【Python库文件学习之Tools:入门篇】:零基础快速掌握Tools库基本结构及应用
发布时间: 2024-10-13 10:27:15 阅读量: 87 订阅数: 47 

tools:通用工具库

# 1. Tools库概述
在当今快速发展的IT行业中,高效、可靠的工具库对于开发者来说是不可或缺的。Tools库作为一个集成了多种实用功能的库,旨在简化开发流程,提高工作效率。本章节将对Tools库进行一个全面的概述,从其设计理念到核心功能,为读者构建一个清晰的知识框架。
## 1.1 Tools库的设计理念
Tools库的设计初衷是为了提供一套简洁、易用、功能全面的工具集合,它可以帮助开发者在日常工作中避免重复造轮子,专注于业务逻辑的实现。库中的每一个模块、类和函数都经过精心设计,以确保在提高代码复用性的同时,保持高效和可维护性。
## 1.2 Tools库的功能范围
Tools库包含了一系列广泛的功能,覆盖了文件操作、网络编程、数据处理等多个方面。例如,在文件操作方面,Tools库提供了一系列便捷的API,用于读写文件、处理文件路径等。在网络编程方面,它支持HTTP请求的发送与接收、连接管理等功能。在数据管理方面,Tools库支持数据库的连接与操作、数据分析等高级功能。这些功能的设计旨在为开发者提供一站式解决方案,简化复杂的任务。
## 1.3 Tools库的使用场景
Tools库适用于多种场景,无论是小型脚本编写还是大型项目的开发,它都能提供必要的支持。对于初创公司或者需要快速迭代的项目,Tools库可以大大缩短开发周期。而对于大型企业项目,它则可以提供稳定可靠的工具支持,帮助团队专注于核心业务的创新。
以上是对Tools库的概述,接下来我们将深入探讨其基本结构。
# 2. Tools库的基本结构
## 2.1 Tools库的模块与子模块
### 2.1.1 模块的导入和使用
在本章节中,我们将深入探讨Tools库的模块化结构,以及如何导入和使用这些模块。Tools库通过模块化设计,将不同的功能封装在独立的模块中,这样不仅提高了代码的可维护性,还增强了模块之间的解耦。
首先,我们要了解如何导入一个模块。在Python中,我们可以使用`import`语句来导入模块。例如,如果我们想使用Tools库中的`moduleA`模块,我们可以在代码的开始处添加如下代码:
```python
import Tools.moduleA
```
这行代码的作用是从Tools库中导入`moduleA`模块。一旦模块被导入,我们就可以使用模块中定义的任何类或函数。例如,如果`moduleA`中有一个名为`ClassA`的类,我们可以这样使用它:
```python
instance = Tools.moduleA.ClassA()
```
这里,我们创建了`moduleA`模块中`ClassA`类的一个实例。
### 2.1.2 子模块的功能和特点
Tools库中的模块往往包含多个子模块,每个子模块都有其特定的功能和特点。这些子模块通常负责处理特定的任务,例如数据处理、文件操作或网络编程。
为了更好地理解子模块的功能和特点,我们可以通过一个例子来进行说明。假设`moduleA`下有一个子模块`submoduleA1`,它专门用于处理文本文件的读写。在这个子模块中,可能包含如下函数:
- `read_file(file_path)`: 读取文件内容。
- `write_file(file_path, content)`: 将内容写入文件。
- `append_file(file_path, content)`: 将内容追加到文件末尾。
这些函数提供了一种简单的方式来处理文本文件,使得用户不需要关心文件操作的细节,只需调用相应的函数即可完成任务。
在本章节的介绍中,我们已经了解了如何导入和使用Tools库的模块和子模块,以及子模块的功能和特点。接下来的章节,我们将深入探讨Tools库中的核心类和函数,以及它们的结构和方法。
## 2.2 Tools库中的核心类和函数
### 2.2.1 类的结构和方法
在本章节中,我们将探讨Tools库中的核心类,以及它们的结构和方法。核心类是构成Tools库的基石,它们提供了丰富的API供开发者使用。
以`Tools.ClassB`为例,这是一个核心类,它可能包含如下方法:
- `methodA()`: 执行某种操作。
- `methodB(param)`: 接受参数并执行操作。
- `methodC()`: 返回一个状态值。
这些方法定义了类的行为,使得实例化的对象能够执行特定的任务。例如,如果`ClassB`有一个`methodA`方法,它可能看起来像这样:
```python
class ClassB:
def __init__(self):
pass
def methodA(self):
print("Executing methodA")
instance = ClassB()
instance.methodA()
```
在这个例子中,我们创建了`ClassB`的一个实例,并调用了`methodA`方法。
### 2.2.2 函数的参数和返回值
除了核心类,Tools库中还包含了大量有用的函数。这些函数通常接受参数,并返回操作的结果。理解函数的参数和返回值对于正确使用Tools库至关重要。
以`Tools.functionC`函数为例,它可能接受两个参数,并返回一个结果。函数定义可能如下所示:
```python
def functionC(param1, param2):
# 执行某些操作
result = param1 + param2
return result
```
在这个例子中,函数`functionC`接受两个参数`param1`和`param2`,并返回它们的和。使用这个函数的示例代码可能如下:
```python
result = Tools.functionC(1, 2)
print(result) # 输出3
```
在本章节中,我们介绍了Tools库中的核心类和函数,以及它们的结构、方法、参数和返回值。接下来的章节,我们将深入探讨Tools库的数据处理机制。
## 2.3 Tools库的数据处理机制
### 2.3.1 数据输入和输出
Tools库提供了一系列的数据处理机制,以便于开发者进行数据的输入和输出操作。在本章节中,我们将探讨如何进行数据的输入和输出,以及相关的API和使用方法。
数据输入和输出是编程中常见的操作,它们允许程序与外部世界进行交互。在Tools库中,数据输入可能涉及到从文件、网络或用户输入中读取数据,而数据输出可能涉及到将数据写入文件、发送到网络或展示给用户。
例如,假设我们有一个函数`Tools.input_data()`用于从用户那里获取数据:
```python
def input_data():
data = input("Enter data: ")
return data
```
这个函数会提示用户输入数据,并将其作为字符串返回。使用这个函数的示例可能如下:
```python
user_data = Tools.input_data()
print("You entered:", user_data)
```
在本章节的介绍中,我们了解了Tools库中数据输入的机制。接下来,我们将深入探讨数据转换和过滤,这是处理数据时的另一个重要方面。
### 2.3.2 数据转换和过滤
在本章节中,我们将探讨Tools库中的数据转换和过滤机制。数据转换是指将数据从一种形式转换为另一种形式的过程,而数据过滤则是根据特定的标准选择或排除数据。
#### 数据转换
数据转换通常涉及将原始数据转换为更易于处理的格式。例如,我们可以将字符串转换为整数或浮点数,或者将字节数据转换为字符串。Tools库提供了一系列的函数来执行这些转换操作。
假设我们有一个函数`Tools.convert_to_int()`,它可以将字符串转换为整数:
```python
def convert_to_int(data_str):
try:
return int(data_str)
except ValueError:
print("Invalid input, not an integer.")
```
这个函数尝试将输入的字符串转换为整数,并在转换失败时打印错误消息。使用这个函数的示例可能如下:
```python
converted_data = Tools.convert_to_int("123")
print("The integer is:", converted_data)
```
#### 数据过滤
数据过滤允许我们根据特定的标准来选择或排除数据。这在处理大型数据集时尤其有用,例如从一组数据中筛选出符合特定条件的记录。
假设我们有一个函数`Tools.filter_even_numbers()`,它从一组数字中筛选出偶数:
```python
def filter_even_numbers(numbers_list):
return [num for num in numbers_list if num % 2 == 0]
```
这个函数使用列表推导式来创建一个新列表,其中只包含输入列表中的偶数。使用这个函数的示例可能如下:
```python
data = [1, 2, 3, 4, 5]
filtered_data = Tools.filter_even_numbers(data)
print("Filtered even numbers:", filtered_data)
```
在本章节中,我们探讨了Tools库中的数据转换和过滤机制。这些机制对于处理各种类型的数据至关重要,无论是进行数据预处理、分析还是展示。接下来的章节,我们将深入探讨Tools库的实践应用。
**注意:** 由于Markdown的限制,实际文章中的代码块、表格、列表、mermaid格式流程图等元素将在这里无法直接展示。在实际的Markdown编辑器中,您将能够添加这些元素,并按照上述示例进行格式化,以满足文章的要求。
# 3. Tools库的实践应用
## 3.1 文件操作实践
### 3.1.1 文件读写实践
在本章节中,我们将深入探讨Tools库中的文件操作功能。文件操作是编程中的基础任务之一,无论是读取配置文件、处理日志,还是编写数据导入导出功能,都离不开文件操作。Tools库提供了一系列方便的API来简化这些操作,使得开发者可以更加专注于业务逻辑的实现。
#### 基本的文件读写
首先,我们来看看如何使用Tools库进行基本的文件读写操作。这里我们假设有一个名为`example.txt`的文本文件,我们想要读取它的内容并将其打印出来。
```python
from tools import file_io
# 打开文件
with open('example.txt', 'r', encoding='utf-8') as ***
* 读取文件内容
content = file.read()
# 打印文件内容
print(content)
```
在这段代码中,我们首先从`tools`模块导入了`file_io`模块,然后使用`open`函数以只读模式打开文件。`open`函数的`encoding`参数确保我们在读取文件时正确处理了编码问题。使用`with`语句可以确保文件在读取后被正确关闭。`read`方法读取文件的全部内容,并将其存储在`content`变量中。
接下来,我们将文件内容打印出来。这种方式适用于文件大小适中的情况。如果文件非常大,我们可能需要使用`readline`或`readlines`方法逐行读取文件内容。
#### 高级文件操作
Tools库不仅仅支持基本的文件读写,还提供了一些高级功能,例如文件的追加写入、二进制文件处理等。
```python
# 以追加模式打开文件,写入内容
with open('example.txt', 'a', encoding='utf-8') as ***
***'\nNew line added by Tools library')
# 以二进制模式打开文件,写入内容
with open('example.bin', 'wb') as ***
***'\x00\x01\x02')
```
在这段代码中,我们展示了如何使用追加模式打开文件,并在文件末尾添加新的内容。另外,我们还演示了如何以二进制模式打开文件,这对于处理非文本文件(如图片、视频等)非常重要。
### 3.1.2 文件处理高级应用
#### 文件内容搜索
除了基本的读写操作,Tools库还提供了一些高级功能,例如在文件内容中搜索特定字符串。
```python
from tools import file_io
# 打开文件
with open('example.txt', 'r', encoding='utf-8') as ***
***
* 搜索特定字符串
search_term = 'search_term'
if search_term in content:
print(f"'{search_term}' found in file.")
else:
print(f"'{search_term}' not found in file.")
```
这段代码展示了如何在文件内容中搜索一个特定的字符串。如果找到了,就打印出相应的消息;如果没有找到,也打印出一个消息。
#### 文件内容统计
我们还可以使用Tools库来统计文件中的字符或行数。
```python
from tools import file_io
# 打开文件
with open('example.txt', 'r', encoding='utf-8') as ***
***
* 统计字符数
character_count = len(content)
# 统计行数
line_count = content.count('\n') + 1
print(f"Character count: {character_count}")
print(f"Line count: {line_count}")
```
在这段代码中,我们使用`len`函数来统计文件中的字符总数,而使用字符串的`count`方法加上1来统计行数(因为每行的结束也被计数)。
#### 文件合并与分割
有时候我们需要合并多个文件的内容,或者根据某些规则将一个大文件分割成多个小文件。Tools库也提供了这样的功能。
```python
from tools import file_io
# 合并文件
def merge_files(file_list, output_file):
with open(output_file, 'w', encoding='utf-8') as out***
***
*** 'r', encoding='utf-8') as in***
***
***'\n')
# 分割文件
def split_file(filename, lines_per_file):
with open(filename, 'r', encoding='utf-8') as in***
***
***
***'{filename}_{i//lines_per_file}', 'w', encoding='utf-8') as out***
***[i:i+lines_per_file])
# 使用示例
merge_files(['file1.txt', 'file2.txt', 'file3.txt'], 'merged.txt')
split_file('big_file.txt', 100)
```
在这段代码中,我们定义了两个函数:`merge_files`用于合并多个文件的内容,而`split_file`用于将一个大文件分割成多个包含指定行数的小文件。这些函数都使用了Tools库中的文件操作API来实现它们的功能。
#### 文件内容比较
最后,我们可能会遇到需要比较两个文件内容是否相同的情况。Tools库提供了这样的功能,可以帮助我们快速实现文件内容的比较。
```python
from tools import file_io
# 比较两个文件内容是否相同
def compare_files(file1, file2):
with open(file1, 'r', encoding='utf-8') as f1, open(file2, 'r', encoding='utf-8') as f2:
return f1.read() == f2.read()
# 使用示例
are_equal = compare_files('file1.txt', 'file2.txt')
print(f"Files are {'equal' if are_equal else 'not equal'}.")
```
在这段代码中,我们定义了一个`compare_files`函数,它使用`open`函数打开两个文件,并比较它们的内容是否相同。这个函数返回一个布尔值,表示两个文件是否内容相同。
## 3.2 网络编程实践
### 3.2.1 网络请求与响应处理
网络编程是现代软件开发中不可或缺的一部分。Tools库提供了一套简单的API来发送网络请求,并处理响应。这使得开发者可以轻松地与其他服务进行交互,无论是API调用、网页爬取还是简单的数据交换。
#### 发送GET请求
在本章节中,我们将学习如何使用Tools库发送GET请求。GET请求是最常见的网络请求之一,用于从服务器获取数据。
```python
from tools import network
# 发送GET请求
response = network.get('***')
# 检查响应状态码
if response.status_code == 200:
# 请求成功,处理响应内容
print(response.text)
else:
# 请求失败,处理错误
print(f'Error: {response.status_code}')
```
在这段代码中,我们首先从`tools`模块导入了`network`模块,然后使用`get`函数发送一个GET请求到指定的URL。`get`函数返回一个`Response`对象,其中包含了响应的状态码和内容。我们通过检查状态码来判断请求是否成功,并相应地处理响应内容或错误。
#### 发送POST请求
除了GET请求,Tools库还支持发送POST请求,这对于需要传递数据给服务器的场景非常有用。
```python
from tools import network
# 发送POST请求
data = {'key': 'value'}
response = network.post('***', data=data)
# 检查响应状态码和内容
if response.status_code == 200:
# 请求成功,处理响应内容
print(response.json())
else:
# 请求失败,处理错误
print(f'Error: {response.status_code}')
```
在这段代码中,我们展示了如何发送一个带有数据的POST请求。`post`函数接受一个URL和一个数据字典作为参数,然后发送一个POST请求。我们假设服务器返回的是JSON格式的数据,因此使用`response.json()`方法来解析响应内容。
#### 错误处理
在网络请求中,错误处理是必不可少的。Tools库提供了一种简洁的方式来处理请求过程中可能发生的各种异常。
```python
from tools import network
try:
# 发送请求
response = network.get('***')
# 处理响应
print(response.text)
except network.RequestError as e:
# 处理请求错误
print(f'Request failed: {e}')
except network.ConnectionError as e:
# 处理连接错误
print(f'Connection failed: {e}')
```
在这段代码中,我们使用`try-except`语句来捕获可能发生的错误。`RequestError`是请求错误的基类,包括了请求超时、服务器错误等情况。`ConnectionError`是连接错误的基类,包括了网络连接问题等。通过捕获这些异常,我们可以对不同的错误情况进行针对性的处理。
### 3.2.2 网络连接管理
网络编程不仅仅涉及到发送请求和接收响应,还涉及到网络连接的管理。Tools库提供了一些功能来帮助开发者管理网络连接,例如设置超时、保持连接等。
#### 设置请求超时
在发送网络请求时,我们可能希望设置一个超时时间,以避免请求挂起太长时间。
```python
from tools import network
# 发送GET请求,并设置超时时间为10秒
response = network.get('***', timeout=10)
# 检查响应状态码
if response.status_code == 200:
# 请求成功,处理响应内容
print(response.text)
else:
# 请求失败,处理错误
print(f'Error: {response.status_code}')
```
在这段代码中,我们通过`timeout`参数设置了请求的超时时间。如果请求在指定时间内没有完成,将抛出一个超时异常。
#### 使用代理
有时候,我们可能需要通过代理服务器来发送网络请求,这可能是出于安全或其他的考虑。
```python
from tools import network
# 使用代理发送GET请求
proxies = {
'http': '***',
'https': '***',
}
response = network.get('***', proxies=proxies)
# 检查响应状态码
if response.status_code == 200:
# 请求成功,处理响应内容
print(response.text)
else:
# 请求失败,处理错误
print(f'Error: {response.status_code}')
```
在这段代码中,我们通过`proxies`参数指定了HTTP和HTTPS代理服务器的地址。Tools库将通过这些代理服务器发送请求。
## 3.3 数据管理实践
### 3.3.1 数据库连接实践
数据库是现代应用程序中不可或缺的一部分。Tools库提供了一系列的API来简化数据库的连接和操作,无论是关系型数据库如MySQL、PostgreSQL,还是非关系型数据库如MongoDB。
#### 连接数据库
首先,我们需要学习如何使用Tools库连接到数据库。
```python
from tools import database
# 连接到MySQL数据库
mysql_conn = database.connect(
host='localhost',
user='root',
password='password',
database='mydatabase',
driver='mysql'
)
# 连接到PostgreSQL数据库
pg_conn = database.connect(
host='localhost',
user='postgres',
password='password',
database='mydatabase',
driver='postgresql'
)
# 连接到MongoDB数据库
mongo_conn = database.connect(
host='localhost',
port=27017,
database='mydatabase',
driver='mongodb'
)
```
在这段代码中,我们展示了如何使用`connect`函数连接到不同类型的数据库。`host`、`user`、`password`和`database`参数用于指定连接信息,而`driver`参数用于指定数据库类型。
#### 执行查询
连接到数据库后,我们可以执行SQL查询或MongoDB操作。
```python
# 执行SQL查询
cursor = mysql_conn.cursor()
cursor.execute("SELECT * FROM users")
rows = cursor.fetchall()
# 执行MongoDB查询
mongo_cursor = mongo_conn.find({'name': 'Alice'})
documents = list(mongo_cursor)
```
在这段代码中,我们展示了如何在MySQL和MongoDB数据库中执行查询。在MySQL中,我们使用`cursor`来执行SQL查询,并获取结果集。在MongoDB中,我们使用`find`方法来执行查询,并将结果集转换为列表。
#### 插入、更新和删除数据
除了查询,我们还可以在数据库中插入、更新和删除数据。
```python
# 插入数据
mysql_conn.execute("INSERT INTO users (name, age) VALUES ('Bob', 25)")
# 更新数据
mysql_conn.execute("UPDATE users SET age = 26 WHERE name = 'Bob'")
# 删除数据
mysql_conn.execute("DELETE FROM users WHERE name = 'Bob'")
```
在这段代码中,我们展示了如何在MySQL数据库中进行插入、更新和删除操作。使用`execute`方法可以执行任何SQL语句。
### 3.3.2 数据分析和可视化
数据分析和可视化是现代数据密集型应用的关键组成部分。Tools库提供了一些工具来帮助开发者进行数据分析和可视化。
#### 数据分析
Tools库内置了一些数据分析工具,可以帮助我们处理数据集。
```python
from tools import data_analysis
# 假设我们有一个包含数据的列表
data = [1, 2, 3, 4, 5]
# 计算平均值
mean_value = data_analysis.mean(data)
# 计算标准差
std_dev = data_analysis.std_dev(data)
# 找到最大值和最小值
max_value = data_analysis.max(data)
min_value = data_analysis.min(data)
```
在这段代码中,我们展示了如何使用`data_analysis`模块来计算一组数据的平均值、标准差、最大值和最小值。
#### 数据可视化
除了数据分析,Tools库还提供了进行数据可视化的功能。
```python
import matplotlib.pyplot as plt
# 使用matplotlib进行数据可视化
data = [1, 2, 3, 4, 5]
plt.plot(data)
plt.title('Data Visualization')
plt.xlabel('Index')
plt.ylabel('Value')
plt.show()
```
在这段代码中,我们使用了`matplotlib`库来创建一个简单的折线图。Tools库提供了与`matplotlib`等流行数据可视化库的集成,使得数据可视化变得简单直观。
以上就是第三章:Tools库的实践应用的全部内容。通过本章节的介绍,我们了解了如何使用Tools库进行文件操作、网络编程以及数据分析和可视化。这些实践应用展示了Tools库在简化常见编程任务方面的强大能力,使开发者能够更加高效地编写代码。
# 4. Tools库高级功能探索
## 4.1 Tools库的扩展模块
### 4.1.1 第三方模块的集成
Tools库的设计理念是高度可扩展的,这意味着用户可以根据自己的需求,通过集成第三方模块来扩展库的功能。这种设计模式不仅可以增强Tools库的通用性,还能保持其核心模块的简洁性。例如,用户可能会发现现有的数据处理功能不足以处理特定的数据格式或协议,这时可以通过集成第三方的数据解析库来扩展数据处理能力。
集成第三方模块的基本步骤如下:
1. **查找合适的第三方模块**:根据需求,在PyPI或其他包管理平台上寻找合适的模块。
2. **安装第三方模块**:使用pip或其他包管理工具安装找到的模块。
3. **模块导入与使用**:在Tools库的代码中导入第三方模块,并在合适的地方调用其功能。
例如,如果需要集成一个用于解析CSV文件的第三方模块,首先需要在Python环境中安装这个模块:
```bash
pip install third_party_csv_parser
```
然后在Tools库的代码中导入并使用它:
```python
from third_party_csv_parser import parse_csv
def process_csv(data):
# 使用第三方模块解析CSV数据
return parse_csv(data)
# 使用过程
csv_data = 'name,age,city\nJohn Doe,30,New York\nJane Doe,25,Los Angeles'
processed_data = process_csv(csv_data)
```
### 4.1.2 扩展模块的功能和限制
扩展模块虽然提供了强大的灵活性,但也带来了一些限制和挑战。这些限制主要体现在以下几个方面:
1. **兼容性问题**:第三方模块可能与Tools库的其他部分存在不兼容的情况,这需要在集成时仔细测试和调试。
2. **性能开销**:集成的第三方模块可能会增加整体的性能开销,尤其是在处理大规模数据时。
3. **维护难度**:随着第三方模块的更新,可能需要定期更新集成代码以保持兼容性,这增加了维护的难度。
为了有效地集成第三方模块,需要遵循以下最佳实践:
- **严格测试**:在集成任何第三方模块之前,都应该进行严格的测试,确保它不会破坏现有的功能。
- **版本控制**:使用版本控制系统来跟踪第三方模块的版本,以便在出现问题时能够迅速回滚到稳定状态。
- **文档记录**:详细记录集成的过程和遇到的问题,这不仅可以帮助自己回顾,也能为其他开发者提供参考。
## 4.2 Tools库的性能优化
### 4.2.1 性能分析工具
在进行性能优化之前,首先需要了解当前系统的性能瓶颈在哪里。性能分析工具可以帮助我们识别这些瓶颈,并提供优化的线索。Python社区提供了多种性能分析工具,例如cProfile、line_profiler和memory_profiler等。
使用cProfile进行性能分析的基本步骤如下:
1. **安装cProfile**:通常Python自带cProfile模块,无需额外安装。
2. **运行分析**:使用Python命令行工具运行cProfile,分析Tools库的性能。
3. **分析结果**:cProfile会生成性能分析报告,从中可以了解哪些函数消耗了最多的时间和内存。
例如,使用cProfile分析Tools库中的一个特定功能:
```bash
python -m cProfile -o profile.prof tools_script.py
```
然后,使用pstats模块来阅读分析结果:
```python
import pstats
p = pstats.Stats('profile.prof')
p.sort_stats('cumulative').print_stats(10)
```
### 4.2.2 代码优化技巧
代码优化是一个持续的过程,需要不断地分析和调整。以下是一些常用的代码优化技巧:
1. **减少不必要的计算**:避免在循环或频繁调用的函数中进行不必要的计算。
2. **使用生成器表达式**:对于大量数据处理,使用生成器可以减少内存占用。
3. **缓存计算结果**:对于昂贵的计算,使用缓存(例如functools.lru_cache)来存储结果,避免重复计算。
4. **优化数据结构**:选择合适的数据结构可以显著提高性能。
例如,如果Tools库中有大量处理字典的操作,可以考虑使用collections模块中的defaultdict来优化性能:
```python
from collections import defaultdict
def optimize_dict_operations(data):
# 使用defaultdict优化字典操作
result = defaultdict(list)
for key, value in data.items():
result[key].append(value)
return result
```
### 4.2.3 代码逻辑的逐行解读分析
在实际项目中,对代码逻辑的逐行解读分析是非常重要的。这不仅可以帮助我们理解代码的工作原理,还能发现潜在的性能问题。以下是一个简单的示例,分析一个简单的字典处理函数:
```python
def process_data(data):
processed = {}
for key, value in data.items():
# 假设这里有一些复杂的逻辑
processed[key] = some_complex_function(value)
return processed
def some_complex_function(x):
# 这里是一些复杂的计算
return x * x
```
**逐行逻辑分析**:
- `def process_data(data):` 定义了一个处理字典的函数`process_data`。
- `processed = {}` 初始化一个空字典`processed`。
- `for key, value in data.items():` 遍历输入的字典`data`。
- `processed[key] = some_complex_function(value)` 对每个值调用`some_complex_function`函数,并将结果存储在`processed`字典中。
- `return processed` 返回处理后的字典。
**参数说明**:
- `data`:输入的字典,包含需要处理的数据。
**执行逻辑说明**:
- 这个函数的主要目的是对输入的字典进行处理,将每个值通过`some_complex_function`函数进行处理,并返回一个新的字典。
通过这种逐行分析,我们可以更好地理解代码的工作原理,并在必要时进行优化。
## 4.3 Tools库的应用场景分析
### 4.3.1 典型应用场景案例
Tools库的设计初衷是为了满足开发者在数据处理、文件操作和网络编程等方面的常见需求。以下是一些典型的应用场景案例:
#### 应用场景案例:批量文件处理
假设你需要对一系列文本文件进行读取和数据提取,Tools库可以帮助你快速实现这一功能。以下是使用Tools库进行批量文件处理的示例代码:
```python
import os
from tools_library import file as file_utils
def batch_process_files(directory):
# 获取目录下所有的.txt文件
files = [f for f in os.listdir(directory) if f.endswith('.txt')]
processed_data = []
for file in files:
full_path = os.path.join(directory, file)
# 使用Tools库的file模块读取和处理文件
content = file_utils.read_file(full_path)
data = extract_data(content)
processed_data.append(data)
return processed_data
def extract_data(content):
# 提取数据的逻辑
return content.split()
# 使用过程
directory_path = '/path/to/directory'
processed_files = batch_process_files(directory_path)
```
### 4.3.2 最佳实践和设计模式
在使用Tools库进行开发时,遵循一些最佳实践和设计模式可以提高代码的质量和可维护性。以下是一些推荐的最佳实践:
#### 最佳实践:模块化设计
将复杂的功能分解成多个小的、独立的模块,可以提高代码的可读性和可维护性。以下是模块化设计的示例:
```python
# tools_library/file.py
def read_file(path):
with open(path, 'r') as ***
***
* 发送网络请求的逻辑
pass
# main.py
from tools_library import file, network
def main():
# 使用Tools库的不同模块
content = file.read_file('example.txt')
response = network.send_request('***')
if __name__ == '__main__':
main()
```
#### 最佳实践:使用配置文件
对于需要频繁更改的配置,使用配置文件可以提高代码的灵活性。以下是使用配置文件的示例:
```python
# config.yaml
server:
host: '***'
port: 8080
# tools_library/config.py
import yaml
def load_config(path):
with open(path, 'r') as ***
***
***'config.yaml')
# 使用配置文件中的数据
server = config['server']
print(server['host'], server['port'])
if __name__ == '__main__':
main()
```
通过这些最佳实践和设计模式,开发者可以更高效地使用Tools库,并构建出高质量的软件。
在本章节中,我们详细介绍了Tools库的扩展模块、性能优化技巧以及应用场景分析。通过具体的代码示例和分析,我们展示了如何在实际项目中应用这些高级功能。这些内容不仅有助于提高开发效率,还能帮助开发者构建出更健壮和可维护的软件系统。
# 5. Tools库的常见问题和解决方案
在本章节中,我们将深入探讨Tools库在实际应用中可能遇到的常见问题,并提供相应的诊断和解决策略。此外,我们还将介绍社区资源和文档参考,帮助用户更有效地使用Tools库。
## 5.1 常见问题汇总
在使用Tools库的过程中,用户可能会遇到各种各样的问题。以下是一些常见的问题汇总,包括但不限于:
- **安装问题**:用户在安装Tools库时可能会遇到兼容性问题,尤其是在不同操作系统或不同版本的Python环境中。
- **模块导入错误**:由于库的结构复杂,用户可能会导入错误的模块或子模块,导致运行时错误。
- **功能使用错误**:用户可能对库的功能理解不足,使用了不恰当的方法或参数,导致预期之外的行为。
- **性能问题**:在处理大规模数据时,用户可能会遇到性能瓶颈,影响程序的执行效率。
- **文档不清晰**:用户在查阅官方文档时,可能会发现某些功能的说明不够详细,导致无法正确使用。
## 5.2 问题诊断和解决策略
针对上述常见问题,我们提供以下诊断和解决策略:
### 5.2.1 安装问题
**诊断**:当遇到安装问题时,首先检查Python环境是否正确配置,包括Python版本和环境变量。
**解决策略**:
1. **确保Python版本兼容**:Tools库可能不支持过旧或过新的Python版本。检查官方文档中推荐的Python版本,并确保你的环境与之匹配。
2. **检查依赖项**:确保所有依赖项都已正确安装。可以使用`pip show <package>`命令来检查特定包是否已安装及其版本信息。
3. **使用虚拟环境**:为了避免库之间的版本冲突,建议使用虚拟环境安装Tools库。
### 5.2.2 模块导入错误
**诊断**:导入错误的模块通常会导致`ImportError`异常。
**解决策略**:
1. **查阅文档**:仔细阅读官方文档,了解库的模块结构和命名规范。
2. **使用IDE自动完成**:利用IDE的功能,例如IntelliJ IDEA或PyCharm的自动完成功能,来检查模块的正确路径和名称。
3. **模块路径检查**:使用Python的`sys.path`来检查当前模块的搜索路径,确保没有错误的路径干扰模块导入。
### 5.2.3 功能使用错误
**诊断**:功能使用错误通常会导致`TypeError`或`ValueError`异常。
**解决策略**:
1. **阅读API文档**:仔细阅读每个函数或类的API文档,理解其参数和返回值。
2. **查看示例代码**:查看官方提供的示例代码,了解功能的正确使用方法。
3. **社区提问**:如果文档无法解决问题,可以在社区论坛中提问,获取来自经验丰富的开发者的帮助。
### 5.2.4 性能问题
**诊断**:性能问题可能表现为程序运行缓慢或内存消耗过大。
**解决策略**:
1. **性能分析**:使用性能分析工具,如`cProfile`或`line_profiler`,来确定性能瓶颈。
2. **代码优化**:根据分析结果,优化代码逻辑,例如减少循环次数、使用更高效的数据结构或算法。
3. **资源管理**:确保在不需要时及时释放资源,如关闭文件、数据库连接等。
### 5.2.5 文档不清晰
**诊断**:当文档信息不足时,用户可能会感到困惑。
**解决策略**:
1. **反馈问题**:在官方文档的GitHub仓库中提交issue,报告不清晰的文档部分。
2. **社区讨论**:参与社区讨论,与其他用户交流使用心得,可能会有意想不到的收获。
3. **编写补丁**:如果可能,自己编写文档补丁并提交给官方,帮助改进文档质量。
## 5.3 社区资源和文档参考
Tools库的社区资源和文档参考是用户解决问题的重要途径。以下是一些推荐的资源:
### 5.3.1 官方文档
官方网站提供最权威的使用指南和API参考。用户应当首先参考官方文档来解决遇到的问题。
### 5.3.2 社区论坛
社区论坛是一个交流和解决问题的好地方。用户可以在这里提问、分享经验或参与讨论。
### 5.3.3 GitHub仓库
GitHub仓库是用户可以查看源代码、报告bug或提交pull请求的地方。通过阅读源代码,用户可以更深入地理解库的工作原理。
### 5.3.4 第三方教程和博客
互联网上有许多第三方编写的教程和博客,它们可能会提供不同的视角和解决方案,帮助用户更好地理解和使用Tools库。
通过本章节的介绍,我们希望用户能够对Tools库的常见问题有一个全面的了解,并掌握解决问题的方法。在使用Tools库时,用户应该充分利用社区资源和文档参考,不断提升自己的使用技能和解决问题的能力。
# 6. Tools库的未来展望
随着技术的不断进步,Tools库也在不断地更新和改进,以适应新的开发需求和技术趋势。本章将深入探讨Tools库的未来展望,包括新版本的更新与改进、行业发展趋势分析以及学习资源和进阶路径。
## 6.1 新版本更新与改进
Tools库的每次新版本发布都会带来一系列的更新和改进。这些更新可能包括新的功能模块、性能优化、错误修复以及对现有API的改进。以下是新版本可能关注的几个方面:
- **新增功能模块**:随着用户需求的变化,新版本可能会引入新的模块来支持更广泛的用例。例如,对特定网络协议的支持、更高效的文件处理算法、或对新兴技术(如机器学习、区块链)的支持。
- **性能优化**:性能是软件的生命线,新版本会致力于提高现有功能的性能,包括更快的处理速度、更少的内存占用以及更低的CPU消耗。
- **错误修复**:修复现有版本中的bug是新版本发布的一个重要方面。开发者会基于社区反馈和内部测试,修复影响用户体验的问题。
- **API改进**:为了保持与最佳实践的一致性,新版本可能会对现有API进行改进,使其更加直观易用。
### 6.1.1 示例代码
假设新版本引入了一个名为`FileProcessor`的模块,用于并行处理大文件。以下是可能的代码示例:
```python
from tools import FileProcessor
processor = FileProcessor()
result = processor.process('large_file.csv', workers=4)
```
在这个例子中,`FileProcessor`模块提供了一个`process`方法,它接受文件名和工作线程数作为参数,实现文件的并行处理。
## 6.2 行业发展趋势分析
Tools库的未来展望与整个行业的技术发展趋势紧密相关。以下是几个可能影响Tools库发展的行业趋势:
- **云原生**:随着云计算的普及,云原生应用的开发和部署将成为主流。Tools库可能会增加对云服务提供商的原生支持,简化云资源的管理。
- **容器化**:容器技术如Docker和Kubernetes的广泛使用要求Tools库能够支持容器化环境。新版本可能会提供更好的容器部署支持。
- **人工智能与大数据**:随着AI和大数据分析需求的增长,Tools库可能会增加对这些领域的支持,例如集成机器学习库、提供高级数据分析功能。
### 6.2.1 行业趋势分析图
```mermaid
graph TD
A[行业趋势] --> B[云原生]
A --> C[容器化]
A --> D[人工智能与大数据]
B --> E[Tools库云原生支持]
C --> F[Tools库容器化部署]
D --> G[Tools库AI与大数据支持]
```
## 6.3 学习资源和进阶路径
为了帮助开发者更好地使用Tools库并跟上其发展步伐,本节将提供一些学习资源和进阶路径的建议。
### 6.3.1 学习资源
- **官方文档**:官方文档是最权威的学习资源,通常包括安装指南、API文档、教程和最佳实践。
- **在线课程**:随着在线教育的兴起,许多平台提供了关于Tools库的在线课程,包括视频教程和互动练习。
- **社区和论坛**:技术社区和论坛是获取帮助和分享经验的好地方。开发者可以在这些平台上提问、解答问题或参与讨论。
### 6.3.2 进阶路径
- **深入学习源码**:通过阅读和理解Tools库的源码,开发者可以更深入地理解其工作原理,从而更好地使用和扩展它。
- **参与贡献**:参与Tools库的开源项目,贡献代码或文档,是提升自身技能和获得实践经验的有效途径。
- **实践项目**:通过实际项目来应用Tools库,解决现实世界的问题,是巩固学习成果和提升实战能力的好方法。
通过上述的学习资源和进阶路径,开发者可以不断提升自己对Tools库的理解和应用能力,最终成为一名高级用户。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“Python库文件学习之Tools”深入探讨了Tools库的方方面面,从入门基础到高级功能,从实战技巧到案例分析,从错误处理到调试技巧,从源码阅读到安全实践,从API设计原则到版本管理,再到文档编写、性能分析和CI/CD实践。专栏旨在帮助读者全面掌握Tools库,提升其Python编程能力。专栏内容涵盖了Tools库的各个方面,从基本概念到高级技术,从理论知识到实践应用,为读者提供了全面的学习指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数据采集与处理:JX-300X系统数据管理的20种高效技巧

# 摘要
本文围绕JX-300X系统在数据采集、处理与管理方面的应用进行深入探讨。首先,介绍了数据采集的基础知识和JX-300X系统的架构特性。接着,详细阐述了提高数据采集效率的技巧,包括系统内置功能、第三方工具集成以及高级数据采集技术和性能优化策略。随后,本文深入分析了JX-300X系统在数据处理和分析方面的实践,包括数据清洗、预处理、分析、挖掘和可视化技术。最后,探讨了有效的数据存储解决方案、数据安全与权限管理,以及通过案例研究分享了最佳实践和提高数据
SwiftUI实战秘籍:30天打造响应式用户界面
# 摘要
随着SwiftUI的出现,构建Apple平台应用的UI变得更为简洁和高效。本文从基础介绍开始,逐步深入到布局与组件的使用、数据绑定与状态管理、进阶功能的探究,最终达到项目实战的应用界面构建。本论文详细阐述了SwiftUI的核心概念、布局技巧、组件深度解析、动画与交互技术,以及响应式编程的实践。同时,探讨了SwiftUI在项目开发中的数据绑定原理、状态管理策略,并提供了进阶功
【IMS系统架构深度解析】:掌握关键组件与数据流

# 摘要
本文对IMS(IP多媒体子系统)系统架构及其核心组件进行了全面分析。首先概述了IMS系统架构,接着深入探讨了其核心组件如CSCF、MRF和SGW的角
【版本号自动生成工具探索】:第三方工具辅助Android项目版本自动化管理实用技巧

# 摘要
版本号自动生成工具是现代软件开发中不可或缺的辅助工具,它有助于提高项目管理效率和自动化程度。本文首先阐述了版本号管理的理论基础,强调了版本号的重要性及其在软件开发生命周期中的作用,并讨论了版本号的命名规则和升级策略。接着,详细介绍了版本号自动生成工具的选择、配置、使用以及实践案例分析,揭示了工具在自动化流程中的实际应用。进一步探讨了
【打印机小白变专家】:HL3160_3190CDW故障诊断全解析
# 摘要
本文系统地探讨了HL3160/3190CDW打印机的故障诊断与维护策略。首先介绍了打印机的基础知识,包括其硬件和软件组成及其维护重要性。接着,对常见故障进行了深入分析,覆盖了打印质量、操作故障以及硬件损坏等各类问题。文章详细阐述了故障诊断与解决方法,包括利用自检功能、软件层面的问题排查和硬件层面的维修指南。此外,本文还介绍了如何制定维护计划、性能监控和优化策略。通过案例研究和实战技巧的分享,提供了针对性的故障解决方案和维护优化的最佳实践。本文旨在为技术维修人员提供一份全面的打印机维护与故障处理指南,以提高打印机的可靠性和打印效率。
# 关键字
打印机故障;硬件组成;软件组件;维护计
逆变器滤波器设计:4个步骤降低噪声提升效率
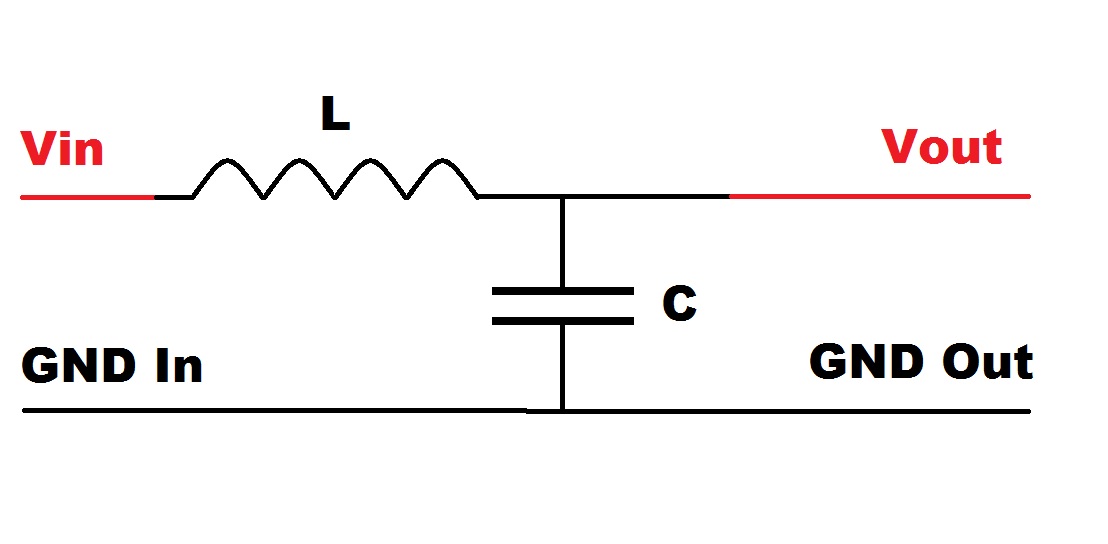
# 摘要
逆变器滤波器的设计是确保电力电子系统高效、可靠运作的关键因素之一。本文首先介绍了逆变器滤波器设计的基础知识,进而分析了噪声源对逆变器性能的影响以及滤波器在抑制噪声中的重要作用。文中详细阐述了逆变器滤波器设计的步骤,包括设计指标的确定、参数选择、模拟与仿真。通过具体的设计实践和案例分析,本文展示了滤波器的设计过程和搭建测试方法,并探讨了设计优化与故障排除的策略。最后,文章展望了滤波器设计领域未来的发展趋势
【Groovy社区与资源】:最新动态与实用资源分享指南
# 摘要
Groovy语言作为Java平台上的动态脚本语言,提供了灵活性和简洁性,能够大幅提升开发效率和程序的可读性。本文首先介绍Groovy的基本概念和核心特性,包括数据类型、控制结构、函数和闭包,以及如何利用这些特性简化编程模型。随后,文章探讨了Groovy脚本在自动化测试中的应用,特别是单元测试框架Spock的使用。进一步,文章详细分析了Groovy与S
【bat脚本执行不露声色】:专家揭秘CMD窗口隐身术

# 摘要
本论文深入探讨了CMD命令提示符及Bat脚本的基础知识、执行原理、窗口控制技巧、高级隐身技术,并通过实践应用案例展示了如何打造隐身脚本。文中详细介绍了批处理文件的创建、常用命令参数、执行环境配置、错误处理、CMD窗口外观定制以及隐蔽命令执行等
【VBScript数据类型与变量管理】:变量声明、作用域与生命周期探究,让你的VBScript更高效
# 摘要
本文系统地介绍了VBScript数据类型、变量声明和初始化、变量作用域与生命周期、高级应用以及实践案例分析与优化技巧。首先概述了VBScript支持的基本和复杂数据类型,如字符串、整数、浮点数、数组、对象等,并详细讨论了变量的声明、初始化、赋值及类型转换。接着,分析了变量的作用域和生命周期,包括全局与局部变量的区别
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )