【Kettle与Hive的高效整合】:批量插入技术详解与实践
发布时间: 2024-12-14 22:47:11 阅读量: 3 订阅数: 11 

13 - 淘宝直播:内容话术有哪些怎么找话题能拥有人气.pdf

参考资源链接:[优化Kettle到Hive2批量插入:提升速度至3000条/秒](https://wenku.csdn.net/doc/6412b787be7fbd1778d4a9ed?spm=1055.2635.3001.10343)
# 1. Kettle与Hive简介及其整合意义
## 1.1 Kettle与Hive的概念及整合价值
数据处理和大数据分析是现代IT领域中的核心议题之一。Kettle(又称Pentaho Data Integration)是一款强大的开源ETL工具,它能够有效地帮助数据工程师处理数据转换、整合和迁移等任务。Hive则是建立在Hadoop上的数据仓库工具,主要用于简化对大数据集的SQL查询。将Kettle与Hive整合,可以实现数据的高效整合、处理和分析,对于构建现代数据处理管道至关重要。
## 1.2 为何要整合Kettle与Hive
整合Kettle与Hive的主要目的是将Kettle强大的数据处理能力与Hive在处理大规模数据集上的优势相结合。Kettle可以作为Hive的数据前处理工具,执行数据清洗、转换和加载等操作,而Hive可以作为存储和分析大数据的平台。通过这种整合,可以实现对大规模数据集的高效分析,同时也能提供对实时数据流的处理能力,提高数据处理的灵活性和可伸缩性。
## 1.3 本章小结
在本章中,我们概览了Kettle与Hive的基础概念,并讨论了将二者整合的必要性和潜在价值。在接下来的章节中,我们将深入探讨Kettle的基础知识、Hive的数据仓库原理,以及如何准备整合工作,为后续的实践应用和技术讨论打下坚实基础。
# 2. Kettle基础知识与Hive架构
### 2.1 Kettle的基本概念与组件
#### 2.1.1 Kettle的核心组件介绍
Kettle是Pentaho数据集成(PDI)的组件,它提供了一种快速且简便的方法来执行提取、转换、加载(ETL)操作。Kettle包含了两个主要的应用程序:Spoon和Kitchen。
- **Spoon** 是一个图形用户界面(GUI)工具,允许用户通过拖放组件来创建转换和作业。这些组件包括输入、输出、转换和工作步骤,它们之间通过跳跃(jumps)连接,代表数据流。
- **Kitchen** 是一个命令行界面(CL),用于执行定义在转换文件中的数据集成任务。Kitchen对于自动化和批处理操作非常有用,可以在没有图形界面的服务器环境中运行。
每个核心组件都扮演着重要角色,在ETL过程中有着特定的职责。转换(Transformation)和作业(Job)是Kettle的两大核心概念。转换专注于数据的抽取、转换和加载的单次执行,而作业则负责定义一系列转换的执行顺序,可以视为转换的容器,用于执行复杂的批处理任务。
#### 2.1.2 Kettle在ETL过程中的作用
Kettle在ETL过程中发挥着至关重要的作用,它为数据提取、转换和加载提供了一个强大的平台。以下是Kettle在ETL过程中的几个关键作用:
1. **数据抽取**:Kettle可以连接到各种数据源,包括关系型数据库、文件系统、平面文件、消息队列和API服务。数据抽取过程可以是简单的单表查询,也可以是复杂的多数据源联结。
2. **数据转换**:数据转换是ETL过程中最复杂和最耗时的步骤。Kettle提供了大量内置的转换步骤,用于处理数据的清洗、格式化、聚合和验证等。用户也可以通过JavaScript或自定义Java类来实现复杂的转换逻辑。
3. **数据加载**:在数据转换完成后,Kettle可以将数据加载到目标系统,如关系型数据库、数据仓库或大数据平台。加载过程中,Kettle支持事务管理,可以确保数据的一致性和完整性。
4. **日志记录和错误处理**:Kettle记录详细的操作日志,方便用户追踪ETL流程的状态。此外,Kettle还提供了强大的错误处理机制,能够捕捉和处理数据加载过程中可能出现的问题。
Kettle的设计理念是使得ETL开发者可以更加聚焦于业务逻辑的实现,而不必担心底层的数据处理和基础设施问题。
### 2.2 Hive的数据仓库原理
#### 2.2.1 Hive的架构与组件
Hive是一个建立在Hadoop之上的数据仓库基础架构,它提供了一系列工具,用于进行数据摘要、查询和分析。Hive将SQL语句转换为MapReduce任务进行分布式处理,但执行的效率通常比直接使用MapReduce编程要高。
- **Metastore**:Hive的元数据存储,包含了数据库、表、分区等信息的定义。它使用关系型数据库作为后端存储,是Hive的核心组件之一。
- **Driver**:驱动组件,负责处理用户提交的查询请求。它主要包含编译器、优化器和执行器。
- **Compiler**:将HiveQL语句编译成执行计划。
- **Optimizer**:优化器负责优化执行计划,使之更有效率。
- **Executor**:执行器负责执行优化后的执行计划,将任务分配给不同的执行节点。
- **HiveServer2**:允许远程客户端使用各种编程语言和Hive进行交互。
- **Hive CLI/Beeline**:Hive的命令行接口,用户可以通过它执行HiveQL语句,也可以作为HiveServer2的一个客户端工具。
Hive将数据存储在HDFS上,使用一种类似于传统数据库中的表结构,但它存储的是半结构化的数据文件。HiveQL是一种类SQL语言,支持大部分SQL-92标准语法,以及一些扩展语法用于数据的处理和分析。
#### 2.2.2 HiveQL与传统SQL的异同
HiveQL是Hive提供的查询语言,它在很多方面类似于标准的SQL,但二者之间存在一些关键差异:
- **性能优化**:传统SQL直接执行,性能优化主要由数据库管理系统(DBMS)在查询执行前完成。HiveQL的查询首先被编译成一系列的MapReduce作业,性能优化主要在编译阶段由Hive的优化器完成。
- **数据存储**:Hive主要用于存储在HDFS上的大数据集,而传统SQL数据库则使用磁盘存储数据,对查询的响应时间更短。
- **类型支持**:虽然HiveQL支持数据类型如INT、STRING和FLOAT等,但对数据类型的处理不如传统SQL数据库严格。
- **处理能力**:HiveQL可以处理非常大的数据集,但对复杂事务的支持不如传统SQL数据库。
- **数据模型**:HiveQL使用表来表示数据,可以使用分区和桶等技术优化数据处理,适用于数据分析场景。
在处理大数据分析任务时,HiveQL提供了更多的灵活性和可扩展性,允许用户通过自定义函数(UDF)和MapReduce来扩展其功能。这使得Hive成为了一个强大的数据仓库工具,特别适合对大量数据集进行分析。
### 2.3 Kettle与Hive整合前的准备工作
#### 2.3.1 环境配置与依赖关系
在整合Kettle与Hive之前,需要确保所需的环境配置正确,并解决好依赖关系。这包括以下几个关键步骤:
1. **安装与配置Hadoop环境**:Hive是建立在Hadoop平台之上的,因此,确保Hadoop环境已经安装并正确配置是首要步骤。这包括配置`hadoop-env.sh`以设置Java环境,以及编辑`core-site.xml`、`hdfs-site.xml`和`mapred-site.xml`等配置文件。
2. **安装Hive**:安装完成后,需要配置Hive,包括设置Metastore的数据库,通常使用MySQL或Derby,并确保所有服务能够正常启动。
3. **配置Kettle**:Kettle需要能够访问Hive环境,因此需要在Kettle的配置文件中指定Hadoop的环境设置和Hive的JDBC连接信息。这通常在`pentaho-big-data-plugin`目录下的`plugin.properties`文件中完成。
4. **安装并配置数据源驱动**:在连接到数据库或其他数据源时,确保已经安装了相应的JDBC驱动程序,并且在Kettle中能够正确加载。
5. **配置网络和安全设置**:根据使用的集群类型,可能需要配置网络设置和安全机制,如Kerberos认证,确保Kettle和Hive之间能够安全通信。
#### 2.3.2 数据类型匹配与转换策略
在Kettle与Hive整合的过程中,一个重要的考量是数据类型的一致性和转换策略。HiveQL和Kettle的数据类型不完全一致,因此需要进行适当的转换以确保数据的准确性和完整性。
1. **理解数据类型差异**:首先,需要明确HiveQL和Kettle支持的数据类型之间的差异。例如,Hive的INT类型在Kettle中对应于`Integer`类型,但是Hive的BIGINT类型可能在Kettle中对应于`Long`类型。
2. **制定转换规则**:根据数据类型的不同,制定相应的转换规则。这可能包括改变数据类型、格式化日期时间或进行类型转换。
3. **在转换过程中实施类型转换**:在Kettle的转换设计中,使用转换步骤来实现类型转换。例如,使用“类型转换”步骤将字符串转换为日期。
4. **使用Hive用户定义函数(UDF)**:对于一些复杂的转换,可能需要使用Hive的用户定义函数。这要求编写Java类来实现特定的转换逻辑,并在Hive中注册UDF。
5. **测试类型转换的有效性**:在实际应用转换规则之前,应进行彻底的测试,确保转换后的数据满足业务逻辑和质量要求。
通过以上步骤,可以确保Kettle与Hive整合过程中数据类型的一致性和准确性,为后续的数据处理和分析打下坚实基础。
# 3. Kettle与Hive的批量插入技术
## 3.1 Kettle批量操作的核心组件
### 3.1.1 了解Kettle中的转换(Transformation)与作业(Job)
Pentaho Data Integration (PDI), 通常称为 Kettle, 是一种强大的ETL工具,它通过两个核心概念简化了数据的抽取、转换和加载过程:转换(Transformation)和作业(Job)。转换是一个包含了数据处理步骤的容器,比如数据的清洗、转换、聚合等。转换通常处理实时数据流,适用于批量操作。
一个转换通常包含以下核心组件:
- **输入**: 数据输入步骤,如表输入、CSV文件输入、数据库查询等。
- **处理**: 数据处理步骤,如选择、过滤、映射、聚合、排序等。
- **输出**: 数据输出步骤,如表输出、文本文件输出、电子邮件输出等。
一个转换的逻辑流程通常如下:
1. **获取数据**: 从一个或多个数据源中获取数据。
2. **数据转换**: 对获取的数据执行各种转换,如数据类型转换、字段重命名、条件过滤、记录合并等。
3. **加载数据**: 将处理后的数据发送到目标系统,如数据库、文件系统或消息队列。
### 3.1.2 使用Kettle实现数据抽取、转换和加载
Kettle中创建转换的基本步骤大致如下:
1. **打开Spoon界面**: 启动 Kettle 的图形界面工具 Spoon。
2. **创建新转换**: 在 Spoon 中新建一个转换文件。
3. **添加输入步骤**: 根据需要从不同数据源中添加输入步骤。
4. **插入数据处理步骤**: 根据数据处理需求,添加适当的处理步骤,如计算器、选择、排序等。
5. **添加输出步骤**: 将处理后的数据输出到目标系统。
每个步骤都涉及到对数据操作的特定细节,例如,在数据转换步骤中,可以创建一个公式来计算新字段的值,或者使用过滤器删除不需要的记录。
```shell
# 示例:使用 kettle 命令行工具执行转换
pan.sh -file="/path/to/transformation.ktr" -level=Basic -progress=5000 -log="/path/to/logfile.log"
```
参数说明:
- `-file`: 指定转换文件的路径。
- `-level`: 设置日志级别。
- `-progress`: 日志输出频率。
- `-log`: 指定日志文件的路径。
在上述命令执行中,每个组件的功能是通过在 Spoon 中的配置参数来决定的。Kettle 的强大之处在于能够灵活地处理不同来源和格式的数据,使得数据工程师能够快速构建出高效的数据流转流程。
## 3.2 Hive批量插入方法论
### 3.2.1 Hive的批量插入技术概述
Hive 是一个构建在 Hadoop 上的数据仓库工具,提供了类 SQL 查询语言 HiveQL。HiveQL 使得大数据的统计分析变得简单,但它本身不是为实时处理设计的。在处理批量数据时,Hive 提供了多种高效的数据插入技术,包括批量加载数据到表中。
Hive 批量插入技术的优点包括:
- **性能提升**: 批量加载数据相比单条插入可以大幅提升性能。
- **低延迟**: 批量数据加载可以降低数据到达的延迟。
- **资源优化**: 减少了 MapReduce 作业的启动次数,优化了资源使用。
### 3.2.2 利用Hive优化数据插入性能
Hive 的数据插入优化可以通过以下几种方法实现:
- **静态分区**: 对数据预先分区,减少数据加载时的负载。
- **压缩数据**: 将数据以压缩格式(如 ORC 或 Parquet)存储,以减少存储空间和提升 I/O 性能。
- **使用Tez或Spark执行引擎**: 这些现代的执行引擎能够更高效地处理数据,提升查询和批量加载的性能。
```sql
-- 示例:Hive批量插入数据
LOAD DATA INPATH '/path/to/input/file' INTO TABLE my_table;
```
在上面的 SQL 命令中,`LOAD DATA INPATH` 是 Hive 提供的批量加载数据的命令,用于将文件系统中的数据加载到 Hive 表中。使用静态分区和压缩技术可以进一步优化这个过程。
## 3.3 Kettle与Hive的整合实践
### 3.3.1 实现Kettle与Hive的连接
要将 Kettle 与 Hive 集成,首先需要确保在 Kettle 的元数据中配置好 Hive 连接。以下是配置步骤:
1. 打开 Kettle 的元数据编辑器。
2. 添加一个新的数据库连接。
3. 选择 Hive 数据库类型。
4. 配置连接参数,如 JDBC URL、Hive 服务器地址、端口、用户名等。
```shell
# 示例:在 kettle 中配置 Hive 连接的配置文件片段
<Database name="Hive" plugin="pentaho-big-data-plugin">
<Type>native</Type>
<DatabaseType>native:Hive</DatabaseType>
<Connection>
<Options>
<Option key="PORT">10000</Option>
<Option key="HOST">localhost</Option>
<Option key="USERNAME">hive_user</Option>
</Options>
<Drivers>
<Driver plugin="pentaho-big-data-plugin" library="libhadoop.so" />
</Drivers>
</Connection>
</Database>
```
在 kettle 中连接到 Hive 后,可以使用它提供的组件进行数据操作。
### 3.3.2 在Kettle中配置Hive批量插入操作
配置好 Hive 连接之后,接下来就是在 Kettle 中使用这个连接执行批量插入。这通常涉及到以下步骤:
1. 从数据源中获取数据。
2. 将数据输入到转换。
3. 在转换中使用 Hive 连接执行批量插入。
```shell
-- 示例:使用 kettle 执行 Hive 批量插入的代码块
INSERT OVERWRITE TABLE my_hive_table SELECT * FROM my_table;
```
上述代码会在 Hive 中执行批量插入操作。在 Kettle 的转换中,可以通过执行 SQL 脚本步骤来调用此语句,或者使用 kettle 的数据库查询组件,通过配置数据库连接和 SQL 语句来完成批量插入操作。
接下来,我们继续深入探讨如何在Kettle与Hive的整合中实现更加高效的数据处理。
# 4. Kettle与Hive高效整合的实践应用
## 4.1 数据清洗与预处理
数据清洗和预处理是任何数据仓库项目中不可或缺的一部分。在这个过程中,数据的完整性和准确性得到保证,以符合后续分析和报告的需求。Kettle作为一个强大的ETL工具,提供了丰富的数据清洗和预处理功能。
### 4.1.1 Kettle中的数据清洗技术
Kettle通过转换(Transformation)组件提供数据清洗功能。转换是一个处理数据的实例,它可以读取输入数据,处理数据,然后输出数据。这些转换可以是简单的,如字段的重命名,也可以是复杂的,如数据的聚合和行的转置。
一个典型的清洗过程可能包括以下步骤:
- **数据去重**: 移除重复的记录以保证数据的唯一性。
- **数据类型转换**: 确保数据类型与预期一致,比如将字符串转换成日期或数值。
- **空值处理**: 填充空值或删除那些无法填补的空值记录。
- **数据格式化**: 将数据格式化为统一的格式,比如日期格式。
- **验证和纠正**: 验证数据的有效性,并进行必要的纠正操作。
在Kettle中实现以上步骤的示例代码如下:
```xml
<transformation>
<name>清洗数据</name>
<step>
<name>读取数据</name>
<class>TableInput</class>
<!-- 详细参数配置 -->
</step>
<step>
<name>数据清洗</name>
<class>DataClean</class>
<!-- 配置清洗规则 -->
</step>
<hop>
<from>读取数据</from>
<to>数据清洗</to>
</hop>
</transformation>
```
### 4.1.2 预处理数据与Hive表结构匹配
一旦数据经过清洗,下一步是确保它们可以被整合进Hive的数据仓库架构中。Hive中的表通常与传统关系数据库系统中的表结构有所差异。因此,可能需要对数据进行额外的处理,比如列转换、分组或聚合等操作,来确保数据与Hive表结构相匹配。
以Hive表结构创建的示例代码如下:
```sql
CREATE TABLE IF NOT EXISTS customer_dim (
customer_id INT,
customer_name STRING,
join_date TIMESTAMP
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;
```
这一步骤关键在于能够理解数据如何流动和转换,因此在实际操作中,需要有对数据流向的深入了解。Kettle的转换组件可以配置相应的脚本或逻辑来处理复杂的转换需求,确保数据最终可以被Hive所接收并存储。
## 4.2 数据批处理与分析
大数据环境下,数据批处理与分析是数据仓库的核心功能。在处理海量数据时,高效的数据批处理技术尤为关键。
### 4.2.1 分析批量数据的技术方法
批量数据分析的技术方法包括:
- **批处理**: 利用Hadoop的MapReduce进行分布式计算。
- **SQL查询**: 使用HiveQL执行大规模数据集上的查询操作。
- **机器学习**: 在Hive中实现数据挖掘与预测分析。
使用HiveQL执行数据分析的示例代码如下:
```sql
SELECT
customer_id,
COUNT(*) as purchase_count
FROM
sales_data
GROUP BY
customer_id
ORDER BY
purchase_count DESC
LIMIT 10;
```
### 4.2.2 利用Hive进行大数据分析的优势
Hive的一个主要优势是能够利用Hadoop生态系统,提供高度可扩展的存储和计算能力。它可以处理PB级别的数据量,并且对于大规模数据集的分析操作提供了优化,如分区、桶化等。HiveQL在语法上与传统SQL类似,使得数据分析师能够使用熟悉的SQL来处理非关系型数据。
使用Hive进行数据分析的流程图可以形象展示其过程:
```mermaid
graph LR
A[数据准备] --> B[数据加载到Hive]
B --> C[数据转换]
C --> D[数据分析]
D --> E[结果存储]
```
## 4.3 性能调优与监控
性能调优与监控是确保数据仓库高效运行的关键。在数据处理、ETL作业执行和数据分析过程中,性能调优和监控显得尤为重要。
### 4.3.1 Kettle和Hive的性能优化策略
性能优化可能包括:
- **硬件升级**: 增加节点、使用SSD存储等。
- **软件调优**: 对Kettle和Hive进行配置优化,如内存分配、线程数调整等。
- **查询优化**: 优化HiveQL语句,减少数据倾斜,利用索引等。
以Kettle为例,性能优化可以通过调整执行日志级别来减少I/O开销:
```properties
# kettle执行日志级别配置
log_level=Basic
```
### 4.3.2 实时监控与故障排除技巧
实时监控确保数据仓库能够稳定运行。Kettle提供了日志记录功能,可以记录执行过程中的详细信息,这对于故障排除非常有帮助。
Kettle日志记录的配置示例:
```xml
<log_handler>
<name>日志处理</name>
<class>org.pentaho.di.core.logging.Log4jLogHandler</class>
<file_name>log/kettle.log</file_name>
<level>Basic</level>
</log_handler>
```
对于故障排除,要关注性能监控工具提供的各种指标,如处理速度、内存使用情况、任务失败次数等。及时响应监控工具的报警,并对遇到的问题进行根本原因分析和解决。
监控工具的配置示例:
```properties
# 监控工具配置
# 性能监控工具URL
performance_monitor_url=http://localhost:8080
```
监控数据可视化展示,有助于快速理解系统的实时状态和性能趋势:
| 性能指标 | 平均值 | 最小值 | 最大值 | 警告阈值 |
|---------|--------|--------|--------|-----------|
| CPU 使用率 | 45% | 10% | 85% | 75% |
| 内存使用 | 75% | 30% | 95% | 85% |
| 磁盘 I/O | 50% | 10% | 90% | 80% |
| 网络流量 | 15MB/s | 1MB/s | 100MB/s | 50MB/s |
通过这些详细分析和实际操作,我们可以确保Kettle与Hive整合后的数据仓库能够高效运行,满足企业的数据处理和分析需求。
# 5. 案例研究:Kettle与Hive整合的高级应用场景
## 5.1 大数据ETL流程优化案例
在大数据处理场景中,ETL(抽取、转换、加载)流程的优化对于整个数据处理效率至关重要。本小节将对比传统ETL工具与Kettle的不同,并探讨一个案例,说明Kettle与Hive整合后的优化步骤和实际效果。
### 5.1.1 传统ETL与Kettle的对比分析
传统ETL工具通常是重型、付费软件,它们提供了一个成熟的平台,支持复杂的数据转换和丰富的数据源连接器。然而,当面对大数据量和多样化数据源时,传统的ETL工具可能会遇到性能瓶颈和高额成本问题。
相比之下,Kettle作为一个轻量级且开源的ETL工具,它在性能和成本上提供了另一种选择。Kettle支持大规模并行处理,并且可以通过插件扩展连接到不同的数据源。它的设计目标是实现数据的有效整合,同时保持了易于使用的特性。
### 5.1.2 案例中Kettle与Hive整合的步骤和效果
在某大数据处理的案例中,通过整合Kettle与Hive,我们取得了以下优化效果:
- **大规模数据处理优化**:通过Kettle的并行处理能力,数据转换过程从单线程执行变为支持多线程和多任务并发执行,显著缩短了数据加载时间。
- **实时数据流处理**:结合Hive的流式处理机制,使得实时数据可以在几秒内被转换并加载到Hive表中,大大提高了数据的实时性。
- **成本节约**:Kettle的开源性质减少了项目成本,而Hive作为数据仓库的组件,有效地利用了Hadoop的集群计算能力,进一步节约了成本。
## 5.2 流式数据处理与实时分析
### 5.2.1 介绍流式数据处理的技术背景
流式数据处理是指实时或近实时地处理连续不断流入的数据。与传统的批量处理相比,流处理需要更快速的响应能力和更高的数据吞吐量。在大数据应用场景中,流处理能够即时分析数据,快速做出决策。
### 5.2.2 Kettle和Hive在实时分析中的应用
Kettle可以与Kafka等消息系统集成,实现数据流的实时抽取。Kettle通过特定的步骤(Steps)和转换(Transformations)来处理和转换这些实时数据流。比如使用"插入/更新"步骤来将数据流插入到Hive表中。
在Hive端,可以配置Hive表以启用流式插入,这样数据可以直接写入Hive表中。Hive的动态分区和分区裁剪功能可以进一步优化处理流程,使得实时分析更加高效。
## 5.3 多数据源整合与数据仓库建设
### 5.3.1 多数据源整合的策略和挑战
在构建企业级数据仓库时,通常需要整合来自不同系统的数据。整合多个数据源不仅涉及到数据的合并和转换,还需要考虑数据的一致性、完整性和时效性。这些数据源可能包括传统关系数据库、NoSQL数据库、日志文件以及各种API服务。
整合过程中的主要挑战包括数据格式的异构性、数据质量的管理、数据同步的实时性以及系统的可扩展性。
### 5.3.2 Kettle与Hive在构建数据仓库中的角色
Kettle提供了丰富且强大的组件来处理多数据源整合。通过使用"数据库连接"步骤,Kettle可以连接到各种类型的数据库和系统。在数据转换阶段,Kettle可以执行清洗、匹配和数据整合等操作。
在将数据整合到Hive时,Kettle利用其"输出到Hive"步骤,可以有效地将清洗和转换后的数据加载到Hive表中。在Hive端,可以利用Hive的SQL能力进行进一步的数据分析和汇总。
## 小结
通过本章节的案例研究,我们可以看到Kettle与Hive整合在多种高级应用场景中的强大作用。不论是进行大数据ETL流程的优化,还是实现流式数据处理和实时分析,甚至在构建复杂的数据仓库中,Kettle与Hive都提供了一套高效的解决方案。这为数据工程师提供了强大的工具集,以应对不断增长的数据挑战。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了使用 Kettle 批量插入 Hive2 时遇到的表输出速度慢问题。通过一系列文章,专家们分析了导致这一问题的根本原因,并提出了优化策略。专栏涵盖了以下主题:
* 性能挑战的剖析
* Hive2 批量处理的最佳实践
* Kettle 在大数据环境中的应用
* 批量插入速度优化策略
* 实操指南和常见问题解答
* Kettle 与 Hive2 的协同工作
* 性能分析和优化指南
* 数据高效批量插入的策略和技巧
通过阅读本专栏,数据工程师和分析师可以了解如何优化 Kettle 批量插入 Hive2 的性能,从而提升数据处理速度和效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【IBIS模型深度剖析】:揭秘系统级仿真的核心应用技巧
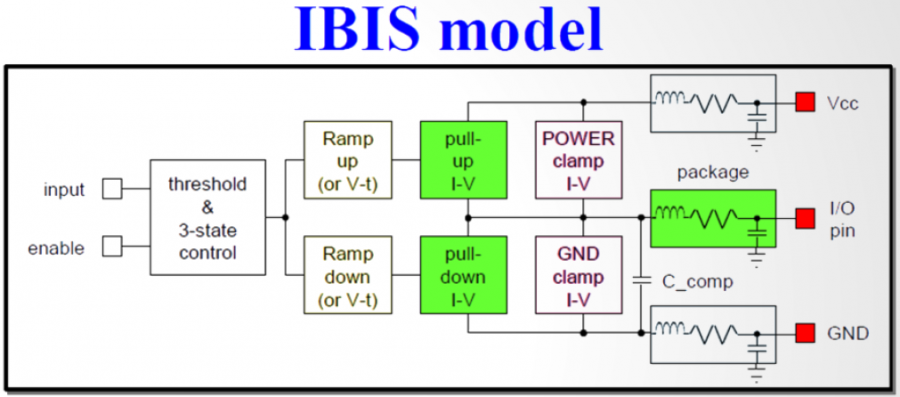
# 摘要
IBIS模型作为电子工程领域中用于描述集成电路输入/输出(I/O)特性的行业标准模型,对于提高信号完整性和电磁兼容性(EMI/EMC)分析具有重要意义。本文首先概述了IBIS模型的基础知识和理论基础,涵盖了其基本原理、文件结构以及关键参数的解析。接着深入探讨了IBIS模型在系统级仿真中的具体应用,特别是在信号完整性分析和EMI预估方面的效用。此外,本文还介绍了I
【TwinCAT 2.0 速成课程】:0基础也能快速上手TwinCAT系统
# 摘要
本文详细介绍了TwinCAT 2.0系统的概述、安装配置、基础编程、高级应用技巧以及实际项目应用,并对TwinCAT 3.0与2.0进行了对比,同时提供了丰富的学习资源和社区支持信息。通过对系统需求、安装步骤、项目配置、编程环境和语言、多任务编程、实时数据监控、故障诊断以及与其他系统的集成等方面的系统性阐述,本文旨在为工程师提供从入门到精通的完整指南。本论文强调了TwinCAT 2.0在实际工业自动化项目中的应用效果,分享了优化与改进建议,并展望了TwinCAT 3.0的发展方向及其在工业4.0中的应用潜力。
# 关键字
TwinCAT 2.0;系统安装;编程环境;多任务编程;实时
【忘记ESXi密码怎么办】:解决方法大全及预防策略
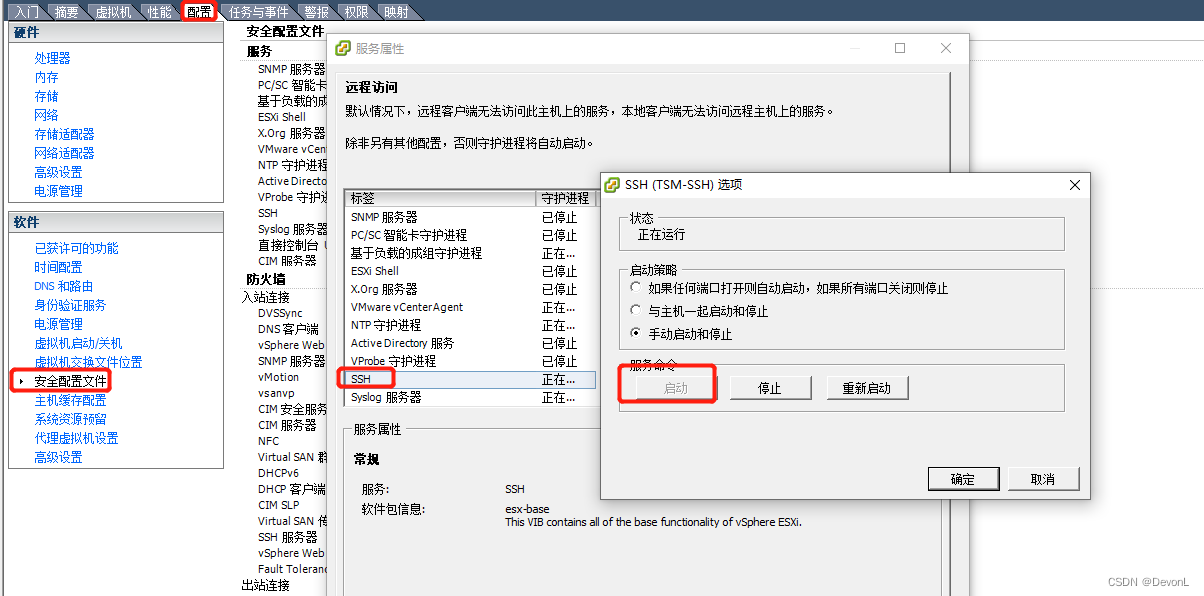
# 摘要
ESXi密码重置是一个关键环节,涉及系统安全性和管理便利性。本文全面介绍了ESXi密码重置的基本概念、理论基础和实践指南,阐述了密码在ESXi系统中的作用、安全性以及最佳实践。文中详细讲解了本地和远程密码重置的多种方法,并介绍了使用第三方工具和脚本以及ESXi Shell和API的高级技术。最后,文章探讨了系统安全加固和密码管理的预防策略,包括禁用不必要的服务、定期审计和多因素认证,以提高整体安
深入解析系统需求分析:如何挖掘检查发货单的深层逻辑

# 摘要
系统需求分析是软件工程的关键阶段,涉及理解和记录系统用户的实际需求。本文首先强调了需求分析的重要性并介绍了相应的方法论,随后探讨了理论基础,包括需求分类、需求工程原则、需求收集的技术和工具,以及需求分析与建模的方法。通过对发货单业务逻辑的具体分析,本文详细描述了需求的搜集和验证过程,并针对深层逻辑进行了探究和实践。文章最后讨论了需求分析过程中遇到的挑战,并对未来发展进行了展望,着重提及了敏捷方法和人工智能技术在需求分析
从零开始的图结构魔法:简化软件工程复杂性的视觉策略
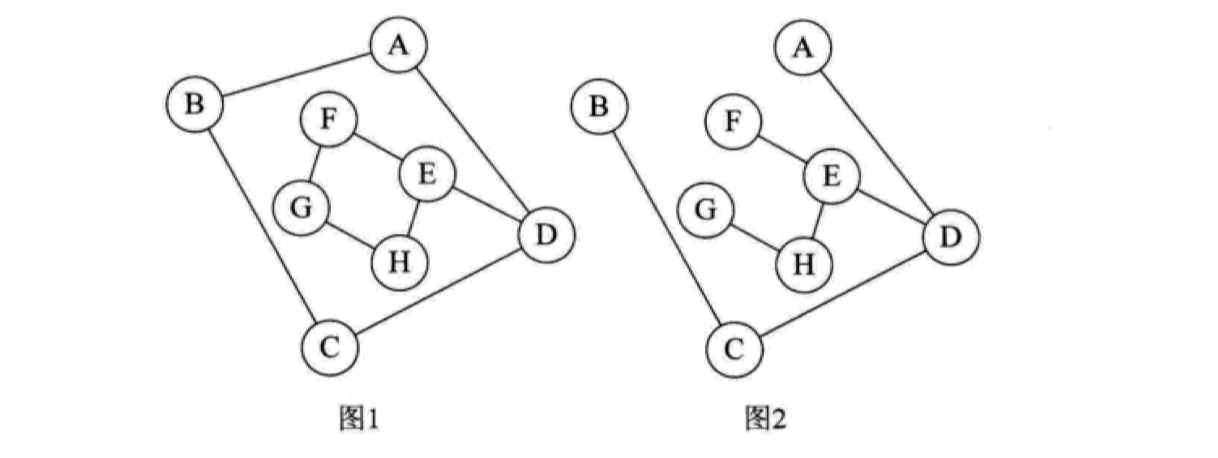
# 摘要
图结构作为一种强大的数据组织方式,在软件工程、系统架构、网络分析等多个领域发挥着至关重要的作用。本文旨在深入探讨图结构的基础理论、不同类型以及在软件工程中的实际应用。文章从图结构的基础概念和类型出发,阐述了其关键定理与算法基础,并详细介绍了图结构在代码管理、系统架构设计、测试与部署流程优化中的应用。此外,还
【泛微OA-E9安全机制全解析】:API安全实践与防护策略的权威指南

# 摘要
本文对泛微OA-E9平台的API安全机制进行了全面分析,涵盖了API安全的基础理论、泛微OA-E9的API安全实施以及安全防护策略的未来趋势。首先介绍了API面临的主要威胁和防护原理,包括认证授权、数据加密传输和安全审计监控。随后,文章深入探讨了泛微OA-E9平台如何通过用户身份认证、权限管理、数据保护、日志审计和异常行为检测等机制确保API的安全。此外,本文分享了泛微OA-E9平台
软件开发安全:CISSP理解深度与生命周期管理
# 摘要
随着信息技术的迅速发展,软件开发安全成为企业和组织的重要关注点。本文系统地概述了CISSP在软件开发生命周期中的安全管理实践,包括安全集成、风险评估、测试与漏洞管理等方面。详细探讨了应用安全框架、加密技术、第三方组件管理等核心应用安全实践,并阐述了在软件维护与部署中,如何通过安全配置、应急响应、部署策略和更新管理来维护软件安全。最后,本文展望了DevOps、人工智能、机器学习以及隐私保护等技术在软件开发安全领域的未来趋势,强调了企业在应对全球性合规性挑战时的策略和应对措施。
# 关键字
CISSP;软件开发安全;风险管理;安全测试;应用安全框架;数据保护;DevOps;AI/ML应
从零基础到数据分析专家:Power Query五步精通法

# 摘要
本文旨在全面介绍Power Query工具及其在数据处理领域的应用。从基础的数据清洗与转换技巧讲起,文章逐步深入至高级数据处理方法、数据整合与连接的策略,以及进阶应用中的参数化查询与错误处理。特别在数据分析实战案例分析章节,本文展示了Power Query如何应用于实际业务场景和数据可视化,以支持企业决策制定。通过具体案例的分析和操作流程的阐述,本文不仅提供了理论知识,也提供了实用
【故障排除】nginx流媒体服务:快速定位与解决常见故障
# 摘要
随着流媒体服务的快速发展,Nginx已成为部署这些服务的流行选择。本文旨在概述Nginx流媒体服务的基本配置、性能优化和故障排查方法。首先介绍Nginx的基础安装、配置和流媒体模块集成。随后,文章重点讨论了性能优化策略,包括性能监控、日志分析以及常见问题的解决方法。最后,本文详细分析了故障排查的理论基础、实用技巧以及高级故障处理技术,并结合真实案例深入剖析故障解决过程中的经验教训
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )