数组与链表:Java 数据结构的基本实现
发布时间: 2024-02-12 05:13:38 阅读量: 62 订阅数: 47 

java数组和链表数据结构的区别 数组和链表.pdf
# 1. Java中数组与链表的基本概念
## 1.1 数组与链表的概念及区别
在Java中,数组和链表都是常见的数据结构,它们都可以用来存储多个元素。然而,它们在内存分配、元素访问、插入和删除操作等方面有很大的区别。数组是一种线性数据结构,它在内存中分配一块连续的空间,元素通过索引进行访问,插入和删除元素可能需要移动其他元素。链表是一种非线性数据结构,它使用指针将多个元素串联起来,插入和删除操作比较灵活,但访问元素需要从头开始逐个查找,没有直接的索引。
## 1.2 Java中数组的定义与基本操作
在Java中,数组可以通过以下方式定义:
```java
// 定义一个整型数组
int[] array = new int[5];
// 初始化数组
int[] array = {1, 2, 3, 4, 5};
// 访问数组元素
int x = array[2];
// 修改数组元素
array[3] = 10;
// 获取数组长度
int len = array.length;
```
## 1.3 Java中链表的定义与基本操作
Java中没有内置的链表数据结构,我们可以通过自定义类来实现链表,或者使用Java集合框架中的`LinkedList`来操作链表。以下是通过自定义类实现简单链表的示例:
```java
class ListNode {
int val;
ListNode next;
ListNode(int val) {
this.val = val;
}
}
// 初始化链表
ListNode head = new ListNode(1);
head.next = new ListNode(2);
// 插入节点
ListNode node = new ListNode(3);
node.next = head.next;
head.next = node;
// 删除节点
head.next = head.next.next;
```
以上是第一章的内容,接下来将会继续编写后续章节的内容。
# 2. 数组的基本实现
数组是一种最基本的数据结构,可以存储固定大小的相同类型元素的顺序集合。在Java中,数组的实现非常灵活,可以进行初始化、访问、插入、删除等操作。下面将详细介绍数组的基本实现方式。
### 2.1 数组的初始化与访问
在Java中,数组的初始化非常简单,可以通过以下方式进行:
```java
// 静态初始化
int[] arr1 = {1, 2, 3, 4, 5};
// 动态初始化
int[] arr2 = new int[5];
arr2[0] = 1;
arr2[1] = 2;
arr2[2] = 3;
arr2[3] = 4;
arr2[4] = 5;
```
对数组进行访问也非常方便,可以通过索引来获取数组中的元素:
```java
int[] arr = {1, 2, 3, 4, 5};
System.out.println(arr[0]); // 输出:1
System.out.println(arr[2]); // 输出:3
```
### 2.2 数组的插入与删除操作
在Java中,数组的插入和删除操作相对复杂,因为数组的长度是固定的。如果需要插入或删除元素,通常需要先创建一个新数组,再将元素复制到新数组中:
```java
// 插入操作
int[] oldArr = {1, 2, 3, 4, 5};
int[] newArr = new int[oldArr.length + 1];
int insertIndex = 2;
int insertValue = 10;
for (int i = 0; i < insertIndex; i++) {
newArr[i] = oldArr[i];
}
newArr[insertIndex] = insertValue;
for (int i = insertIndex + 1; i < newArr.length; i++) {
newArr[i] = oldArr[i - 1];
}
// 删除操作
int[] oldArr = {1, 2, 3, 4, 5};
int[] newArr = new int[oldArr.length - 1];
int deleteIndex = 2;
for (int i = 0; i < deleteIndex; i++) {
newArr[i] = oldArr[i];
}
for (int i = deleteIndex; i < newArr.length; i++) {
newArr[i] = oldArr[i + 1];
}
```
### 2.3 数组的遍历与常见算法
遍历数组是经常使用的操作,可以使用for循环或者增强for循环实现:
```java
int[] arr = {1, 2, 3, 4, 5};
// for循环遍历
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
// 增强for循环遍历
for (int num : arr) {
System.out.println(num);
}
```
常见的数组算法包括数组反转、查找最大/最小值、排序等,这些算法也是数组操作中的重要部分,可以根据实际情况选择合适的算法进行处理。
经过本章的学习,读者应该掌握了Java中数组的基本实现方式,包括初始化、访问、插入、删除、遍历和常见算法。接下来,我们将继续学习链表的基本实现方法。
# 3. 链表的基本实现
### 3.1 单向链表的定义与实现
在Java中,链表是一种常见的数据结构,可以用于存储和操作一系列的元素。链表由一个个节点(node)组成,每个节点都包含了一个元素和一个指向下一个节点的引用。在单向链表中,每个节点只包含一个指向下一个节点的引用。
下面是一个简单的单向链表的定义和实现示例:
```java
class Node {
int data;
Node next;
public Node(int data) {
this.data = data;
this.next = null;
}
}
class LinkedList {
Node head;
public LinkedList() {
this.head = null;
}
public void insert(int data) {
Node newNode = new Node(data);
if (head == null) {
head = newNode;
} else {
Node current = head;
while (current.next != null) {
current = current.next;
}
current.next = newNode;
}
}
public void delete(int data) {
if (head == null) {
return;
}
if (head.data == data) {
head = head.next;
return;
}
Node current = head;
while (current.next != null) {
if (current.next.data == data) {
current.next = current.next.next;
return;
}
current = current.next;
}
}
}
```
以上代码定义了一个`Node`类用于表示单向链表的节点,以及一个`LinkedList`类用于实现单向链表。`LinkedList`类具有`insert`方法用于在链表末尾插入节点,以及`delete`方法用于删除指定元素的节点。
### 3.2 双向链表的定义与实现
在双向链表中,每个节点除了包含一个指向下一个节点的引用外,还包含一个指向前一个节点的引用。相比于单向链表,双向链表的查询操作更加高效,但是在插入和删除操作时需要处理更多的指针。
下面是一个简单的双向链表的定义和实现示例:
```java
class Node {
int data;
Node prev;
Node next;
public Node(int data) {
this.data = data;
this.prev = null;
this.next = null;
}
}
class DoublyLinkedList {
Node head;
public DoublyLinkedList() {
this.head = null;
}
public void insert(int data) {
Node newNode = new Node(data);
if (head == null) {
head = newNode;
} else {
Node current = head;
while (current.next != null) {
current = current.next;
}
current.next = newNode;
newNode.prev = current;
}
}
public void delete(int data) {
if (head == null) {
return;
}
if (head.data == data) {
head = head.next;
head.prev = null;
return;
}
Node current = head;
while (current.next != null) {
if (current.next.data == data) {
current.next = current.next.next;
if (current.next != null) {
current.next.prev = current;
}
return;
}
current = current.next;
}
}
}
```
以上代码定义了一个`Node`类用于表示双向链表的节点,以及一个`DoublyLinkedList`类用于实现双向链表。`DoublyLinkedList`类具有`insert`方法用于在链表末尾插入节点,以及`delete`方法用于删除指定元素的节点。
在实际应用中,根据具体需求选择单向链表还是双向链表。如果需要频繁在链表的末尾插入和删除节点,可以选择单向链表;如果需要频繁在链表的中间插入和删除节点,或者需要双向遍历链表,可以选择双向链表。
# 4. 数组与链表的性能分析
在实际的软件开发中,我们经常会需要选择合适的数据结构来存储和处理数据。数组和链表是常见的数据结构,它们各自有着不同的特点和性能表现。在本章中,我们将对数组和链表的性能进行分析,以便在实际开发中能够更好地选择合适的数据结构。
#### 4.1 数组与链表的时间复杂度比较
数组和链表在插入、删除和查找等操作上有着不同的时间复杂度表现。
- **数组的时间复杂度**:
- 插入:对于无序数组,插入的时间复杂度为O(1);对于有序数组,平均情况下为O(n)。
- 删除:平均情况下为O(n)。
- 查找:平均情况下为O(n)。
- **链表的时间复杂度**:
- 插入:平均情况下为O(1)。
- 删除:平均情况下为O(1)。
- 查找:平均情况下为O(n)。
由上可知,链表在插入和删除操作上有着明显的优势,而数组在查找操作上略有优势。因此,在需要频繁进行插入和删除操作的场景下,链表更适合;而对于需要频繁进行查找操作的场景,数组可能更优秀一些。
#### 4.2 数组与链表的空间复杂度比较
除了时间复杂度之外,空间复杂度也是考量数据结构的重要指标。
- **数组的空间复杂度**:
- 需要连续的内存空间来存储元素,一旦数组创建后,其大小不可改变,可能会出现空间浪费的情况。
- **链表的空间复杂度**:
- 需要额外的空间来存储指向下一个节点的指针,但可以更灵活地分配内存空间,不存在大小固定的问题。
#### 4.3 如何选择合适的数据结构
在实际开发中,如果需要频繁进行插入和删除操作,且对内存空间的动态分配要求较高,那么链表可能是更好的选择;而如果对内存空间利用率要求较高,且主要进行查找操作,那么数组可能更适合。
综合考虑时间复杂度和空间复杂度,以及具体的应用场景,对于选择合适的数据结构至关重要。在实际开发中,我们需要根据具体情况做出合理的选择,以便在性能和内存利用上都能取得较好的表现。
通过本章的分析,我们对数组和链表的性能特点有了更深入的了解,能够更好地在实际开发中进行选择和应用。
# 5. Java中数组与链表的应用场景
## 5.1 数组与链表在算法中的应用
数组与链表是两种常用的数据结构,在算法中都有各自的应用场景。
### 5.1.1 数组在算法中的应用
- **动态规划**:动态规划算法中,数组常用来存储中间计算结果,以减少重复计算。
- **贪心算法**:贪心算法中,数组可以用来存储元素的权重或者价值,在某些问题中有重要的作用。
- **排序算法**:很多排序算法(如快速排序、归并排序)都是基于数组进行操作的。
### 5.1.2 链表在算法中的应用
- **递归**:链表结构天然适合递归操作,例如反转链表、合并链表等。
- **深度优先搜索(DFS)**:在一些图遍历算法中,链表可以用来表示图的邻接表。
- **回溯算法**:链表可以被用作回溯过程中的数据结构之一。
## 5.2 数组与链表在实际开发中的应用
数组和链表在实际的软件开发中都有着广泛的应用。
### 5.2.1 数组的应用场景
- **数据库管理**:在数据库中,数组被广泛用于存储大量数据,并且可以通过索引快速访问数据。
- **图像处理**:在图像处理中,数组可以用来表示图像像素点的颜色值。
- **机器学习**:在机器学习中,数组常用于存储特征向量和标签。
### 5.2.2 链表的应用场景
- **队列和栈**:链表的特点使其在实现队列和栈等数据结构时非常合适。
- **系统设计**:在分布式系统设计中,链表可以用于实现高效的消息队列。
- **文本编辑器**:在文本编辑器中,链表被广泛用于实现撤销和恢复功能。
## 5.3 如何根据情况选择合适的数据结构
在实际开发中,根据问题的需求和特点选择合适的数据结构是非常重要的。下面是一些指导原则:
- **时间复杂度**:如果需要在常数时间内访问或修改元素,数组是较好的选择;如果需要频繁的插入和删除操作,链表可能更合适。
- **空间复杂度**:数组通常需要连续的内存空间,而链表通过指针连接节点,更为灵活。
- **功能需求**:根据问题的需求,选择数组或链表结构中更适合实现功能的数据结构。
综上所述,根据具体应用场景和需求,选择合适的数据结构对于系统的性能和功能都具有重要影响。
希望本章的内容对你有所启发,为你在实际应用中选择合适的数据结构提供了指导。接下来,我们将进入下一章,深入分析数组与链表的性能。
# 6. 扩展阅读与实践
本章将介绍一些扩展阅读和实践的内容,帮助读者深入学习数据结构的相关知识并在实际项目中运用。
### 6.1 其他数据结构的学习路径
除了数组与链表,还有许多其他常用的数据结构,如栈、队列、树、堆、图等。在学习数据结构时,了解和掌握这些数据结构也是非常重要的。以下是一些建议的学习路径:
- 栈和队列是常用的数据结构,它们可以帮助我们解决很多实际问题。在学习栈和队列时,可以先了解它们的定义和基本操作,然后学习它们的应用场景和常见算法。
- 树是一种重要的数据结构,它在计算机科学中被广泛应用。学习树的基本概念后,可以深入学习二叉树、平衡树、红黑树等常用的树结构,了解它们的特点和应用。
- 堆是一种特殊的树结构,主要用于实现优先队列。学习堆的基本知识后,可以进一步学习二叉堆、斐波那契堆等高级堆结构。
- 图是一种非常复杂的数据结构,它由节点和边组成,用于表示事物之间的关系。学习图的基本概念后,可以进一步学习图的遍历算法、最短路径算法、最小生成树算法等。
### 6.2 利用数组与链表解决实际问题的案例分析
在实际项目中,数组与链表是常用的数据结构,它们能够帮助我们解决许多实际问题。以下是一些案例分析:
**案例1:员工管理系统**
我们需要设计一个员工管理系统,包含员工信息的增加、删除、查找等操作。可以使用链表来实现这个系统,每个节点表示一个员工,节点中保存员工的相关信息。
```java
// 节点类
class EmployeeNode {
String name;
int age;
EmployeeNode next;
public EmployeeNode(String name, int age) {
this.name = name;
this.age = age;
this.next = null;
}
}
// 链表类
class EmployeeLinkedList {
private EmployeeNode head;
public EmployeeLinkedList() {
this.head = null;
}
public void add(String name, int age) {
EmployeeNode newNode = new EmployeeNode(name, age);
if (head == null) {
head = newNode;
} else {
EmployeeNode current = head;
while (current.next != null) {
current = current.next;
}
current.next = newNode;
}
}
public void delete(String name) {
if (head == null) {
return;
}
if (head.name.equals(name)) {
head = head.next;
} else {
EmployeeNode current = head;
while (current.next != null && !current.next.name.equals(name)) {
current = current.next;
}
if (current.next != null) {
current.next = current.next.next;
}
}
}
public void printAll() {
EmployeeNode current = head;
while (current != null) {
System.out.println("Name: " + current.name + ", Age: " + current.age);
current = current.next;
}
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
EmployeeLinkedList list = new EmployeeLinkedList();
list.add("Alice", 25);
list.add("Bob", 30);
list.add("Chris", 35);
list.printAll();
list.delete("Bob");
System.out.println("--- After deletion ---");
list.printAll();
}
}
```
代码总结:以上代码演示了如何使用链表来实现员工管理系统。链表的优势是可以动态地添加和删除员工信息,适合对员工信息进行频繁操作的场景。
**案例2:商品库存管理**
我们需要设计一个商品库存管理系统,包含商品的添加、修改、查找等操作。可以使用数组来实现这个系统,每个元素表示一个商品,元素中保存商品的相关信息。
```java
// 数组类
class InventoryArray {
private String[] names;
private double[] prices;
private int[] quantities;
private int size;
private int capacity;
public InventoryArray(int capacity) {
this.names = new String[capacity];
this.prices = new double[capacity];
this.quantities = new int[capacity];
this.size = 0;
this.capacity = capacity;
}
public void add(String name, double price, int quantity) {
if (size == capacity) {
expandCapacity();
}
names[size] = name;
prices[size] = price;
quantities[size] = quantity;
size++;
}
public void modify(String name, double newPrice) {
int index = find(name);
if (index != -1) {
prices[index] = newPrice;
System.out.println("Modified " + name + "'s price to: " + newPrice);
}
}
public int find(String name) {
for (int i = 0; i < size; i++) {
if (names[i].equals(name)) {
return i;
}
}
return -1;
}
public void printAll() {
for (int i = 0; i < size; i++) {
System.out.println("Name: " + names[i] + ", Price: " + prices[i] + ", Quantity: " + quantities[i]);
}
}
private void expandCapacity() {
int newCapacity = capacity * 2;
String[] newNames = new String[newCapacity];
double[] newPrices = new double[newCapacity];
int[] newQuantities = new int[newCapacity];
for (int i = 0; i < size; i++) {
newNames[i] = names[i];
newPrices[i] = prices[i];
newQuantities[i] = quantities[i];
}
names = newNames;
prices = newPrices;
quantities = newQuantities;
capacity = newCapacity;
System.out.println("Expanded capacity to: " + newCapacity);
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
InventoryArray inventory = new InventoryArray(3);
inventory.add("Apple", 2.5, 10);
inventory.add("Banana", 1.8, 8);
inventory.add("Orange", 3.0, 5);
inventory.printAll();
inventory.modify("Banana", 2.0);
System.out.println("--- After modification ---");
inventory.printAll();
}
}
```
代码总结:以上代码演示了如何使用数组来实现商品库存管理系统。数组的优势是可以快速访问商品信息,适合对商品信息进行频繁查找的场景。
### 6.3 如何在项目中合理运用数据结构以提升性能
在实际项目中,合理运用数据结构可以提升系统的性能和效率。以下是一些建议:
- 根据实际需求选择合适的数据结构。不同的数据结构有不同的特点和适用场景,选择合适的数据结构可以使系统更高效。
- 对于大规模的数据操作,尽量避免频繁的插入和删除操作,因为这可能导致数据结构的频繁调整和内存的频繁分配,影响系统性能。在这种情况下,可以选择适当的数据结构或算法来优化操作。
- 对于频繁访问和查找的场景,可以使用哈希表来存储数据,它能够实现快速的插入、删除和查找操作。
- 在设计数据库表结构时,可以合理运用索引来提高查询效率。索引可以将数据库的查询操作从全表扫描变为按索引快速定位,提高查询效率。
总之,在项目中合理选择和运用数据结构,可以显著提升系统的性能和效率,提高用户体验。
希望本章的内容能够帮助读者更深入地学习数据结构,并在实际项目中灵活运用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏《Java数据结构与算法面试实战课程详解》提供了深入解析和实践Java中常用的数据结构与算法的课程。文章包括《Java 数据结构简介与基本概念解析》,介绍了Java中基本的数据结构;《数组与链表:Java 数据结构的基本实现》,讲解了数组和链表的实现方式;《排序算法原理与实践:Java 中的多种排序技术》,详细介绍了Java中常用的排序算法;《搜索算法:深入浅出 Java 中的查找技术》,解析了Java中的搜索技术;《哈希表与映射:高效的数据结构应用》,讨论了哈希表的应用;《字符串处理与匹配算法:Java中的常用技术》,探讨了字符串处理与匹配算法;《动态规划:复杂问题的优化解决方案》和《贪心算法:在Java中解决最优化问题》讲解了如何用动态规划和贪心算法解决问题;《位运算与布隆过滤器:高级数据结构与算法应用》讨论了位运算和布隆过滤器的应用;《图论基础知识:Java中的常见应用》介绍了图论的基本概念;《最短路径算法:解决Java中的路由与导航问题》讨论了最短路径算法;《拓扑排序与关键路径:解决项目管理中的顺序问题》探讨了拓扑排序和关键路径的应用;《流量网络与最大流算法:高级图论技术在Java中的应用》介绍了流量网络和最大流算法;《多重集与列表:Java中的复杂数据结构实现》和《集合类与并查集:Java中的高级数据结构应用》探索了复杂数据结构的实现方式;《霍夫曼编码与压缩算法:Java中的数据压缩技术》研究了数据压缩技术。通过学习这个专栏,读者将深入了解Java中常用的数据结构与算法,并能够在面试中灵活运用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Madagascar程序安装详解:手把手教你解决安装难题

# 摘要
Madagascar是一套用于地球物理数据处理与分析的软件程序。本文首先概述了Madagascar程序的基本概念、系统要求,然后详述了其安装步骤,包括从源代码、二进制包安装以及容器技术部署的方法。接下来,文章介绍了如何对Madagascar程序进行配置与优化,包括
【Abaqus动力学仿真入门】:掌握时间和空间离散化的关键点

# 摘要
本文综合概述了Abaqus软件在动力学仿真领域的应用,重点介绍了时间离散化和空间离散化的基本理论、选择标准和在仿真实践中的重要性。时间离散化的探讨涵盖了不同积分方案的选择及其适用性,以及误差来源与控制策略。空间离散化部分详细阐述了网格类型、密度、生成技术及其在动力学仿真中的应用。在动力学仿真实践操作中,文中给出了创建模型、设置分析步骤、数据提取和后处理的具体指导。最后,本文还探讨了非线
精确控制每一分电流:Xilinx FPGA电源管理深度剖析
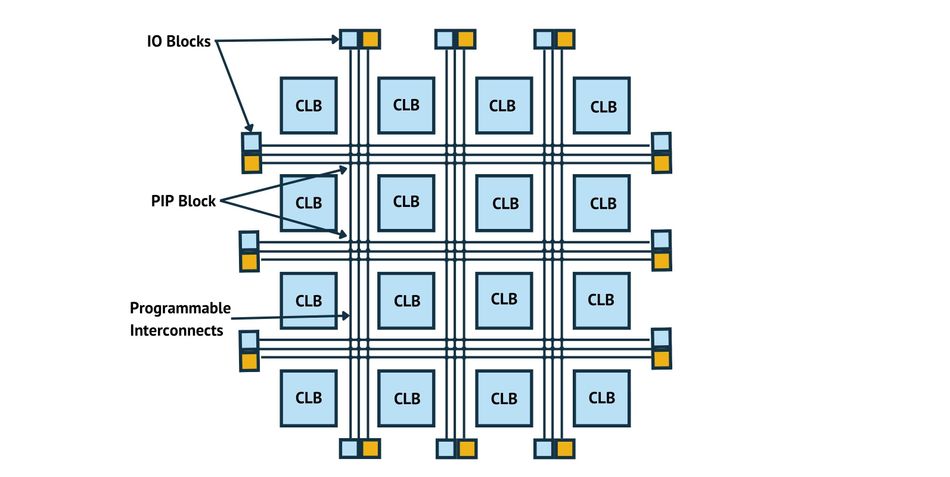
# 摘要
本文全面介绍并分析了FPGA电源管理的各个方面,从电源管理的系统架构和关键技术到实践应用和创新案例。重点探讨了Xilinx F
三维激光扫描技术在行业中的12个独特角色:从传统到前沿案例
# 摘要
三维激光扫描技术是一种高精度的非接触式测量技术,广泛应用于多个行业,包括建筑、制造和交通。本文首先概述了三维激光扫描技术的基本概念及其理论基础,详细探讨了其工作原理、关键参数以及分类方式。随后,文章通过分析各行业的应用案例,展示了该技术在实际操作中的实践技巧、面临的挑战以及创新应用。最后,探讨了三维激光扫描技术的前沿发展和行业发展趋势,强调了技术创新对行业发展的推动作用。本研究旨在为相关行业提供技术应用和发展的参考,促进三维激光扫描技术的进一步普及和深化应用。
# 关键字
三维激光扫描技术;非接触式测量;数据采集与处理;精度与分辨率;多源数据融合;行业应用案例
参考资源链接:[三维
【深入EA】:揭秘UML数据建模工具的高级使用技巧

# 摘要
UML数据建模是软件工程中用于可视化系统设计的关键技术之一。本文旨在为读者提供UML数据建模的基础概念、工具使用和高级特性分析,并探讨最佳实践以及未来发展的方向。文章从数据建模的基础出发,详细介绍了UML数据建模工具的理论框架和核心要素,并着重分析了模型驱动架构(MDA)以及数据建模自动化工具的应用。文章进一步提出了数据建模的优化与重构策略,讨论了模式与反模式,并通过案例研究展示了UML数据建模
CPCI标准2.0合规检查清单:企业达标必知的12项标准要求

# 摘要
CPCI标准2.0作为一项广泛认可的合规性框架,旨在为技术产品与服务提供清晰的合规性指南。本文全面概述了CPCI标准2.0的背景、发展、核心内容及其对企业和行业的价值。通过对标准要求的深入分析,包括技术、过程及管理方面的要求,本文提供了对合规性检查工具和方法的理解,并通过案例研究展示了标准的应用与不合规的后果。文章还探讨了实施前的准备工作、实施过程中的
【系统管理捷径】:Win7用户文件夹中Administrator.xxx文件夹的一键处理方案
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/z/U/B8daU9QrCGUjGluubd2Q/2013-02-19-ao-clicar-em-detalhes-reparem
RTD2555T应用案例分析:嵌入式系统中的10个成功运用

# 摘要
RTD2555T芯片作为嵌入式系统领域的重要组件,因其高效能和高度集成的特性,在多种应用场合显示出显著优势。本文首先介绍了RTD2555T芯片的硬件架构和软件支持,深入分析了其在嵌入式系统中的理论基础。随后,通过实际应用案例展示了RTD2555T芯片在工业控制、消费电子产品及汽车电子系统中的多样
按键扫描技术揭秘:C51单片机编程的终极指南

# 摘要
本文全面介绍了按键扫描技术的基础知识和应用实践,首先概述了C51单片机的基础知识,包括硬件结构、指令系统以及编程基础。随后,深入探讨了按键扫描技术的原理,包括按键的工作原理、基本扫描方法和高级技术。文章详细讨论了C51单片机按键扫描编程实践,以及如何实现去抖动和处理复杂按键功能。最后,针对按键扫描技术的优化与应用进行了探讨,包括效率优化策略、实际项目应用实例以及对未来趋势的预
【C语言数组与字符串】:K&R风格的处理技巧与高级应用
# 摘要
本论文深入探讨了C语言中数组与字符串的底层机制、高级应用和安全编程实践。文章首先回顾了数组与字符串的基础知识,并进一步分析了数组的内存布局和字符串的表示方法。接着,通过比较和分析C语言标准库中的关键函数,深入讲解了数组与字符串处理的高级技巧。此外,文章探讨了K&R编程风格及其在现代编程实践中的应用,并研究了在动态内存管理、正则表达式以及防御性编程中的具体案例。最后,通过对大型项目和自定义数据结构中数组与字符串应用的分析,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )