【Acrobat PDF转换终极指南】:20个专业技巧解决Office文件转换难题
发布时间: 2024-12-14 11:32:48 阅读量: 6 订阅数: 6 

pdf转换为office文档工具

参考资源链接:[解决acrobat不支持docx、doc文件转换为PDF的问题](https://wenku.csdn.net/doc/6401acebcce7214c316ed9f3?spm=1055.2635.3001.10343)
# 1. PDF转换的基础知识
在数字化时代的今天,电子文档已经成为我们日常工作和生活中不可或缺的一部分。PDF(便携式文档格式)因其跨平台兼容性和不易被编辑的特点,成为了最流行的文档格式之一。然而,在实际应用中,我们常常需要将PDF转换为其他格式以适应不同的场景,例如将PDF转换为Word、Excel或PPT等。这个转换过程涉及了一系列的技术细节,包括解析PDF文件结构、处理文本和图形元素、以及确保转换后文档的完整性和可用性。本章将带领读者走进PDF转换的世界,了解其基本概念、转换的必要性和所涉及的关键技术。无论你是需要偶尔转换文档的普通用户,还是需要处理大量文件的专业人士,本章内容将为你提供必要的背景知识,帮助你更高效地完成文档处理任务。
# 2. 选择合适的PDF转换工具
在当今数字化的办公环境中,PDF已经成为数据共享的通用格式。选择合适的PDF转换工具,可以确保数据的准确性和高效性。本章深入探讨市场上各类PDF转换解决方案,并对它们的功能进行比较分析。
## 2.1 市场上的PDF转换解决方案
不同的工作场景和需求决定了用户对PDF转换工具的不同选择。目前市场上,PDF转换器的解决方案主要分为两大类:免费PDF转换器和付费PDF转换服务。
### 2.1.1 免费PDF转换器
免费PDF转换器在市场上数量众多,它们通常具备基础的转换功能,并且易于获取和使用。免费转换器的优点是成本低,适合偶尔或基本的PDF转换需求。
- **优点**:
- 不需要支付额外费用。
- 界面通常简洁明了,操作简单。
- **缺点**:
- 功能可能受限,不支持一些高级格式或特性。
- 无法保证转换质量,可能在转换过程中出现数据丢失或格式错乱。
- 广告可能较多,影响使用体验。
- 用户隐私和安全性难以得到保证。
### 2.1.2 付费PDF转换服务
付费PDF转换服务通常提供更为全面和专业的功能。用户需要为服务支付一定费用,但能得到更稳定和高质量的转换体验。
- **优点**:
- 通常具备更高的转换质量和速度。
- 支持广泛的文件格式,包括一些专业和特殊格式。
- 提供额外的高级功能,如批量转换、自动化处理等。
- 用户界面友好,提供更佳的使用体验。
- **缺点**:
- 需要支付使用费用,长期使用成本较高。
- 某些服务可能对文件大小或转换次数有限制。
## 2.2 PDF转换器的功能比较
选择合适的PDF转换工具不仅仅基于价格,更重要的是考虑工具的功能是否满足具体的工作需求。这里我们将对一些常见的功能进行比较分析。
### 2.2.1 转换质量和速度
转换质量和速度是用户在选择PDF转换器时最关心的两个方面。高质量的PDF转换意味着转换后的文件能够完整保留原有的排版、字体和图像等元素。
- **转换质量**:
- 取决于转换算法的先进性和优化程度。
- 可以通过对比原始文件和转换后文件的相似度来评估。
- **转换速度**:
- 转换速度受多种因素影响,如文件大小、转换器的性能等。
- 一些工具通过优化代码和使用更强大的服务器来提升转换速度。
### 2.2.2 兼容性和格式支持
兼容性和格式支持是评估PDF转换器是否能应对各种不同需求的重要指标。
- **兼容性**:
- 指转换后的PDF文件在不同操作系统、设备上的表现。
- 良好的兼容性意味着PDF文件可以在任何设备上无障碍打开和使用。
- **格式支持**:
- 指转换器支持转换的文件格式种类。
- 广泛的格式支持可以让用户从多种源文件轻松转换到PDF。
### 2.2.3 用户界面和易用性
用户界面和易用性对于提升用户体验至关重要。
- **用户界面**:
- 界面设计的直观性,是否让用户能够快速找到需要的功能。
- 界面是否美观,是否能提供愉悦的使用感受。
- **易用性**:
- 工具是否提供明确的操作指南或帮助文档。
- 是否能够快速上手,对于非技术用户是否友好。
为了方便读者对上述内容的理解,以下是三种常见的PDF转换工具的比较表格:
| 功能/工具 | Adobe Acrobat | Smallpdf | PDF2DOC |
|----------------|---------------|-----------|---------|
| 转换质量 | 高 | 中 | 中 |
| 转换速度 | 中 | 高 | 中 |
| 兼容性 | 高 | 中 | 中 |
| 格式支持 | 广泛 | 有限 | 有限 |
| 用户界面 | 专业且复杂 | 简洁直观 | 简洁直观|
| 易用性 | 需要学习曲线 | 易于上手 | 易于上手|
通过上述分析,读者可以针对自己的具体需求进行选择。在选择PDF转换工具时,不应仅关注其单一功能,更应从整体上考虑其性能、支持的格式、易用性和安全性等因素。
# 3. PDF转换的实践技巧
在本章中,我们将深入探讨将不同类型的文件如Word、Excel和PPT转换为PDF时所应采取的实践技巧,以及如何调整转换参数以优化最终文档的呈现效果。我们将从文件结构的优化开始,到批量转换和自动化技巧,一步步引领你掌握PDF转换的实际操作技巧。
## 3.1 从Word到PDF的转换
Word文档是最常见的文档类型之一,而将其转换为PDF格式在学术、商业等领域都极为普遍。以下是如何进行高效Word到PDF转换,并优化最终文档结构和设置的详细步骤。
### 3.1.1 优化Word文档结构
在转换前,对Word文档进行适当的结构优化,可以显著提升转换后的PDF质量。以下是一些关键步骤:
1. **标题和子标题的层次性**:确保文档使用了清晰的标题层次结构,这有助于在PDF中生成有效的导航大纲。
2. **样式和格式的一致性**:利用Word的样式功能统一文档格式,包括字体大小、颜色等,这将直接转化为PDF中的视觉效果。
3. **图片和图形的优化**:在插入图片或图形前,先进行适当的优化,比如调整分辨率和压缩,避免在转换时丢失图像质量。
4. **链接和引用的校验**:Word文档中的链接和引用在转换为PDF时需要特别注意,确保所有链接在PDF中都能正确打开,引用准确无误。
### 3.1.2 转换参数的调整和设置
Word到PDF的转换过程中,不同的转换参数设置会导致不同的输出结果。以下是如何根据需要调整转换参数的指南:
1. **页面布局和尺寸**:根据最终需求选择合适的页面布局和尺寸。例如,如果你需要将PDF用于打印,可能需要选择A4纸张大小。
2. **打印选项**:在Word中选择“打印”选项时,选择合适的打印机,通常是Adobe PDF或Microsoft Print to PDF,它们能够提供更高质量的PDF输出。
3. **高级设置**:利用“导出”选项中的高级设置,可以对输出的PDF进行进一步的定制,包括图像压缩、字体嵌入等。
```markdown
例1:导出Word文档为PDF时选择“最小文件大小”选项,这将优化文件大小。
例2:选择“最佳质量”选项,确保图像和文字在PDF中显示清晰。
```
## 3.2 从Excel到PDF的转换
将Excel数据导出为PDF是数据分析和报告中常见的需求。这一节将指导你如何在转换过程中保留公式和格式,并利用批量转换和自动化技巧来提高工作效率。
### 3.2.1 转换时保留公式和格式
在转换Excel表格到PDF时,确保重要公式和格式不丢失是关键:
1. **使用名称范围**:在Excel中使用命名范围来引用复杂的公式,这有助于在转换后的PDF中更好地识别和引用数据。
2. **颜色和格式的统一**:确保数据格式一致,包括字体颜色和单元格格式,以保证在PDF中的视觉效果。
3. **隐藏不必要的行或列**:在转换前,隐藏不必要的行或列,确保只有需要展示的数据出现在PDF中。
### 3.2.2 批量转换和自动化技巧
在处理大量数据时,批量转换和自动化技巧可以极大提升工作效率:
1. **使用PowerShell脚本**:对于IT专家来说,可以使用PowerShell脚本自动化整个转换过程,实现从输入源Excel文件到输出PDF的一系列操作。
2. **设置宏**:在Excel中设置宏记录器,可以自动记录转换过程中的各种操作,之后将这些操作应用于多个文件以进行批量转换。
```powershell
例1:PowerShell脚本转换单个Excel文件为PDF
$Excel = New-Object -ComObject Excel.Application
$Excel.Visible = $false
$Workbook = $Excel.Workbooks.Open("C:\path\to\your\file.xlsx")
$Workbook.ExportAsFixedFormat(0, "C:\path\to\output.pdf")
$Workbook.Close($false)
$Excel.Quit()
```
## 3.3 从PPT到PDF的转换
演示文稿的PDF转换是将PPT分享给没有相应演示软件的观众时的常见做法。本节将介绍如何优化演示文稿的视觉效果,并应用高级转换选项以达到最佳的展示效果。
### 3.3.1 优化演示文稿的视觉效果
在转换前,优化PPT演示文稿的视觉效果,可以确保最终的PDF文件具有专业外观:
1. **统一幻灯片模板**:使用统一的幻灯片模板,确保从头到尾的连贯性,并在转换后保持视觉一致性。
2. **图形和图表清晰**:在PPT中使用的图形和图表需要清晰可辨,避免因转换为PDF后而变得模糊不清。
3. **动画和过渡效果**:虽然PDF不支持动画和过渡,但预先决定幻灯片切换是否手动可以帮助控制PDF的阅读流程。
### 3.3.2 高级转换选项的应用
PPT到PDF的转换提供了各种高级选项,这些选项可以根据具体需要进行定制:
1. **选择输出范围**:可以选择输出特定的幻灯片或整个演示文稿,这有助于控制PDF文件的大小。
2. **注释和标记的保留**:在转换时选择保留演讲者的注释和标记,这在分享演示文稿时可以提供额外的信息。
3. **高质量图形的输出**:如果PDF将用于高质量打印,那么需要在转换设置中选择高分辨率图形输出选项。
```markdown
例1:使用PowerPoint软件的"导出"功能选择特定的幻灯片进行转换。
例2:在"导出"设置中,选择高分辨率图形输出选项来提高PDF的图像质量。
```
在本章中,我们详细介绍了针对Word、Excel和PPT等不同类型文件转换为PDF时应采取的实践技巧。通过结构优化、转换参数的细致设置、批量转换和自动化处理,你将能够更高效地完成转换任务,并确保输出的PDF文件质量达到最佳。在下一章中,我们将探讨解决PDF转换过程中遇到的常见问题,并提供相应的处理策略。
# 4. 解决PDF转换过程中的常见问题
在将文档转换为PDF格式的过程中,用户经常会遇到各种各样的问题,特别是对于那些需要高度精确的转换。了解这些问题,并找到有效的解决方法是实现高质量PDF转换的关键。
## 4.1 图像和图形在转换中的质量损失
### 4.1.1 调整分辨率和压缩设置
在进行PDF转换时,图像和图形的分辨率对于输出质量至关重要。高分辨率的图像会生成高质量的PDF,但同时也会增加文件大小。因此,需要找到合适的平衡点。
```markdown
在Adobe Acrobat中进行图像质量设置的步骤:
1. 打开要转换的文档。
2. 点击“文件”菜单,选择“导出PDF”。
3. 在导出设置中,选择“图像”选项卡。
4. 选择适当的“分辨率”,如高分辨率(至少300dpi)。
5. 根据需要调整“压缩”选项来减小文件大小。
6. 点击“导出”并保存转换后的PDF文件。
```
### 4.1.2 使用矢量图形的优势
与位图图像不同,矢量图形不依赖于分辨率,并且在放大或缩小时不会失去质量。为了减少在PDF转换中可能出现的质量损失,可以使用矢量图形。
```markdown
在Adobe Illustrator中使用矢量图形的步骤:
1. 打开Illustrator并加载需要转换为PDF的矢量图形文件。
2. 点击“文件”菜单,然后选择“另存为”或“导出”。
3. 选择PDF格式并点击“保存”。
4. 在导出设置中,确保输出选项保留了矢量信息。
5. 导出PDF文件并确认图形质量无损。
```
## 4.2 字体和排版问题的处理
### 4.2.1 字体嵌入和替代策略
确保PDF文件中的字体正确显示对于维护文档的可读性和专业性至关重要。如果源文档中的字体在目标计算机上不存在,可以选择嵌入字体或使用替代字体。
```markdown
在Microsoft Word中嵌入字体的步骤:
1. 打开Word文档。
2. 点击“文件”菜单,选择“选项”。
3. 在“Word选项”窗口中选择“高级”,然后向下滚动到“显示文档内容”部分。
4. 点击“字体嵌入”旁边的“选项”按钮。
5. 勾选“将字体嵌入文件”复选框,并选择“嵌入所有字符”。
6. 点击“确定”并保存文档。
```
### 4.2.2 文档流式布局的调整
PDF格式支持流式布局,这意味着文档可以在不同大小的屏幕上保持一致的显示效果。调整布局以适应不同的显示需求可以提升用户体验。
```markdown
在Adobe InDesign中调整流式布局的步骤:
1. 打开InDesign文档。
2. 选择“文件”菜单中的“导出”选项。
3. 在导出对话框中,选择“Adobe PDF (印刷)”并点击“保存”。
4. 在导出PDF对话框中选择“高级”。
5. 在“标记和出血”选项中,设置适当的出血。
6. 在“页面和跨页设置”中,选择适合你的文档的页面尺寸。
7. 点击“导出”并确认布局调整。
```
## 4.3 批量转换和自动化处理
### 4.3.1 使用脚本和批处理文件
对于拥有大量需要转换的文件,手动转换效率极低。可以使用脚本或批处理文件自动化整个过程。
```markdown
一个简单的Windows批处理脚本用于批量转换文件:
```
```batch
@echo off
cd C:\path\to\source\files
for %%f in (*.doc) do (
"C:\Program Files\Adobe\Acrobat DC\Acrobat\Acrobat.exe" /t "C:\Program Files\Adobe\Acrobat DC\Acrobat\Acrobat.exe" "%%f" "%%f.pdf"
)
```
### 4.3.2 利用API进行高效转换
许多PDF转换服务提供API,允许开发者集成转换功能到自己的应用程序中。这可以大幅度提升转换过程的效率和可靠性。
```markdown
一个使用PDF转换API的基本示例:
```
```python
import requests
def convert_pdf(input_file, output_file):
url = 'https://api.pdfconvert.com/convert'
files = {'file': open(input_file, 'rb')}
data = {'output_format': 'pdf'}
response = requests.post(url, files=files, data=data)
if response.status_code == 200:
with open(output_file, 'wb') as f:
f.write(response.content)
print(f"文件已成功转换并保存为 {output_file}")
else:
print("转换失败")
convert_pdf('example.docx', 'example.pdf')
```
通过这些方法,可以确保PDF转换过程中的问题得到及时和有效的解决,最终获得高质量的PDF输出文件。
# 5. 高级PDF转换技术
在第五章中,我们将深入探讨高级PDF转换技术,这不仅仅是为了完成文件格式之间的转换,而是为了满足更具体的专业需求。我们将探索PDF/A和PDF/X标准,PDF的安全性管理和权限设置,以及OCR技术在PDF转换中的关键应用。
## 5.1 PDF/A和PDF/X标准的转换
### 5.1.1 理解PDF/A和PDF/X的差异
PDF/A和PDF/X是PDF格式的两个特定标准,分别针对不同的用途和要求。
- **PDF/A**:是专为文档存档设计的PDF标准,它保证文档在未来能够被准确地再现和打印。PDF/A禁止包含可能会随时间改变的特征,例如,它不允许使用可执行的JavaScript。PDF/A有三个不同的子版本(PDF/A-1, PDF/A-2, PDF/A-3),这些子版本针对不同的存档要求和功能。
- **PDF/X**:主要面向印刷和图像行业。PDF/X标准为确保印刷过程中的色彩、字体和图像的一致性提供了一系列规范,要求PDF文件中必须包含所有必需的字体和图像,并且符合特定的颜色和输出要求。
这两种标准的转换涉及到对原始PDF文件的全面检查,确保转换后的文件满足特定标准所要求的条件。
### 5.1.2 转换为存档或打印标准的最佳实践
转换为PDF/A或PDF/X标准时,最佳实践包括:
- **预先验证**:使用专业的PDF验证工具检查原始PDF文件是否符合转换目标标准的要求。
- **使用专业工具**:选择支持PDF/A和PDF/X标准转换的工具,例如Adobe Acrobat或专业的PDF转换软件。
- **设置适当的转换参数**:在转换过程中选择正确的标准,并根据需要设置相关的参数,如颜色模式和字体嵌入选项。
- **后期验证和修正**:转换后,再次使用验证工具检查文档是否符合标准,如发现问题,应进行必要的修正。
下面是一个使用Adobe Acrobat进行PDF/A转换的示例代码块:
```python
from PyPDF2 import PdfFileReader, PdfFileWriter
from pdf2image import convert_from_path
from io import BytesIO
def convert_to_pdfa(input_pdf_path, output_pdf_path):
# 使用PyPDF2库读取PDF
pdf_writer = PdfFileWriter()
pages = convert_from_path(input_pdf_path)
for page in pages:
pdf_writer.add_page(page)
# 写入到BytesIO对象,以便PDF2Image可以处理
buffer = BytesIO()
pdf_writer.write(buffer)
# 将BytesIO转换为PDF
pdf = PdfFileReader(buffer)
pdf_output = PdfFileWriter()
# 将PDF转换为PDF/A标准
for page in range(pdf.numPages):
pdf_output.addPage(pdf.getPage(page))
with open(output_pdf_path, "wb") as file:
pdf_output.write(file)
convert_to_pdfa('input.pdf', 'output.pdf')
```
这段代码首先将PDF文件转换为图像格式,然后再转换回PDF格式,这样可以确保PDF符合PDF/A标准。这种方法适用于那些需要将扫描文档转换为存档级别标准的场景。
## 5.2 PDF安全性和权限设置
### 5.2.1 加密PDF文件
在需要保护文档内容时,PDF提供加密功能,通过设置密码保护文件,限制文件的打开、打印、编辑等功能。在Python中,可以使用PyPDF2库来实现这一功能。
下面是一个示例代码块,展示了如何给PDF文件设置密码:
```python
from PyPDF2 import PdfFileReader, PdfFileWriter
def encrypt_pdf(input_pdf_path, output_pdf_path, password):
# 读取PDF文件
pdf_writer = PdfFileWriter()
pdf_reader = PdfFileReader(input_pdf_path)
# 加密文件
pdf_writer.cloneDocumentFromReader(pdf_reader)
pdf_writer.encrypt(user_pwd=password, owner_pwd=password, use_128bit=True)
# 将加密后的内容写入新文件
with open(output_pdf_path, 'wb') as output_pdf_file:
pdf_writer.write(output_pdf_file)
encrypt_pdf('input.pdf', 'output.pdf', 'your_password')
```
在执行上述操作后,只有输入正确密码的用户才能访问PDF文件。
### 5.2.2 设置文档权限和访问控制
除了设置密码,用户还可以设置不同的文档权限,例如是否允许打印、编辑内容或者复制文本。权限的设置依赖于PDF文件的加密策略和密码的复杂度。
权限设置可以通过修改PDF文件的内部属性来实现:
```python
pdf_writer.addMetadata({
'/Producer': 'PyPDF2',
'/Author': 'Your Name',
'/CreationDate': 'D:20230301120000',
'/ModDate': 'D:20230301120000',
'/Subject': 'Subject',
'/Title': 'Title',
'/Keywords': 'Keywords',
'/Creator': 'PyPDF2',
'/Linearized': '0',
'/Trapped': '/False',
'/MetadataDate': 'D:20230301120000',
'/OCProperties': {
'D': [{
'TYPE': '/Sig',
'Filter': '/Adobe.PPKLite',
'SubFilter': '/ETSI.CAdES.detached',
'Reference': {
'Type': '/Transform',
'TransformMethod': '/Base64',
'URI': 'This is an example URI.'
},
'Name': 'Example Signature',
'M': '20230301120000Z',
'Contents': 'Example Signature Contents',
'Reason': 'Example Reason',
'ContactInfo': 'Contact Info',
'Location': 'Location'
}]
},
'/PageMode': '/UseOutlines',
'/OCGs': [{
'ON': True,
'BaseState': '/ON',
'Name': 'Example OCG',
'Intent': '/Design',
'S': 'Yes'
}],
'/MarkInfo': {
'Marked': True,
'UserProperties': True,
'Suspects': False
}
})
```
上述代码展示了如何使用PyPDF2库为PDF文件添加元数据和设置权限。
## 5.3 OCR技术在PDF转换中的应用
### 5.3.1 从扫描文档创建可搜索的PDF
光学字符识别(OCR)技术能够从图像或扫描的PDF文档中识别文字,将非可编辑的图像转换为可搜索和可选择的文本。
使用Python实现OCR转换的示例代码如下:
```python
import pytesseract
from PIL import Image
import io
def ocr_scan_to_pdf(input_image_path, output_pdf_path):
# 使用Pillow库打开图像文件
img = Image.open(input_image_path)
img_byte_arr = io.BytesIO()
img.save(img_byte_arr, format='PNG')
img_byte_arr = img_byte_arr.getvalue()
# 使用Tesseract进行OCR识别
text = pytesseract.image_to_string(Image.open(io.BytesIO(img_byte_arr)))
# 将识别的文本写入PDF
doc = SimpleDocTemplate(output_pdf_path)
Story = []
Story.append Paragraph(text, styles['Normal'])
doc.build(Story)
ocr_scan_to_pdf('input.png', 'output.pdf')
```
在这个例子中,Pillow用于图像处理,而pytesseract用于OCR识别。
### 5.3.2 OCR错误纠正和优化
OCR识别过程中可能会出现错误,因此通常需要对识别出的文本进行校对和编辑。可以使用如下方法来优化OCR的准确性:
- **图像预处理**:在进行OCR之前对图像进行清晰化、二值化、去噪等处理,以提高识别率。
- **字典校对**:增加自定义字典,可以提高特定行业术语或专有名词的识别准确率。
- **人工校对**:对于重要的文档转换,推荐进行人工校对,以确保转换后的文本准确无误。
在实际应用中,还可以结合PDF处理库和OCR库,自动化这一流程,提高工作效率。
通过本章节的介绍,我们了解了PDF/A和PDF/X转换标准的重要性,以及如何使用Python设置PDF文件的安全性和权限。此外,我们还探索了OCR技术如何在PDF转换中发挥作用,以及如何优化OCR的准确性。在下一章节中,我们将讨论未来PDF转换技术的发展趋势,以及人工智能、云服务和开源工具在这一领域的应用前景。
# 6. 未来PDF转换技术的发展趋势
随着技术的快速发展,PDF转换技术也在不断进步和演变。新的趋势和创新正在涌现,为用户提供更智能、更便捷的转换解决方案。在这一章节中,我们将探讨未来PDF转换技术的发展趋势,包括人工智能的应用、云端服务和移动转换的潜力,以及开源工具和自定义转换解决方案的兴起。
## 6.1 人工智能在PDF转换中的应用
人工智能(AI)已经成为改善和简化各种技术流程的强大工具,PDF转换也不例外。通过引入AI技术,我们可以实现更加智能和自动化的转换过程。
### 6.1.1 机器学习改善转换质量
机器学习算法能够学习和适应不同的转换需求,从而提高转换的准确性和效率。例如,通过机器学习,PDF转换器可以自动识别文档中的不同元素(如文本、图像、表格等),并根据内容的性质来优化转换设置。
**代码块示例(伪代码):**
```python
# 伪代码示例,展示机器学习在PDF转换中的潜在应用
import machine_learning_model
def improve_conversion_quality(input_pdf):
# 使用机器学习模型分析PDF内容
elements = machine_learning_model.analyze_pdf(input_pdf)
# 根据分析结果调整转换参数
optimized_params = machine_learning_model.calculate_optimized_params(elements)
# 应用优化参数进行转换
output_pdf = convert_pdf(input_pdf, optimized_params)
return output_pdf
```
### 6.1.2 自然语言处理优化文本转换
自然语言处理(NLP)技术可以用来改善文档中的文本转换。NLP可以识别文档中的语言和语境,然后自动进行文本格式的优化,如自动翻译、文本校对和内容摘要。
**代码块示例(伪代码):**
```python
# 伪代码示例,展示自然语言处理在PDF文本转换中的应用
import natural_language_processing
def optimize_text_conversion(input_pdf):
# 提取PDF中的文本内容
text_content = extract_text_from_pdf(input_pdf)
# 使用NLP进行文本优化处理
optimized_text = natural_language_processing.process_text(text_content)
# 将优化后的文本重新插入PDF
output_pdf = insert_optimized_text(input_pdf, optimized_text)
return output_pdf
```
## 6.2 云端服务和移动转换
云计算和移动技术的普及为PDF转换带来了新的可能性。用户可以随时随地通过互联网访问服务,并且利用移动设备进行转换操作。
### 6.2.1 利用云平台实现高效转换
云平台可以提供强大的计算资源,支持大规模和高复杂度的PDF转换任务。用户可以根据需求选择不同的云服务提供商,并通过云服务实现高度可扩展的转换解决方案。
**表格示例:**
| 云服务提供商 | 转换速度 | 可用性 | 成本效益 |
|---------------|-----------|--------|----------|
| 云服务A | 高 | 高 | 中 |
| 云服务B | 中 | 中 | 高 |
| 云服务C | 低 | 高 | 低 |
### 6.2.2 移动设备上的PDF转换工具
移动设备上的PDF转换工具正在变得越来越成熟。用户可以通过应用程序直接在手机或平板电脑上进行PDF转换,这些应用通常具有直观的用户界面,并且支持多种转换任务。
**列表示例:**
- 随时随地进行文件转换
- 支持多种文件格式之间的转换
- 通过电子邮件、云存储或直接通过应用分享转换后的文件
## 6.3 开源工具和自定义转换解决方案
开源工具提供了高度的灵活性和定制能力,允许用户根据自己的特定需求开发和部署PDF转换解决方案。
### 6.3.1 探索开源PDF处理库
开源的PDF处理库,如Poppler、PDFium和Apache PDFBox,提供了丰富的API和工具,允许开发者进行深入的PDF操作,包括但不限于转换、编辑和内容提取。
**mermaid格式流程图示例:**
```mermaid
graph LR
A[开始] --> B[选择开源库]
B --> C[阅读文档]
C --> D[集成API]
D --> E[自定义转换逻辑]
E --> F[测试和部署]
F --> G[发布自定义工具]
```
### 6.3.2 构建定制的PDF转换工作流
通过将不同的开源工具和自定义脚本整合在一起,可以构建一个完整的工作流程,从而自动化整个转换过程,同时保留高度的自定义选项来满足特定的业务需求。
**代码块示例(伪代码):**
```python
# 伪代码示例,展示如何构建一个PDF转换工作流
import pdf_library
import conversion_script
def build_custom_conversion_workflow(input_pdf):
# 使用开源库读取PDF文档
pdf_document = pdf_library.read_pdf(input_pdf)
# 应用转换脚本进行内容转换
converted_content = conversion_script.apply_conversion(pdf_document)
# 保存转换后的PDF文件
output_pdf = pdf_library.save_pdf(converted_content, "output.pdf")
return output_pdf
```
随着技术的不断进步,未来PDF转换将变得更加智能、便捷和自定义。用户不仅能够享受到更快更准确的转换服务,还可以通过先进的工具和平台,实现个性化的转换需求。这一切将彻底改变我们处理和转换PDF文档的方式。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了 20 个专业技巧和 10 种权威解决方案,旨在解决使用 Acrobat 创建 PDF 时 Microsoft Office 文件不支持的问题。通过遵循这些专家指南,读者可以掌握 Office 文件转换的成功秘诀,并提升转换率。专栏还提供了问题诊断全解析、独家揭秘和紧急应对策略,帮助读者立即解决转换障碍,提高效率。此外,专栏还传授了黄金法则和优化技巧,让 Office 文件转换变得更加轻松无忧。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【十进制计数器性能革命】:实现计数速度与稳定性的双重突破

参考资源链接:[西南交通数电:十进制可逆计数器设计与实现](https://wenku.csdn.net/doc/4kw3ievq3g?spm
安川G7电气设计精要

参考资源链接:[安川G7变频器使用指南:安装与安全须知](https://wenku.csdn.net/doc/4srkck2qpv?spm=1055.2635.3001.10343)
# 1. 安川G7系列电气设备概述
在当今复杂的工业环境中,安川G7系列电气设备作为自动化和控制领域的一部分,扮演着至关重要的角色。本章节旨在为读者提供一个关于安川G7电气设备的基础介绍,包括其特点、应用领域和市场定位。首先,我们将了解
WebView2 Runtime x64-109.exe安装失败急救指南:终极解决方案
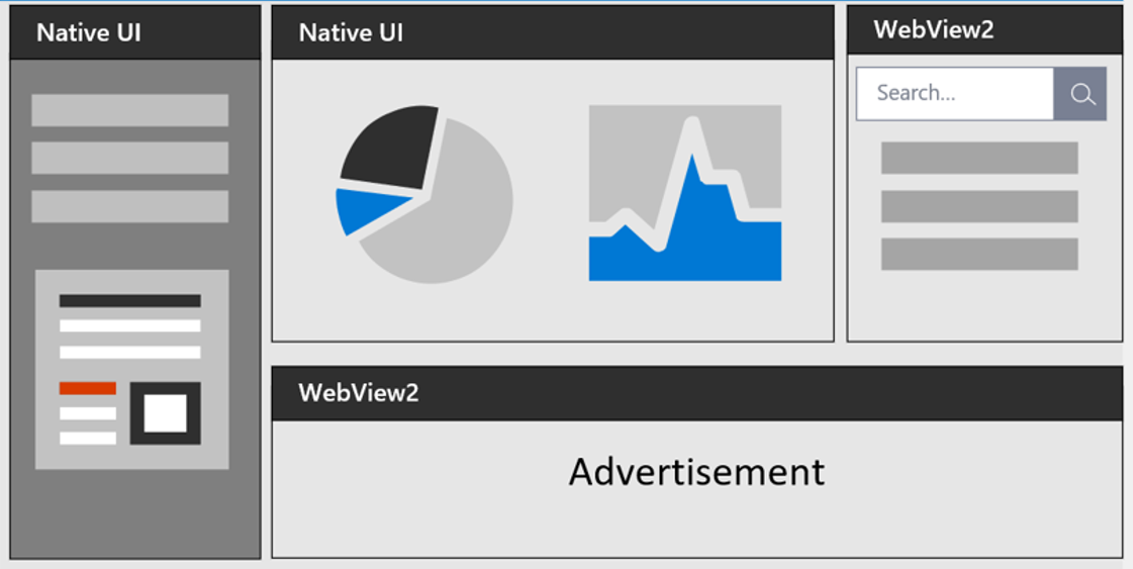
参考资源链接:[解决Edge WebView2在Win7系统上的安装问题](https://wenku.csdn.net/doc/4gyr8mg6ib?spm=1055.2635.3001.10343)
# 1. WebView2 Runtime x64-109.exe概述
## 简介
WebView2 Runtime x
JavaScript错误处理大师课:管理Uncaught SyntaxError的最佳实践

参考资源链接:[JavaScript: Uncaught SyntaxError: Unexpected token ) 解决教程](https://wenku.csdn.net/doc/6401ad10cce7214c316ee25b?spm=
AIS协议解析精要:动态数据的提取与应用(实用指南)

参考资源链接:[AIS数据协议详解:结构、编码与校验](https://wenku.csdn.net/doc/5q1x6x6rmd?spm=1055.2635.3001.10343)
# 1. AIS协议概览
## 1.1 AIS协议的重要性
AIS(Automatic Identification System,自动识别系统)是一种用于船只和
【LAMMPS数据可视化大揭秘】:轻松处理数据的可视化工具
参考资源链接:[LAMMPS Data文件创建:从Ms到Atomsk与OVITO](https://wenku.csdn.net/doc/7478dbc96n?spm=1055.2635.3001.10343)
# 1. LAMMPS数据可视化的概述
在现代计算材料科学领域,分子动力学模拟(MD)已经成为研究材料性质和过程的重要手段。作为MD模拟软件中的佼佼者,LAMMPS(Large-sc
【数据迁移秘籍】:Ecology9平滑过渡的技术细节与实践

参考资源链接:[泛微Ecology9在Linux下的详细安装部署指南](https://wenku.csdn.net/doc/646046fa5928463033ad442d?spm=1055.2635.3001.10343)
# 1. 数据迁移基础概述
在数字化转型的浪潮中,数据迁移是IT行业的一个重要环节,它涉及到数据从一个系统、平台或环境转移到另一个的过程。有效执行数据迁
风险沟通的艺术:3个ISO31000沟通技巧让你无往不利
参考资源链接:[ISO31000:2018风险管理升级版:领导力与优化为核心](https://wenku.csdn.net/doc/6412b738be7fbd1778d4983d?spm=1055.2635.3001.10343)
# 1. ISO31000风险沟通概述
风险沟通是风险管理的核心组成部分,其目的是帮助组织和个人理
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )