Flask中的RESTful API设计与实现
发布时间: 2024-01-26 06:10:08 阅读量: 37 订阅数: 44 

Python-Frest又一个Flask实现的RESTful接口框架
# 1. 介绍RESTful API
### 1. 什么是RESTful API
RESTful API(Representational State Transfer)是一种软件架构风格,通过使用HTTP协议中的GET、POST、PUT、DELETE等方法,来实现对资源的增删改查操作。它的设计原则简单明了,易于扩展和维护,因此在Web开发中广泛应用。
RESTful API的核心思想就是将服务器上的资源以URL的形式暴露出来,客户端通过HTTP协议访问这些URL,进行数据的读写操作。
### 2. RESTful API的优势及应用场景
RESTful API具有以下优势:
- 简单易学:RESTful API的设计原则简单清晰,易于理解和学习。
- 可扩展性好:由于使用了HTTP协议,RESTful API能够很好地与现有的Web技术和工具进行集成和扩展。
- 状态无关性:RESTful API通过URL和HTTP方法来描述资源,不保存客户端状态,提高了可靠性和可伸缩性。
RESTful API广泛应用于各种Web开发场景,特别适用于以下场景:
- 移动端应用:RESTful API能够为移动端提供高效、可靠的数据访问接口。
- 微服务架构:RESTful API适合于构建分布式、松耦合的微服务架构。
- 后端服务开发:RESTful API能够为前端开发人员提供友好的接口,加速前后端分离开发。
通过以上介绍,我们了解了RESTful API的基本概念、设计原则以及应用场景。下一章将介绍Flask框架的基础知识,为实现RESTful API做好准备。
# 2. Flask基础
Flask是一个使用Python编写的微型Web框架,它简洁而灵活,适用于构建小型到中型的Web应用程序。以下是使用Flask构建Web应用程序的基本知识。
### 1. 简介Flask框架
Flask是一个轻量级的Web框架,它的设计理念是保持简单和易扩展。Flask不内置具体的数据库、认证机制或其他功能性组件,而是通过扩展来提供这些功能。这种设计使得Flask可以根据具体需求灵活地选择扩展,简化了框架本身的复杂性。
Flask具有以下特点:
- 简洁:Flask的核心只包含了一个用于构建Web应用的核心库,它具有良好的代码组织结构和可读性,易于理解和学习。
- 易扩展:通过使用Flask的扩展,可以轻松地集成数据库、表单验证、认证和授权等功能。
- RESTful友好:Flask对RESTful API的支持很好,可以通过简单的装饰器来定义不同URL路径对应的请求方法,使得API的设计和实现更加简单和直观。
### 2. 使用Flask构建Web应用程序的基本知识
使用Flask构建Web应用程序需要先安装Flask库。可以使用pip命令进行安装:
```python
pip install flask
```
安装完成后,就可以在Python代码中引入Flask库:
```python
from flask import Flask
```
接下来,我们需要创建一个Flask应用实例:
```python
app = Flask(__name__)
```
然后,我们可以通过装饰器来定义URL路径对应的请求方法。例如,以下代码定义了一个简单的路由规则,将根路径("/")的GET请求映射到一个视图函数:
```python
@app.route('/')
def index():
return 'Hello, Flask!'
```
最后,我们需要运行应用,使其监听在指定的主机和端口上:
```python
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
```
以上就是使用Flask构建Web应用程序的基本知识。通过Flask的简洁和灵活性,我们可以快速构建出具有各种功能的Web应用程序。在接下来的章节中,我们将介绍如何使用Flask构建RESTful API。
# 3. RESTful API设计原则
在设计和实现RESTful API时,需要遵循一些基本原则和最佳实践,以确保API的可读性、可维护性和可扩展性。
### 1. 资源的命名与URI设计
在RESTful API中,每个资源都应该有一个唯一的标识符,通常使用URI来表示。在设计URI时,应该遵循以下原则:
- 使用**名词**而不是动词来命名资源,比如使用`/users`代表用户资源,而不是使用`/getUser`。
- 尽量使用**复数形式**来表示集合资源,比如使用`/users`代表用户集合资源,使用`/users/{i

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python Web框架中的Flask》专栏深入介绍了Flask框架的各个方面以及其在开发Web应用程序中的应用。首先,专栏详细解析了Flask模板引擎的使用方法,包括模板的创建、变量的传递以及常用的模板语法。接着,专栏讲解了Flask中静态文件的管理,包括如何正确配置和使用静态文件,以及如何优化静态文件的加载速度。此外,专栏还介绍了Flask中表单的处理与WTForms的使用,让读者能够轻松地实现表单的验证和数据处理。最后,专栏探讨了Flask中机器学习集成与模型部署的方法,帮助读者了解如何将机器学习模型整合到Flask应用中并进行部署。无论是初学者还是有一定经验的开发者,本专栏都能够提供全面而实用的Flask知识,帮助读者构建高效、功能丰富的Web应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【GSEA基础入门】:掌握基因集富集分析的第一步

# 摘要
基因集富集分析(GSEA)是一种广泛应用于基因组学研究的生物信息学方法,其目的是识别在不同实验条件下显著改变的生物过程或通路。本文首先介绍了GSEA的理论基础,并与传统基因富集分析方法进行比较,突显了GSEA的核心优势。接着,文章详细叙述了GSEA的操作流程,包括软件安装配置、数据准备与预处理、以及分析步骤的讲解。通过实践案例分析,展示了GSEA在疾病相关基因集和药物作用机制研究中的应用,以及结果的
【ISO 14644标准的终极指南】:彻底解码洁净室国际标准
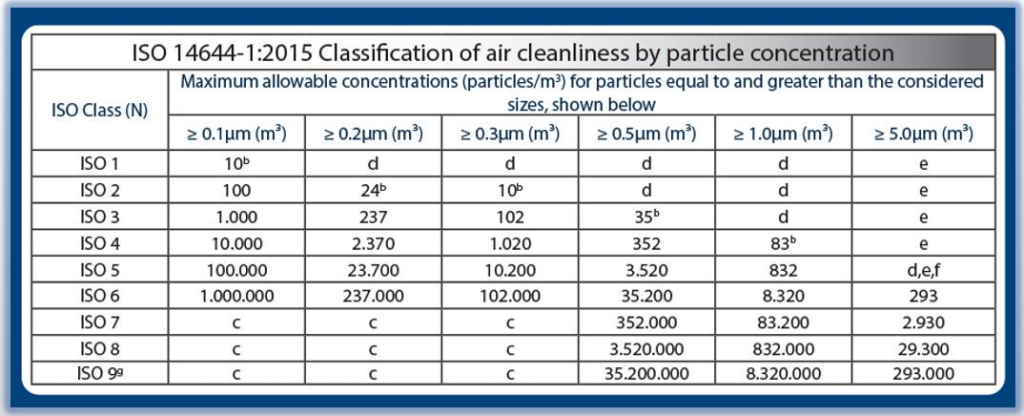
# 摘要
本文系统阐述了ISO 14644标准的各个方面,从洁净室的基础知识、分类、关键参数解析,到标准的详细解读、环境控制要求以及监测和维护。此外,文章通过实际案例探讨了ISO 14644标准在不同行业的实践应用,重点分析了洁净室设计、施工、运营和管理过程中的要点。文章还展望了洁净室技术的发展趋势,讨论了实施ISO 14644标准所
【从新手到专家】:精通测量误差统计分析的5大步骤

# 摘要
测量误差统计分析是确保数据质量的关键环节,在各行业测量领域中占有重要地位。本文首先介绍了测量误差的基本概念与理论基础,探讨了系统误差、随机误差、数据分布特性及误差来源对数据质量的影响。接着深入分析了误差统计分析方法,包括误差分布类型的确定、量化方法、假设检验以及回归分析和相关性评估。本文还探讨了使用专业软件工具进行误差分析的实践,以及自编程解决方案的实现步骤。此外,文章还介绍了测量误差统计分析的高级技巧,如误差传递、合
【C++11新特性详解】:现代C++编程的基石揭秘
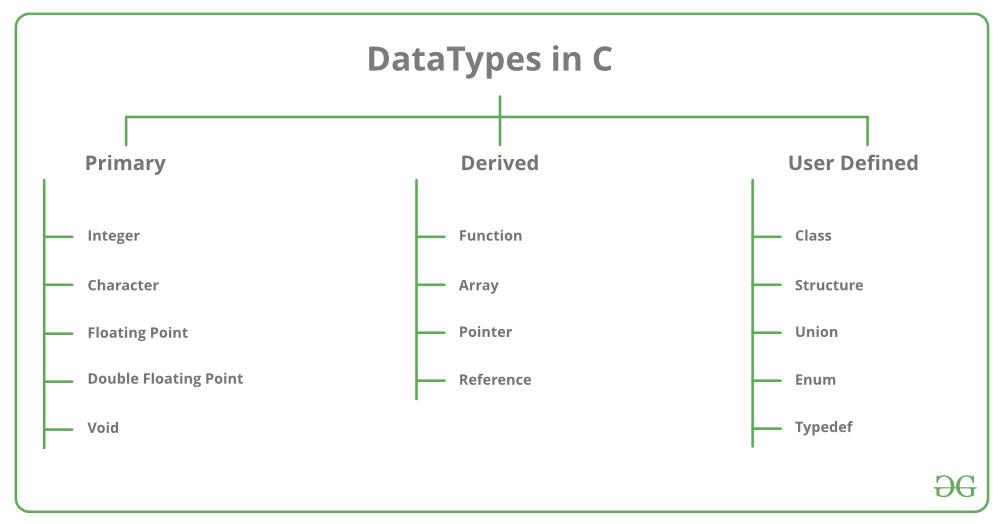
# 摘要
C++11作为一种现代编程语言,引入了大量增强特性和工具库,极大提升了C++语言的表达能力及开发效率。本文对C++11的核心特性进行系统性概览,包括类型推导、模板增强、Lambda表达式、并发编程改进、内存管理和资源获取以及实用工具和库的更新。通过对这些特性的深入分析,本文旨在探讨如何将C++11的技术优势应用于现代系统编程、跨平台开发,并展望C++11在未来
【PLC网络协议揭秘】:C#与S7-200 SMART握手全过程大公开
# 摘要
本文旨在详细探讨C#与S7-200 SMART PLC之间通信协议的应用,特别是握手协议的具体实现细节。首先介绍了PLC与网络协议的基础知识,随后深入分析了S7-200 SMART PLC的特点、网络配置以及PLC通信协议的概念和常见类型。文章进一步阐述了C#中网络编程的基础知识,为理解后续握手协议的实现提供了必要的背景。在第三章,作者详细解读了握手协议的理论基础和实现细节,包括数据封装与解析的规则和方法。第四章提供了一个实践案例,详述了开发环境的搭建、握手协议的完整实现,以及在实现过程中可能遇到的问题和解决方案。第五章进一步讨论了握手协议的高级应用,包括加密、安全握手、多设备通信等
电脑微信"附近的人"功能全解析:网络通信机制与安全隐私策略
# 摘要
本文综述了电脑微信"附近的人"功能的架构和隐私安全问题。首先,概述了"附近的人"功能的基本工作原理及其网络通信机制,包括数据交互模式和安全传输协议。随后,详细分析了该功能的网络定位机制以及如何处理和保护定位数据。第三部分聚焦于隐私保护策略和安全漏洞,探讨了隐私设置、安全防护措施及用户反馈。第四章通过实际应用案例展示了"附近的人"功能在商业、社会和
Geomagic Studio逆向工程:扫描到模型的全攻略
# 摘要
本文系统地介绍了Geomagic Studio在逆向工程领域的应用。从扫描数据的获取、预处理开始,详细阐述了如何进行扫描设备的选择、数据质量控制以及预处理技巧,强调了数据分辨率优化和噪声移除的重要性。随后,文章深入讨论了在Geomagic Studio中点云数据和网格模型的编辑、优化以及曲面模型的重建与质量改进。此外,逆向工程模型在不同行业中的应用实践和案例分析被详细探讨,包括模型分析、改进方法论以及逆向工程的实际应用。最后,本文探
大数据处理:使用Apache Spark进行分布式计算

# 摘要
Apache Spark是一个为高效数据处理而设计的开源分布式计算系统。本文首先介绍了Spark的基本概念及分布式计算的基础知识,然后深入探讨了Spark的架构和关键组件,包括核心功能、SQL数据处理能力以及运行模式。接着,本文通过实践导向的方式展示了Spark编程模型、高级特性以及流处理应用的实际操作。进一步,文章阐述了Spark MLlib机器学习库和Gr
【FPGA时序管理秘籍】:时钟与延迟控制保证系统稳定运行

# 摘要
随着数字电路设计的复杂性增加,FPGA时序管理成为保证系统性能和稳定性的关键技术。本文首先介绍了FPGA时序管理的基础知识,深入探讨了时钟域交叉问题及其对系统稳定性的潜在影响,并且分析了多种时钟域交叉处理技术,包括同步器、握手协议以及双触发器和时钟门控技术。在延迟控制策略方面,本文阐述了延
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )