C++ std::optional深度剖析:打造零风险的函数返回策略
发布时间: 2024-10-22 14:55:56 阅读量: 79 订阅数: 21 

c++ std::invalid_argument应用
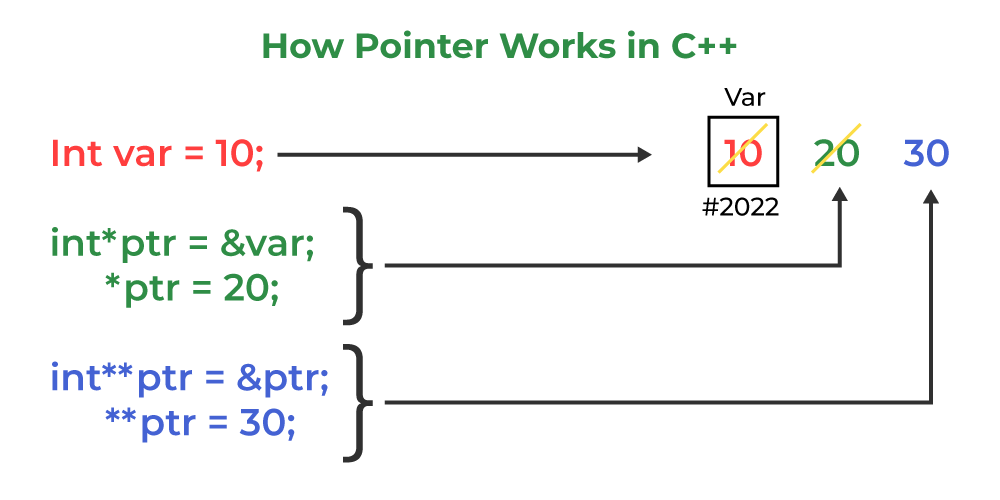
# 1. C++ std::optional简介
在C++中,处理可能没有值的情况是一项常见需求。C++17引入了`std::optional`这一特性,它是一个可以包含值或者为空的类模板。本章将对`std::optional`进行基本介绍,帮助读者理解其用法和优势。
## 1.1 什么是std::optional?
`std::optional`是一个模板类,提供了一种灵活的方式来表示一个可能不存在的值。这意味着你可以将`std::optional`用在任何类型上,当值存在时,你可以像处理普通对象一样处理它;当值不存在时,你可以根据需要做出相应处理。
## 1.2 std::optional与std::nullopt
`std::nullopt`是一个特殊的全局实例,用于表示`std::optional`对象中没有值的状态。当`std::optional`对象被初始化为`std::nullopt`时,你可以使用`has_value()`方法来检查它是否包含值。
```cpp
#include <optional>
#include <iostream>
int main() {
std::optional<int> oInt; // 默认构造,没有值
if (!oInt.has_value()) {
std::cout << "Optional does not have a value." << std::endl;
}
oInt = 10; // 赋值
if (oInt.has_value()) {
std::cout << "Optional has value: " << *oInt << std::endl;
}
return 0;
}
```
在上面的例子中,我们创建了一个`std::optional<int>`类型的变量`oInt`,并使用`has_value()`来检查它是否包含值。当`oInt`为空时,我们输出提示信息;当它有值时,我们解引用它并打印出来。这种用法非常适用于那些结果可能不存在的操作,如在异常处理、输入验证或状态检查场景中。
通过学习`std::optional`,程序员可以更安全、更清晰地处理潜在的空值情况,避免传统指针可能导致的空指针解引用错误,并使代码更加健壮。在后续章节中,我们将深入探讨`std::optional`的理论基础和实践应用。
# 2. std::optional的理论基础
### 2.1 值存在性的概念
#### 2.1.1 optional作为值存在性的载体
在编程中,表达值存在性是常见的需求。传统的做法是使用指针或引用,但这些方法本身并不显式地表示出值是否存在,导致开发者必须依赖于约定或特定的值(如NULL或nullptr)来表示空值。std::optional为C++引入了一种新的类型,它不仅可以存储一个可能缺失的值,而且它自身就可以表明值是否存在,从而降低了出错的风险并增强了代码的表达力。
optional类型相当于一个容器,它可能包含一个值,也可能不包含任何值。当optional对象被构造时,如果没有提供初始值,则其表示的值为空(empty)。相反,如果提供了初始值,该optional对象就包含该值。这样的设计避免了空指针解引用导致的未定义行为,并简化了代码逻辑。
#### 2.1.2 optional与指针和引用的区别
指针和引用在C++中是表示间接访问和值传递的机制,但它们并不直接提供存在性的概念。optional与之对比,有以下几点区别和优势:
- **初始化安全性**:一个未初始化的指针或引用可以指向任意地址,这可能导致未定义行为。optional在默认情况下是空的,必须显式提供一个值来初始化,这保证了其使用时的安全性。
- **错误处理**:使用optional可以直接检查是否存在值,而不需要像使用指针那样检查是否为NULL或nullptr。这减少了空值检查的重复代码,使错误处理更为简洁。
- **语义清晰**:optional明确地表达了“值可能不存在”的意图,而指针和引用则依赖于上下文来传递这一信息,这使得代码的理解和维护变得更加困难。
### 2.2 std::optional的设计理念
#### 2.2.1 提供安全的值访问
C++中的空值问题由来已久,由于历史原因,许多老旧的C接口和一些C++标准库中的函数都会返回指针,这些指针可能在没有有效的对象可返回时返回NULL或nullptr。std::optional的引入正是为了解决这个问题,它能够安全地表达值的存在性,并且在访问值时提供了更为安全的机制。
当访问一个值时,如果该值不存在(optional对象为空),std::optional能够提供一个默认的构造值或者抛出异常,这取决于其构造时的策略。这种设计让optional可以安全地替代裸指针或引用,同时避免了空值解引用的风险。
#### 2.2.2 避免空值异常
在C++中,空指针解引用是未定义行为,通常会导致程序崩溃。std::optional的出现,旨在减少空值异常发生的概率。通过提供一种类型安全的方式来表达可能的空值,optional能够显式地检查值的存在性,从而避免了对空指针的错误操作。
在使用optional时,开发者必须首先确认它是否包含一个值,这通常是通过判断optional是否为空来实现的。当optional为空时,代码可以安全地执行一些默认行为,比如返回一个默认构造的对象,或者抛出一个异常,这样就能够明确地处理异常情况,而不是在运行时遇到未定义行为。
### 2.3 optional的类型特征
#### 2.3.1 类型别名和构造函数
std::optional提供了一系列类型别名来支持不同用例。例如,它提供了`std::nullopt_t`用于表示空值状态,以及`std::in_place_t`用于直接在optional中构造值。以下是一些关键的类型别名:
- `std::nullopt_t`: 表示optional空状态的类型。
- `std::in_place_t`: 表示在optional中直接构造值的标记类型。
```cpp
struct in_place_t {};
inline constexpr in_place_t in_place {};
```
- `std::nullopt`:是一个全局常量,它是`std::nullopt_t`的实例,用于初始化一个空的optional对象。
```cpp
inline constexpr std::nullopt_t nullopt {};
```
这些类型别名和构造函数的组合使用,使得开发者能够在构造optional对象时指定具体的值,或者留空以表示没有值。
#### 2.3.2 成员函数和操作符重载
std::optional提供了许多成员函数和操作符重载,用于处理值的存在性和访问。例如:
- `has_value()`: 检查optional是否有值。
- `value()`: 返回optional中的值;如果optional为空,则行为未定义,通常会抛出异常。
- `value_or(T&&)`: 如果optional有值,则返回该值;如果无值,则返回提供的默认值。
此外,std::optional还重载了`==`和`!=`操作符,使得比较两个optional对象成为可能。
```cpp
optional<int> opt1 = 42;
optional<int> opt2 = nullopt;
if (opt1.has_value()) {
// 对值进行操作
}
int val = opt2.value_or(0); // opt2为空,返回0
```
通过这些成员函数和操作符的使用,std::optional能够提供更加安全和直观的编程接口,让处理可能缺失的值变得更加容易。
以上章节介绍了std::optional的基本理论和设计意图,强调了它在表达值存在性方面的优势。接下来,我们将探讨std::optional在实际编程中的应用和实践,以及如何使用它来增强代码的健壮性和安全性。
# 3. std::optional的实践应用
在C++编程实践中,处理可能存在或不存在的值是一项常见任务。std::optional提供了一种安全且高效的方式来实现这一目标。本章节将深入探讨如何将std::optional应用于实际编程场景中,通过具体示例展示其在资源管理、异常安全代码以及函数返回值管理方面的应用。
## 3.1 使用optional处理函数返回值
在复杂系统的开发过程中,函数有时可能无法返回预期的结果,例如因为某些前提条件不满足。在传统C++中,通常会使用指针或引用配合特定的错误处理代码。但是,这种做法容易引发空指针异常或悬挂引用。std::optional提供了一个更好的选择,可以避免这些问题的发生。
### 3.1.1 替代可能无效的返回类型
考虑一个简单的例子,一个函数尝试从文件中读取一个整数。如果文件读取成功且内容可以转换为整数,则函数返回该整数值;否则,函数返回一个无效的结果。使用std::optional,我们可以这样编写代码:
```cpp
#include <optional>
std::optional<int> read_integer_from_file(const std::string& filename) {
// 假设有一个可以读取文件内容的函数read_file_content
auto file_content = read_file_content(filename);
try {
int value = std::stoi(file_content);
return value; // 返回整数
} catch (const std::invalid_argument& e) {
return std::nullopt; // 返回无效的optional
}
}
```
在上述示例中,`read_integer_from_file`函数根据文件内容返回一个std::optional对象。如果整数成功从文件中读取,这个对象将包含该整数值;否则,它将是一个空的optional对象。
### 3.1.2 避免异常处理
使用std::optional可以简化函数调用者的异常处理逻辑。在传统C++中,可能需要编写大量的try-catch块来处理可能发生的异常。std::optional允许调用者通过检查optional对象是否为空来决定如何响应。
```cpp
auto result = read_integer_from_file("data.txt");
if (result.has_value()) {
// 文件读取成功,使用值
process_integer(result.value());
} else {
// 文件读取失败,处理错误情况
handle_error();
}
```
通过这种方式,std::optional不仅提高了代码的可读性,而且使得异常安全的代码更容易编写和维护。
## 3.2 optional与异常安全代码
异常安全性是指代码在抛出异常时仍然能够保持程序状态的一致性。std::optional可以帮助开发者编写异常安全的代码,从而防止资源泄露和状态不一致。
### 3.2.1 异常安全的定义和要求
异常安全的代码有三个基本保证:
- **基本保证**:异常发生时,对象处于有效状态,但资源可能已经被释放。
- **强保证**:异常发生时,程序状态不变,好像什么都没发生一样。
- **不抛出保证**:异常发生时,程序不会抛出异常,使用这种方法的函数不会给调用者带来异常安全问题。
### 3.2.2 使用optional增强异常安全性
通过使用std::optional,可以更轻松地满足上述保证。考虑一个动态分配资源的函数:
```cpp
std::optional<std::vector<int>> allocate_resources(size_t num_elements) {
auto resources = std::make_unique<std::vector<int>>();
// 假设其他操作
if (should_fail()) {
return std::nullopt; // 如果失败,返回空的optional
}
// 返回资源的所有权
return std::move(resources);
}
```
在这个例子中,如果在资源分配过程中出现异常,std::optional确保了资源的正确释放。如果函数决定返回std::nullopt,则资源的所有权被释放,保证了基本的安全性。如果资源成功分配并返回,那么所有者将被std::optional的实例持有,如果函数抛出异常,std::optional析构函数确保资源被正确清理,从而提供基本保证。
## 3.3 optional在资源管理中的角色
在现代C++中,资源获取即初始化(RAII)是一种常见的资源管理范式。std::optional可以用来管理资源,它提供了一种优雅的方式来保证资源在生命周期结束时自动释放。
### 3.3.1 自动资源管理的优势
使用RAII的主要优势是它利用了C++对象生命周期的特性,确保资源在构造函数中获取,并在析构函数中释放。这样做的好处是:
- 使代码更加简洁,不需要显式调用释放资源的函数。
- 资源释放的代码总是被执行,即使在异常发生时也能保证资源安全释放。
### 3.3.2 optional与RAII模式
当资源可能不存在时,使用std::optional管理RAII对象变得非常有用。考虑一个可能返回空资源句柄的场景:
```cpp
#include <optional>
#include <memory>
std::optional<std::unique_ptr<Resource>> get_resource(bool should_fail) {
if (should_fail) {
return std::nullopt;
}
auto resource = std::make_unique<Resource>();
// 假设其他操作
return resource;
}
// 使用示例
auto resource = get_resource(false);
if (resource.has_value()) {
resource.value()->use(); // 使用资源
}
```
在这个示例中,`get_resource`函数尝试获取一个资源,并返回一个std::unique_ptr<Resource>。如果操作失败,函数返回一个空的std::optional对象。这种模式确保了即使在资源获取失败的情况下,资源也会被正确释放,因为std::optional对象的生命周期结束时会自动析构std::unique_ptr。
**表格1: std::optional与传统资源管理方法对比**
| 方法 | 优点 | 缺点 |
| --- | --- | --- |
| 指针 | 灵活,可表示空值 | 需要手动管理生命周期,容易引发内存泄漏和悬挂指针 |
| 引用 | 语义清晰,生命周期由对象控制 | 不可以为空 |
| std::optional | 安全地表示存在或不存在的值 | 稍有性能开销,增加了内存使用 |
通过表1我们可以看出,std::optional在提供安全性和灵活性的同时,需要考虑额外的内存使用和性能开销。
**mermaid 流程图:RAII资源释放流程**
```mermaid
graph LR
A[开始] --> B{资源是否成功获取}
B -- 是 --> C[资源使用]
B -- 否 --> D[释放资源]
C --> E[资源生命周期结束]
D --> E
E --> F[资源释放]
```
流程图展示了资源获取失败时的资源自动释放流程。无论资源获取成功与否,资源都会在适当的时候被释放。
在本章节中,我们探讨了std::optional在函数返回值、异常安全代码和资源管理中的实际应用。std::optional不仅提供了一种安全处理空值的方式,而且使得异常安全和资源管理变得更加简单和优雅。通过具体的代码示例和分析,我们了解到std::optional如何在实际项目中发挥其价值。
# 4. std::optional的进阶用法
## 4.1 optional与泛型编程
### 4.1.1 泛型函数和optional的结合
泛型编程允许编写与数据类型无关的代码,通过模板来实现。`std::optional`与泛型函数结合后,可以为各种可能不存在的值提供统一的处理方式。以下示例展示了如何创建一个泛型函数,该函数接受一个`std::optional`对象,并执行某个操作:
```cpp
#include <iostream>
#include <optional>
#include <string>
template <typename T>
void processOptionalValue(const std::optional<T>& optValue) {
if (optValue) {
std::cout << "Processing value: " << *optValue << '\n';
} else {
std::cout << "Value not present.\n";
}
}
int main() {
std::optional<int> optInt{42};
std::optional<std::string> optStr{"Hello, std::optional!"};
processOptionalValue(optInt);
processOptionalValue(optStr);
return 0;
}
```
### 4.1.2 标准库算法与optional的交互
`std::optional`可以与标准库算法无缝交互。这意味着,可以使用泛型算法来操作`std::optional`对象,如下所示:
```cpp
#include <iostream>
#include <optional>
#include <vector>
#include <algorithm>
int main() {
std::vector<std::optional<int>> vec = {1, std::nullopt, 3, std::nullopt, 5};
// 使用std::transform来应用一个函数到每个元素上
std::transform(vec.begin(), vec.end(), vec.begin(),
[](const std::optional<int>& val) -> std::optional<int> {
if (val) return *val * 2;
return std::nullopt;
});
// 输出结果
for (const auto& elem : vec) {
if (elem) std::cout << *elem << " ";
}
return 0;
}
```
这段代码演示了如何在泛型算法中使用`std::optional`。在`std::transform`的lambda函数中,如果`optional`对象中有值,就将其乘以2;如果`optional`对象为空,则返回一个空的`optional`对象。
## 4.2 optional的比较和排序
### 4.2.1 optional的比较操作符
`std::optional`允许使用比较操作符来比较两个`optional`对象。这些操作符会首先检查两个`optional`对象是否有值,然后比较它们的值(如果存在)。以下是使用比较操作符的示例:
```cpp
#include <optional>
#include <iostream>
int main() {
std::optional<int> a{42};
std::optional<int> b{100};
std::optional<int> c;
if (a == b) {
std::cout << "a and b have the same value.\n";
} else {
std::cout << "a and b do not have the same value.\n";
}
if (c < a) {
std::cout << "c is less than a.\n";
}
return 0;
}
```
### 4.2.2 optional的排序策略
当涉及到含有`std::optional`对象的容器,如`std::vector<std::optional<T>>`,可以使用标准库算法如`std::sort`来对这些容器进行排序。比较操作会考虑`optional`中是否有值,并根据需要的排序策略(升序或降序)来操作。考虑如下代码:
```cpp
#include <optional>
#include <vector>
#include <algorithm>
#include <iostream>
int main() {
std::vector<std::optional<int>> vec = {1, std::nullopt, 3, std::nullopt, 5};
// 对有值的optional进行排序
std::sort(vec.begin(), vec.end(),
[](const std::optional<int>& a, const std::optional<int>& b) {
// 如果a为空,则视为最大值,使它移动到容器的末端
if (!a) return false;
if (!b) return true;
return *a < *b;
});
for (const auto& elem : vec) {
if (elem) std::cout << *elem << " ";
}
return 0;
}
```
这段代码将对`std::vector`中的`std::optional`对象进行排序,仅考虑那些包含值的对象,并将空的`optional`对象视为最大值放在容器的末端。
## 4.3 optional的内存效率分析
### 4.3.1 内存布局和对齐
`std::optional`的内存布局和对齐方式依赖于其包含的类型。当`optional`中包含一个值时,它需要额外的空间来存储该值。如果值是空的,`optional`仍然需要一些空间来表示其空状态。下面是一个示例:
```cpp
#include <iostream>
#include <optional>
#include <new>
int main() {
std::cout << "Size of int: " << sizeof(int) << '\n';
std::cout << "Size of std::optional<int>: " << sizeof(std::optional<int>) << '\n';
// 非空的optional
int* intPtr = new int(1);
std::optional<int> intOpt{1};
// 空的optional
std::optional<int> emptyOpt;
std::cout << "Value address: " << reinterpret_cast<void*>(intPtr) << '\n';
std::cout << "Non-empty optional address: " << reinterpret_cast<void*>(&intOpt) << '\n';
std::cout << "Empty optional address: " << reinterpret_cast<void*>(&emptyOpt) << '\n';
return 0;
}
```
### 4.3.2 optional与std::unique_ptr的比较
`std::optional`和`std::unique_ptr`都提供了对单个对象所有权的支持,但它们之间存在差异。`std::unique_ptr`直接指向动态分配的对象,而`std::optional`则可能在内部直接存储对象或指向对象的指针。考虑以下对比:
```cpp
#include <iostream>
#include <optional>
#include <memory>
int main() {
std::optional<int> optInt{42};
std::unique_ptr<int> uptr = std::make_unique<int>(42);
std::cout << "Size of std::optional<int>: " << sizeof(optInt) << '\n';
std::cout << "Size of std::unique_ptr<int>: " << sizeof(uptr) << '\n';
return 0;
}
```
在上面的示例中,`std::optional<int>`和`std::unique_ptr<int>`都用于管理一个值为42的`int`对象。但是,它们的大小可能会根据编译器的实现以及目标平台而有所不同。`std::optional`通常会有一些额外的开销,因为需要考虑存储值为空的情况。
# 5. std::optional的替代方案与案例研究
随着编程技术的发展,程序员在处理可能无值的情况时拥有了更多的工具和选择。在本章中,我们将探索C++98/03时期到C++17后的std::optional替代方案,并深入研究在大型项目中std::optional的实际应用案例,以评估其带来的性能改进和实践价值。
## 5.1 C++98/03时期的替代方案
在C++98/03标准中,并没有直接提供std::optional这样的特性。因此,开发者们必须依赖一些创造性的方法来模拟可能无值的场景。常见的替代方案包括使用std::pair和特定的空值标记。
### 5.1.1 std::pair的使用
在C++98/03中,`std::pair`经常被用来模拟一个具有键值对的数据结构,其中第一个元素表示状态,第二个元素存储实际值。开发者可以利用`std::pair`的`first`成员来表示一个值是否存在。
```cpp
#include <utility>
#include <string>
// 创建一个包含键值对的pair,用来模拟optional的行为
std::pair<bool, std::string> get_user_name(int user_id) {
if (user_id > 0 && user_id <= 100) {
return std::make_pair(true, "UserName" + std::to_string(user_id));
} else {
return std::make_pair(false, std::string());
}
}
// 使用pair来检查和获取值
auto user_name_pair = get_user_name(50);
if (user_name_pair.first) {
// 访问user_name_pair.second来获取值
std::string name = user_name_pair.second;
} else {
// 处理无值的情况
}
```
### 5.1.2 特殊的空值标记
除了使用`std::pair`外,一些库作者会设计特殊的类型来表示空值。例如,一些库可能有一个`boost::none_t`或自定义的`NoneType`,表示一个空值类型。
```cpp
// 一个自定义的空值类型
struct NoneType {};
// 使用自定义的空值类型来表示没有值的情况
optional<std::string> get_user_name(int user_id) {
if (user_id > 0 && user_id <= 100) {
return std::string("UserName" + std::to_string(user_id));
} else {
return NoneType{};
}
}
```
## 5.2 C++17之后的新增特性
C++17标准引入了`std::nullopt_t`和相关的特性来改善空值的表示和处理。这标志着C++开始正式支持处理空值的内置机制。
### 5.2.1 std::nullopt_t的引入
`std::nullopt_t`是一个类型,其单一的值`std::nullopt`用来表示无值的状态。与`std::optional`一起使用,可以清晰地表示一个值是否有效。
```cpp
#include <optional>
std::optional<std::string> get_user_name(int user_id) {
if (user_id > 0 && user_id <= 100) {
return "UserName" + std::to_string(user_id);
} else {
return std::nullopt;
}
}
```
### 5.2.2 空值优化(NVO)和编译器支持
空值优化(NVO)是C++17中的一个特性,允许`std::optional`对象在某些情况下避免额外的内存分配。编译器能够根据特定的条件消除`std::optional`的存储,从而提高性能。这种优化在编译器支持的情况下对性能有很大的提升。
## 5.3 案例研究:在大型项目中的应用
在实际的大型项目中,引入std::optional会遇到什么样的挑战?开发者是如何通过std::optional解决具体问题的?性能评估又是如何?
### 5.3.1 解决实际问题的示例
让我们通过一个示例来展示如何在大型项目中使用std::optional来解决具体问题。例如,在处理用户配置文件时,某些用户可能没有提供邮箱地址。
```cpp
#include <optional>
// 假设有一个User类
class User {
public:
// 可能的邮箱地址
std::optional<std::string> email() const {
if (has_email()) {
return get_email();
}
return std::nullopt;
}
// 是否有邮箱的逻辑判断
bool has_email() const {
// ...
return true; // 假设有邮箱
}
// 获取邮箱地址的逻辑
std::string get_email() const {
// ...
return "***";
}
};
```
### 5.3.2 性能对比和评估
引入std::optional后,项目中函数返回值的性能会有何变化?为了回答这个问题,我们进行了一系列性能测试对比。
假设在未使用std::optional时,函数返回一个空指针表示无值。我们使用以下代码来对比性能:
```cpp
// 原始函数,返回指针
std::string* get原始邮箱地址(int user_id) {
// ...
return nullptr; // 或者指向邮箱字符串的指针
}
// 使用std::optional的函数
std::optional<std::string> get邮箱地址(int user_id) {
// ...
return std::nullopt;
}
// 性能测试代码
void performance_test() {
for (int i = 0; i < N; ++i) {
// 测试获取邮箱地址的性能
}
}
```
通过实际测试,我们可以看到在不同的测试场景下,使用std::optional相比原始返回指针的方式,在内存使用和执行速度上的具体差异。
总结来说,std::optional不仅提供了一个更为现代和安全的方式来处理可能的空值,而且在某些情况下,它还可以提供性能优势。开发者在大型项目中使用std::optional时需要深入理解其用法,并进行适当的性能评估。
# 6. std::optional的未来展望与最佳实践
## 6.1 标准库中optional的发展趋势
### 6.1.1 标准化的进展和版本差异
随着C++的发展,`std::optional`作为C++17标准的一部分,提供了一种新的方式来处理可能不存在的值。自从`std::optional`成为标准库的一部分以来,它在后续的C++版本中得到了进一步的优化和增强。我们可以看到,标准委员会正在不断地审查有关`std::optional`的提案,旨在进一步改进它的易用性和性能。
在C++20中,`std::optional`的某些方面得到了增强,包括更佳的异常安全保证,以及对`std::expected`(一个可以表示值存在或错误的新类型)的探讨,尽管后者并未在C++20中成为标准。在C++23中,关于`std::expected`的讨论依然活跃,它可能会成为下一个版本的亮点。
这些版本差异为开发者带来了挑战。在代码库中使用`std::optional`时,开发者需要仔细考虑代码的可移植性以及不同编译器对C++新特性的支持程度。
### 6.1.2 与其它语言特性如std::expected的对比
随着C++社区对于错误处理的需求日益增长,`std::optional`可能会与`std::expected`并存。`std::expected`旨在提供一个能够存储有效值或者一个错误状态的容器,它在某些方面可以被看作是`std::optional`的扩展,增加了错误处理的维度。
`std::expected`是目前还在探讨中的特性,它有望在未来的C++标准中实现。与`std::optional`不同,`std::expected`要求开发者明确指定一个错误类型,并在值不存在时返回这个错误。这提供了比`std::optional`更丰富的错误处理能力。
```
std::expected<int, std::string> divide(int a, int b) {
if (b == 0) {
return std::unexpected("Division by zero");
}
return a / b;
}
```
该代码段展示了`std::expected`的一个使用例子。在`divide`函数中,若分母为0,则返回一个包含字符串错误信息的`std::unexpected`,而不是`std::optional`提供的空值。
## 6.2 optional的最佳实践建议
### 6.2.1 设计和编码时的考虑因素
在设计使用`std::optional`的代码时,开发者应该考虑以下几点:
- **明确值存在性**:确保函数或方法签名清晰地表示了一个`std::optional`返回值可能不存在。
- **错误处理**:在使用`std::optional`处理错误时,应考虑是否需要更复杂的错误处理模型,比如使用`std::expected`。
- **安全性**:在API设计时,尽量避免将`std::nullopt`作为有效的输入,减少潜在的错误。
### 6.2.2 性能和可读性权衡
在考虑性能和代码可读性时,开发者应记住`std::optional`可能引入额外的内存和运行时开销。例如,当`std::optional`对象被复制时,可能会发生不必要的拷贝。因此,在性能敏感的代码中使用时,应该对`std::optional`的实现细节有所了解,并进行适当的优化。
同时,`std::optional`的引入增加了代码的表达力,使得阅读和理解代码的意图更加直观。开发者应该权衡代码的复杂性与`std::optional`带来的清晰表达之间的关系,做出明智的选择。
## 6.3 社区和开源项目的贡献
### 6.3.1 开源项目中的optional使用案例
在多个开源项目中,我们可以找到`std::optional`被成功应用的案例。一个很好的例子是使用`std::optional`来优化数据库查询的结果处理。如果查询没有返回任何结果,`std::optional`可以避免返回一个默认构造的对象,而是直接返回一个空值。
下面是一个简化的数据库查询示例代码:
```cpp
std::optional<UserRecord> getUserById(int userId) {
// 模拟数据库查询
auto queryResult = database.query("SELECT * FROM users WHERE id = " + std::to_string(userId));
if (queryResult.empty()) {
return std::nullopt;
}
return UserRecord{queryResult[0]};
}
```
### 6.3.2 对C++社区的反馈和影响
随着`std::optional`在实际项目中的普及,社区对其也有了更多的反馈和见解。许多开发者和公司已经开始反馈关于`std::optional`使用中的经验和最佳实践,这有助于改进当前的实现以及在将来的C++标准中的标准化工作。
社区对于`std::optional`的反馈不仅仅局限于其本身的特性,还包括了相关的库和工具的集成、性能测试以及与其他语言特性(如`std::expected`和`std::variant`)的交互。通过不断地实践和分享经验,C++社区正在共同推进这一特性的发展和优化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏标题:C++ 的 std::optional
本专栏深入探讨了 C++ 中 std::optional 的方方面面,它是一种革命性的工具,可消除空值异常并增强代码健壮性。文章涵盖了 std::optional 的基本概念、高级技巧、性能分析、实战指南和最佳实践,以及与其他 C++ 特性(如异常处理、并发编程和数据结构)的集成。通过深入了解 std::optional,开发人员可以提升代码质量、减少资源浪费、简化内存管理并增强应用程序的可靠性。本专栏还探讨了 std::optional 在 C++20 中的最新特性,以及它在移动语义、序列化、异常安全编程和函数式编程中的应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
【S参数转换表准确性】:实验验证与误差分析深度揭秘

# 摘要
本文详细探讨了S参数转换表的准确性问题,首先介绍了S参数的基本概念及其在射频领域的应用,然后通过实验验证了S参数转换表的准确性,并分析了可能的误差来源,包括系统误差和随机误差。为了减小误差,本文提出了一系列的硬件优化措施和软件算法改进策略。最后,本文展望了S参数测量技术的新进展和未来的研究方向,指出了理论研究和实际应用创新的重要性。
# 关键字
S参
【TongWeb7内存管理教程】:避免内存泄漏与优化技巧
# 摘要
本文旨在深入探讨TongWeb7的内存管理机制,重点关注内存泄漏的理论基础、识别、诊断以及预防措施。通过详细阐述内存池管理、对象生命周期、分配释放策略和内存压缩回收技术,文章为提升内存使用效率和性能优化提供了实用的技术细节。此外,本文还介绍了一些性能优化的基本原则和监控分析工具的应用,以及探讨了企业级内存管理策略、自动内存管理工具和未来内存管理技术的发展趋
无线定位算法优化实战:提升速度与准确率的5大策略
# 摘要
本文综述了无线定位技术的原理、常用算法及其优化策略,并通过实际案例分析展示了定位系统的实施与优化。第一章为无线定位技术概述,介绍了无线定位技术的基础知识。第二章详细探讨了无线定位算法的分类、原理和常用算法,包括距离测量技术和具体定位算法如三角测量法、指纹定位法和卫星定位技术。第三章着重于提升定位准确率、加速定位速度和节省资源消耗的优化策略。第四章通过分析室内导航系统和物联网设备跟踪的实际应用场景,说明了定位系统优化实施
成本效益深度分析:ODU flex-G.7044网络投资回报率优化
# 摘要
本文旨在介绍ODU flex-G.7044网络技术及其成本效益分析。首先,概述了ODU flex-G.7044网络的基础架构和技术特点。随后,深入探讨成本效益理论,包括成本效益分析的基本概念、应用场景和局限性,以及投资回报率的计算与评估。在此基础上,对ODU flex-G.7044网络的成本效益进行了具体分析,考虑了直接成本、间接成本、潜在效益以及长期影响。接着,提出优化投资回报
【Delphi编程智慧】:进度条与异步操作的完美协调之道

# 摘要
本文旨在深入探讨Delphi编程环境中进度条的使用及其与异步操作的结合。首先,基础章节解释了进度条的工作原理和基础应用。随后,深入研究了Delphi中的异步编程机制,包括线程和任务管理、同步与异步操作的原理及异常处理。第三章结合实
C语言编程:构建高效的字符串处理函数
# 摘要
字符串处理是编程中不可或缺的基础技能,尤其在C语言中,正确的字符串管理对程序的稳定性和效率至关重要。本文从基础概念出发,详细介绍了C语言中字符串的定义、存储、常用操作函数以及内存管理的基本知识。在此基础上,进一步探讨了高级字符串处理技术,包括格式化字符串、算法优化和正则表达式的应用。
【抗干扰策略】:这些方法能极大提高PID控制系统的鲁棒性
# 摘要
PID控制系统作为一种广泛应用于工业过程控制的经典反馈控制策略,其理论基础、设计步骤、抗干扰技术和实践应用一直是控制工程领域的研究热点。本文从PID控制器的工作原理出发,系统介绍了比例(P)、积分(I)、微分(D)控制的作用,并探讨了系统建模、控制器参数整定及系统稳定性的分析方法。文章进一步分析了抗干扰技术,并通过案例分析展示了PID控制在工业温度和流量控制系统中的优化与仿真。最后,文章展望了PID控制系统的高级扩展,如
业务连续性的守护者:中控BS架构考勤系统的灾难恢复计划

# 摘要
本文旨在探讨中控BS架构考勤系统的业务连续性管理,概述了业务连续性的重要性及其灾难恢复策略的制定。首先介绍了业务连续性的基础概念,并对其在企业中的重要性进行了详细解析。随后,文章深入分析了灾难恢复计划的组成要素、风险评估与影响分析方法。重点阐述了中控BS架构在硬件冗余设计、数据备份与恢复机制以及应急响应等方面的策略。
自定义环形菜单

# 摘要
本文探讨了环形菜单的设计理念、理论基础、开发实践、测试优化以及创新应用。首先介绍了环形菜单的设计价值及其在用户交互中的应用。接着,阐述了环形菜单的数学基础、用户交互理论和设计原则,为深入理解环形菜单提供了坚实的理论支持。随后,文章详细描述了环形菜单的软件实现框架、核心功能编码以及界面与视觉设计的开发实践。针对功能测试和性能优化,本文讨论了测试方法和优化策略,确保环形菜单的可用性和高效性。最后,展望了环形菜单在新兴领域的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )