Hadoop生态系统简介与基本使用
发布时间: 2023-12-17 09:20:22 阅读量: 17 订阅数: 21 
# 1. Hadoop 生态系统概述
## Hadoop 的起源与发展
Hadoop 是由 Apache 软件基金会开发的一套开源软件框架,最初是由 Doug Cutting 和 Mike Cafarella 在 2005 年创建的。其核心设计目的是为了解决海量数据的存储和分析问题。Hadoop 最初的版本是基于 Google 发表的 GFS(Google 文件系统)和 MapReduce 论文实现的。经过多年的发展,目前已经成为大数据处理领域最重要的基础设施之一。
## Hadoop 的核心组件
Hadoop 生态系统由多个核心组件组成,其中包括 HDFS(分布式文件系统)、YARN(资源管理器)、MapReduce(分布式计算框架)、HBase(分布式数据库)、Hive(数据仓库工具)和 Spark(大数据计算框架)。这些组件共同构成了一个完整的大数据处理和分析平台。
## Hadoop 生态系统的重要作用
Hadoop 生态系统在大数据领域发挥着至关重要的作用。它为用户提供了存储海量数据的能力,同时也提供了强大的计算和分析能力。通过 Hadoop,用户可以在成百上千台服务器上并行处理数据,实现高性能的大数据处理和分析任务。同时,Hadoop 还提供了良好的可扩展性和容错性,能够应对各种复杂的大数据场景。因此,Hadoop 生态系统被广泛应用于互联网、金融、零售等领域,成为了支撑大数据应用的重要基础设施之一。
# 2. Hadoop 生态系统组件详解
### HDFS:分布式文件系统
Hadoop 分布式文件系统(Hadoop Distributed File System,简称 HDFS)是 Hadoop 生态系统中的一项重要组件。它的设计目标是将大规模数据集存储在通用硬件上,并提供高吞吐量的数据访问性能。HDFS 将文件切分成一系列的数据块,将这些数据块存储在集群中的多个节点上,实现以分布式方式存储和处理数据。
```java
// 示例代码
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileStatus;
public class HDFSExample {
public static void main(String[] args) {
try {
// 创建配置对象
Configuration conf = new Configuration();
// 获取文件系统实例
FileSystem fs = FileSystem.get(conf);
// 获取文件状态
FileStatus status = fs.getFileStatus(new Path("/path/to/file"));
// 打印文件大小
System.out.println("File size: " + status.getLen());
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
在以上示例代码中,我们使用 Java 编写了一个简单的 HDFS 示例,通过获取文件系统实例和文件状态,可以获得指定文件的大小。
### YARN:资源管理器
YARN(Yet Another Resource Negotiator)是 Hadoop 的资源管理器,用于管理集群中的计算资源。YARN 将集群资源划分为多个容器,分配给不同的应用程序进行计算任务。它支持多种类型的计算框架,如 MapReduce、Spark 等,并能够根据应用程序的需求进行动态分配和管理资源。
```python
# 示例代码
from yarn_api_client import ApplicationMaster, ApplicationMasterConfig
# 创建 ApplicationMasterConfig 对象
config = ApplicationMasterConfig()
# 设置应用程序名称
config.set_name("Example Application")
# 设置资源需求
config.set_memory(1024)
config.set_vcpus(2)
# 创建 ApplicationMaster 对象
am = ApplicationMaster(config)
# 提交应用程序
response = am.submit()
# 获取应用程序状态
status = am.get_status()
# 打印应用程序状态
print("Application status: " + status)
```
以上示例代码使用 Python 的 yarn_api_client 库创建了一个简单的 YARN 应用程序,并实现了提交应用程序和获取应用程序状态的功能。
### MapReduce:分布式计算框架
MapReduce 是 Hadoop 生态系统中的核心组件之一,用于处理大规模数据集的分布式计算。MapReduce 模型将计算任务分为两个阶段,即 Map 阶段和 Reduce 阶段。在 Map 阶段,数据被切分成多个片段,并由不同的计算节点进行处理;在 Reduce 阶段,计算节点将 Map 阶段输出的结果进行合并和归约,最终得到计算结果。
```java
// 示例代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
```
以上示例代码使用 Java 编写了一个经典的 WordCount MapReduce 程序,实现了对输入文本中单词出现次数的统计。
### HBase:分布式数据库
HBase 是一个分布式的、可扩展的、基于列的 NoSQL 数据库。它在 Hadoop 生态系统中扮演着存储和管理大规模结构化数据的角色。HBase 使用 HDFS 作为底层存储,以分布式方式提供对数据的读写操作,支持高吞吐量和低延迟的访问。
```python
# 示例代码
import happybase
# 创建连接
connection = happybase.Connection('localhost')
# 创建表
connection.create_table(
'example_table',
{
'cf1': dict(max_versions=10),
'cf2': dict(max_versions=1, block_cache_enabled=False),
'cf3': dict()
}
)
# 获取表
table = connection.table('example_table')
# 插入数据
table.put('row1', {'cf1:col1': 'value1', 'cf2:col2': 'value2'})
# 获取数据
row = table.row('row1')
print(row)
#
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏以“机器回答”为主题,通过一系列连载文章为读者全面介绍了Python编程语言以及机器学习领域的知识和技能。从编程入门到深度学习,涵盖了Python语言的基础语法、数据结构、函数和模块化编程、面向对象编程以及异常处理与调试技巧等内容。同时,还深入探讨了数据处理与分析的相关工具库,包括Pandas和Matplotlib,以及机器学习领域的重要概念和实践技术,如数据预处理、监督学习、无监督学习、深度学习、图像处理、自然语言处理、推荐系统等。此外,专栏还介绍了大数据处理与分布式计算原理,以及Hadoop生态系统的基本使用。通过本专栏,读者可以系统性地学习Python编程语言和机器学习领域的相关知识,为从事相关领域的工作或研究打下坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
正弦波在数学建模中的应用:微分方程与傅里叶级数的威力

# 1. 正弦波的数学基础
正弦波是一种特殊的周期性波形,其数学表达式为:
```
y = A * sin(2πft + φ)
```
其中:
* A 为波的振幅,表示波峰和波
多项式拟合在金融建模中的关键作用:预测未来,掌控风险

# 1. 多项式拟合概述**
多项式拟合是一种数学技术,用于通过多项式函数来近似给定数据集。多项式函数是一类具有幂次和常数项的代数表达式。在金融建模中,多项式拟合用于拟合金融数据,例如股票价格、利率和汇率。通过拟合这些数据,可以识别趋势、预测未来值并进行风险评估。
多项式拟合的优点包括其简单性和易于解释。它可以快速地拟合复杂的数据集,并产生易于理解的模型。然而,多项式拟
STM32单片机CAN总线通信:详解CAN协议、硬件配置和应用的秘籍
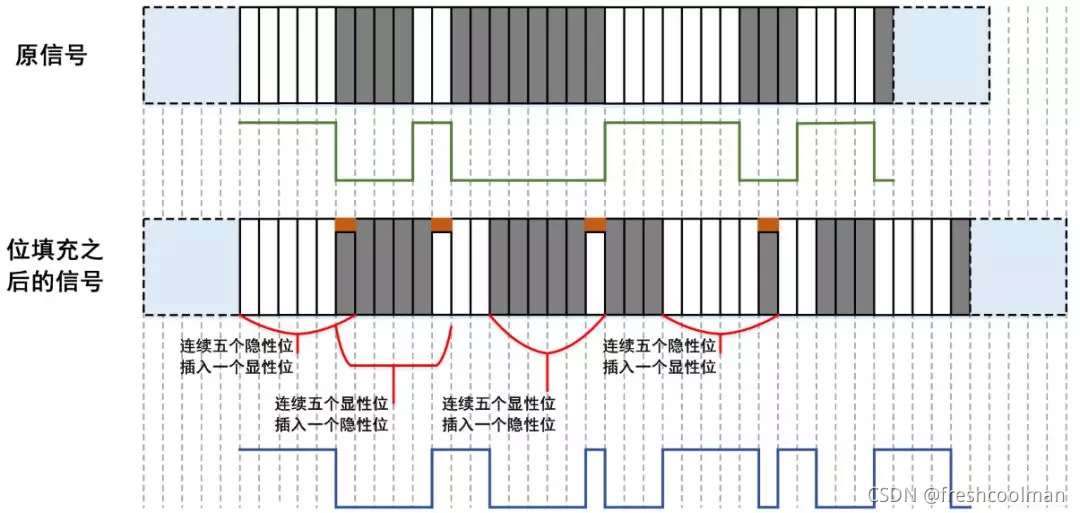
# 1. CAN总线简介**
CAN(控制器局域网络)总线是一种广泛应用于工业控制、汽车电子和医疗设备等领域的串行通信协
FIR滤波器在声纳系统中的应用:水下信号处理和目标识别,让声纳系统更清晰

# 1. 声纳系统概述**
声纳系统是一种利用声波在水下传播的特性,探测、定位和识别水下目标的设备。它广泛应用于海洋探索、军事侦察、渔业探测等领域。
MySQL数据库事务处理机制详解:确保数据一致性和完整性
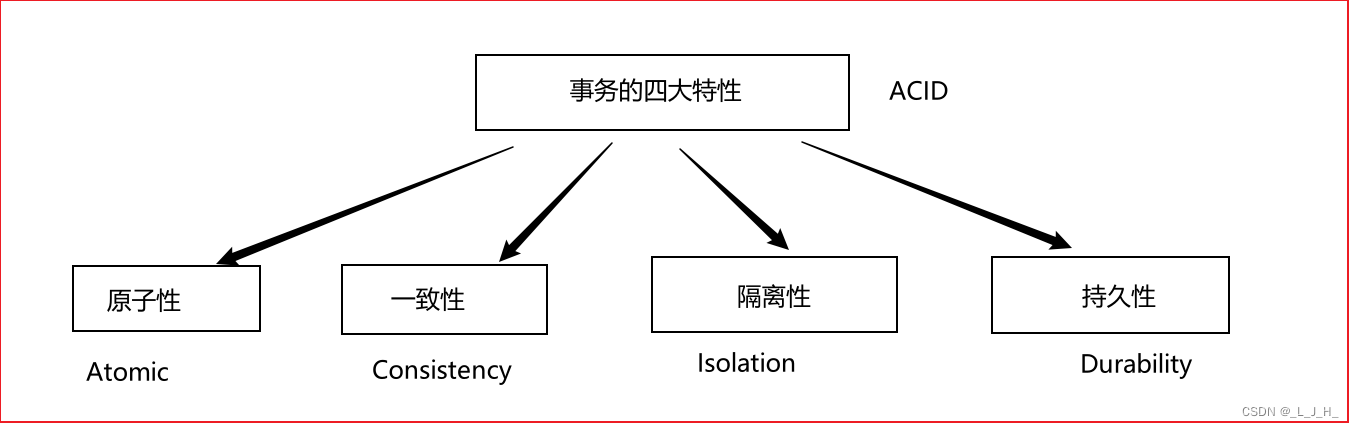
# 1. MySQL数据库事务基础**
事务是数据库中一个逻辑操作单元,它包含一系列对数据库的操作,要么全部成功执行,要么全部失败回滚。事务确保了数据库数据的完整性和一致性。
事务具有以下特性:
* **原子性(Atomicity):**事务中的所有操作要么全部成功执行,要么全部失败回滚。
* **一致性(Consistency):**事务执行前后,数据库必须处于一致状态,即满足所
DFT在土木工程中的应用:结构分析与地震工程的秘密武器

# 1. DFT的基本原理**
DFT(离散傅里叶变换)是一种数学变换,它将时域信号转换为频域信号。时域信号表示信号随时间的变化,而频域信号表示信号中不同频率成分的幅度和相位。
STM32单片机项目实战秘籍:从硬件设计到软件开发,打造完整单片机项目
# 1. STM32单片机项目实战概述
**1.1 STM32单片机简介**
STM32单片机是意法半导体(STMicroelectronics)公司推出的32位微控制器系列,基于ARM Cortex-M内核,具有高性能、低功耗、丰富的外设和广泛的应用领域。
**1.2 项目实战概述**
本项目实战将
STM32故障诊断与调试技术:12个技巧,揭秘系统故障幕后真凶

# 1. STM32故障诊断与调试概述**
STM32故障诊断与调试是识别和解决STM32系统故障的关键技术。它涉及硬件和软件故障的检测、分析和修复。通过掌握这些技巧,工程
51单片机单总线应用案例:从键盘扫描到LCD显示,实战解析
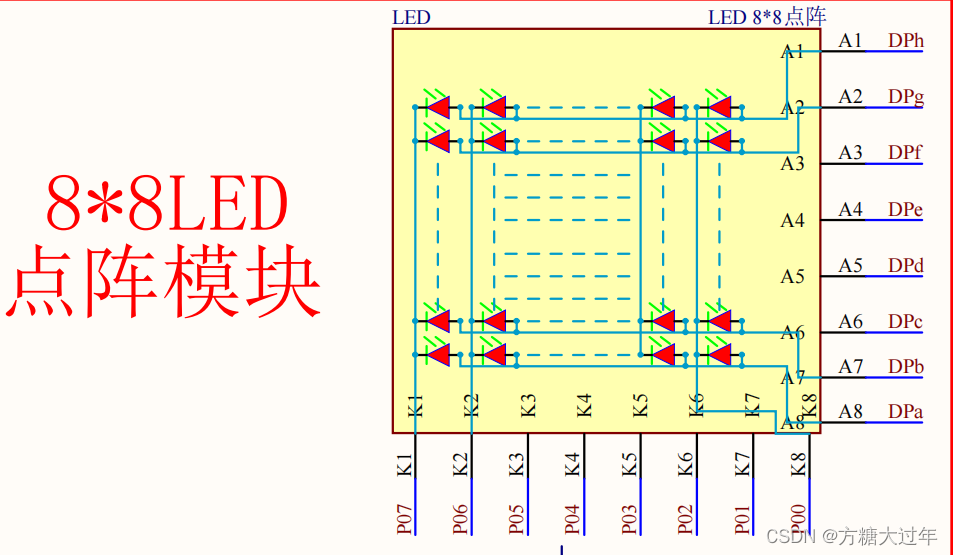
# 1. 51单片机单总线简介
51单片机单总线是一种简化的总线结构,它仅包含数据总线和地址总线,不包含控制总线。这种结构使得51单片机具有成本低、功耗小、体积小的优点,非常适合于低端控制应用。
单总线的工作原理是:CPU通过地址总线向外设发送地址信号,指定要访问的外设;然后通过数据总线与外设进行数据交换。这种方式可以简化总线结构,降低系统成本。
# 2. 键盘扫描原理与实现
### 2.1
STM32单片机嵌入式Linux应用指南:移植、配置与开发,解锁无限可能
# 1. STM32单片机嵌入式Linux简介
嵌入式Linux是一种针对嵌入式系统定制的Linux操作系统,它具有体积小、资源占用低、可移植性强等特点,广泛应用于物联网、工业控制、汽车电子等领域。
STM32单片机是意法半导体公司推出的32位微控制器系列,以其高性能、低功耗、丰富的外设而著称。将嵌入式Linux移植到STM32单片机上,可以充分发挥STM32的硬件
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )