Redis单机与集群部署及配置
发布时间: 2024-01-11 21:37:50 阅读量: 51 订阅数: 47 

dnSpy-net-win32-222.zip
# 1. Redis概述与部署
## 1.1 Redis简介
Redis(Remote Dictionary Server)是一个开源的内存数据库,通过提供高速的键值存储、数据结构、发布/订阅,以及持久化的功能,被广泛应用于缓存、队列、实时分析等场景。其特点包括快速、支持丰富的数据结构、持久化、高可用、分布式等。在实际应用中,Redis常用作关键数据的缓存,以提升系统的性能和扩展性。
## 1.2 Redis单机部署
Redis的单机部署是最简单的部署方式,适用于小规模应用场景。通过在单个服务器上安装和运行Redis,可以快速实现数据存储和访问的功能。
## 1.3 Redis集群部署
当数据量逐渐增大或者面临高并发请求时,单机部署可能无法满足需求,这时就需要考虑使用Redis集群部署来实现高可用和横向扩展。Redis集群可以将数据分布在多个节点上,提供更高的性能和容错能力。接下来,我们将详细介绍Redis单机部署和集群部署的配置与优化。
# 2. 单机部署配置
### 2.1 安装Redis
在进行单机部署配置之前,首先需要安装Redis。
Redis的安装可以通过源码编译安装或者使用现成的二进制安装包。以下是使用二进制安装包进行安装的示例:
```bash
$ wget http://download.redis.io/releases/redis-x.x.x.tar.gz
$ tar xzf redis-x.x.x.tar.gz
$ cd redis-x.x.x
$ make
```
### 2.2 配置Redis
安装完成后,接下来需要进行Redis的配置。
Redis的配置文件位于Redis安装目录下的redis.conf文件中。可以使用文本编辑器打开该文件进行配置。
以下是一些常见的配置项及其说明:
- `bind`: 指定监听地址,默认为127.0.0.1,表示只能本地访问。如果需要远程访问,可以设置为0.0.0.0。
- `port`: 指定监听的端口,默认为6379。
- `daemonize`: 是否以守护进程方式运行,默认为no,如果需要以守护进程方式运行,可以设置为yes。
- `logfile`: 指定日志文件路径。
- `dbfilename`: 指定持久化文件名称,默认为dump.rdb。
- `dir`: 指定持久化文件和日志文件的保存目录。
配置完成后,保存文件并退出。
### 2.3 启动与优化Redis
配置完成后,即可启动Redis服务器。
```bash
$ redis-server /path/to/redis.conf
```
启动后,可以使用以下命令检查Redis服务器是否正常运行:
```bash
$ redis-cli ping
```
如果返回结果为`PONG`,则表示服务器正常运行。
根据具体的使用场景和需求,可以对Redis进行优化。以下是一些常见的优化方法:
- 指定最大内存限制:可以通过配置`maxmemory`项来指定Redis的最大内存限制,当内存使用达到限制时,可以根据缓存策略进行数据替换或清理。
- 使用持久化机制:可以选择使用RDB持久化或AOF持久化来保证数据的持久化存储,以防止数据丢失。
- 合理配置缓存策略:根据数据的访问频率和重要性,可以选择适合的缓存策略,如LRU、LFU等。
通过合理配置和优化,可以提升Redis的性能和稳定性。
本章介绍了Redis的单机部署方式以及相应的配置和优化方法。通过正确的配置和优化,可以确保Redis服务器的正常运行,并满足不同场景下的需求。下一章将介绍Redis的集群部署配置。
# 3. 集群部署配置
#### 3.1 集群架构选择
在进行Redis集群部署前,首先需要选择适合的集群架构。常见的Redis集群架构包括主从复制、哨兵模式和集群模式。主从复制适合于读多写少的场景,哨兵模式适合高可用场景,而集群模式则适合大规模的数据存储和高并发访问。
#### 3.2 集群节点规划
在部署Redis集群时,需要合理规划集群节点,包括主节点和从节点的数量,以及它们的分布。通常情况下,建议设置至少3个主节点和相应的从节点,以确保集群的高可用性和性能。
#### 3.3 集群配置与搭建
在选择了集群架构并规划好节点之后,接下来需要进行集群的配置与搭建。这包括配置每个Redis节点的主从关系、槽分配以及集群的初始化。在配置完成后,还需要进行集群的启动和验证,确保集群可以正常工作。
以上是Redis集群部署配置的基本内容,接下来我们将详细介绍每个步骤的具体操作和注意事项。
# 4. 性能优化与调整
#### 4.1 内存管理
在使用Redis时,合理地管理内存是非常重要的,因为Redis的性能直接受到内存的限制。下面是一些内存管理的技巧和优化方法:
- 设置最大使用内存: 可以通过在Redis配置文件中设置`maxmemory`参数来限制Redis使用的最大内存量。当内存使用达到设定的最大值时,可以根据配置的策略来处理数据(如淘汰旧数据或禁止写入等)。
- 开启内存淘汰策略: 当内存已满,无法容纳新数据时,Redis会根据配置的淘汰策略来删除一定量的旧数据。常用的淘汰策略有:`noeviction`(禁止写入)、`allkeys-lru`(最近最少使用算法)、`volatile-lru`(只对设置了过期时间的数据进行最近最少使用算法)等。
- 使用Redis数据结构: Redis提供了多种数据结构,如字符串、哈希、列表、集合和有序集合,根据业务需求选择合适的数据结构可以提高性能。例如,使用哈希数据结构可以有效地存储和检索键值对。
#### 4.2 持久化配置
为了确保数据持久化,防止数据丢失,可以通过配置Redis的持久化方式。Redis支持两种持久化方式:
- RDB持久化: 将Redis在内存中的数据周期性地写入磁盘,生成一个快照文件(`.rdb`文件)。可以通过在Redis配置文件中设置`save`参数来定义触发快照保存的条件和频率。
- AOF持久化: 将Redis的操作日志以追加的方式写入磁盘,记录每个写操作的指令,当Redis重启时,可以通过重新执行指令来恢复数据。可以通过在Redis配置文件中设置`appendonly`参数来开启AOF持久化。
#### 4.3 缓存策略选择
在使用Redis作为缓存的场景中,选择合适的缓存策略对性能有很大的影响。以下是常见的缓存策略:
- 缓存穿透:当访问缓存中不存在的数据时,会导致大量对数据库的无效查询,产生缓存穿透问题。解决方法包括设置空缓存、布隆过滤器等。
- 缓存雪崩:当缓存中的大量数据同时失效,导致所有请求都直接访问数据库,产生缓存雪崩问题。解决方法包括设置合理的过期时间、加锁更新等。
- 缓存击穿:当某个热点key失效导致大量请求同时访问数据库,产生缓存击穿问题。解决方法包括设置热点数据不过期、互斥锁等。
需要根据具体场景选择合适的缓存策略,并对缓存进行监控和调优,以提高性能和稳定性。
以上是针对Redis性能优化与调整的一些常见方法和策略,这些方法可以根据实际需求进行具体配置和调整,以达到更好的性能和稳定性。
# 5. 高可用与故障恢复
在Redis的集群部署中,高可用性是一个非常重要的考虑因素。本章将介绍如何配置Redis实现高可用性,并介绍常见的故障恢复方法。
### 5.1 高可用配置
在Redis集群中实现高可用性,可以采用主从复制的方式。主从复制是指将一个Redis实例作为主节点(master),而其他Redis实例作为其从节点(slave)。主节点负责写操作,而从节点负责读操作。
在进行主从复制前,首先需要在Redis配置文件中进行一些基本的配置。具体配置如下:
```ini
# 在从节点配置文件中,添加如下配置
slaveof <master-ip> <master-port>
# 在主节点配置文件中,添加如下配置
masterauth <master-password>
```
配置完成后,重启Redis服务,从节点将会自动连接到主节点,并进行数据同步。此时,如果主节点发生故障,可以手动将一个从节点提升为主节点,以确保服务的可用性。
### 5.2 主从复制
主从复制是一种常见的实现高可用性的方法,主要有以下几个步骤:
1. 在主节点的配置文件中设置密码,并启用主从复制功能。
```ini
requirepass <password>
masterauth <password>
slaveof <master-ip> <master-port>
```
2. 在从节点的配置文件中设置密码,并指定主节点的地址。
```ini
requirepass <password>
slaveof <master-ip> <master-port>
```
3. 重启主节点和从节点的Redis服务。
4. 在从节点上执行SYNC命令,进行数据同步。
```shell
$ redis-cli -h <slave-ip> -p <slave-port>
> AUTH <password>
> SYNC
```
5. 完成主从复制后,从节点将会自动进行数据同步,并成为主节点的备份。
### 5.3 故障切换与恢复
当主节点发生故障时,需要手动进行故障切换,将一个从节点提升为新的主节点。故障切换的步骤如下:
1. 确定主节点的故障,通过监控系统或手动检测进行判断。
2. 登录到从节点上,执行以下命令提升节点为主节点。
```shell
$ redis-cli -h <slave-ip> -p <slave-port>
> SLAVEOF NO ONE
```
3. 更新应用程序的配置文件,将原来连接的主节点地址改为新的主节点地址。
4. 重新启动应用程序和Redis服务,故障切换完成。
故障切换完成后,新的主节点将继续提供写操作,并重新配置从节点。
## 总结
本章介绍了如何配置Redis集群实现高可用性,并介绍了主从复制的原理和步骤。通过主从复制,可以确保当主节点发生故障时,能够快速切换到新的主节点,以提高系统的稳定性和可用性。同时,需要注意定期进行监控和备份,以便及时发现并恢复故障。
# 6. 安全配置与监控
在Redis的部署与配置中,安全性和监控是至关重要的方面。本章将重点介绍如何进行安全配置以及监控Redis实例的方法。
#### 6.1 访问控制与安全设置
在实际应用中,为了保护Redis服务器不受未经授权的访问,我们需要进行一些安全设置和访问控制。
##### 场景:使用密码认证进行访问控制
```python
# Python示例代码
import redis
# 连接Redis服务器
r = redis.StrictRedis(host='localhost', port=6379, password='your_password')
# 执行一些操作
r.set('key', 'value')
print(r.get('key'))
```
##### 代码总结
在连接Redis服务器时,通过设置密码参数即可进行访问控制。
##### 结果说明
通过设置密码,只有知道密码的客户端才能成功连接和操作Redis。
#### 6.2 监控与日志配置
在生产环境中,合理设置监控和日志记录对于排查问题和性能优化至关重要。下面我们将讨论如何配置监控和日志记录。
##### 场景:使用Redis官方提供的监控工具Redis-Stat进行实时监控
```java
// Java示例代码
// 使用Jedis连接Redis服务器
Jedis jedis = new Jedis("localhost", 6379);
// 打印Redis服务器的一些信息
System.out.println("Redis 服务器信息: " + jedis.info("server"));
System.out.println("Redis 客户端信息: " + jedis.info("clients"));
```
##### 代码总结
通过使用Jedis客户端的info方法,可以获取Redis服务器的各项信息,进行监控和分析。
##### 结果说明
通过实时监控Redis服务器,可以及时发现潜在问题并进行调整和优化。
以上就是关于安全配置与监控的基本介绍,希望能够帮助读者更好地理解和实践Redis的安全设置和监控方法。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏《Redis高可用分布式锁精讲》全面解析了Redis的高可用性及分布式锁的使用方法。专栏内容包括Redis的介绍及基本概念、数据结构及应用场景、单机与集群部署与配置、持久化技术、读写性能优化技巧、主从复制原理与配置、哨兵模式与高可用性、Cluster集群模式的详解等。此外,还讲解了分布式锁的多种实现方法并进行对比,以及基于Redis的分布式高可用锁的设计。同时,专栏还探讨了Redis分布式锁可能遭遇的问题及相应的解决方案。除了讲解Redis的高级特性外,专栏还涉及到Redis在实时消息推送、缓存穿透与雪崩、分布式动态配置、秒杀系统、数据库一致性、消息队列集成与优化、分布式会话管理等方面的应用。通过该专栏的学习,读者将全面了解Redis的高可靠性、分布式锁的使用方式,并掌握Redis在不同场景中的应用技巧,为实际工作中的分布式系统设计和开发提供有效的指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
算法到硬件的无缝转换:实现4除4加减交替法逻辑的实战指南
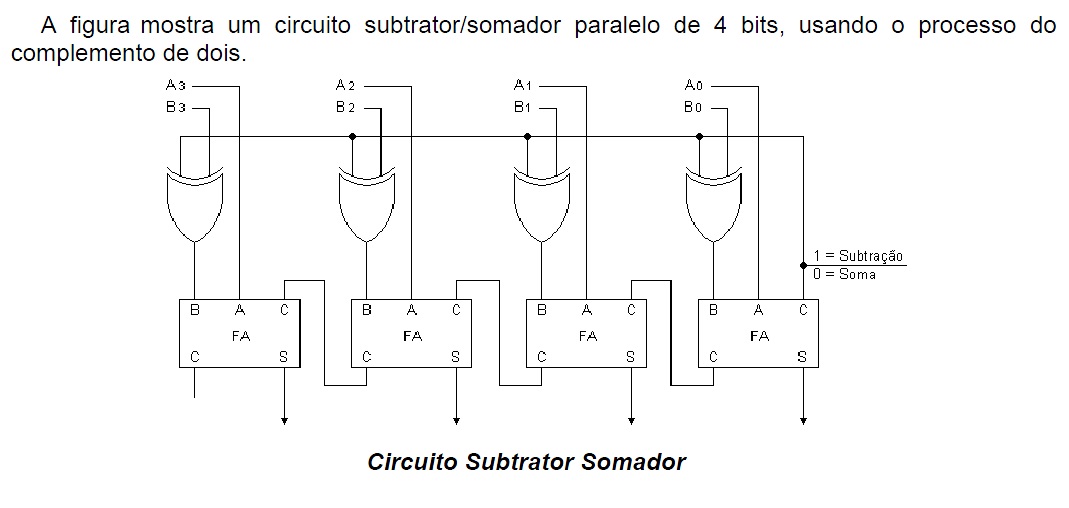
# 摘要
本文旨在介绍一种新颖的4除4加减交替法,探讨了其基本概念、原理及算法设计,并分析了其理论基础、硬件实现和仿真设计。文章详细阐述了算法的逻辑结构、效率评估与优化策略,并通过硬件描述语言(HDL)实现了算法的硬件设计与仿真测试。此外,本文还探讨了硬件实现与集成的过程,包括FPGA的开发流程、逻辑综合与布局布线,以及实际硬件测试。最后,文章对算法优化与性能调优进行了深入分析,并通过实际案例研究,展望了算法与硬件技术未来的发
【升级攻略】:Oracle 11gR2客户端从32位迁移到64位,完全指南

# 摘要
随着信息技术的快速发展,企业对于数据库系统的高效迁移与优化要求越来越高。本文详细介绍了Oracle 11gR2客户端从旧系统向新环境迁移的全过程,包括迁移前的准备工作、安装与配置步骤、兼容性问题处理以及迁移后的优化与维护。通过对系统兼容性评估、数据备份恢复策略、环境变量设置、安装过程中的问题解决、网络
【数据可视化】:煤炭价格历史数据图表的秘密揭示

# 摘要
数据可视化是将复杂数据以图形化形式展现,便于分析和理解的一种技术。本文首先探讨数据可视化的理论基础,再聚焦于煤炭价格数据的可视化实践,
FSIM优化策略:精确与效率的双重奏

# 摘要
本文详细探讨了FSIM(Feature Similarity Index Method)优化策略,旨在提高图像质量评估的准确度和效率。首先,对FSIM算法的基本原理和理论基础进行了分析,然后针对算法的关键参数和局限性进行了详细讨论。在此基础上,提出了一系列提高FSIM算法精确度的改进方法,并通过案例分析评估
IP5306 I2C异步消息处理:应对挑战与策略全解析

# 摘要
本文系统介绍了I2C协议的基础知识和异步消息处理机制,重点分析了IP5306芯片特性及其在I2C接口下的应用。通过对IP5306芯片的技术规格、I2C通信原理及异步消息处理的特点与优势的深入探讨,本文揭示了在硬件设计和软件层面优化异步消息处理的实践策略,并提出了实时性问题、错误处理以及资源竞争等挑战的解决方案。最后,文章
DBF到Oracle迁移高级技巧:提升转换效率的关键策略

# 摘要
本文探讨了从DBF到Oracle数据库的迁移过程中的基础理论和面临的挑战。文章首先详细介绍了迁移前期的准备工作,包括对DBF数据库结构的分析、Oracle目标架构的设计,以及选择适当的迁移工具和策略规划。接着,文章深入讨论了迁移过程中的关键技术和策略,如数据转换和清洗、高效数据迁移的实现方法、以及索引和约束的迁移。在迁移完成后,文章强调了数据验证与性能调优的重要性,并通过案例分析,分享了不同行业数据迁移的经
【VC709原理图解读】:时钟管理与分布策略的终极指南(硬件设计必备)
# 摘要
本文详细介绍了VC709硬件的特性及其在时钟管理方面的应用。首先对VC709硬件进行了概述,接着探讨了时钟信号的来源、路径以及时钟树的设计原则。进一步,文章深入分析了时钟分布网络的设计、时钟抖动和偏斜的控制方法,以及时钟管理芯片的应用。实战应用案例部分提供了针对硬件设计和故障诊断的实际策略,强调了性能优化
IEC 60068-2-31标准应用:新产品的开发与耐久性设计
# 摘要
IEC 60068-2-31标准是指导电子产品环境应力筛选的国际规范,本文对其概述和重要性进行了详细讨论,并深入解析了标准的理论框架。文章探讨了环境应力筛选的不同分类和应用,以及耐久性设计的实践方法,强调了理论与实践相结合的重要性。同时,本文还介绍了新产品的开发流程,重点在于质量控制和环境适应性设计。通过对标准应用案例的研究,分析了不同行业如何应用环境应力筛选和耐久性设计,以及当前面临的新技术挑战和未来趋势。本文为相关领域的工程实践和标准应用提供了有价值的参考。
# 关键字
IEC 60068-2-31标准;环境应力筛选;耐久性设计;环境适应性;质量控制;案例研究
参考资源链接:
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )