【Fluent中文帮助文档精读指南】:全面掌握流式处理技术(第一章至第二十章)
发布时间: 2024-12-15 08:14:33 阅读量: 5 订阅数: 3 

参考资源链接:[Fluent 中文帮助文档(1-28章)完整版 精心整理](https://wenku.csdn.net/doc/6412b6cbbe7fbd1778d47fff?spm=1055.2635.3001.10343)
# 1. Fluent中文帮助文档概述
Fluent 是一个专门用于流式数据处理的开源框架,它通过一个简单而强大的编程模型,帮助工程师和开发者们构建可扩展且可靠的实时数据系统。在这一章中,我们将对Fluent中文帮助文档作一个快速的概述,帮助您快速掌握该文档的结构和内容,以便后续更深入的学习和应用。
首先,文档对Fluent的主要功能和特性进行了说明,包括其流式处理的基本概念、组件和扩展机制。接着,文档详细介绍了如何安装和配置Fluent环境,包括不同操作系统下的安装步骤以及环境变量的设置。
在对文档进行深入了解之前,需要理解Fluent的核心设计哲学,即“简单而强大”。这种设计理念贯穿于整个Fluent框架,使得即便是复杂的数据流也可以通过简洁的代码实现。文档中还强调了Fluent的可扩展性和与其他系统的集成能力,这对于需要进行定制开发的用户来说非常重要。
紧接着,文档转向Fluent的具体应用,包括数据流的创建、管理,以及流式数据处理的各种操作。其中,数据流的创建是理解Fluent的基础,这涉及到如何定义数据源、如何配置数据流以及如何对数据流进行监控和调整。而数据处理操作实践部分,则通过具体的组件使用和案例分析,展示了Fluent如何有效地进行流式数据处理。
整体上,Fluent中文帮助文档为用户提供了一个全面、系统的学习路径。无论是新手还是有经验的开发者,都能够通过阅读文档中的每个章节,逐步构建起对Fluent的深入理解和使用能力。同时,文档还包含了Fluent的高级特性与优化策略,这部分内容将帮助用户更好地利用Fluent进行高级应用开发和系统优化。
本章旨在为读者提供一个清晰的入口,让你们能够从整体上把握Fluent中文帮助文档的结构和重点,为接下来的深入学习打下坚实的基础。
# 2. Fluent基础流式处理理论
流式处理是一种在计算机科学中广泛应用的技术,它允许应用程序处理连续的数据流。Fluent是一个高性能、可扩展的流式处理框架,它提供了一种编程模型,以便开发者可以编写可以处理实时数据流的应用程序。本章将对Fluent的基础理论进行探讨,并分析其在流式处理中的角色。
## 2.1 流式处理的定义与原理
### 2.1.1 流式处理概念解析
流式处理是一种处理无边界数据集的技术,其核心在于处理到达的每个数据点,而不是等待所有数据集完整。这一方法在大数据处理、物联网、金融交易分析等领域中尤为重要,因为它们需要实时或接近实时地分析数据。
在Fluent框架中,数据流被视为一个连续的事件序列。每个事件是一个数据点,可以包含多个字段,例如时间戳、值等。Fluent通过定义数据流来处理这些事件,并且可以设置各种操作符来转换、过滤和聚合数据流。
### 2.1.2 流式处理与批处理的区别
批处理和流式处理是数据处理的两种主要方法。批处理将数据集分为固定大小的数据块,然后在这些数据块上执行计算。批处理的优势在于它易于实现、并行处理能力较强,并且适合于大规模数据集的处理。
相比之下,流式处理不需要等待所有数据到达再进行处理。它允许应用程序在数据到达时就立即对其进行处理,这使得流式处理非常适合于需要低延迟处理的应用场景。
Fluent之所以在流式处理领域中脱颖而出,是因为其设计的灵活性和扩展性。它支持事件时间和处理时间的差异,允许开发者更精确地控制数据流的处理逻辑。
## 2.2 Fluent在流式处理中的角色
### 2.2.1 Fluent框架简介
Fluent是一个开源项目,它提供了一种简明的编程模型,用于处理和分析数据流。Fluent的核心是一个事件驱动的异步处理系统,它通过一系列的组件来处理数据流。
在Fluent框架中,流是由一系列的事件构成,这些事件可以由Source组件产生,并通过各种操作符进行处理,最终被Sink组件输出。Fluent提供了强大的连接器和适配器,使得与外部数据源的集成变得非常方便。
### 2.2.2 Fluent与其他流式处理工具的比较
在流式处理的生态系统中,Fluent并不是唯一的工具。Apache Kafka、Apache Flink、Apache Storm等都是这一领域的知名工具。与这些工具相比,Fluent具有以下几个显著的优势:
- 易于使用和部署:Fluent的API设计简洁直观,使得开发者可以快速上手。
- 强大的连接性和适应性:Fluent提供了丰富的连接器,能够处理各种不同的数据源和输出目标。
- 高性能:Fluent能够进行高度优化的事件处理,并且在分布式环境中的扩展性很好。
这些优势使得Fluent在流式处理领域中占据了独特的地位,为开发者提供了强大的工具来构建复杂的实时数据应用。
## 2.3 流式数据的来源和收集
### 2.3.1 数据源的种类与特性
在流式处理的上下文中,数据源可以是任何生成数据流的系统。这些数据源的种类繁多,包括网络日志、社交媒体、传感器数据等。它们的共同特性在于产生数据的速度可能是非常快的,并且数据的到达可能是不均匀的。
Fluent支持多种数据源,包括但不限于Kafka、TCP/UDP套接字和HTTP请求。它能够处理结构化、半结构化和非结构化数据,这使得Fluent成为一个非常灵活的工具。
### 2.3.2 数据收集技术与实践
数据收集是流式处理的第一步,也是非常关键的一个环节。正确地收集数据对于确保数据质量、及时性和完整性至关重要。
Fluent提供了多种数据收集技术,例如Fluentd、Fluent Bit等,它们都能够从各种来源收集数据,并将数据输入到处理流程中。在实践中,这些数据收集器可以根据应用需求进行配置,比如过滤不需要的数据、添加额外的元数据等,以便更好地进行数据处理。
在配置Fluent以收集数据时,开发者需要考虑如何优化性能和资源利用,同时确保数据的准确性和完整性。这通常涉及到日志级别的选择、缓冲机制的配置以及如何处理可能的数据丢失或重复问题。
在本章节的探讨中,我们了解了流式处理的基础理论,Fluent框架在流式处理中的角色以及如何通过Fluent进行数据的来源和收集。这些基础知识构成了使用Fluent进行更复杂流式数据处理的基础。接下来,我们将深入探讨Fluent环境的配置与安装,以及如何进行有效的数据处理操作实践。
# 3. Fluent环境配置与安装
在深入探讨Fluent的安装和配置之前,我们需要了解安装Fluent的系统环境要求。这包括对硬件和软件的要求,以及网络设置和依赖项。接下来,我们将会详细解释Fluent安装的步骤,并提供配置Fluent运行环境的最佳实践。这将为后续章节中Fluent数据处理操作和高级应用的探讨奠定基础。
### 3.1 系统环境要求
Fluent作为一个流式处理框架,在不同的系统环境下,可能需要不同的配置和优化。理解这些要求对于确保Fluent能够高效稳定地运行至关重要。
#### 3.1.1 硬件和软件环境准备
Fluent对硬件的要求较为灵活,但推荐的基本配置为至少1GB的RAM以及一个双核处理器。考虑到Fluent的流式处理特性,对I/O的读写速度和网络带宽有一定要求,特别是在处理大量实时数据流时。在软件环境方面,Fluent支持跨平台运行,包括但不限于Linux、macOS以及Windows。
#### 3.1.2 网络设置与依赖项
为了确保Fluent节点间的高效通信和数据传输,网络设置需要优化,包括网络带宽和延迟。具体而言,应避免在不同地理位置的Fluent节点间进行数据传输,以减少数据传输时间。关于依赖项,Fluent需要依赖于Java运行环境(JRE)或Java开发工具包(JDK),版本需为Java 8或更高版本。同时,Fluent也依赖于Apache Kafka用于消息队列和事件流的分发。
### 3.2 Fluent安装步骤详解
安装Fluent涉及下载合适的发行版和执行一系列安装步骤。为确保安装成功,还需进行安装验证和故障排除。
#### 3.2.1 下载与安装流程
首先,从Fluent的官方网站下载最新版本的安装包。下载完成后,解压安装包到指定目录。在Linux或macOS系统中,可以使用命令行解压,例如:
```bash
tar -xzf fluentd.tar.gz
cd fluentd
```
在Windows系统中,使用相应的压缩软件解压即可。安装Fluent之前,确保Java环境已经正确安装。接下来,需要配置Fluent。这包括修改配置文件`fluent.conf`,设置正确的输入和输出源,以及网络参数等。
#### 3.2.2 安装验证与故障排除
安装完成后,应通过运行一些基本的命令来验证Fluent是否安装成功,并能够正常工作。以下是在命令行中启动Fluent并检查其状态的命令:
```bash
./fluentd -c fluent.conf -v
```
这条命令会启动Fluent,并在详细模式下运行(`-v`表示详细模式),查看日志输出,确保没有错误信息出现。如果遇到问题,需要根据错误信息进行故障排除。
### 3.3 配置Fluent运行环境
正确的配置是确保Fluent稳定运行的前提。这包括对Fluent配置文件的解析和优化,以及环境变量的设置和管理。
#### 3.3.1 配置文件解析与优化
Fluent的配置文件`fluent.conf`是整个系统的灵魂。一个典型的`fluent.conf`配置文件示例如下:
```xml
<system>
workers 2
log_level info
</system>
<match **>
@type forward
port 24224
bind 0.0.0.0
</match>
```
在上面的配置中,`<system>`部分定义了系统级别的配置,例如工作进程数和日志级别。`<match>`标签定义了消息的输出方式。此处配置为将所有消息转发到远程Fluentd节点上。需要注意的是,配置文件中的参数应根据实际需求进行调整,例如增加更多的缓冲和重试策略来优化性能。
#### 3.3.2 环境变量的设置和管理
设置环境变量有助于管理和运行Fluent。在Linux和macOS中,可以通过`.bashrc`或`.zshrc`文件来永久设置环境变量。例如,添加如下行到`.bashrc`文件:
```bash
export FLUENTD_CONF=fluent.conf
export PATH=$PATH:/path/to/fluentd/bin
```
设置好环境变量后,需要重新加载配置文件使改动生效。对于Windows系统,可以在系统的“环境变量”设置中添加相应的条目。
通过以上步骤,我们可以完成Fluent的环境配置和安装,为后续的数据处理操作和高级应用打下坚实的基础。在第四章中,我们将进一步深入了解Fluent数据处理操作的具体实践,包括数据流的创建、管理和流式数据处理案例分析等。
# 4. Fluent数据处理操作实践
## 4.1 数据流的创建与管理
在构建流式数据处理系统时,创建和管理数据流是基础工作。本章节将详细介绍如何在Fluent中定义数据流,监控其状态,并进行相应的调整。
### 4.1.1 数据流的定义与创建
在Fluent中,数据流由一系列的组件组成,这些组件通过流式处理逻辑互相连接。要创建一个数据流,首先需要定义源组件(Source),它负责收集原始数据,并将数据引入数据流。接着,定义转换组件(Transform),对数据进行处理。最后,通过输出组件(Sink)将处理后的数据输出。
```json
# 定义一个Fluent配置文件,用于创建数据流
{
"source": {
"type": "file",
"path": "/path/to/logfile.log",
"format": "text",
"codec": "line",
"poll_interval": "1s"
},
"transform": {
"type": "parser",
"format": "json",
"parse_map": {
"message": "log",
"timestamp": "timestamp"
}
},
"sink": {
"type": "console",
"encoding": "json"
}
}
```
在上述配置文件中,我们定义了一个简单的数据流,它从一个文件中读取文本格式的日志文件,将其解析为JSON格式,并最终将解析后的数据输出到控制台。
### 4.1.2 数据流状态监控与调整
数据流一旦创建,就需要对其进行监控,确保数据流动的稳定性和性能。Fluent提供了一系列的命令和API来监控数据流的状态,例如使用`fluentd --show脱`命令可以显示当前运行的数据流实例状态。此外,Fluent的监控插件提供了丰富的监控图表,可以帮助开发者及时了解数据流的吞吐量、缓存使用情况等。
```bash
# 显示Fluentd当前运行状态的命令
fluentd --show脱
```
监控到数据流异常时,可以通过调整参数或者重新配置组件来优化数据流。例如,如果发现某个转换组件处理速度跟不上,可能需要调整缓冲区大小,或者将转换逻辑优化为更高效的处理方式。
## 4.2 数据处理组件的使用
在数据流中,组件的使用是实现复杂数据处理逻辑的关键。Fluent提供了丰富的源组件、输出组件以及各种转换组件,使得数据流的处理既灵活又高效。
### 4.2.1 源组件(Source)与输出组件(Sink)
源组件(Source)是数据流的起点,它负责从各种数据源收集数据。Fluent内置了多种源组件,如File、HTTP、TCP等,每种都有其特定的配置方式。输出组件(Sink)则决定数据流的终点,常见的输出组件有File、HTTP、Elasticsearch等。根据不同的需求,用户可以选择合适的源和输出组件来构建数据流。
```xml
# Fluentd配置文件示例,定义了File源组件和Elasticsearch输出组件
<source>
@type file
path /path/to/access.log
format json
tag my_access_log
</source>
<sink>
@type elasticsearch
host elasticsearch.example.com
port 9200
logstash_format true
logstash_prefix my_index
</sink>
```
在上述配置中,我们使用了File源组件来读取JSON格式的access.log文件,并将解析后的数据通过Elasticsearch输出组件发送到Elasticsearch服务器。
### 4.2.2 数据处理与转换组件
数据处理与转换是Fluent中的核心功能之一,它允许开发者在数据流中嵌入各种处理逻辑,比如过滤、选择、聚合等。Fluent提供了Filter插件和Parser插件,使得数据处理更加灵活。Filter插件允许开发者根据预设条件对事件进行过滤或修改;而Parser插件则负责对事件中的数据进行解析,转换为结构化格式。
```xml
<filter my_access_log>
@type record_transformer
enable_ruby true
<record>
user_id ${event["user_id"]}
action ${event["action"]}
</record>
</filter>
```
以上配置中,我们定义了一个Record Transformer Filter插件,使用Ruby代码将access.log中的数据解析为`user_id`和`action`两个字段。
## 4.3 流式数据处理案例分析
在实际应用中,Fluent的数据处理能力体现在复杂的流式数据处理场景中。本节通过案例分析,深入讲解Fluent在不同场景下的应用和效果。
### 4.3.1 实时数据处理流程
实时数据处理流程要求数据能够快速被收集、处理并响应。以实时日志分析为例,我们需要快速处理服务器上生成的日志文件,以监控系统的健康状态,及时发现和响应问题。本案例中,我们将构建一个实时日志分析的数据流,实现从日志收集到实时分析的完整流程。
```xml
<match my_access_log>
@type elasticsearch
host elasticsearch.example.com
port 9200
logstash_format true
logstash_prefix my_index
flush_interval 10s
</match>
```
上述配置中的`<match>`块定义了对名为`my_access_log`的日志流进行处理。我们使用Elasticsearch作为输出组件,将数据实时索引到Elasticsearch中。`flush_interval`参数设置为10秒,意味着数据每10秒会被批量发送到Elasticsearch。
### 4.3.2 复杂事件处理(CEP)应用实例
复杂事件处理(Complex Event Processing, CEP)是流式数据处理中的一个高级应用。它允许对流式事件进行模式识别、聚合、关联等操作。在Fluent中,我们可以通过定义一系列的Filter和Transform组件来实现CEP。例如,在金融交易系统中,我们可能需要监控和分析特定的交易模式,以检测欺诈行为。
```xml
<filter my_transaction>
@type record_transformer
enable_ruby true
<record>
timestamp ${event["timestamp"]}
amount ${event["amount"]}
user_id ${event["user_id"]}
</record>
</filter>
<filter my_transaction>
@type aggregate
emit_mode interval
interval 1m
cache_size 10000
<aggregate>
user_id ${user_id}
@type sum
field amount
tag total_amount
</aggregate>
</filter>
```
在上述配置中,我们首先使用Record Transformer Filter将交易事件转换为包含`timestamp`、`amount`和`user_id`的结构化记录。然后,我们使用Aggregate Filter每分钟计算每个用户的交易总金额,并输出到`total_amount`标签。这个CEP流程可以帮助我们实时监控用户的交易行为。
## 章节小结
本章通过详细介绍Fluent中数据流的创建、管理和监控方法,使读者能够深刻理解Fluent在数据处理操作中的基本实践。同时,通过讲解源组件(Source)与输出组件(Sink)的使用,以及数据处理与转换组件的配置,进一步加深了对Fluent数据处理能力的认识。最后,通过实时数据处理流程和复杂事件处理(CEP)应用实例的案例分析,展示了Fluent在实际业务场景中的应用效果和价值。这些知识将为后续章节中对Fluent的高级特性和优化策略的深入探讨打下坚实的基础。
# 5. Fluent高级特性与优化策略
## 5.1 Fluent的扩展性与集成
Fluent在设计上强调了模块化和可扩展性,它允许开发者通过自定义组件来扩展系统功能,同时也支持与其他服务和工具的集成。
### 5.1.1 自定义组件开发
自定义组件的开发是扩展Fluent能力的关键途径。Fluent通过插件系统允许开发者编写和集成新的数据源、处理器、转换器和输出目的地。开发者需要了解Fluent的插件接口以及如何通过Go编程语言来实现这些接口。
```go
package main
import (
"github.com/fluent/fluent-operator/v2/apis/fluent/v1alpha1"
"k8s.io/apimachinery/pkg/runtime"
"sigs.k8s.io/controller-runtime/pkg/client/config"
"sigs.k8s.io/controller-runtime/pkg/manager"
"sigs.k8s.io/controller-runtime/pkg/manager/signals"
)
func main() {
// Setup Scheme for all resources
mgr, err := manager.New(config.GetConfigOrDie(), manager.Options{})
if err != nil {
panic("unable to start manager")
}
// Setup all resources and start the Manager
err = mgr.Add(&v1alpha1.OutputPlugin{})
if err != nil {
panic(err.Error())
}
err = mgr.Start(signals.SetupSignalHandler())
if err != nil {
panic("unable to run the manager")
}
}
```
上述代码片段演示了如何启动一个Fluent Operator并加入自定义输出插件。
### 5.1.2 集成第三方服务与工具
Fluent可以与多种第三方服务集成,比如消息队列(如Kafka)、数据存储(如Elasticsearch)以及监控工具(如Prometheus)。集成这些服务通常需要配置Fluent的相关组件,使其能够与这些服务进行通信。
## 5.2 性能优化与故障排除
为了确保流式数据处理系统能够稳定高效地运行,性能优化与故障排除是至关重要的。
### 5.2.1 性能监控工具与指标
Fluent提供了一系列内置的性能监控工具和指标,包括日志级别调整、聚合统计和内置探针。开发者可以利用这些工具来监控Fluent的运行状态并作出相应的优化。
```shell
fluentd --use-v1-config --dry-run
```
该命令可以用来检查配置文件是否有语法错误,并模拟运行Fluentd实例,而不实际启动它。
### 5.2.2 优化策略与故障诊断
优化策略通常涉及调整缓冲策略、提高数据吞吐量、减少内存使用和优化网络传输。故障诊断则涉及到对Fluentd日志的分析,定位和解决问题。
## 5.3 安全性与合规性考虑
随着数据敏感性的增加,确保Fluent操作的安全性和合规性变得尤为重要。
### 5.3.1 安全配置与访问控制
Fluent支持基于角色的访问控制(RBAC),可以配置安全规则来限制对Fluent资源的访问。此外,Fluentd支持使用安全的传输层(如TLS)来加密客户端和服务器之间的通信。
### 5.3.2 合规性标准与审计日志
为了满足合规性要求,Fluent提供审计日志记录功能。开发者可以启用并配置Fluentd的审计日志功能,记录所有重要的操作和事件,以符合审计和合规性需求。
请注意,本章节内容旨在为有一定经验的IT从业者提供Fluent高级特性的参考,其中包括扩展性、性能优化、安全性和合规性方面的内容。为了达到更高的实践水平,读者应尝试实际部署和配置Fluent系统,从而更深入地理解和掌握这些高级特性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MAC地址申请全攻略:步骤、误区和全球分配机构解析

参考资源链接:[IEEE下的MAC地址申请与费用详解](https://wenku.csdn.net/doc/646764ec5928463033d8ada0?spm=1055.2635.3001.10343)
# 1. MAC地址概述及其重要性
MAC地址,即媒体访问控制地址,是网络设备在局域网中用于唯一标识的地址。它由48位二进制数字构成,通常以十六进制数的形式表示
【奇安信漏扫安全策略】

参考资源链接:[网神SecVSS3600漏洞扫描系统用户手册:安全管理与操作指南](https://wenku.csdn.net/doc/3j9q3yzs1j?spm=1055.2635.3001.10343)
# 1. 奇安信漏扫工具概述
网络安全是当今信息时代不可忽视的话题,随着数字化转型的加速,企业网络面临的安全威胁与日俱增。奇安信漏扫工具是业界知名的安全扫描解决方案,旨在帮助
AE-2M-3043 GC2053 CSP核心参数深度解读:技术手册速成教程

参考资源链接:[GC2053 CSP图像传感器 datasheet V1.2:AE-2M-3043 最新版](https://wenku.csdn.net/doc/5dmsy2n5n3?spm=1055.2635.3001.10343)
# 1. GC2053 CSP核心参数概述
在集成电路设计领域,了解核心组件
【质量监控必学】:PPK实战应用技巧,提升过程控制精度
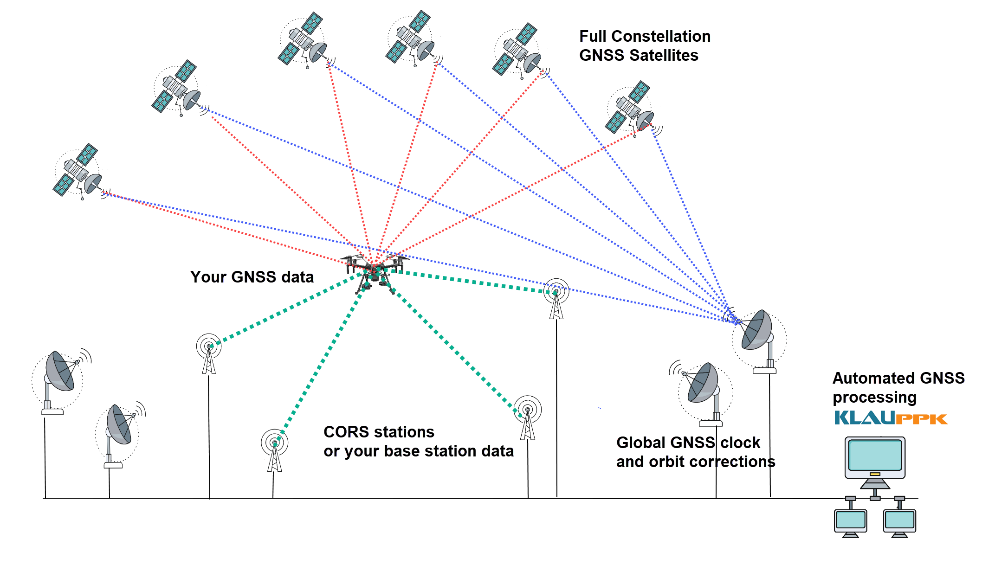
参考资源链接:[CP、CPK、PP、PPK、CMK的计算公式过程能力指数公式](https://wenku.csdn.net/doc/6412b710be7fbd1778d48f44?spm=1055.2635.3001.10343)
# 1. PPK概念解析及应用场景
在制造和质量控制领域,PPK(过程性能指数)是一个至关重要的概念。PPK提供了一个度量,用于确定一个过程在长期运行中满足顾客规格要求的程度。
CREAD_CWRITE进阶教程:机器人编程参数与性能同步提升

参考资源链接:[KUKA机器人高级编程:CREAD与CWRITE详解](https://wenku.csdn.net/doc/wf9hqgps2r?spm=1055.2635.3001.10343)
# 1. CREAD_CWRITE概念解析
在现代IT技术和系统架构中,CREAD_CWRITE是一个关键的概念,它涉及到系统对于
Verilog编码器优化秘籍:提升性能与降低功耗的20个实用技巧

参考资源链接:[8-13编码器 verilog 实现 包含仿真图](https://wenku.csdn.net/doc/6412b78bbe
【兄弟 DCP9020CDN 维修手册】:打印机操作技巧与故障解决全攻略

参考资源链接:[兄弟DCP9020CDN等系列彩色激光多功能设备维修手册指南](https://wenku.csdn.net/doc/644b8ce2ea0840391e559a94?spm=1055.2635.3001.1
PLC程序逻辑全解析:水塔水位控制系统的深入理解

参考资源链接:[PLC编程实现水塔水位智能控制系统设计](https://wenku.csdn.net/doc/64a4de3450e8173efdda6ba2?spm=1055.2635.3001.10343)
# 1. PLC程序逻辑控制基础
## 1.1 PLC的定义及工作原理
可编程逻辑控制器(PLC)是一种用于自动化控制的工业数字计算机。它通过读取输入信号,根据用户编写的程序
【嵌入式系统性能调优】:CCRAM配置与优化策略,专家级教程

参考资源链接:[STM32与GD32使用CCRAM指南:arm-gcc配置](https://wenku.csdn.net/doc/8556i38a8x?spm=1055.2635.3001.10343)
# 1. 嵌入式系统性能调优概述
在嵌入式系统的开发和维护过程中,性能调优始终是一个核心议题。随着技术的不断进步,嵌入式设备的性能需求日益增长,对于内存管理的要求也随之提高。内存调
RV-C文档结构全解析:深入理解与编写的艺术
参考资源链接:[北美房车通讯协议RV-C:CAN2.0应用详解](https://wenku.csdn.net/doc/70dzrx8o2e?spm=1055.2635.3001.10343)
# 1. RV-C文档结构的基础知识
## 1.1 RV-C文档的概念解析
RV-C文档是一种结构化数据表达方式,广泛应用于IT行业进行数据存储和交换。它以清晰定义的结构和格式,确保了数据的一致性和可读性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )