Kafka Connect的监控和日志管理
发布时间: 2024-02-24 12:36:36 阅读量: 79 订阅数: 29 

Kafka+Log4j实现日志集中管理
# 1. Kafka Connect简介
## 1.1 什么是Kafka Connect
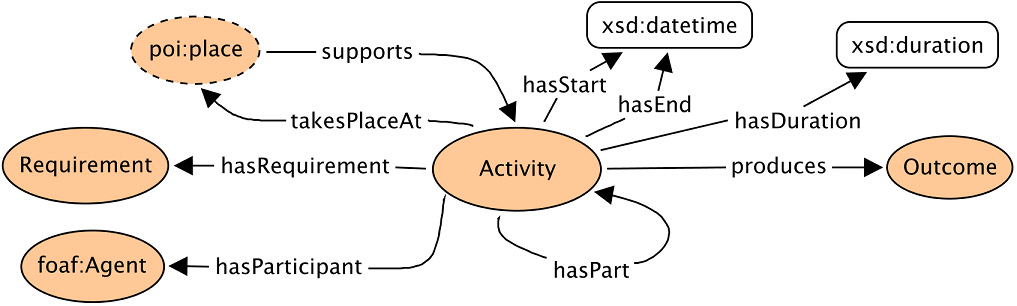
Kafka Connect是一个用于在Apache Kafka和其他数据存储系统之间可靠地传输数据的工具。它允许用户配置连接器(connectors),这些连接器可以捕获来自外部系统的数据并将其发布到Kafka主题中,或者订阅Kafka主题的数据并将其传输到外部系统中。
## 1.2 Kafka Connect的工作原理
Kafka Connect采用分布式的、可扩展的架构,其中包括连接器、任务和工作器。连接器负责定义如何配置数据从来源系统传输到Kafka或者从Kafka传输到目标系统。连接器的工作由任务来执行,而这些任务则由工作器负责分配和协调。这种架构使得Kafka Connect能够处理大规模的数据传输,同时保持高度的容错性和可伸缩性。
## 1.3 Kafka Connect的应用场景
Kafka Connect可用于多种数据集成场景,包括但不限于:
- 将数据库中的变更数据捕获并加载到Kafka中
- 从Kafka主题中消费数据,并将其加载到数据仓库中
- 从日志文件中读取数据,并将其发布到Kafka中
- 实现不同数据存储系统之间的实时同步
- ...
在接下来的章节中,我们将深入探讨Kafka Connect的监控功能、日志管理、常用工具、性能优化与故障排查,以及最佳实践与未来发展趋势。
# 2. Kafka Connect的监控功能
Kafka Connect作为一个重要的数据集成工具,在实际应用中,监控其状态和性能表现至关重要。本章将介绍Kafka Connect的监控功能,包括监控的重要性、监控指标和工具的介绍,以及如何配置和设置Kafka Connect的监控系统。
### 2.1 监控Kafka Connect的重要性
监控Kafka Connect的运行状态和性能可以帮助我们及时发现潜在问题,并采取相应的措施来保证数据流的稳定和可靠。通过监控,可以实时了解连接器的运行情况、任务的执行情况,以及集群的负载状况,从而做出及时的调整和优化。
### 2.2 监控指标和监控工具介绍
Kafka Connect提供了丰富的监控指标,包括连接器状态、任务状态、偏移量情况、错误率等。我们可以通过监控工具来收集和展示这些指标,常用的监控工具包括:
- **JMX(Java Management Extensions)**:Kafka Connect默认支持JMX监控,可以通过JConsole、JVisualVM等工具查看JMX指标。
- **Prometheus**:Prometheus是一套开源的监控和报警系统,可以通过Exporter将Kafka Connect的监控指标暴露给Prometheus。
- **Grafana**:Grafana是一款流行的可视化指标展示工具,可以与Prometheus搭配,实现监控数据的直观展示和报表分析。
### 2.3 配置和设置Kafka Connect监控
要启用Kafka Connect的监控功能,可以在Kafka Connect的配置文件中添加以下配置:
```properties
# 开启JMX监控
export JMX_PORT=8090
```
通过设置JMX端口,我们可以通过JConsole等JMX监控工具来查看Kafka Connect的指标。另外,通过安装Prometheus Exporter插件,我们还可以将Kafka Connect的监控数据导出给Prometheus进行统一管理和展示。
**总结:** 监控Kafka Connect是保证数据流稳定运行的关键,选择合适的监控工具并配置适当的监控指标,可以帮助我们及时发现和解决问题,提高系统的稳定性和性能。
# 3. Kafka Connect的日志管理
日志对于Kafka Connect 来说至关重要,它可以帮助我们跟踪连接器和任务的状态、发现问题以及进行故障排查。在本章中,我们将深入探讨 Kafka Connect 的日志管理。
#### 3.1 日志的作用和重要性
Kafka Connect 的日志记录了连接器的运行情况,包括启动信息、错误信息、警告信息等。它对于故障排查、性能优化、系统监控都非常重要。通过查看日志,我们可以了解连接器的运行状态,及时发现问题并进行处理。
#### 3.2 Kafka Connect的日志级别和日志格式
Kafka Connect 的日志级别包括 DEBUG、INFO、WARN、ERROR 等,可根据需要进行配置,以便记录不同级别的信息。另外,Kafka Connect 的日志格式也是可以定制的,通常支持的格式有 JSON、Log4j、Logback 等。
#### 3.3 配置和管理Kafka Connect的日志
配置和管理 Kafka Connect 的日志通常包括以下几个方面:
- 日志级别的配置:通过修改配置文件中的参数,可以设置不同模块的日志级别,例如将某个特定模块的日志级别调整为 DEBUG,以便进行详细的调试。
- 日志文件的管理:可以配置日志文件的最大大小、保留的备份数量等参数,避免日志文件过大占用过多磁盘空间。
- 日志的集中管理:将 Kafka Connect 的日志集中到日志管理系统中,便于集中查看和分析。
在实际操作中,我们可以通过修改 Kafka Connect 的配置文件来进行日志配置,也可以将日志集成到常见的日志管理工具中,如 ELK Stack、Splunk 等。
以上是 Kafka Connect 的日志管理相关内容,下一节将介绍如何使用常用工具监控 Kafka Connect。
# 4. 监控Kafka Connect的常用工具
Kafka Connect 是一个用于连接 Apache Kafka 与外部系统的工具,对于 Kafka Connect 的监控是非常重要的。本章将介绍一些常用的监控工具,以及它们的用途和特点。
#### 4.1 使用Prometheus监控Kafka Connect
Prometheus 是一款开源的监控和警报工具,它可以帮助你收集 Kafka Connect 的性能指标并存储这些数据。你可以使用 Prometheus 提供的图形界面来实时监控 Kafka Connect 的运行情况并进行分析。
```java
// 示例代码:使用Java编写的Kafka Connect监控指标接口
import io.prometheus.client.CollectorRegistry;
import io.prometheus.client.Counter;
import io.prometheus.client.exporter.HTTPServer;
import org.apache.kafka.connect.runtime.Worker;
import java.io.IOException;
public class KafkaConnectMetricsExporter {
private final Worker worker;
private final CollectorRegistry collectorRegistry = new CollectorRegistry();
private final Counter connectorThroughput = Counter.build()
.name("kafka_connect_connector_throughput")
.help("The throughput of Kafka Connect connectors")
.register(collectorRegistry);
public KafkaConnectMetricsExporter(Worker worker) {
this.worker = worker;
}
public void start() throws IOException {
HTTPServer server = new HTTPServer(1234);
collectorRegistry.register(connectorThroughput);
}
public void stop() {
collectorRegistry.clear();
}
}
```
#### 4.2 Grafana可视化监控数据
Grafana 是一款流行的开源数据可视化工具,它可以与 Prometheus 集成,帮助用户创建、编辑和共享仪表盘。你可以利用 Grafana 创建漂亮的图表,通过可视化数据来监控 Kafka Connect 的性能和运行状态。
```python
# 示例代码:使用Python编写的Grafana监控配置
{
"annotations": {
"list": [
{
"name": "Kafka Connect Connector Throughput",
"datasource": "Prometheus",
"enable": true,
"iconColor": "rgba(0, 211, 255, 1)",
"type": "dashboard"
}
]
},
"editable": true,
"gnetId": null,
"graphTooltip": 0,
"hideControls": false,
"id": null,
"links": [],
"panels": [
{
"datasource": "Prometheus",
"fieldConfig": {
"defaults": {
"custom": {}
}
},
"gridPos": {
"h": 9,
"w": 12,
"x": 0,
"y": 0
},
"id": 2,
"options": {
"show": true
},
"pluginVersion": "7.5.5",
"targets": [
{
"expr": "kafka_connect_connector_throughput",
"legendFormat": "{{connector}}",
"refId": "A"
}
],
"timeFrom": null,
"timeShift": null,
"title": "Kafka Connect Connector Throughput",
"type": "timeseries"
}
],
"schemaVersion": 26,
"style": "dark",
"tags": [],
"templating": {
"list": []
},
"time": {
"from": "now-6h",
"to": "now"
},
"timepicker": {
"refresh_intervals": [
"5s",
"10s",
"30s",
"1m",
"5m",
"15m",
"30m",
"1h",
"2h",
"1d"
],
"time_options": [
"5m",
"15m",
"1h",
"6h",
"12h",
"24h",
"2d",
"7d",
"30d"
]
},
"timezone": "",
"title": "Kafka Connect Monitoring Dashboard",
"uid": "9c-bb-3a-3d-5c"
}
```
#### 4.3 其他监控工具的介绍和比较
除了上述的工具之外,还有一些其他常用的监控工具,如InfluxDB、Zabbix等,它们提供了丰富的监控功能,可以根据实际需求选择适合的工具进行监控和管理。
通过以上内容,我们了解了一些常用的 Kafka Connect 监控工具及其使用方法,下一步可以根据实际情况选择合适的工具进行监控配置和管理。
# 5. Kafka Connect性能优化与故障排查
在使用Kafka Connect过程中,性能优化和故障排查是非常重要的,能够帮助我们更好地管理和维护Kafka Connect实例,确保数据流的稳定和高效。本章将重点介绍Kafka Connect的性能优化方法和常见故障排查技巧。
#### 5.1 优化Kafka Connect的性能
##### 优化配置参数
通过调整Kafka Connect的配置参数可以有效提升其性能,例如增加工作线程数、调整批处理大小、调整内存设置等。
```java
// 示例Java代码:调整Kafka Connect的工作线程数
"rest.threads": 16,
"offset.flush.interval.ms": 10000
```
##### 监控性能指标
建立监控体系,监控关键性能指标如处理速率、延迟、堆积量等,及时发现问题并进行调优。
```python
# 示例Python代码:监控Kafka Connect的处理速率
consumer = KafkaConsumer(bootstrap_servers='localhost:9092')
consumer.subscribe(['my_topic'])
for message in consumer:
process_message(message)
```
##### 资源优化
合理分配CPU、内存、磁盘等资源,避免资源瓶颈影响Kafka Connect的性能。
```go
// 示例Go代码:优化Kafka Connect的资源分配
func main() {
runtime.GOMAXPROCS(2) // 使用多核心
// 其他代码...
}
```
#### 5.2 常见故障排查和解决方法
##### 监控日志
定期查看Kafka Connect的日志,及时关注警告和错误信息,排查可能存在的问题。
```javascript
// 示例JavaScript代码:查看Kafka Connect的日志
const logStream = fs.createReadStream('kafka-connect.log');
logStream.on('data', (chunk) => {
console.log(chunk);
});
```
##### 重启服务
在遇到无法解决的故障时,可以尝试重启Kafka Connect服务,可能会解决一些临时性问题。
```java
// 示例Java代码:重启Kafka Connect服务
sudo systemctl restart kafka-connect
```
##### 问题定位
利用监控工具定位具体故障原因,比如使用Prometheus、Grafana等工具进行深入分析。
```python
# 示例Python代码:使用Prometheus监控Kafka Connect
from prometheus_client import start_http_server, Summary
import random
import time
# 其他监控代码...
```
通过以上优化和排查方法,可以使Kafka Connect在工作中保持高效稳定,遇到问题时能够快速定位并解决,提高数据流的可靠性和性能。
# 6. Kafka Connect的最佳实践与未来发展
Kafka Connect作为一个强大的分布式数据集成工具,有着广泛的应用场景和丰富的功能特性。为了更好地利用Kafka Connect,以下是一些最佳实践和未来发展的建议:
### 6.1 Kafka Connect的最佳实践分享
在使用Kafka Connect时,可以考虑以下最佳实践来提升系统性能和可靠性:
1. **合理选择连接器**:根据实际需求和数据来源/目的地的不同,选择合适的连接器是非常重要的。确保连接器的稳定性和性能能够满足任务需求。
2. **优化任务配置**:合理设置任务配置参数,包括分区数、批处理大小、并发任务数等,以提高数据传输效率和降低延迟。
3. **监控和日志管理**:建议及时监控Kafka Connect的运行状态,通过监控工具获取关键指标信息,同时管理好日志,便于故障排查和性能优化。
4. **数据格式处理**:对于不同的数据格式,如JSON、Avro等,可以通过Schema Registry来统一管理和验证数据格式,确保数据准确性和一致性。
5. **保证数据一致性和幂等性**:在数据传输过程中,考虑实现幂等性操作,以避免重复数据或数据丢失的情况,保证数据传输的一致性。
### 6.2 新特性和未来发展趋势展望
随着大数据和实时数据处理的不断发展,Kafka Connect在未来可能会有以下发展趋势和新特性:
1. **更多的连接器支持**:Kafka Connect将持续扩展支持各种数据源和数据目的地,涵盖更多的系统和数据类型,提供更灵活的数据集成解决方案。
2. **性能优化和扩展性提升**:未来版本可能会进一步优化Kafka Connect的性能,提升数据处理能力和扩展性,适应更大规模和更复杂的数据处理需求。
3. **更丰富的监控和管理功能**:为了更好地监控和管理Kafka Connect集群,未来可能引入更丰富的监控指标和管理功能,提供更直观、更便捷的运维体验。
4. **集成机器学习和数据治理**:随着人工智能和数据治理的兴起,未来版本可能会加强对机器学习模型的集成和数据质量管理,提供更智能化的数据集成解决方案。
### 6.3 总结与建议
综上所述,Kafka Connect作为一个重要的数据集成工具,在数据传输和处理中发挥着关键作用。通过遵循最佳实践、及时了解新特性和发展趋势,可以更好地利用Kafka Connect,提升数据集成的效率和可靠性,满足不断变化的业务需求。在使用过程中,建议持续关注Kafka Connect社区的动态,参与讨论和分享经验,共同推动Kafka Connect的发展和创新。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Apache Kafka Connect》专栏深入探讨了Apache Kafka Connect 的各个方面。从简介与基本概念出发,逐步引导读者了解如何使用Apache Kafka Connect进行简单的数据传输。通过深入理解配置文件和创建连接器,读者可以实现定制化的数据流处理。此外,专栏还介绍了如何优化Kafka Connect的性能和可靠性,以及建立分布式Kafka Connect集群的方法。监控和日志管理也是关键议题之一,帮助读者全面掌握Kafka Connect的运行状态。无论是初学者还是有经验的开发者,本专栏都将为他们提供全面而实用的指导,助力他们在实际应用中运用Apache Kafka Connect取得成功。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
供口与需口的秘密:OMT方法在软件设计中的高级应用
# 摘要
OMT方法作为一种面向对象的分析和设计技术,广泛应用于软件工程领域,有助于提高软件开发的系统性和可维护性。本文首先概述了OMT方法的理论基础,包括其核心原则、建模技术以及设计模式。随后,探讨了OMT方法在软件开发生命周期中的具体实践应用,包括与敏捷开发结合的策略和真实案例分析。进一步地,本文分析了OMT方法的高级特性和当前面向对象技术所面临的挑战,并展望其未来趋势。最后,文章总结了O
【大文件处理】:高级zip命令技巧,轻松管理复杂文件结构
# 摘要
本文全面探讨了zip命令在大文件处理方面的应用,从基础操作到进阶技巧,再到与其他工具的整合,以及性能限制与解决策略。文章首先介绍了zip命令的安装、基本压缩和解压技巧,然后深入探讨了错误处理、大文件处理的策略和脚本化管理。在整合应用方面,本文比较了zip与其他压缩工具,并分析了zip在数据备份和云存储服务中的应用。此外,文章还分析了z
嵌入式系统调试高手必修课:逻辑分析仪的应用技巧
# 摘要
逻辑分析仪是电子工程师进行数字电路设计和调试的关键工具,其原理基于对数字信号的实时采样和分析。本文首先介绍了逻辑分析仪的工作原理和基本功能,随后详细探讨了硬件的选择和配置要点,包括不同探头和连接方式、采样速率及存储深度等因素。文中还着重分析了软件界面的设计,特别是信号捕捉、触发设置及数据分析显示选项。此外,本文深入讨论了逻辑分析仪在嵌入式系统调试中的具体应用,例如总线通信跟踪、故障定位与性能评估。最后,通过实践案例分析,本文展示了逻辑分析仪在实际项目调试中的应用技巧,并探讨了其未来发展趋势,如集成化分析工具和与AI的结合。
# 关键字
逻辑分析仪;硬件配置;软件界面;嵌入式系统调试
【CFD分析的视觉盛宴】:Tecplot在流体动力学中的应用

# 摘要
计算流体动力学(CFD)分析与可视化在现代工程设计与研究中扮演着关键角色,而Tecplot是这一领域中广泛应用的可视化工具。本文首先概述了CFD和Tecplot的基本概念及其理论基础,涵盖了CFD分析原理、Tecplot操作和数据处理功能。接着,本文深入探讨了Tecplot在流体动力学领域中的具体实践应用,如流场分析、结果解
【内存管理与指针】:C++中指针与引用的高级用法,成为内存管理专家

# 摘要
本论文系统地探讨了内存管理与指针的多个方面,从内存管理的基础知识到指针与引用的深入应用,再到高级技术的运用和实践。首先,介绍了内存管理基础、指针的定义与运算以及动态内存管理,并着重分析了内存分配与释放机制、栈内存与堆内存的区别、以及内存泄漏的检测与避免。其次,深入探讨了指针与引用的区别和高级技巧,例如智能指针的使用和选择,以及引用在函数中的高级用法。接着,探讨了内存池的概念、对象
【时间戳转换技术】:Oracle中的日期类型与Unix时间戳互转秘籍

# 摘要
本文全面解析了时间戳转换的基础概念、Oracle日期类型内部表示、转换方法、实际应用案例,以及性能优化与最佳实践。通过对Oracle DATE和TIMESTAMP数据类型的结构、特点及精确性分析,阐述了Unix时间戳的工作原理和与UTC的时间关系。文章进一步介绍了
ARM与NIC-400总线互操作性探究:硬件软件兼容性深度分析

# 摘要
本文主要探讨了ARM架构与NIC-400总线的互操作性问题,包括硬件兼容性分析、软件兼容性分析和互操作性实践案例。在硬件兼容性方面,文章分析了ARM与NIC-400的硬件接口、连接方案以及硬件级连接方案,同时提供了兼容性测试与问题诊断的方法。在软件兼容性方面,文章探讨了操作系统与驱动程序的支持,软件层面的互操作性以及性能优化与扩展性策略。最后,文章基于ARM与
系统质量保障指南:学生作业管理系统的全面测试策略
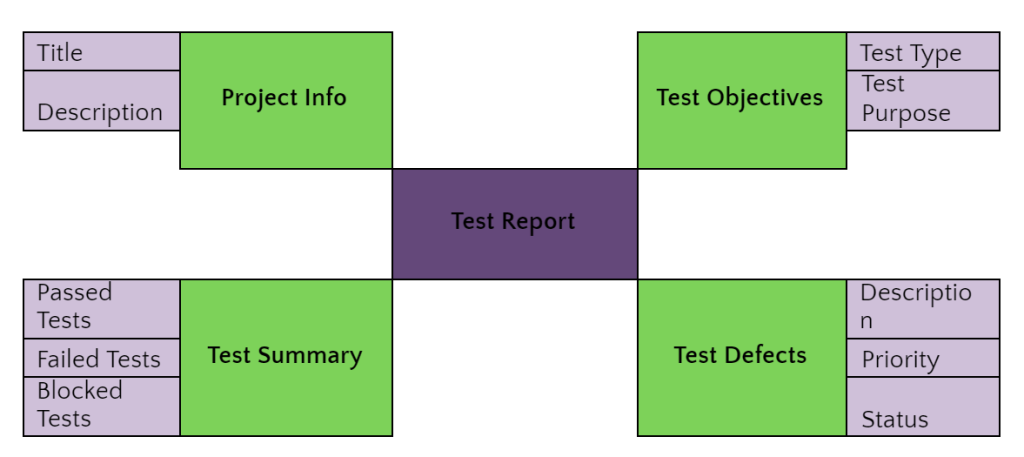
# 摘要
本文旨在系统性地探讨软件测试与系统质量保障的各个方面。文章首先介绍了系统质量保障的基础知识,随后深入到需求分析与测试计划制定的具体过程,包括需求收集与分析方法以及测试策略的选择。第三章详细阐述了不同类型的测试技术,如黑盒测试和白盒测试,并探讨了自动化测试与持续集成的方法。性能测试与安全性评估作为第四章的核心,涵盖了性能测试的目标、指标以及安全性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )