户,都能通过该专栏系统、全面地了解和应用ERwin数据建模工具,提升数据建模的效率和质量。通过专栏的学习,读者可以更好地掌握数据建模工具,从而在实际工作中更加得心应手。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【iMX8MP内存性能优化大揭秘】:从参数配置到系统稳定的深度实践指南
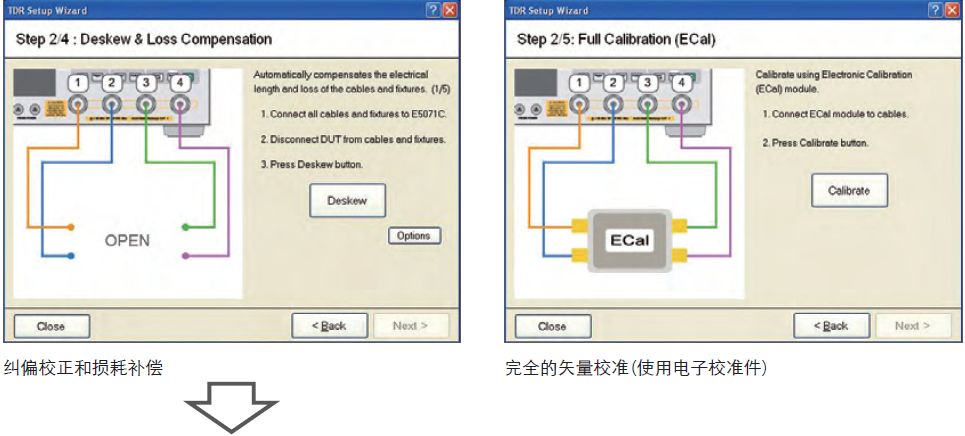
# 摘要
本论文综合探讨了iMX8MP平台的内存架构、性能参数配置、监控与分析、系统级优化及未来内存技术的发展。文章首先为读者提供了iMX8MP平台内存架构的概览,并详细解释了内存性能参数配置的基础和调优策略。接着,深入分析了内存性能监控工具和内存管理系统的优化实践,同时提供了系统级内存性能优化的案例研究。最后,本文展望了新兴内存技术与智能系统在内存管理中的应用前景,讨论了iMX8MP内存性能优化的潜在发展方向以及面
【TongWeb V8.0性能大揭秘】:3大技巧加速你的Web应用
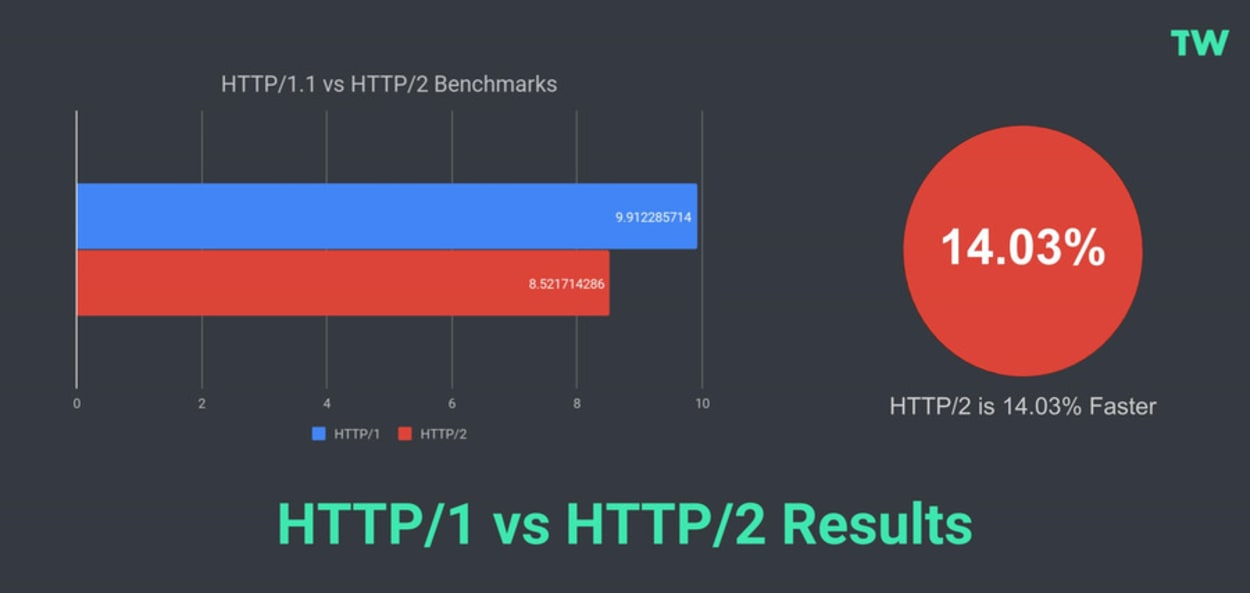
# 摘要
TongWeb V8.0作为一款应用服务器产品,以其在性能上的优势成为关注焦点。本文首先概览了TongWeb V8.0并分析其性能特性,包括理论基础、架构解析以及关键性能指标的调优技巧。随后,文章通过实践案例展示了如何在资源管理、数据库
【Delphi扩展】:自定义ListView进度条:数据绑定与多线程更新技巧

# 摘要
Delphi中的ListView组件广泛应用于复杂数据展示与管理。本文首先介绍了ListView组件的基本概念及应用基础,随后深入探讨了数据绑定技术在ListView中的实现,包括数据绑定概念解析、数据源类型配
ArcGIS线转面:专家级教程揭秘高效率工作流

# 摘要
本文详细探讨了地理信息系统(GIS)中线转面技术的基础概念、理论基础、操作步骤、常见问题解决方法以及实际应用案例。首先对线转面的概念和GIS中的数据模型进行了基础解析,接着深入分析了线转面的理论依据和操作的技术路线。随后,本文详解了ArcGIS软件操作界面与线转面的具体步骤,并针对在操作过程中可能遇到的数据兼容性、精度控制以及性能优化等问题提供了针对性的解决方案
【用友政务数据字典优化攻略】:提升数据敏捷性与准确性

# 摘要
数据字典是信息系统中的关键组成部分,它对于维护数据的准确性和一致性至关重要。本文首先介绍了数据字典的基本概念及其重要性,随后探讨了数据字典的构建、管理和维护过程。在政务应用实例中,本文强调了数据字典在提升数据敏捷性和准确性方面的作用,以及自动化工具的引入。文中还对数据字典的优化与改进进行了深入讨论,包括性能优化、用户体验提升及面向大数据的演化方向。最后,分析了数据字典优化所面
CCS专家实战手册:解决日常开发难题和安全性的终极解决方案
# 摘要
本书《CCS专家实战手册》全面而深入地介绍了在日常开发中诊断和解决技术难题的实战经验,同时强调了代码安全性的最佳实践。书中详细探讨了CCS工具在代码分析、安全加固、性能优化以及安全性测试中的应用,提供了丰富的案例研究来展示其在实际问题中的应用效果。此外,本书还对CCS技术的未来趋势进行了展望,并分享了行业内的最佳实践。对于追求高效开发流程和提升软件安全性的开发者来说,本书是一本不可多得的实用手册。
# 关键字
CCS工具;
JQC-3FF选型秘籍:如何快速找到你的理想继电器

# 摘要
本文旨在全面介绍JQC-3FF继电器的性能特点和技术参数,为工程师和用户提供选型指南,并分析其在不同应用领域的案例。文章首先概述了继电器的基础知识,随后深入解读JQC-3FF继电器的电气和机械技术参数,探讨其环境适应性。在继电器选型方面,本文提出了匹配负载特性、封装和接口选择的策略,并指出选型中的常见误区。通过工业自动化、家用电器和汽车电子等实际应用案例分析,本文进一步阐述了继电器
Toad for DB2性能监控与调优技巧:让你的数据库运行如飞

# 摘要
Toad for DB2作为一款专业数据库管理工具,提供了强大的性能监控和优化功能。本文首先对Toad for DB2工具进行概述,进而详细介绍其性能监控技巧,包括监控指标基础、SQL执行计划分析以及高级性能监控功能。随后,本文深入探讨调优实践,涵盖优化器与索引调优、SQL代码优化以及通过案例分析展示调优效果。第四章深入解析调优策略,包括数据库配置调优
操作系统设计实践:从概念到实现的完整过程,看这里!
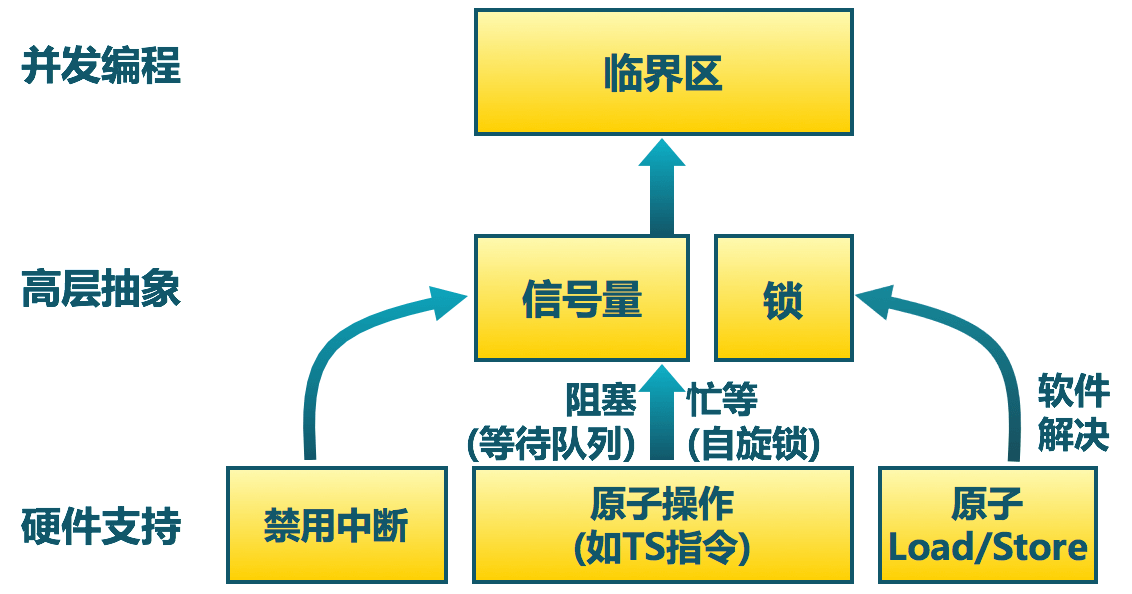
# 摘要
本文全面探讨了操作系统设计的核心概念,从理论基础到实践开发,再到高级功能开发、测试与优化,最后展望了现代操作系统的发展趋势。章节内容涵盖了操作系统的五大基本功能、进程和内存管理策略,以及文件系统的设计原理。在实践开发部分,文章强调了编程环境搭建、进程控制块设计、内存分配策略以及文件系统实现的重要性。高级功能开发章节中,讲述了设备驱动程序、多线程同步机制、网络功能集成和安全机制。在测试与优化方面,本文
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )