【Go内嵌结构体与并发安全】:确保线程安全的高级策略与实践
发布时间: 2024-10-21 10:47:00 阅读量: 24 订阅数: 22 

java与C#区别详细介绍1.pdf
# 1. Go语言并发基础与内嵌结构体简介
Go语言自从发布以来,其内置的并发特性迅速成为开发者的热门话题。本章节将介绍Go语言的并发基础,并对内嵌结构体的概念进行深入解读,为读者揭开Go语言并发编程和结构体设计的神秘面纱。
## Go语言并发编程的入门
Go语言的并发模型基于CSP( Communicating Sequential Processes,通信顺序进程)理论,提倡通过消息传递进行进程间通信(IPC)而非共享内存。这一理念在Go中的实现主要体现在Goroutine和Channels上。
**Goroutine:** 相较于传统语言的线程,Goroutine在Go中非常轻量级。启动一个Goroutine的成本很低,这使得开发者能够以极小的性能开销并发执行大量任务。以下是一个简单的Goroutine启动示例:
```go
func say(s string) {
for i := 0; i < 5; i++ {
time.Sleep(100 * time.Millisecond)
fmt.Println(s)
}
}
func main() {
go say("world") // 并发执行
say("hello") // 主函数中同步执行
}
```
**Channels:** Channels作为Goroutine间通信的桥梁,通过通道发送和接收数据,保证了数据同步性和线程安全。通道是类型化的,这意味着只能传递一种类型的值。
```go
ch := make(chan int)
ch <- 1 // 发送值到通道
value := <-ch // 从通道接收值
```
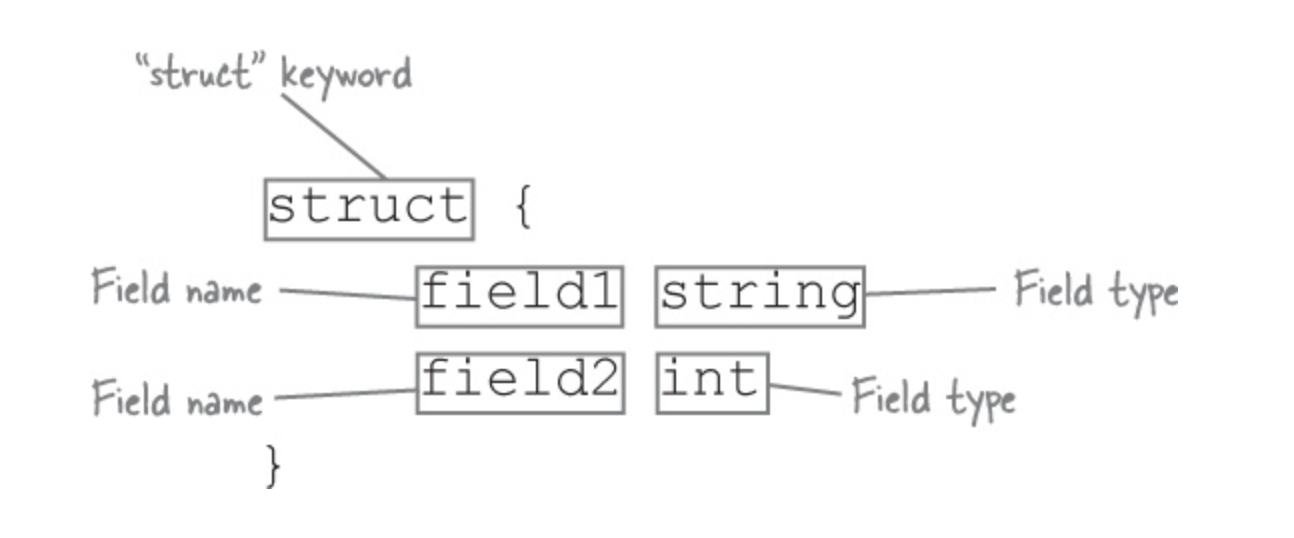
## 内嵌结构体简介
内嵌结构体是Go语言中的一项特性,允许开发者在结构体中内嵌其他结构体或接口,来扩展新的结构体的功能。这种语法糖不仅简化了代码,还能提供更深层次的继承和组合。
```go
type Base struct {
Name string
}
type Container struct {
Base
Description string
}
container := Container{
Base: Base{Name: "Base container"},
Description: "This is a container with a base.",
}
fmt.Println(container.Name) // 输出 "Base container"
```
内嵌结构体能够在不改变原有结构体定义的情况下,赋予结构体新的行为和属性,从而构建出更为复杂的类型系统。
在后续章节中,我们将深入探讨Go语言的并发安全理论基础,以及如何确保并发安全的高级实践技巧,并分析Go内嵌结构体与并发安全在真实项目中的应用案例。
# 2. 并发安全的理论基础
### 2.1 Go语言的并发模型
#### 2.1.1 Goroutine和Channels
Go语言在设计时就内置了对并发的原生支持,这使得在Go中编写并发程序变得异常简单和高效。Go的并发模型基于CSP(Communicating Sequential Processes)理论,其中两个核心组件是Goroutine和Channels。
Goroutine是Go中并发的核心,可以将其视为轻量级线程。在Go中创建一个Goroutine非常简单,只需要在函数调用前加上关键字`go`。例如,`go f(x, y, z)`会立即返回,`f(x, y, z)`会在一个新的Goroutine中异步执行,而主程序则会继续执行下一行代码,无需等待Goroutine执行完毕。
Channels则是Goroutine之间通信的通道。它们像是管道,允许数据在Goroutine之间安全地传递。在Go中,一个Channel是一个先进先出(FIFO)队列,既可以是无缓冲的,也可以是有缓冲的。无缓冲的Channel会在两个Goroutine试图通过它发送和接收数据时同步。而有缓冲的Channel在队列未满时允许发送者继续发送数据,只有当队列满时发送者才会阻塞。
```go
package main
import "fmt"
func sum(s []int, c chan int) {
sum := 0
for _, v := range s {
sum += v
}
c <- sum // send sum to c
}
func main() {
s := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
go sum(s[:len(s)/2], c)
go sum(s[len(s)/2:], c)
x, y := <-c, <-c // receive from c
fmt.Println(x, y, x+y)
}
```
在这段代码中,`sum`函数在两个不同的Goroutine中计算了切片`s`的一半的和。每个Goroutine将计算结果发送到同一个`c` Channels中,主程序从这个Channel中接收两个结果并打印。
#### 2.1.2 竞态条件与数据竞争
虽然Goroutine和Channels为并发编程带来了便利,但它们也带来了潜在的复杂性。最常见的是竞态条件(race condition)和数据竞争(data race)问题。
竞态条件是指程序的执行结果依赖于特定的执行顺序或时间,而这种顺序或时间在并发环境下是不确定的。当多个Goroutine并发地访问和修改共享数据时,如果没有适当的同步机制,就可能导致数据竞争,进而导致程序行为不可预测。
为了识别和避免这些问题,Go提供了`go vet`工具和运行时的race detector。`go vet`可以分析Go代码并报告可疑的构造,而race detector在测试时可以检测并报告数据竞争。
### 2.2 并发安全的理论概念
#### 2.2.1 什么是并发安全
并发安全是指在并发执行的程序中,多个goroutine可以同时安全地访问和修改同一个数据结构,而不会造成数据的不一致或竞争条件。
并发安全并不意味着所有的并发操作都必须是原子的,而是指通过适当的同步机制和数据结构设计,确保程序的行为在并发环境下仍然是正确的。例如,可以使用互斥锁(mutexes)、读写锁(RWMutexes)、原子操作(atomics)以及通道(channels)等来保证数据的一致性。
#### 2.2.2 并发安全的必要性
在构建大型、复杂的应用程序时,特别是在微服务架构和分布式系统中,保证数据一致性是非常关键的。数据不一致可能导致程序出现错误、性能问题,甚至服务故障。并发安全的必要性不仅体现在保证数据的一致性,还体现在提高系统的可靠性、可维护性和可扩展性。
举个简单的例子,如果我们有一个全局变量`counter`表示服务中的请求数量,当多个Goroutine并发地增加这个计数器时,我们需要确保每次增加操作都是安全的,否则最终计数可能会不准确。
### 2.3 内存可见性和原子操作
#### 2.3.1 内存模型基础
在并发编程中,内存可见性是指一个goroutine对共享变量的修改能够被其他goroutine及时看到的能力。在Go语言中,内存模型定义了变量读取和写入之间的顺序。简单来说,Go的内存模型是通过happens-before规则来定义的,即如果一个操作A在时间上发生在另一个操作B之前,那么A的结果对B可见。
然而,在没有适当同步的情况下,不同Goroutine对同一变量的读写可能会发生重排(reordering),这就可能导致数据竞争。因此,内存模型也规定了一些内存屏障(memory barriers)的规则,来保证某些操作能够按照特定的顺序发生。
#### 2.3.2 原子操作的使用和原理
原子操作是指在多线程环境中,其操作不可分割,即在执行过程中不会被线程调度机制打断的操作。在Go中,`sync/atomic`包提供了原子操作,这些操作对于并发程序非常有用,尤其是那些需要维护共享状态的程序。
原子操作背后通常依赖于特定硬件的原子指令,比如比较并交换(Compare-and-Swap, CAS)。使用原子操作可以确保并发环境下的数据安全,而不需要使用锁机制,从而避免了锁带来的性能开销。
```go
package main
import (
"fmt"
"sync/atomic"
)
func main() {
var ops uint64
for i := 0; i < 50; i++ {
go func() {
for {
atomic.AddUint64(&ops, 1)
// Note: it would be a race condition if we did not use atomic here.
if atomic.LoadUint64(&ops) == 100000 {
break
}
}
}()
}
// Wait for gorou
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Go 内嵌结构体的终极指南!本专栏将深入探讨 Go 中内嵌结构体的方方面面,从基础概念到高级应用。您将学习如何利用内嵌结构体实现继承、组合和代码重构。我们还将探索内嵌结构体在并发编程、面向对象设计和模块化设计中的应用。此外,您将了解内嵌结构体的内存布局优化、性能提升和类型断言。通过深入的分析、代码示例和最佳实践,本专栏将帮助您掌握 Go 内嵌结构体的奥秘,从而提升您的编程技能并构建更强大、更灵活的应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
运动模型实战:提升计算效率的7大优化策略

# 摘要
运动模型在计算机科学与工程领域中扮演着关键角色,其计算效率直接影响到模型的性能和实用性。本文首先阐述了运动模型的理论基础,探讨了理论框架、模型分类以及数学与物理意义。随后,本文重点分析了计算效率的重要性和优化策略,包括算法选择、数据结构、时间复杂度和空间复杂度的优化。通过并行计算和分布式系统,算法改进与模型简化,以及数据管理和缓存优化的实践方法,本文
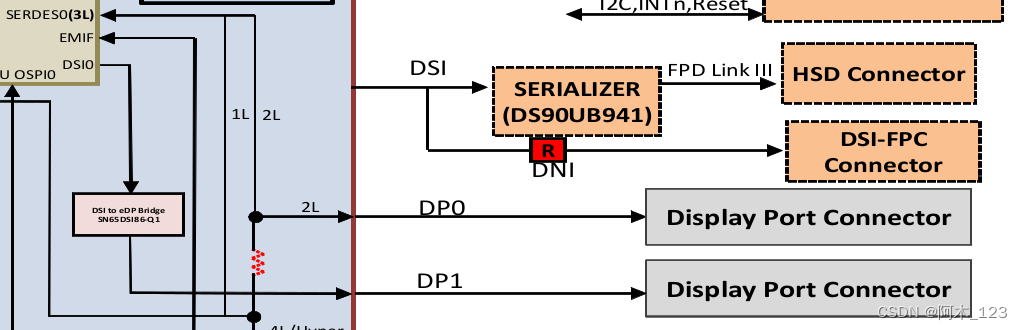
嵌入式系统中的MDSS-DSI-Panel集成:顶级工程师的调试与案例分析
# 摘要
本文全面解析了MDSS-DSI-Panel的集成概念,详细探讨了硬件接口与通信协议的关键要素,包括MDSS组件、DSI接口标准、Panel接口类型及选择标准,以及DSI协议的工作模式、帧结构和数据传输优化。文章还深入研究了软件配置,涵盖了驱动层配置优化和应用层接口实现。通过嵌入式系统中实践案例的分析,本文提供故障排除与维护的策略,并展望了MDSS-DSI-Panel集成技
【Avantage平台:5分钟快速启动新手项目指南】:别让项目启动拖沓!

# 摘要
本文旨在为初学者提供一个全面的Avantage平台入门指南。首先概述了Avantage平台的核心概念和基础使用,接着详细介绍了新手项目准备、环境搭建和快速启动项目的步骤。文中也对项目的核心功能、代码结构和编写规范进行了解读,并提供了问题定位与调试的实用方法。此外,本文还探讨了项目扩展、性能优化、安全加固和定期维护等高级话题。最后,本文通过分析社区资源与用户支持
浏览器版本管理的艺术:Chromedriver最佳实践

# 摘要
本文对Chromedriver及其在Selenium自动化测试中的应用进行了全面介绍。首先概述了浏览器自动化的基本概念,随后详细解读了Selenium框架与WebDriver的集成机制,并重点阐述了Chromedriver的作用、特点以及与Chrome浏览器的交互方式。接
ISE 14.7深度优化:高级技巧助你提升性能
# 摘要
本文系统介绍了ISE 14.7软件在FPGA设计与开发中的应用,重点探讨了其性能优化的核心技术和策略。首先,本文概述了ISE 14.7的基本性能以及项目管理和代码优化的基础知识,强调了设计原则和资源管理的重要性。随后,深入分析了高级性能优化策略,包括高级综合特性、处理器及IP核优化,以及硬件调试与性能验证的高级技巧。通过具体案例分析,文章
【A6电机性能优化】:掌握9个关键参数设定技巧,让你的电机运行无忧

# 摘要
A6电机作为一款高效节能的电机产品,其性能优化和智能化管理是当前研究的热点。本文首先概述了A6电机的基本特点,接着详细解析了影响其性能的关键参数,包括效率、功率因素以及负载能力的优化调整。针对电机运行中产生的热管理问题,本文探讨了温升控制、散热系统设计以及维护和寿命预测的有效方法。在电机控制方面,本文着重介绍了变频技术的应用和电机智能化管理的优势,以及远程监控技术的进步。通过性能
【泛微OA流程表单开发】:13个秘籍让你从新手到高手
# 摘要
泛微OA流程表单开发是企业信息化管理的重要组成部分,本文详细介绍了流程表单开发的基础设置、实践技巧、调试优化及高级应用。从基础的表单设计到复杂流程的实现,再到与其他系统的集成,本文提供了一系列操作指南和高级定制功能。同时,文章也强调了在开发过程中对于权限和数据安全的重视,以及在流程表单优化中提升用户体验和处理效率的策略。最后,展望了人工智能技术在流程表单中的潜在
【性能优化专家】:宿舍管理系统效率提升的十大关键点

# 摘要
本文综合分析了宿舍管理系统的性能优化方法,涉及数据库性能调优、应用层代码优化、网络与硬件层面的性能调整等多个方面。通过数据库设计优化、SQ
【ADAMS坐标系调整实战】:理论到实践的详细操作指南

# 摘要
本论文深入探讨了ADAMS软件中坐标系的基础概念、理论知识与类型,并详细阐述了坐标系在建模、运动分析和结果输出中的应用。此外,本文介绍了坐标系调整的实战技巧,包括基于ADAMS的命令操作和图形用户界面的使用方法,以及针对特定几何特征的坐标系对齐与定位技巧。论文还分析了动态仿真、复杂模型和多体系统中坐标系调整的高级应用案例,并探讨了自动化、智能化调整技术的发展趋势。最后,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )