【面向对象数据库交互】:Hibernate映射技术全面解析
发布时间: 2024-12-10 05:33:38 阅读量: 13 订阅数: 17 

精通Hibernate:Java对象持久化详解.zip
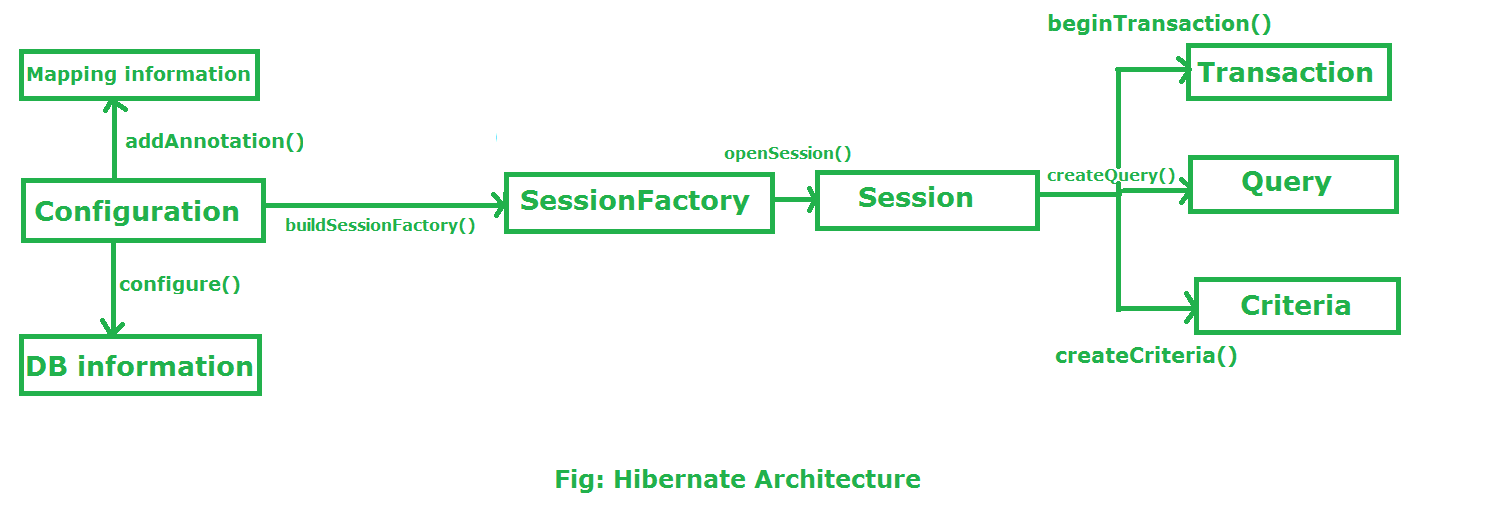
# 1. Hibernate框架概述
Hibernate是一个开源的对象关系映射(ORM)框架,它使得开发者能够使用Java语言中的对象来操作关系型数据库。这种ORM方法不仅减少了开发者的数据库操作代码,而且极大地提升了开发效率,同时使得Java代码与数据库之间的耦合度大大降低。
在ORM技术中,Hibernate作为一个重量级框架,提供了从简单的CRUD(创建、读取、更新和删除)操作到复杂的事务管理和查询优化的全面解决方案。它的核心特性包括透明持久化、查询语言HQL(Hibernate Query Language)、缓存机制和事务管理等。
开发者无需了解底层数据库的细节,就能利用Hibernate的强大功能进行数据库应用开发。本章会带领读者进入Hibernate的世界,为后续章节关于环境搭建、映射技术以及优化策略等深入探讨打下基础。
# 2. Hibernate的环境搭建和配置
## 2.1 环境搭建
### 2.1.1 Hibernate的下载和安装
Hibernate框架的下载和安装步骤是进行Hibernate开发的首要任务。首先,前往Hibernate官方网站下载所需版本的Hibernate框架。下载完成后,解压到本地计算机上指定的目录中。
安装过程简单,通常只涉及解压步骤。接下来需要配置系统环境变量,确保Java环境变量和Hibernate的`lib`目录路径被加入到`CLASSPATH`变量中。这样,Java应用程序才能正确地加载Hibernate的jar包,以及所需的所有依赖库。
### 2.1.2 Hibernate与数据库的连接
完成Hibernate下载和安装后,下一步是配置Hibernate与数据库之间的连接。通常,这一过程涉及编辑Hibernate的配置文件`hibernate.cfg.xml`,来指定数据库的连接信息和Hibernate运行时需要使用的属性。
在此配置文件中,需要设定数据库的驱动程序、URL、用户名和密码等信息。这一信息将允许Hibernate在应用程序运行时,自动地建立与数据库之间的连接。
```xml
<hibernate-configuration>
<session-factory>
<!-- Database connection settings -->
<property name="connection.driver_class">org.postgresql.Driver</property>
<property name="connection.url">jdbc:postgresql://localhost:5432/mydatabase</property>
<property name="connection.username">dbuser</property>
<property name="connection.password">dbpass</property>
<!-- SQL dialect -->
<property name="dialect">org.hibernate.dialect.PostgreSQLDialect</property>
<!-- Enable Hibernate's automatic session context management -->
<property name="current_session_context_class">thread</property>
<!-- Echo all executed SQL to stdout -->
<property name="show_sql">true</property>
<!-- Drop and re-create the database schema on startup -->
<property name="hbm2ddl.auto">update</property>
<!-- Mapping files -->
<mapping class="com.example.MyEntity"/>
</session-factory>
</hibernate-configuration>
```
在上述配置中,`connection.driver_class` 指定了数据库的驱动程序,`connection.url` 是数据库的JDBC URL,`connection.username` 和 `connection.password` 分别为数据库的用户名和密码。`dialect` 属性用于指定数据库使用的SQL方言,以便Hibernate可以生成兼容特定数据库的SQL语句。
## 2.2 配置文件解析
### 2.2.1 hibernate.cfg.xml的配置
`hibernate.cfg.xml` 是Hibernate配置的中心文件。它包含了与数据库交互所需的所有配置信息。该文件的配置通常包括以下几个方面:
- 数据库连接参数:包括驱动类、连接URL、用户名和密码等。
- 数据库方言:指定Hibernate使用的SQL方言,以支持特定数据库的特性。
- Session工厂配置:例如事务工厂类型、当前会话上下文类等。
- 是否显示SQL:`show_sql` 参数控制Hibernate是否打印执行的SQL到控制台。
- Schema管理:`hbm2ddl.auto` 属性配置Hibernate在启动和关闭时对数据库schema的管理行为。
### 2.2.2 实体类映射文件的配置
除了`hibernate.cfg.xml`之外,Hibernate还需要实体类映射文件来完成实体类到数据库表的映射。这些映射文件可以是XML格式的,也可以是注解的方式。
以XML映射文件为例,每个实体类对应一个映射文件,文件名通常与实体类名相同(但不包含包路径),并将映射文件放在与实体类相同的包中或指定在`hibernate.cfg.xml`中。
```xml
<class name="com.example.MyEntity" table="MY_ENTITY_TABLE">
<id name="id" type="java.lang.Integer">
<generator class="native"/>
</id>
<property name="name" type="java.lang.String"/>
<!-- Additional properties -->
</class>
```
在上述配置中,`<class>` 标签定义了实体类和数据库表之间的映射关系。`name` 属性指定了对应的实体类全名,`table` 属性指定了数据库中的表名。`<id>` 标签定义了实体类的主键映射,`generator` 类型定义了主键生成策略。`<property>` 标签则用于定义实体类的其他属性与数据库表列的映射。
实体类映射文件的配置是确保Hibernate正确地持久化和检索对象的关键。通过这些映射,Hibernate知道如何将对象的状态转换为SQL语句,以及如何将查询结果转换回应用程序中的对象。
# 3. Hibernate基本映射技术
## 3.1 实体映射
### 实体类的创建和映射
Hibernate的核心是将Java对象映射到数据库表。要实现这种映射,首先需要创建实体类,然后通过注解或XML映射文件来定义这种映射关系。实体类通常包含主键(用于唯一标识表中的记录)和业务属性。每个实体类都代表数据库表中的一行数据。
```java
@Entity
@Table(name="EMPLOYEE")
public class Employee {
@Id
@Column(name="ID")
private int id;
@Column(name="NAME")
private String name;
@Column(name="DEPARTMENT")
private String department;
// standard getters and setters
}
```
在上述代码段中,`@Entity`注解表示该类是一个实体类。`@Table(name="EMPLOYEE")`注解定义了数据库中的表名,而`@Id`和`@Column`注解则分别用于标识主键和表中的列。
### 实体关系的映射
实体之间的关系主要通过主键/外键关系、一对多、多对一、一对一以及多对多等几种方式实现。在Hibernate中,可以通过映射文件或注解来配置这些关系。
以下是一个简单的多对一关系映射的例子:
```java
@Entity
@Table(name="DEPARTMENT")
public class Department {
@Id
@Column(name="ID")
private int id;
@Column(name="DEPARTMENT_NAME")
private String name;
// reference to Employee
@OneToMany(mappedBy="department")
private List<Employee> employees;
// standard getters and setters
}
```
在`Department`实体中,一个部门可以包含多个员工(一对多关系),这是通过`@OneToMany`注解来定义的。员工实体通过`@ManyToOne`来反向引用部门。
## 3.2 集合映射
### 集合映射的类型和配置
集合映射在Hibernate中是常见的需求,它允许将集合类型的属性映射到数据库中。集合类型包括List, Set, Map等。配置集合映射通常在实体类中使用特定的注解来完成。
以下是一个Set集合映射的例子:
```java
@Entity
public class Employee {
@Id
private int id;
@ElementCollection
@CollectionTable(name="ADDRESS", joinColumns=@JoinColumn(name="EMPLOYEE_ID"))
@Column(name="ADDRESS")
private Set<String> address = new HashSet<>();
// standard getters and setters
}
```
在该例子中,`@ElementCollection`注解表明`address`属性是一个集合类型。`@CollectionTable`注解定义了存储集合数据的数据库表,而`@Column`注解指定了表中的列名。
### 集合映射的高级应用
高级映射可能包括映射复合主键或使用嵌入式集合。这类映射更复杂,但提供了灵活性和细粒度控制。
以下是一个使用嵌入式集合映射的例子:
```java
@Embeddable
public class Address {
private String street;
private String city;
private String zipCode;
// standard getters and setters
}
@Entity
public class Employee {
@Id
private int id;
@ElementCollection
@CollectionTable(name="ADDRESS")
@AttributeOverrides({
@AttributeOverride(name="street", column=@Column(name="HOME_STREET")),
@AttributeOverride(name="city", column=@Column(name="HOME_CITY")),
@AttributeOverride(name="zipCode", column=@Column(name="HOME_ZIP"))
})
private List<Address> homeAddresses = new ArrayList<>();
// standard getters and setters
}
```
在这个例子中,`Address`类被嵌入到`Employee`类的`homeAddresses`集合属性中。每个地址属性都被映射为单独的数据库列。这允许数据库更精确地控制嵌入数据。
接下来,将会探讨如何通过组件映射来扩展实体的属性,使得相关属性的映射更加灵活。
# 4. Hibernate高级映射技术
## 4.1 组件映射
### 4.1.1 组件映射的定义和配置
组件映射是Hibernate中一种将一个实体类的多个属性映射到数据库的多个列的方式。在实际应用中,某些情况下一个复杂的对象可能需要在数据库中映射为多个列,这时候我们可以考虑使用组件映射。
在Hibernate中配置组件映射相对简单,主要需要在实体类中定义一个内部类作为组件,并在该组件类上使用`@Embeddable`注解。同时,在外层的实体类中使用`@Embedded`注解来嵌入这个组件。
以下是一个简单的组件映射示例代码:
```java
import javax.persistence.Embeddable;
import javax.persistence.Embedded;
@Embeddable
public class Address {
private String street;
private String city;
private String zipCode;
// 构造函数、getter和setter省略
}
public class Customer {
@Id
private Long id;
private String name;
@Embedded
private Address address;
// 构造函数、getter和setter省略
}
```
在`hibernate.cfg.xml`配置文件中,通常不需要为组件单独配置,因为组件映射是由`@Embedded`注解驱动的。
### 4.1.2 组件映射的应用实例
理解组件映射的最好方式是通过一个实际的例子。假设我们有一个客户实体,其中包含一个地址组件,我们想要将其持久化到数据库中。那么,我们首先需要定义`Address`类为可嵌入组件,并且在`Customer`实体中嵌入它。之后,Hibernate框架会自动处理这些映射细节。
```java
@Entity
@Table(name = "Customer")
public class Customer {
@Id
@GeneratedValue
@Column(name = "id")
private Long id;
private String name;
@Embedded
private Address address;
// 构造函数、getter和setter省略
}
@Embeddable
public class Address {
private String street;
private String city;
private String zipCode;
// 构造函数、getter和setter省略
}
```
然后,在`hibernate.cfg.xml`中配置此实体:
```xml
<session-factory>
<!-- 其他配置省略 -->
<mapping class="com.example.Customer"/>
</session-factory>
```
在数据库中,Hibernate会为`Customer`表创建三个额外的列来存储`Address`组件的属性。
## 4.2 继承映射
### 4.2.1 继承映射的类型和配置
继承映射在Hibernate中是一个很重要的高级特性,它允许我们通过继承的方式创建一个类层次结构,并将它们映射到单一数据库表或一组表。Hibernate提供了三种继承映射策略:
1. 每个具体的类一个表(Table per concrete class)
2. 每个子类一个表(Table per subclass)
3. 每个子类层次一个表(Table per class hierarchy)
每种映射策略都有其使用场景和优缺点,开发者可以根据具体的业务需求选择合适的映射策略。
例如,使用“每个子类一个表”的策略,对于继承层次结构的映射,我们需要在父类上添加`@Inheritance`注解并设置策略为`InheritanceType.SINGLE_TABLE`。然后,为每个子类添加`@DiscriminatorValue`注解来指定区分值。
```java
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn(name = "dtype")
public abstract class Vehicle {
@Id
@GeneratedValue
private Long id;
// 其他通用属性省略
}
@Entity
@DiscriminatorValue("car")
public class Car extends Vehicle {
private String model;
// 构造函数、getter和setter省略
}
@Entity
@DiscriminatorValue("truck")
public class Truck extends Vehicle {
private int payload;
// 构造函数、getter和setter省略
}
```
### 4.2.2 继承映射的应用实例
我们可以通过一个例子来进一步了解继承映射的应用。假设我们有一个车辆的继承层次结构,其中`Vehicle`是基类,`Car`和`Truck`是具体的子类。每种类型的车辆都会有不同的属性。我们可以使用上述的“每个子类一个表”的策略来映射这个层次结构。
```java
@Entity
@Table(name = "vehicle")
public class Vehicle {
@Id
@Column(name = "id")
private Long id;
@Column(name = "dtype")
private String dtype; // 此列用于区分不同的子类
// 基类属性
// 其他通用属性省略
}
@Entity
@Table(name = "car")
@DiscriminatorValue("car")
public class Car extends Vehicle {
private String model;
// 构造函数、getter和setter省略
}
@Entity
@Table(name = "truck")
@DiscriminatorValue("truck")
public class Truck extends Vehicle {
private int payload;
// 构造函数、getter和setter省略
}
```
在`hibernate.cfg.xml`配置文件中配置这些实体:
```xml
<session-factory>
<!-- 其他配置省略 -->
<mapping class="com.example.Vehicle"/>
<mapping class="com.example.Car"/>
<mapping class="com.example.Truck"/>
</session-factory>
```
Hibernate将创建三个表,分别是`vehicle`、`car`和`truck`,其中`car`和`truck`表会扩展`vehicle`表来存储子类特有的数据。`dtype`列将用于区分存储的子类类型。
这样,我们就能够将对象继承结构映射到数据库中,并且能够持久化和检索不同类型的车辆对象,而无需担心如何处理不同的表和列。
# 5. Hibernate的持久化操作
在深入探讨Hibernate持久化操作之前,理解持久化对象的生命周期是至关重要的。持久化对象是指那些与数据库同步的Java对象,它们由Hibernate管理其状态。在这一章节中,我们将从理论和实践两个方面,详细探讨Hibernate的持久化对象状态,以及CRUD(创建、读取、更新、删除)操作的实现和查询操作的实现。
## 5.1 持久化对象状态
### 5.1.1 持久化对象的概念和特点
持久化对象是Hibernate框架中用来代表数据库中存储的数据的对象。它们是应用程序中用于业务逻辑处理的普通Java对象,但同时又具有与数据库表行相对应的特定状态和行为。一个对象成为持久化对象的几个关键特征如下:
1. **生命周期管理**:由Hibernate Session负责对象的生命周期,包括对象的创建、更新和删除。
2. **状态同步**:持久化对象的状态会与数据库中的对应行保持同步,任何对持久化对象的更改都会在事务提交时反映到数据库中。
3. **可查询性**:持久化对象可以被加入到查询操作中,包括HQL(Hibernate Query Language)和Criteria API。
4. **标识符**:持久化对象具有一个唯一的标识符,通常映射到数据库表的主键列。
### 5.1.2 持久化对象的状态转换
持久化对象的状态转换是理解Hibernate如何操作数据库的关键。一个对象可以处于以下几种状态:
- **临时状态**:对象刚刚被创建,还没有和任何Session关联,对数据库没有任何影响。
- **持久化状态**:对象已经和一个Session关联,并且数据库中存在对应的记录。
- **游离状态**(也称为脱管状态):对象之前是持久化的,但是当前没有和任何Session关联。然而数据库中仍然存在对应的记录。
### 5.2 持久化操作实例
#### 5.2.1 CRUD操作的实现
CRUD操作是持久化操作中的核心内容,我们通过实例来演示如何在Hibernate中进行创建(Create)、读取(Read)、更新(Update)和删除(Delete)操作。
##### 创建(Create)
```java
// 创建一个User实体对象
User user = new User("John Doe", "john.doe@example.com");
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
// 将临时状态的对象保存为持久化状态
session.save(user);
tx.commit();
session.close();
```
上述代码中,`session.save()` 方法将一个临时状态的User对象持久化到数据库中。
##### 读取(Read)
```java
Session session = sessionFactory.openSession();
// 使用HQL从数据库中获取对象
User foundUser = (User) session.createQuery("from User where name = 'John Doe'").uniqueResult();
session.close();
System.out.println("User ID: " + foundUser.getId());
```
这里,我们使用了`session.createQuery()` 方法执行HQL查询来读取数据库中的记录。
##### 更新(Update)
```java
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
// 读取用户,然后更改其信息
User userToUpdate = (User) session.load(User.class, 1L);
userToUpdate.setEmail("john.newemail@example.com");
session.update(userToUpdate);
tx.commit();
session.close();
```
在上述代码中,`session.update()` 方法标记了对象状态为修改过的,即在提交事务时,Hibernate将执行相应的SQL更新语句。
##### 删除(Delete)
```java
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
// 获取用户对象并删除
User userToDelete = (User) session.get(User.class, 1L);
session.delete(userToDelete);
tx.commit();
session.close();
```
`session.delete()` 方法将从数据库中删除对应的记录,并将对象的状态从持久化转变为临时状态。
#### 5.2.2 查询操作的实现
查询操作在Hibernate中通常有两种方式:使用HQL(Hibernate Query Language)和Criteria API。接下来,我们通过实例来看一下如何使用这两种方式。
##### 使用HQL
```java
Session session = sessionFactory.openSession();
// 使用HQL执行查询
List<User> users = session.createQuery("from User").list();
for (User user : users) {
System.out.println("User name: " + user.getName());
}
session.close();
```
HQL允许我们查询持久化对象的集合,非常适合于复杂查询场景。
##### 使用Criteria API
```java
Session session = sessionFactory.openSession();
// 使用Criteria API执行查询
Criteria criteria = session.createCriteria(User.class);
List<User> users = criteria.list();
for (User user : users) {
System.out.println("User email: " + user.getEmail());
}
session.close();
```
Criteria API提供了一种类型安全的查询方式,特别适合于需要动态构建查询条件的场景。
通过以上实例,我们展示了Hibernate持久化操作的CRUD和查询的基本用法。在实际应用中,根据业务需求,这些基本操作会被组合和扩展以实现复杂的数据操作逻辑。
请注意,上述代码仅为示例,实际应用中需要根据具体的数据库结构和业务需求进行适配。此外,错误处理(如捕获异常)和事务管理也是实际开发中需要重视的部分,但为了不分散注意力,这里未展示。
# 6. Hibernate的优化和性能调优
## 6.1 优化策略
### 6.1.1 SQL优化
在使用Hibernate进行数据库操作时,SQL语句的生成直接影响了应用程序的性能。优化SQL语句可以大幅度提升应用的响应速度和处理能力。
**避免N+1查询问题**:N+1查询问题是指在加载实体及其关联实体时,系统会生成一条主查询和N条子查询,造成大量的数据库访问。解决方法是在Hibernate的配置文件中设置`hibernate.fetch_size`,或者使用`@Fetch(FetchType.EAGER)`注解强制立即加载关联对象。
**使用批量操作**:对于需要批量更新或删除的场景,使用`Session.createCriteria`或HQL/SQL查询的`batch-size`参数可以减少数据库的往返次数。
### 6.1.2 缓存优化
缓存是提高数据库性能的重要手段,但不恰当的使用会适得其反。以下是一些常见的缓存优化策略:
- **合理配置缓存级别**:根据数据的访问频率和更新频率合理配置第一级缓存和二级缓存。例如,经常读取但很少更新的数据适合使用二级缓存。
- **使用查询缓存**:对于执行频率高但结果集不变的查询,启用Hibernate的查询缓存可以显著提高性能。
- **调整缓存容量**:设置合适的`maxElementsInMemory`和`overflowToDisk`参数,避免因为缓存容量不足导致的频繁的缓存替换。
## 6.2 性能调优实践
### 6.2.1 案例分析
某企业内部管理系统在使用Hibernate进行数据访问时,发现系统响应时间长,尤其是在数据量大的情况下。经过分析,确认是由于大量N+1查询问题导致的。通过调整HQL查询语句,利用`JOIN FETCH`来一次性加载关联数据,同时在配置文件中设置了合理的缓存级别和容量。实施这些调整后,系统的响应时间缩短了30%,用户体验得到显著提升。
### 6.2.2 调优工具的使用
Hibernate提供了多个工具和接口来帮助开发者进行性能调优,如:
- **Hibernate Profiler**:这是一个强大的工具,可以监控和分析Hibernate生成的SQL语句,以及事务的执行情况。它可以提供详细的执行计划和性能指标。
- **日志记录**:通过配置Hibernate的日志记录,可以查看Hibernate与数据库的交互过程,这在诊断性能问题时非常有用。可以调整日志级别来获取不同细节的信息。
- **性能分析器**:Hibernate提供了性能分析器接口,允许开发者收集运行时数据。这些数据可以用于分析数据库访问模式,并提供优化建议。
以下是一个简单的例子,展示如何在代码中使用Hibernate Profiler进行性能监控:
```java
// 创建并配置Hibernate Profiler
Configuration configuration = new Configuration().configure();
ProfilingConfiguration profilingConfig = new ProfilingConfigurationImpl();
profilingConfig.setProfilingEnabled(true);
profilingConfig.setInstrumentationEnabled(true);
// 创建并配置Session工厂
SessionFactory sessionFactory = configuration.buildSessionFactory(profilingConfig);
Session session = sessionFactory.openSession();
// 开始监控
ProfilerSupport profilers = ProfilerSupport.class.cast(session);
profilers.start();
// 执行数据操作,例如查询
List<SomeEntity> entities = session.createQuery("FROM SomeEntity").list();
// 停止监控
profilers.stop();
// 获取并查看性能分析结果
PerformanceStatistics stats = profilers.getStatistics();
System.out.println(stats);
```
通过使用这些工具和实践,开发者可以对Hibernate应用进行深入的性能调优,确保应用程序以最佳性能运行。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏深入探讨了 Java 和 Hibernate 的 ORM 映射,为开发人员提供了全面的指导。它涵盖了 Hibernate 和 JPA 的深度剖析、面向对象数据库交互、Hibernate 映射技术的全面解析、配置指南、生命周期管理、查询优化、加载策略、缓存使用、映射实现、查询对比、高级映射应用、回调拦截、批量操作、多数据库环境支持、版本控制实现和二级缓存。通过这些主题的深入分析,专栏旨在帮助开发人员掌握 Hibernate ORM 的高级技巧,优化应用程序性能,并有效地管理数据库交互。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ROST软件数据可视化技巧:让你的分析结果更加直观动人
:max_bytes(150000):strip_icc()/ScreenShot2019-10-28at1.25.36PM-ab811841a30d4ee5abb2ff63fd001a3b.jpg)
参考资源链接:[ROST内容挖掘系统V6用户手册:功能详解与操作指南](https://wenku.csdn.net/doc/5c20fd2fpo?spm=1055.2635.3001.10343)
RTCM 3.3协议深度剖析:如何构建秒级精准定位系统

参考资源链接:[RTCM 3.3协议详解:全球卫星导航系统差分服务最新标准](https://wenku.csdn.net/doc/7mrszjnfag?spm=1055.2635.3001.10343)
# 1. RTCM 3.3协议简介及其在精准定位中的作用
RTCM (Radio Technical Co
提升航空数据传输效率:AFDX网络数据流管理技巧
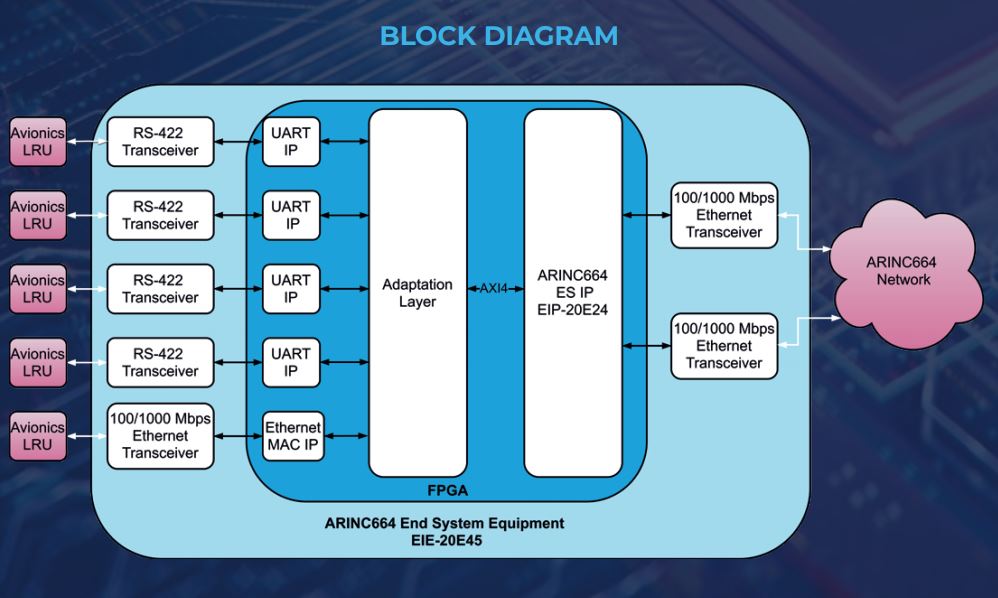
参考资源链接:[AFDX协议/ARINC664中文详解:飞机数据网络](https://wenku.csdn.net/doc/66azonqm6a?spm=1055.2635.3001.10343)
# 1. AFDX网络技术概述
## 1.1 AFDX网络技术的起源与应用背景
AFDX (Avionics Full-Duplex Switched Ethernet) 网络技术,是专为航空电子通信设计
软件开发者必读:与MIPI CSI-2对话的驱动开发策略
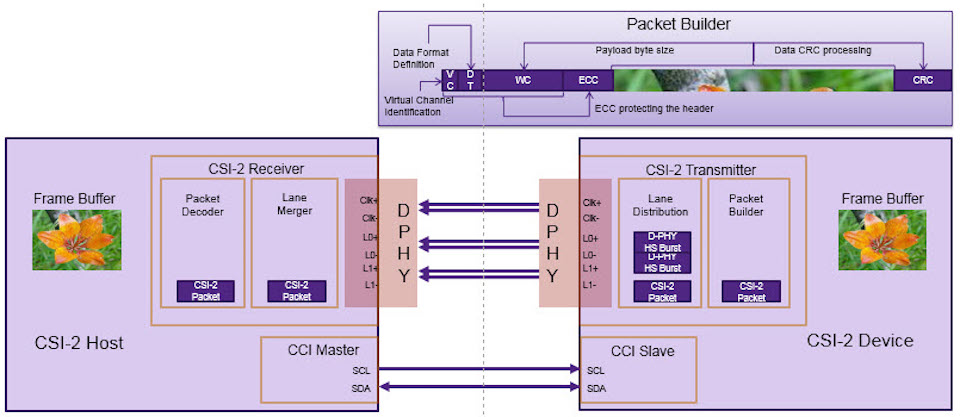
参考资源链接:[mipi-CSI-2-标准规格书.pdf](https://wenku.csdn.net/doc/64701608d12cbe7ec3f6856a?spm=1055.2635.3001.10343)
# 1. MIPI CSI-2协议概述
在当今数字化和移动化的世界里,移动设备图像性能的提升是用户体验的关键部分。为
【PCIe接口新革命】:5.40a版本数据手册揭秘,加速硬件兼容性分析与系统集成
参考资源链接:[2019 Synopsys PCIe Endpoint Databook v5.40a:设计指南与版权须知](https://wenku.csdn.net/doc/3rfmuard3w?spm=1055.2635.3001.10343)
# 1. PCIe接口技术概述
PCIe( Peripheral Component Interconnect Express)是一种高速串行计算机扩展总线标准,被广泛应用于计算机内部连接高速组件。它以点对点连接的方式,能够提供比传统PCI(Peripheral Component Interconnect)总线更高的数据传输率。PCIe的进
ZMODEM协议的高级特性:流控制与错误校正机制的精妙之处

参考资源链接:[ZMODEM传输协议深度解析](https://wenku.csdn.net/doc/647162cdd12cbe7ec3ff9be7?spm=1055.2635.3001.10343)
# 1. ZMODEM协议简介
## 1.1 什么是ZMODEM协议
ZMODEM是一种在串行通信中广泛使用的文件传输协议,它支持二进制数据传输,并可以对数据进行分块处理,确保文件完整无误地传输到目标系统。与早期的XMODEM和YMODEM协
IS903优盘通信协议揭秘:USB通信流程的全面解读

参考资源链接:[银灿IS903优盘完整的原理图](https://wenku.csdn.net/doc/6412b558be7fbd1778d42d25?spm=1055.2635.3001.10343)
# 1. USB通信协议概述
USB(通用串行总线)通信协议自从1996年首次推出以来,已经成为个人计算机和其他电子设备中最普遍的接口技术之一。该章节将概述USB通信协议的基础知识,为后续章节深入探讨USB的硬件结构、信号传输和通信流程等主题打
【功能拓展】创维E900 4K机顶盒应用管理:轻松安装与管理指南
参考资源链接:[创维E900 4K机顶盒快速配置指南](https://wenku.csdn.net/doc/645ee5ad543f844488898b04?spm=1055.2635.3001.10343)
# 1. 创维E900 4K机顶盒概述
在本章中,我们将揭开创维E900 4K机顶盒的神秘面纱,带领读者了解这一强大的多媒体设备的基本信息。我们将从其设计理念讲起,探索它如何为家庭娱乐带来高清画质和智能功能。本章节将为读者提供一个全面的概览,包括硬件配置、操作系统以及它在市场中的定位,为后续章节中关于设置、应用使用和维护等更深入的讨论打下坚实的基础。
创维E900 4K机顶盒采用先
【cx_Oracle数据库管理】:全面覆盖连接、事务、性能与安全性

参考资源链接:[cx_Oracle使用手册](https://wenku.csdn.net/doc/6476de87543f84448808af0d?spm=1055.2635.3001.10343)
# 1. cx_Oracle数据库基础介绍
cx_Oracle 是一个
【深度学习的交通预测力量】:构建上海轨道交通2030的智能预测模型

参考资源链接:[上海轨道交通规划图2030版-高清](https://wenku.csdn.net/doc/647ff0fc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )