利用winner1300进行大数据分析的基本原理
发布时间: 2024-04-14 15:16:48 阅读量: 74 订阅数: 28 

# 1. 背景介绍
大数据分析是指通过对海量、高维、异构数据的采集、存储、处理和分析,从中挖掘出有价值的信息和知识的过程。在当今信息爆炸的时代,数据分析扮演着至关重要的角色,能够帮助企业做出科学决策、发现潜在市场机会和优化运营效率。winner1300作为一种强大的大数据分析工具,具有高效、灵活和可扩展等特点,广泛应用于金融、电商、医疗等领域。其使用需求随着大数据的快速增长而不断提升。通过winner1300,用户可以运用各种算法和技术,深入挖掘数据背后的规律,为企业决策提供科学依据,极大地推动了数据驱动决策的发展。
# 2. winner1300的基本原理解析
### 2.1 winner1300的工作原理
#### 2.1.1 winner1300的架构与组件
winner1300的架构包括数据采集模块、数据处理模块和数据展示模块。数据采集模块负责从各种数据源获取数据,包括结构化数据、半结构化数据和非结构化数据。数据处理模块则用于对采集到的数据进行清洗、转换和存储,以便后续的分析和挖掘。数据展示模块则提供用户友好的界面,帮助用户查看分析结果。
#### 2.1.2 数据处理流程概述
winner1300的数据处理流程主要分为数据采集、数据清洗、数据存储和数据分析几个步骤。在数据采集阶段,系统会从不同的数据源获取数据,并将其转化成统一的数据格式;接着在数据清洗阶段,系统会对数据进行清洗、去重、缺失值处理等操作;数据存储阶段会将清洗后的数据存储在数据库或数据仓库中;最后,在数据分析阶段,系统会运行各种数据分析算法,生成报告或结论。
### 2.2 winner1300的数据存储与处理机制
#### 2.2.1 数据存储方式分析
winner1300采用分布式存储和计算的方式来存储和处理大数据。它通常会使用Hadoop分布式文件系统(HDFS)作为存储后端,利用Hive、Presto等工具进行数据查询和分析。此外,winner1300还支持数据的实时处理和分析,可以通过Spark Streaming、Flink等流处理框架来实现。
#### 2.2.2 数据处理流程详解
数据处理流程包括数据的读取、转换、计算和存储几个步骤。首先,系统会从数据源读取数据,然后经过ETL(Extract-Transform-Load)流程进行数据转换和清洗;接着进行数据计算,运行各种算法进行数据分析;最后将结果存储在数据库或数据仓库中,以便后续查询和展示。
#### 2.2.3 数据计算与分析的实现原理
数据计算和分析主要依赖于数据处理引擎和算法。winner1300通常会使用MapReduce、Spark等计算引擎来进行数据计算,支持分布式计算和并行处理;同时,系统中也会集成各种数据挖掘和机器学习算法,用于模式识别、分类、预测等数据分析任务。这些算法通过并行计算,加速大规模数据的处理和分析过程。
```python
# 伪代码示例: 数据清洗
import pandas as pd
# 读取数据
data = pd.read_csv('data.csv')
# 数据清洗
cleaned_data = data.drop_duplicates().dropna()
# 存储清洗后的数据
cleaned_data.to_csv('cleaned_data.csv')
```
```mermaid
graph LR
A[数据采集] --> B{数据清洗}
B --> C{数据存储}
C --> D{数据分析}
```
在winner1300的架构中,数据处理模块负责从不同来源的数据源获取原始数据,进行数据清洗和转换,然后将处理后的数据存储在数据库中,最终进行数据分析并生成可视化报告。整个流程涵盖了数据处理的各个环节,确保了大数据分析的高效性和准确性。
# 3. winner1300数据分析应用实践
### 3.1 数据采集与清洗
数据分析的第一步是数据采集与清洗,这一过程对后续的分析具有至关重要的作用。
#### 3.1.1 数据源选择与接入
在数据采集阶段,需要选择适合的数据源,并建立与数据源的连接,以确保数据能够被成功获取。
```python
# 示例代码:使用winner1300连接到MySQL数据库进行数据获取
import pymysql
# 连接到MySQL数据库
conn = pymysql.connect(host='localhost', user='root', password='password', database='sample_db')
cursor = conn.cursor()
# 执行SQL查询
cursor.execute("SELECT * FROM table_name")
# 获取数据
data = cursor.fetchall()
# 关闭连接
cursor.close()
conn.close()
```
#### 3.1.2 数据清洗与预处理
数据清洗是指对数据进行去重、缺失值处理、异常值处理等操作,以保证数据的质量和完整性。
```python
# 示例代码:使用winner1300对数据进行清洗处理
import pandas as pd
# 创建DataFrame
df = pd.DataFrame(data, columns=['col1', 'col2', 'col3'])
# 去重
df.drop_duplicates(inplace=True)
# 缺失值处理
df.fillna(0, inplace=True)
# 异常值处理
df = df[(df['col1'] > 0) & (df['col2'] < 100)]
```
### 3.2 数据挖掘与分析
数据清洗完成后,接下来是数据挖掘与分析阶段,利用winner1300强大的计算能力进行数据探索和挖掘。
#### 3.2.1 数据挖掘算法的应用
winner1300支持各种数据挖掘算法的应用,包括聚类、分类、回归等,以发掘数据中隐藏的规律和关联。
```python
# 示例代码:使用winner1300进行K-Means聚类分析
from sklearn.cluster import KMeans
# 创建K-Means模型
kmeans = KMeans(n_clusters=3)
# 拟合模型
kmeans.fit(df[['col1', 'col2']])
# 预测分类
df['cluster'] = kmeans.predict(df[['col1', 'col2']])
```
#### 3.2.2 数据可视化与报告
数据分析结果可通过数据可视化展现,帮助用户更直观地理解分析结果和趋势。
```python
# 示例代码:使用matplotlib进行数据可视化
import matplotlib.pyplot as plt
# 绘制散点图
plt.scatter(df['col1'], df['col2'], c=df['cluster'], cmap='rainbow')
plt.xlabel('col1')
plt.ylabel('col2')
plt.title('K-Means Clustering Result')
plt.show()
```
流程图如下:
```mermaid
graph LR
A[数据清洗] --> B[数据挖掘]
B --> C[模型构建]
C --> D[模型优化]
D --> E[结果解读]
```
### 3.3 模型构建与优化
在数据分析中,模型构建和优化是至关重要的环节,直接影响到最终的分析结果和预测准确度。
#### 3.3.1 模型选择与建立
根据业务需求和数据特征,选择合适的模型进行建模,进行模型训练和评估。
```python
# 示例代码:使用winner1300构建回归模型
from sklearn.linear_model import LinearRegression
# 创建线性回归模型
model = LinearRegression()
# 拟合模型
model.fit(df[['col1']], df['col2'])
# 打印模型系数
print('Coefficients:', model.coef_)
```
#### 3.3.2 模型优化与性能评估
通过交叉验证、参数调优等方法对模型进行优化,评估模型性能并调整参数以提升模型准确度。
```python
# 示例代码:使用winner1300进行模型性能评估
from sklearn.metrics import mean_squared_error
# 预测
pred = model.predict(df[['col1']])
# 计算均方误差
mse = mean_squared_error(df['col2'], pred)
print('Mean Squared Error:', mse)
```
### 结语
数据分析是当今企业决策的重要工具,而winner1300作为强大的大数据分析工具,通过数据采集、清洗、分析和建模,帮助企业发现价值,实现业务增长和优化。
以上是winner1300数据分析应用的实践过程,通过这一系列流程,用户可以全面了解数据的价值和潜力,并据此进行决策和预测。
# 4.1 人工智能与大数据融合
人工智能和大数据是当今科技领域的两大热门话题,它们的结合被誉为未来科技发展的关键驱动力。大数据为人工智能提供了海量的数据支持,而人工智能则赋予了大数据更深层次的分析和应用能力。在当前信息爆炸的时代,人工智能与大数据的融合已经成为众多行业发展的核心。
#### 4.1.1 智能化数据分析的需求
随着数据量的爆炸式增长,传统的数据处理方法已经无法满足对数据的高效利用。智能化数据分析依托人工智能技术,可以更深入地挖掘数据背后的价值,帮助企业实现更精准的决策和优化流程。智能化数据分析的需求在各个行业中日益凸显。
#### 4.1.2 winner1300在人工智能领域的发展展望
winner1300作为一款强大的大数据分析工具,将更多人工智能技术引入其体系,有望构建出更为智能化的数据分析平台。通过整合机器学习、深度学习等技术,winner1300将实现更精准、更高效的数据分析和预测能力,为用户提供更多智能化的数据处理方案。winner1300在不断演进中,将成为人工智能与大数据融合发展的重要推动力量。
### 4.2 面向未来的winner1300发展方向
未来,随着人工智能和大数据技术的不断发展,winner1300面临着更多的机遇和挑战。如何更好地融合人工智能技术,提升数据处理和分析的智能化水平,将成为winner1300未来发展的关键方向。
#### 4.2.1 社会化数据分析的挑战与机遇
社会化数据分析是未来大数据发展的重要方向之一,winner1300需要面对社交网络、在线评论等海量数据的挖掘和分析。如何从这些数据中发掘用户需求、行业趋势等关键信息,将是winner1300未来发展的挑战与机遇。
#### 4.2.2 云端服务与智能化分析的融合
随着云计算技术的普及,winner1300有望借助云端服务实现更大规模数据处理和存储能力。同时,结合智能化分析技术,winner1300将更加高效地提供数据分析服务,为用户带来更全面、更智能的数据解决方案。云端服务与智能化分析的融合将成为winner1300未来发展的重要方向。
# 5. winner1300大数据分析的未来趋势
在信息技术快速发展的背景下,winner1300作为一款强大的大数据分析工具,也随着时代的潮流不断演进和发展。未来,winner1300在大数据分析领域将面临更多挑战与机遇,需要不断创新和改进。以下将探讨winner1300在未来发展中的趋势和展望。
1. **人工智能与大数据融合**
1.1 智能化数据分析的需求
- 随着数据量的不断增大,传统的数据处理和分析方法已经无法满足需求,需要更智能化的技术来处理大规模的数据。
- 人工智能技术的发展为大数据分析提供了新的契机,通过机器学习、深度学习等技术可以更好地挖掘数据中的价值信息。
1.2 winner1300在人工智能领域的发展展望
- winner1300作为一款先进的大数据分析工具,未来将更加注重与人工智能的融合,提供更智能化的数据分析服务。
- 可以预见,winner1300将加强对机器学习和人工智能算法的支持,实现更智能、更高效的大数据分析功能。
2. **面向未来的winner1300发展方向**
2.1 社会化数据分析的挑战与机遇
- 随着社交网络和互联网的普及,社会化数据逐渐成为重要的数据来源,但也带来了数据分析上的挑战,winner1300需要不断改进数据处理能力。
- 社会化数据的广泛涉猎给winner1300带来了更多的数据分析可能性,能够更全面地了解用户行为和社会趋势。
2.2 云端服务与智能化分析的融合
- 云计算技术的发展为大数据分析提供了便利的环境,winner1300可以借助云端服务快速扩展计算资源,提高数据处理效率。
- 未来winner1300有望与云服务商合作,提供更智能化、快速响应的数据分析解决方案,更好地满足用户需求。
3. **总结与展望**
3.1 winner1300在大数据分析的价值
- winner1300作为一款强大的大数据分析工具,为用户提供了丰富的数据处理和分析功能,帮助用户更好地理解和利用数据。
- 未来winner1300将继续发挥作用,为用户提供更智能、更高效的数据分析服务,促进数字化转型和创新发展。
3.2 未来winner1300发展的方向
- 未来winner1300将不断融合人工智能技术,提供更智能化的数据分析解决方案,满足用户日益增长的数据分析需求。
- 社会化数据与云端服务的融合将成为winner1300发展的重要方向,带来更广阔的发展空间和应用场景。
通过不断创新和改进,winner1300在大数据分析的未来发展中将持续发挥重要作用,助力用户更好地实现数据驱动决策,推动行业数字化转型和发展。未来winner1300有望实现更广泛的应用和更高效的数据分析服务,成为大数据时代的重要利器。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏 "winner1300" 深入探讨了该平台的各个方面,涵盖了从开发环境配置到安全防护、性能优化和数据分析等广泛主题。它提供了分步指南、最佳实践和故障排除技巧,帮助开发人员充分利用 winner1300 的强大功能。专栏还深入研究了 winner1300 的架构设计思想、并发控制机制和网络安全挑战,为读者提供了对该平台全面而深入的理解。此外,它还讨论了大数据分析、容器化部署、CI/CD 流程、日志分析和监控等高级主题,为读者提供了构建和维护高性能、可扩展和安全的 winner1300 应用程序所需的关键知识。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【51单片机矩阵键盘扫描终极指南】:全面解析编程技巧及优化策略

# 摘要
本论文主要探讨了基于51单片机的矩阵键盘扫描技术,包括其工作原理、编程技巧、性能优化及高级应用案例。首先介绍了矩阵键盘的硬件接口、信号特性以及单片机的选择与配置。接着深入分析了不同的扫
【Pycharm源镜像优化】:提升下载速度的3大技巧

# 摘要
Pycharm作为一款流行的Python集成开发环境,其源镜像配置对开发效率和软件性能至关重要。本文旨在介绍Pycharm源镜像的重要性,探讨选择和评估源镜像的理论基础,并提供实践技巧以优化Pycharm的源镜像设置。文章详细阐述了Pycharm的更新机制、源镜像的工作原理、性能评估方法,并提出了配置官方源、利用第三方源镜像、缓存与持久化设置等优化技巧。进一步,文章探索了多源镜像组
【VTK动画与交互式开发】:提升用户体验的实用技巧
# 摘要
本文旨在介绍VTK(Visualization Toolkit)动画与交互式开发的核心概念、实践技巧以及在不同领域的应用。通过详细介绍VTK动画制作的基础理论,包括渲染管线、动画基础和交互机制等,本文阐述了如何实现动画效果、增强用户交互,并对性能进行优化和调试。此外,文章深入探讨了VTK交互式应用的高级开发,涵盖了高级交互技术和实用的动画
【转换器应用秘典】:RS232_RS485_RS422转换器的应用指南
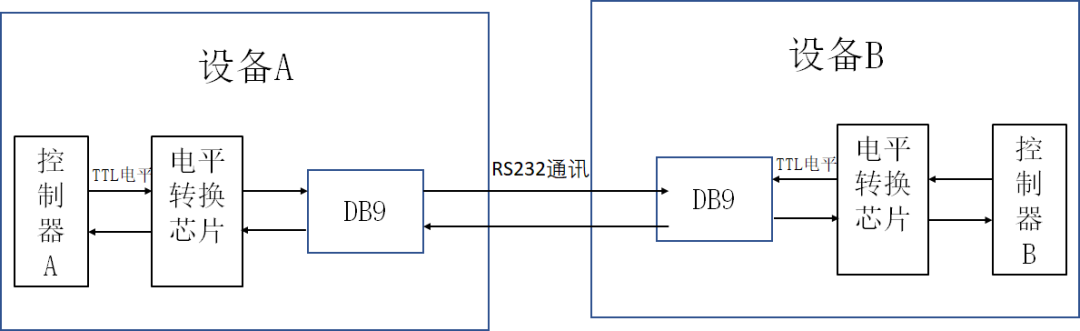
# 摘要
本论文全面概述了RS232、RS485、RS422转换器的原理、特性及应用场景,并深入探讨了其在不同领域中的应用和配置方法。文中不仅详细介绍了转换器的理论基础,包括串行通信协议的基本概念、标准详解以及转换器的物理和电气特性,还提供了转换器安装、配置、故障排除及维护的实践指南。通过分析多个实际应用案例,论文展示了转
【Strip控件多语言实现】:Visual C#中的国际化与本地化(语言处理高手)

# 摘要
本文全面探讨了Visual C#环境下应用程序的国际化与本地化实施策略。首先介绍了国际化基础和本地化流程,包括本地化与国际化的关系以及基本步骤。接着,详细阐述了资源文件的创建与管理,以及字符串本地化的技巧。第三章专注于Strip控件的多语言实现,涵盖实现策略、高级实践和案例研究。文章第四章则讨论了多语言应用程序的最佳实践和性能优化措施。最后,第五章通过具体案例分析,总结了国际化与本地化的核心概念,并展望了未来的技术趋势。
# 关
C++高级话题:处理ASCII文件时的异常处理完全指南
# 摘要
本文旨在探讨异常处理在C++编程中的重要性以及处理ASCII文件时如何有效地应用异常机制。首先,文章介绍了ASCII文件的基础知识和读写原理,为理解后续异常处理做好铺垫。接着,文章深入分析了C++中的异常处理机制,包括基础语法、标准异常类使用、自定义异常以及异常安全性概念与实现。在此基础上,文章详细探讨了C++在处理ASCII文件时的异常情况,包括文件操作中常见异常分析和异常处理策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )