使用Boost库实现基本的字符串操作
发布时间: 2023-12-15 03:47:02 阅读量: 56 订阅数: 32 

boost库中对字符串的一些算法
# 1. 引言
## 1.1 IT中字符串操作的重要性
在IT领域中,字符串操作是非常常见且重要的任务之一。无论是在编程语言中还是在软件开发过程中,字符串操作都扮演着关键的角色。从简单的字符串拼接到复杂的字符串比较和查找,字符串操作可以帮助我们处理和分析文本数据,提取所需信息,以及进行各种数据处理和转换。
## 1.2 Boost库的概述
Boost库是一个跨平台的C++库集合,提供了大量的功能和工具,帮助开发人员提高C++程序的质量和效率。其中也包含了一些有用的字符串操作函数,可以简化字符串处理的任务并提供更高效的解决方案。
Boost库中的字符串操作函数具有良好的性能和稳定性,广泛应用于各种领域,包括网络编程、数据处理、图像处理等。接下来,我们将介绍如何安装和配置Boost库,并详细讲解Boost库中的字符串操作函数的使用方法。
# 2. 安装和配置Boost库
Boost库作为一个C++库,提供了丰富的字符串操作函数,为C++中的字符串操作提供了很多便利。在使用Boost库中的字符串操作函数之前,首先需要进行Boost库的安装和配置。
### 2.1 下载和安装Boost库
Boost库可以从其官方网站 [Boost官网](https://www.boost.org) 下载最新版本的库文件。下载完成后,根据官方提供的安装指南进行编译和安装。
在Linux环境下,通常可以通过以下步骤安装Boost库:
```bash
sudo apt-get install libboost-all-dev
```
在Windows环境下,可以下载预编译好的库文件,或者根据官方文档自行编译安装。
### 2.2 配置Boost库的环境变量
安装完成后,需要将Boost库的路径添加到系统的环境变量中,以便编译器可以找到Boost库的头文件和链接库文件。
在Linux环境下,可以编辑`~/.bashrc`文件,添加类似以下内容:
```bash
export BOOST_ROOT=/usr/local/boost_1_75_0
export LD_LIBRARY_PATH=$BOOST_ROOT/lib:$LD_LIBRARY_PATH
export CPLUS_INCLUDE_PATH=$BOOST_ROOT
```
在Windows环境下,可以在系统环境变量中新建`BOOST_ROOT`变量,将Boost库的路径添加进去。
配置完成后,即可开始在代码中引用Boost库中的字符串操作函数。
# 3. Boost库中的基本字符串操作函数介绍
Boost库提供了许多方便的字符串操作函数,下面将介绍其中几个常用的函数。
#### 3.1 字符串拼接函数
Boost库提供了多种方法用于字符串的拼接。
首先是使用 `boost::algorithm::join` 函数,它可以将一个字符串容器中的所有字符串拼接成一个新的字符串。例如:
```cpp
#include <iostream>
#include <vector>
#include <boost/algorithm/string/join.hpp>
int main()
{
std::vector<std::string> strVec = {"Hello", "Boost", "Library"};
std::string result = boost::algorithm::join(strVec, " ");
std::cout << result << std::endl;
return 0;
}
```
运行结果为:
```
Hello Boost Library
```
另一种常见的字符串拼接方法是使用 `boost::format` 函数,它类似于C语言中的 `printf` 函数,可以通过占位符将变量插入到字符串中。例如:
```cpp
#include <iostream>
#include <boost/format.hpp>
int main()
{
std::string name = "Alice";
int age = 25;
std::string result = boost::str(boost::format("My name is %s and I am %d years old.") % name % age);
std::cout << result << std::endl;
return 0;
}
```
运行结果为:
```
My name is Alice and I am 25 years old.
```
#### 3.2 字符串比较函数
Boost库提供了多种方法用于字符串的比较。
使用 `boost::algorithm::equals` 函数可以比较两个字符串是否相等。例如:
```cpp
#include <iostream>
#include <boost/algorithm/string/equals.hpp>
int main()
{
std::string str1 = "Hello";
std::string str2 = "hello";
bool isEqual = boost::algorithm::equals(str1, str2);
std::cout << std::boolalpha << isEqual << std::endl;
return 0;
}
```
运行结果为:
```
false
```
#### 3.3 字符串查找函数
Boost库提供了多种方法用于字符串的查找。
使用 `boost::algorithm::ifind_first` 函数可以查找字符串中是否包含指定的子串,它返回一个迭代器指向第一次出现子串的位置。例如:
```cpp
#include <iostream>
#include <boost/algorithm/string/find.hpp>
int main()
{
std::string str = "Boost is a powerful library for C++ programming.";
std::string subStr = "powerful";
auto it = boost::algorithm::ifind_first(str, subStr);
if (it != str.end())
{
std::cout << "Found at position " << std::distance(str.begin(), it) << std::endl;
}
else
{
std::cout << "Not found." << std::endl;
}
return 0;
}
```
运行结果为:
```
Found at position 11
```
以上就是Boost库中的一些基本字符串操作函数的介绍。在接下来的章节中,我们将演示如何使用这些函数进行实际的字符串操作。
# 4. 使用Boost库进行字符串拼接
在实际编程中,经常需要将多个字符串拼接成一个更大的字符串。Boost库提供了多种方法来实现字符串的拼接操作。下面将介绍三种常用的拼接方法。
### 4.1 使用 `+` 运算符拼接字符串
在C++中,我们可以使用`+`运算符来拼接两个字符串。Boost库同样支持这种方式,不过需要使用`boost::algorithm::join`函数来实现。
```cpp
#include <iostream>
#include <boost/algorithm/string/join.hpp>
int main() {
std::string str1 = "Hello";
std::string str2 = "Boost";
std::string result = str1 + " " + str2;
// Output: Hello Boost
std::cout << result << std::endl;
return 0;
}
```
**代码解析:**
首先,我们定义了两个字符串`str1`和`str2`,分别存储"Hello"和"Boost"。然后,通过使用`+`运算符将两个字符串拼接在一起,并将结果赋值给`result`变量。最后,我们将拼接后的字符串输出到控制台。
**代码总结:**
使用`+`运算符可以方便地拼接两个字符串,但是在需要拼接多个字符串时,这种方式就不太灵活了。因此,接下来我们将介绍另外两种方法。
### 4.2 使用 `boost::join` 函数拼接字符串
`boost::join`函数可以将一个字符串容器(如`std::vector`或`std::list`)中的所有元素按照指定的分隔符拼接成一个字符串。
```cpp
#include <iostream>
#include <vector>
#include <boost/algorithm/string/join.hpp>
int main() {
std::vector<std::string> strs = {"Hello", "Boost", "Library"};
std::string result = boost::algorithm::join(strs, " ");
// Output: Hello Boost Library
std::cout << result << std::endl;
return 0;
}
```
**代码解析:**
首先,我们定义了一个字符串容器`strs`,其中包含了三个字符串元素。然后,使用`boost::algorithm::join`函数将容器中的所有元素拼接成一个字符串,并以空格作为分隔符。最后,将拼接后的字符串输出到控制台。
**代码总结:**
使用`boost::algorithm::join`函数可以方便地将一个字符串容器中的所有元素拼接成一个字符串,并且可以指定分隔符。
### 4.3 使用 `boost::format` 函数拼接字符串
`boost::format`函数提供了一种类似于格式化输出的方式来拼接字符串。
```cpp
#include <iostream>
#include <boost/format.hpp>
int main() {
std::string str1 = "Hello";
std::string str2 = "Boost";
std::string result = boost::str(boost::format("%s %s") % str1 % str2);
// Output: Hello Boost
std::cout << result << std::endl;
return 0;
}
```
**代码解析:**
首先,我们定义了两个字符串`str1`和`str2`,分别存储"Hello"和"Boost"。然后,使用`boost::format`函数创建了一个格式化字符串`"%s %s"`,其中`%s`表示字符串类型的占位符。接着,使用`%`运算符将`str1`和`str2`分别填充到格式化字符串中,并将结果通过`boost::str`函数转换为一个普通的字符串。最后,将拼接后的字符串输出到控制台。
**代码总结:**
使用`boost::format`函数可以方便地将多个字符串按照指定的格式拼接在一起。
通过以上三种方法,我们可以灵活地进行字符串的拼接操作,选择适合自己的方式来拼接字符串。接下来,我们将介绍Boost库中的字符串比较和查找函数。
# 5. 使用Boost库进行字符串比较和查找
在实际的软件开发过程中,经常需要对字符串进行比较和查找操作。Boost库提供了一系列方便实用的函数来帮助我们进行字符串比较和查找,下面我们将介绍其中一些常用的函数。
#### 5.1 使用boost::algorithm::equals函数比较字符串
```cpp
#include <boost/algorithm/string.hpp>
#include <iostream>
int main() {
std::string str1 = "Hello";
std::string str2 = "hello";
if(boost::algorithm::equals(str1, str2)) {
std::cout << "The strings are equal." << std::endl;
} else {
std::cout << "The strings are not equal." << std::endl;
}
return 0;
}
```
**代码总结:**
- 使用boost::algorithm::equals函数可以进行字符串的比较。
- 在上述代码中,我们比较了两个字符串,其中一个包含大写字母,另一个包含小写字母,最终输出结果为"The strings are not equal.",因为equals函数区分大小写。
**结果说明:**
- 由于boost::algorithm::equals函数区分大小写,所以输出结果为"The strings are not equal."。
#### 5.2 使用boost::algorithm::iequals函数比较字符串(不区分大小写)
```cpp
#include <boost/algorithm/string.hpp>
#include <iostream>
int main() {
std::string str1 = "Hello";
std::string str2 = "hello";
if(boost::algorithm::iequals(str1, str2)) {
std::cout << "The strings are equal." << std::endl;
} else {
std::cout << "The strings are not equal." << std::endl;
}
return 0;
}
```
**代码总结:**
- 使用boost::algorithm::iequals函数可以进行字符串的比较,且不区分大小写。
- 在上述代码中,我们比较了两个字符串,其中一个包含大写字母,另一个包含小写字母,最终输出结果为"The strings are equal.",因为iequals函数不区分大小写。
**结果说明:**
- 由于boost::algorithm::iequals函数不区分大小写,所以输出结果为"The strings are equal."。
#### 5.3 使用boost::algorithm::ifind_first函数查找子串
```cpp
#include <boost/algorithm/string.hpp>
#include <iostream>
int main() {
std::string str = "Boost C++ Libraries";
std::string sub = "C++";
if(boost::algorithm::ifind_first(str, sub)) {
std::cout << "Substring found." << std::endl;
} else {
std::cout << "Substring not found." << std::endl;
}
return 0;
}
```
**代码总结:**
- 使用boost::algorithm::ifind_first函数可以查找字符串中的子串。
- 在上述代码中,我们查找了字符串中是否包含子串"C++",最终输出结果为"Substring found.",表明子串存在于字符串中。
**结果说明:**
- 由于boost::algorithm::ifind_first函数成功找到了子串,所以输出结果为"Substring found."。
通过上述示例,我们了解了如何使用Boost库进行字符串比较和查找操作。Boost库提供了丰富的字符串操作函数,能够帮助开发人员更高效地处理字符串数据。
# 6. 总结
在本文中,我们介绍了Boost库在字符串操作方面的重要性和基本概述。我们讨论了如何安装和配置Boost库,以及Boost库中的基本字符串操作函数的介绍。然后我们深入研究了如何使用Boost库进行字符串拼接、比较和查找。
#### 6.1 Boost库字符串操作的优势
使用Boost库进行字符串操作具有以下优势:
- Boost库提供了丰富的字符串操作函数,简化了开发人员的工作。
- Boost库中的字符串操作函数经过优化和测试,具有较高的性能和稳定性。
- Boost库支持多种编程语言,使得开发人员可以在不同项目中灵活应用。
#### 6.2 进一步学习Boost库的推荐资源
如果你对Boost库的字符串操作功能感兴趣,以下是一些推荐资源,可以帮助你进一步学习:
- Boost库官方网站:https://www.boost.org/
- Boost库官方文档:https://www.boost.org/doc/
- 《Boost程序库完全解析》(Complete Guide to the Boost C++ Libraries)书籍,作者Boris Schäling
#### 6.3 结束语
通过本文的学习,我们了解了Boost库在字符串操作方面的强大功能和优势,希望能够对你的开发工作有所帮助。接下来,你可以尝试在实际项目中应用Boost库的字符串操作函数,体验其强大的功能和便利性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将深入探讨Boost库编程,为读者提供编程技巧和实践经验。我们将从初步了解Boost库开始,介绍其概述和安装指南。接下来,我们将使用Boost库实现基本的字符串操作,并讲解Boost库中智能指针的使用及其应用场景。此外,我们还将深入研究Boost.Asio库,帮助读者基于Boost进行网络编程。同时,我们也会分享Boost库中的多线程编程指南,并展示如何使用Boost库实现高效的文件操作和管理。此外,我们还将涉及日期和时间处理、正则表达式、HTTP和WebSocket、并发数据结构以及XML和JSON解析等方面的内容。我们还会探讨工程单位转换、数据序列化与反序列化、空间几何和地理信息系统等功能。最后,我们将详细讲解如何使用Boost.Test库进行C 单元测试,并分享Boost库中的异常处理与错误信息管理以及性能优化技巧和实践。通过本专栏,读者将全面掌握Boost库的各项功能,并能够灵活运用于实际项目中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【A2开发板深度解析】

# 摘要
A2开发板作为一款功能强大的硬件平台,具有广泛的开发者社区支持和丰富的软件资源。本文对A2开发板进行全面概述,详细介绍了其硬件组成,包括核心处理器的架构和性能参数、存储系统的类型和容量、以及通信接口与外设的细节。同时,本文深入探讨了A2开发板的软件环境,包括支持的操作系统、启动过程、驱动开发与管理、以及高级编程接口与框架。针对A2开发板的应用实践,本文提供了从入门级项目构建到高级项目案例分析的指导,涵盖了硬件连
【段式LCD驱动性能提升】:信号完整性与温度管理策略
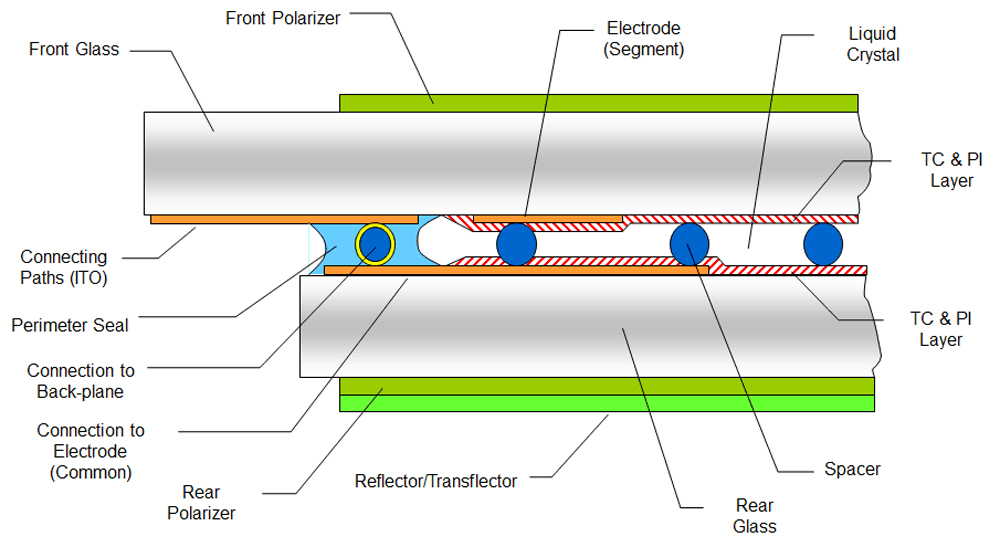
# 摘要
本文综合探讨了段式LCD驱动技术中温度管理和信号完整性的理论与实践。首先,介绍了段式LCD驱动技术的基本概念和信号完整性的理论基础,并探讨了在信号完整性优化中的多种技术,如布线优化与屏蔽。随后,文章重点分析了温度对LCD驱动性能的影响以及有效的温度管理策略,包括热管理系统的设计原则和散热器的设计与材料选择。进一步,结合实际案例,本文展示了如何将信号完整性分析融入温度管理中,以及优化LC
高流量下的航空订票系统负载均衡策略:揭秘流量挑战应对之道

# 摘要
随着航空订票系统用户流量的日益增加,系统面临着严峻的流量挑战。本文详细介绍了负载均衡的基础理论,包括其概念解析、工作原理及其性能指标。在此基础上,探讨了航空订票系统中负载均衡的实践应用,包括硬件和软件负载均衡器的使用、微服务架构下的负载策略。进一步,本文阐述了高流量应对策略与优
【系统性能革命】:10个步骤让你的专家服务平台速度翻倍
# 摘要
随着信息技术的飞速发展,系统性能优化已成为确保软件和硬件系统运行效率的关键课题。本文从系统性能优化的概述入手,详细探讨了性能评估与分析的基础方法,包括性能指标的定义、测量和系统瓶颈的诊断。进一步深入至系统资源使用优化,重点分析了内存、CPU以及存储性能提升的策略。在应用层,本文提出了代码优化、数据库性能调整和网络通信优化的实用方法。
【百兆以太网芯片升级秘籍】:从RTL8201到RPC8201F的无缝转换技巧
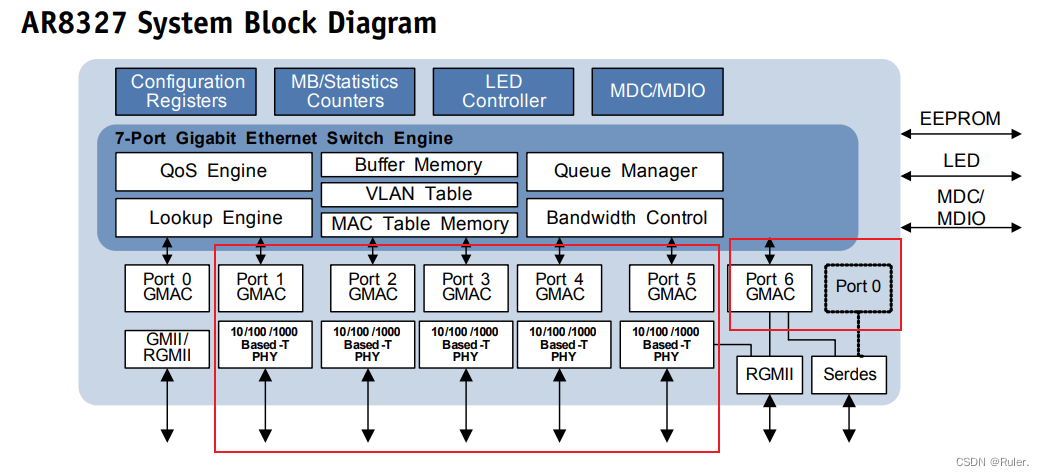
# 摘要
随着网络技术的快速发展,百兆以太网芯片的升级换代显得尤为重要。本文首先概述了百兆以太网芯片升级的背景和必要性。接着,详细解析了RTL8201芯片的技术特性,包括其架构、性能参数、编程接口及应用场景,并分析了RPC8201F芯片的技术升级路径和与RTL8201的对比。本文进一步探讨了百兆以太网芯片从硬件到软件的无缝转换技巧,强调了风险控制的重要性。最后,本文介绍了RPC8
AWR分析慢查询:Oracle数据库性能优化的黄金法则

# 摘要
Oracle数据库性能优化是确保企业级应用稳定运行的关键环节。本文首先概述了性能优化的重要性和复杂性,然后深入探讨了AWR报告在性能诊断中的基础知识点及其核心组件,如SQL报告、等待事件和段统计信息等。第三章详细介绍了如何利用AWR报告来诊断慢查询,并分析了等待事件与系统性
AMEsim在控制系统中的应用:深入解析与实践

# 摘要
AMEsim是一种先进的多领域仿真软件,广泛应用于控制系统的设计、分析和优化。本文旨在介绍AMEsim的基本概念、理论基础以及其在控制系统中的关键作用。文章详细探讨了AMEsim的设计原则、操作界面、建模与仿真工具,并通过案例研究和应用实践展示了其在机电、流体控制等系统中的实际应用。此外,本文还介绍了AMEsim的高级功能、技术支持和社区资源,以及其在仿真技术发展和新兴行业中的应用前景
【CC2530单片机性能飞跃】:系统时钟源的精细调整与性能极限挑战
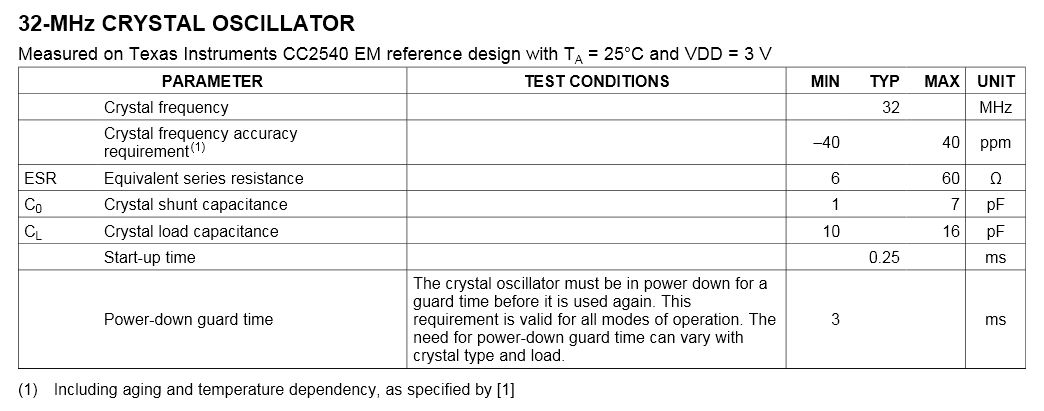
# 摘要
CC2530单片机作为一种广泛应用于低功耗无线网络技术中的微控制器,其性能和时钟源管理对于系统整体表现至关重要。本文首先概述了CC2530的基本应用和系统时钟源的基础理论,包括时钟源的定义、分类以及内外部时钟的对比。进一步深入探讨了CC2530的时钟体系结构和时钟精度与稳定性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )