【数据分析中的Black应用】:掌握代码整洁的艺术
发布时间: 2024-10-06 08:04:59 阅读量: 25 订阅数: 39 

Javalab_BlackJack:JavaLab代码
# 1. 数据分析中的Black应用概述
数据分析领域在近年来获得了巨大发展,而代码质量对于项目成功至关重要。随着项目规模的增长,保持代码整洁和一致性变得越来越具挑战性。因此,代码美化工具应运而生,以帮助开发者维护代码风格和格式。在众多工具中,Black以其独特的优势脱颖而出,它是一款能够自动格式化Python代码的工具,旨在减少因个人编码风格差异导致的不必要争议。
Black所遵循的强制性编码规范,不仅缩短了开发者的编码决策时间,还提高了代码的可读性和一致性。本章将概述Black在数据分析中的应用,以及如何通过它的使用来提高代码质量和工作效率。对于追求高效、清晰代码风格的分析师而言,Black是一个不可或缺的工具。
为了充分利用Black,我们将在接下来的章节深入探讨Black的理论基础、实践操作和进阶技巧。
# 2. Black代码美化工具的理论基础
## 2.1 代码美化工具的演化历程
### 2.1.1 早期的代码格式化工具
在编程语言的早期,代码的格式化和美化更多地依赖于手工操作。开发者需要手动遵守特定的格式规则,例如缩进、换行等,以确保代码的整洁和一致性。随着编程语言的发展,自动化工具开始出现,早期的代码格式化工具如`indent`(用于C语言)和`Artistic Style`(AStyle)提供了基本的代码风格统一功能。
### 2.1.2 代码美化工具的发展趋势
随着时间的推移,代码美化工具变得越来越智能。现代代码美化工具不仅仅是简单的格式化工具,它们可以分析代码结构,理解语言的语义,并在此基础上提供更加精细的格式化选项。例如,`Prettier`和`Black`不仅遵循特定的编码规范,还提供了编辑器集成、命令行使用等便捷方式,极大提高了开发效率。
## 2.2 Black工具的原理和特性
### 2.2.1 Black工具的格式化原理
Black是一款专为Python语言设计的代码美化工具,其格式化原理在于尽可能地简化代码格式化的过程,减少开发者的配置负担。Black通过固定输出格式以避免无谓的风格争议,它遵循PEP 8规范,但并不完全按PEP 8进行格式化,而是选择了一种独特的风格。Black强调一致性和可读性,并且在格式化时不会改变代码的语义。
```python
# 示例代码块,展示Black格式化前后的差异
# Black格式化前
def example_function(var1, var2):
result = var1 + var2
return result
# Black格式化后
def example_function(var1, var2):
result = var1 + var2
return result
```
### 2.2.2 Black的配置和自定义
尽管Black的设计原则是“无需配置”,但仍然提供了一些配置选项供开发者自定义。这些配置选项包括代码的最大行宽、是否在括号内部进行换行等。通过修改`pyproject.toml`文件,开发者可以轻松地设置这些选项,以适应个人或团队的编码风格偏好。
## 2.3 Black与PEP 8标准的关系
### 2.3.1 PEP 8编码规范介绍
PEP 8是Python社区广泛遵循的编码风格指南,它详细规定了Python代码的排版和布局。PEP 8的目标是增加代码的可读性,并帮助开发者编写出更加一致的代码。其内容包括但不限于缩进、空格与制表符的使用、行长度限制、导入语句的顺序等。
### 2.3.2 Black如何实现PEP 8的一致性
Black通过内置的规则集和算法实现了与PEP 8的一致性。虽然在某些情况下Black的选择与PEP 8的建议不同,但Black的目标是产生易于阅读的代码,其结果往往是既遵循PEP 8规范,又提供了一种不同的、可读性极强的格式。例如,Black会将括号内的内容进行换行处理,从而保持每行代码的长度在88个字符以内。
```mermaid
flowchart LR
A[开始格式化]
A --> B[读取代码]
B --> C{是否符合PEP 8?}
C --> |是| D[保持原样]
C --> |否| E[应用Black的规则]
E --> F[输出美化后的代码]
F --> G[结束格式化]
```
通过上述流程图可以看出,Black在格式化过程中不断检测代码是否符合PEP 8规范,对于不符合的部分则应用Black的规则进行调整,从而确保最终输出的代码既符合PEP 8标准,又具有Black特有的风格。
# 3. Black工具的实践操作
## 3.1 Black工具的安装和配置
### 3.1.1 安装Black环境准备
安装Black前,需要确保系统中已经安装了Python环境。Black适用于Python 3.6及以上版本,因此需要有相应版本的Python解释器。在准备安装Black之前,可以使用以下命令检查Python版本:
```bash
python --version # 对于Python 2
python3 --version # 对于Python 3
```
如果系统尚未安装Python,或者版本不兼容,需要先进行安装。大多数操作系统都支持包管理器,例如在Ubuntu上可以使用`apt`,在macOS上可以使用`brew`。
安装好Python后,可以使用`pip`包管理器来安装Black。由于Black是一个命令行工具,因此不需将其安装到项目依赖中,而应该安装为全局可用。可以通过以下命令安装:
```bash
pip install black
```
安装完成后,可以使用以下命令来验证安装是否成功:
```bash
black --version
```
如果看到Black的版本信息,那么安装过程便已完成。
### 3.1.2 Black工具的配置方法
尽管Black工具的默认行为已经很适合大多数场景,但其配置选项可以让用户根据特定需求调整Black的行为。Black的配置可以通过命令行参数或配置文件完成。
命令行参数可以为单次运行Black提供灵活的配置,例如,使用`--line-length`参数可以改变代码中的最大行长度限制。例如:
```bash
black --line-length 88 my_script.py
```
然而,为了在多个项目中统一代码风格,推荐使用配置文件。Black默认会读取项目根目录下的`.pyproject.toml`文件中的配置,如果该文件不存在,则会使用内置的默认配置。配置文件应遵循TOML格式,例如:
```toml
[tool.black]
line-length = 88
target-version = ["py37"]
include = '\.pyi?$'
```
在上面的例子中,我们设置了最大行长度为88,指定了目标Python版本为Python 3.7,并且设置了文件匹配模式,其中包含以.py结尾的文件以及可选的.pyi后缀。
要创建或更新配置文件,Black提供了一个便捷的命令:
```bash
black --config --generate-config
```
这将根据用户的代码风格生成一个配置文件的模板。
## 3.2 Black在数据分析项目中的应用
### 3.2.1 数据分析代码的整理实例
在数据分析项目中,整洁一致的代码风格对于团队协作和代码可读性至关重要。假设有一个简单的数据分析脚本,它可能包含以下内容:
```python
# data_analysis_script.py
import pandas as pd
import numpy
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 Python 库文件 Black 为主题,深入探讨了其代码格式化功能。文章涵盖了 Black 的秘诀、入门指南、团队推广实践、选择理由、大型项目处理技巧、高级配置指南、性能优化策略、工具对比分析、与 pre-commit 集成、内部机制揭秘、扩展性探索、问题解答、数据分析应用、演变历史、CI/CD 应用、代码质量提升步骤、代码美化技巧、教育应用和最新动态。通过阅读本专栏,读者可以全面了解 Black,掌握代码整洁术,提升 Python 代码质量,并了解代码格式化工具的发展历程。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【张量分解:技术革命与实践秘籍】:从入门到精通,掌握机器学习与深度学习的核心算法

# 摘要
张量分解作为数据分析和机器学习领域的一项核心技术,因其在特征提取、预测分类及数据融合等方面的优势而受到广泛关注。本文首先介绍了张量分解的基本概念与理论基础,阐述了其数学原理和优化目标,然后深入探讨了张量分解在机器学习和深度学习中的应用,包括在神经网络、循环神经网络和深度强化学习中的实践案例。进一步,文章探讨了张量分解的高级技术,如张量网络与量
【零基础到专家】:LS-DYNA材料模型定制化完全指南

# 摘要
本论文对LS-DYNA软件中的材料模型进行了全面的探讨,从基础理论到定制化方法,再到实践应用案例分析,以及最后的验证、校准和未来发展趋势。首先介绍了材料模型的理论基础和数学表述,然后阐述了如何根据应用场景选择合适的材料模型,并提供了定制化方法和实例。在实践应用章节中,分析了材料模型在车辆碰撞、高速冲击等工程问题中的应用,并探讨了如何利用材料模型进行材料选择和产品设计。最后,本论文强调了材料模型验证和校准的重要
IPMI标准V2.0实践攻略:如何快速搭建和优化个人IPMI环境
# 摘要
本文系统地介绍了IPMI标准V2.0的基础知识、个人环境搭建、功能实现、优化策略以及高级应用。首先概述了IPMI标准V2.0的核心组件及其理论基础,然后详细阐述了搭建个人IPMI环境的步骤,包括硬件要求、软件工具准备、网络配置与安全设置。在实践环节,本文通过详尽的步骤指导如何进行环境搭建,并对硬件监控、远程控制等关键功能进行了验证和测试,同时提供了解决常见问题的方案。此外,本文
SV630P伺服系统在自动化应用中的秘密武器:一步精通调试、故障排除与集成优化

# 摘要
本文全面介绍了SV630P伺服系统的工作原理、调试技巧、故障排除以及集成优化策略。首先概述了伺服系统的组成和基本原理,接着详细探讨了调试前的准备、调试过程和故障诊断方法,强调了参数设置、实时监控和故障分析的重要性。文中还提供了针对常见故障的识别、分析和排除步骤,并分享了真实案例的分析。此外,文章重点讨论了在工业自动化和高精度定位应用中
从二进制到汇编语言:指令集架构的魅力
# 摘要
本文全面探讨了计算机体系结构中的二进制基础、指令集架构、汇编语言基础以及高级编程技巧。首先,介绍了指令集架构的重要性、类型和组成部分,并且对RISC和CISC架
深入解读HOLLiAS MACS-K硬件手册:专家指南解锁系统性能优化
# 摘要
本文首先对HOLLiAS MACS-K硬件系统进行了全面的概览,然后深入解析了其系统架构,重点关注了硬件设计、系统扩展性、安全性能考量。接下来,探讨了性能优化的理论基础,并详细介绍了实践中的性能调优技巧。通过案例分析,展示了系统性能优化的实际应用和效果,以及在优化过程中遇到的挑战和解决方案。最后,展望了HOLLiAS MACS-K未来的发展趋势
数字音频接口对决:I2S vs TDM技术分析与选型指南
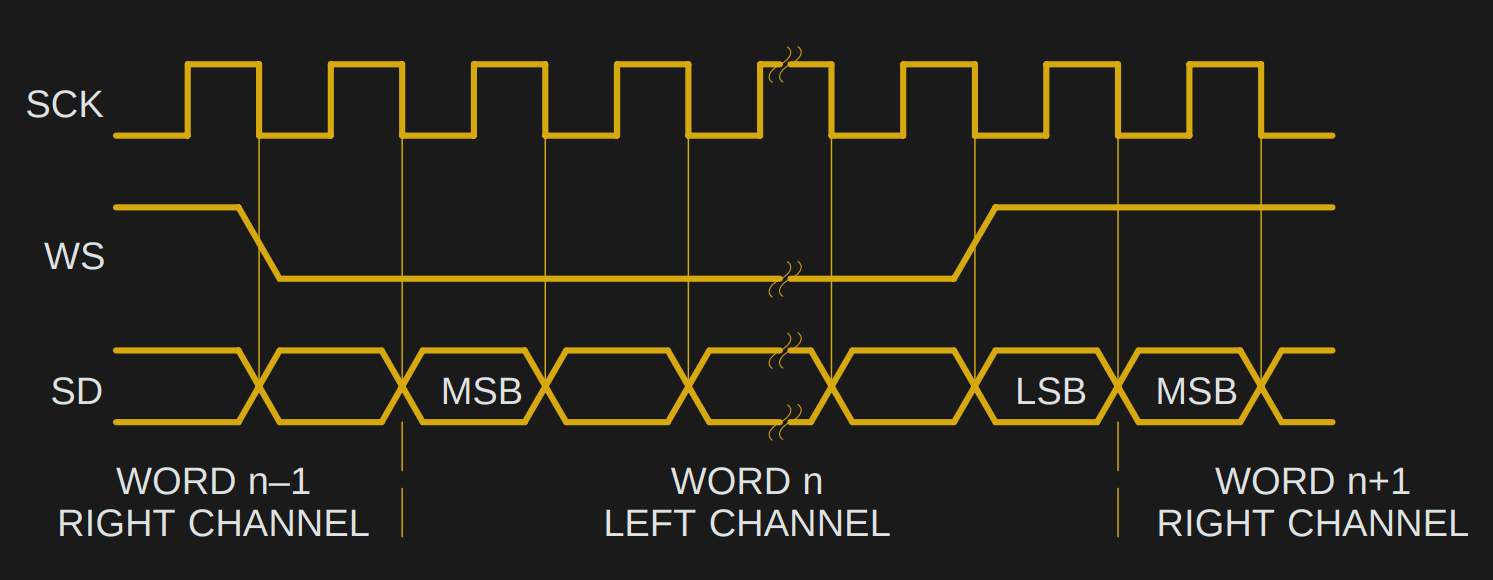
# 摘要
数字音频接口作为连接音频设备的核心技术,对于确保音频数据高质量、高效率传输至关重要。本文从基础概念出发,对I2S和TDM这两种广泛应用于数字音频系统的技术进行了深入解析,并对其工作原理、数据格式、同步机制和应用场景进行了详细探讨。通过对I2S与TDM的对比分析,本文还评估了它们在信号质量、系统复杂度、成本和应用兼容性方面的表现。文章最后提出了数字音频接口的选型指南,并展望了未来技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )