C++17结构化绑定:全新数据访问模式,简化代码的艺术
发布时间: 2024-10-22 09:48:33 阅读量: 29 订阅数: 42 

# 1. C++17结构化绑定的概述
C++17引入了结构化绑定这一特性,极大地简化了多返回值的处理,提高了代码的可读性和易用性。它允许开发者在一个简洁的语句中,将一个对象的多个成员分别绑定到一组变量上。尽管在C++17之前,可以使用`std::tie`来实现类似的功能,但结构化绑定的引入使得这一过程更加直观和方便。
结构化绑定不仅限于内建类型和数组,还支持自定义类型,甚至在某些情况下可以用于改善模板编程。它为C++程序员提供了一种新的方式,来处理复杂的函数返回值或容器元素,从而使得代码更加清晰和优雅。
总的来说,结构化绑定是C++17中一个重要的改进,它反映了语言持续进化以适应现代编程实践的趋势。开发者可以利用这一特性来简化代码,减少错误,并提高整体的开发效率。在接下来的章节中,我们将深入探讨结构化绑定的语法、原理、适用场景以及在实际编程中的应用。
# 2. 结构化绑定的语法和原理
### 2.1 结构化绑定的语法细节
#### 2.1.1 基本声明和初始化方式
结构化绑定是C++17引入的一种便捷特性,它允许程序员在一行代码中分解复合值(如数组、结构体或std::tuple)并将其成员赋给多个变量。基本的结构化绑定语法非常简洁,如下所示:
```cpp
auto [x, y] = some_tuple;
```
这里,`some_tuple`是一个已存在的tuple对象,而`x`和`y`是新声明的变量,它们分别接收`some_tuple`的第一个和第二个元素。值得一提的是,使用`auto`关键字可以自动推断绑定变量的类型,这使得代码更加简洁。
结构化绑定同样支持引用,允许直接操作原始数据:
```cpp
auto& [x, y] = some_tuple; // x和y是对some_tuple元素的引用
```
此外,结构化绑定还可以用于初始化命名空间中的对象,这为管理多个返回值提供了极大的便利。
```cpp
std::pair<int, std::string> createPair();
auto [a, b] = createPair(); // 使用结构化绑定初始化a和b
```
#### 2.1.2 与传统数据访问方式的对比
在结构化绑定出现之前,程序员通常需要分别声明每个变量,并通过索引或成员访问操作符来访问容器或对象的数据。例如:
```cpp
std::tuple<int, int> createTuple();
int x, y;
std::tie(x, y) = createTuple(); // 使用std::tie进行手动分解
```
这种方法不仅代码更长,而且易出错,尤其是当涉及到复杂数据结构时。结构化绑定通过简化语法显著提高了代码的可读性和易用性。
### 2.2 结构化绑定背后的机制
#### 2.2.1 编译器如何处理结构化绑定
在编译阶段,编译器会为每个结构化绑定创建一个实现细节类,这个类包含了用于存储数据的私有成员变量和公共构造函数。每个变量都是这个类的公共成员变量。例如:
```cpp
struct StructuredBindingHolder {
int x;
int y;
StructuredBindingHolder(int x, int y) : x(x), y(y) {}
};
auto [x, y] = some_tuple;
// 等价于:
StructuredBindingHolder tmp = std::make_from_tuple<StructuredBindingHolder>(some_tuple);
int x = tmp.x;
int y = tmp.y;
```
编译器生成的这个实现细节类使得结构化绑定能够像其他变量一样正常工作。
#### 2.2.2 结构化绑定与性能影响
关于性能,结构化绑定没有直接的性能开销。实际上,它提供了一种清晰且简洁的方式来访问数据,有时甚至可以通过减少错误和减少代码量来间接提高性能。编译器在处理结构化绑定时,会尝试生成最优的代码,避免不必要的开销。
### 2.3 结构化绑定的限制和适用场景
#### 2.3.1 目前的限制和未来展望
尽管结构化绑定在很多场景下都非常有用,但它也有一些限制。目前,结构化绑定只能用于具有`public`数据成员的聚合类型或具有`std::tuple_size`和`std::get`特化的类型。此外,结构化绑定不能直接用于访问私有成员或保护成员。
随着C++标准的演进,未来的版本可能会对这些限制有所突破,例如提供对私有成员的结构化绑定访问。
#### 2.3.2 最佳实践和注意事项
在使用结构化绑定时,需要注意以下几点:
- 当绑定到引用时,原始数据的生命周期必须得到保证,因为绑定的变量只是对原始数据的引用。
- 尽量不要对带有`const`或`volatile`限定符的数据使用结构化绑定,以避免潜在的编程错误。
- 注意重载`operator,`(逗号操作符)和`operator&`(取地址操作符)的类型,可能会导致意外的编译错误。
- 在多线程程序中,结构化绑定简化了并发数据的访问,但仍然需要适当使用同步机制以避免竞态条件。
为了确保最佳实践,应当进行充分的测试,并确保代码的可维护性和可读性。
通过掌握结构化绑定的语法和背后原理,以及了解它的限制和最佳实践,程序员可以更好地在实际编程中利用这一特性,提高代码质量并减少开发时间。接下来,我们将探讨结构化绑定在实际编程中的应用,包括与容器、自定义类型以及lambda表达式的结合使用。
# 3. 结构化绑定在实际编程中的应用
## 3.1 结构化绑定与容器
### 3.1.1 容器迭代器的结构化绑定
在 C++17 引入结构化绑定之前,使用容器时需要对迭代器的 `std::pair` 或 `std::tuple` 进行访问,这通常会导致冗长的代码和容易出错的命名。结构化绑定提供了一种更简洁直观的方式来访问容器中的元素。
以一个简单的 `std::vector<std::pair<std::string, int>>` 为例,该容器存储了员工的名字和他们的ID。传统方式下,我们可能需要这样编写代码:
```cpp
std::vector<std::pair<std::string, int>> employees = { {"John", 1}, {"Alice", 2} };
for (auto it = employees.begin(); it != employees.end(); ++it) {
std::string name = it->first;
int id = it->second;
// 进行一些操作
}
```
而使用结构化绑定,同样的操作可以这样完成:
```cpp
for (const auto& [name, id] : employees) {
// 进行一些操作
}
```
这种方式不仅代码更简洁,而且提高了可读性。编译器会自动将每个 `pair` 的 `first` 和 `second` 分量分别绑定到 `name` 和 `id`。
### 3.1.2 使用结构化绑定简化容器操作
进一步,结构化绑定的引入也简化了对标准库容器如 `std::map` 和 `std::unordered_map` 的操作。在这些容器中,每个元素都是键值对,使用结构化绑定可以直接获取到键和值:
```cpp
std::map<std::string, int> user_scores = { {"Alice", 100}, {"Bob", 200} };
for (const auto& [user, score] : user_scores) {
std::cout << user << " has a score of " << score << "\n";
}
```
对于 `std::array` 或原生数组,结构化绑定也提供了一个清晰的方式来访问每个元素:
```cpp
std::array<int, 3> numbers = {1, 2, 3};
for (const auto& [i, num] : numbers | std::views::enumerate) {
std::cout << "Index " << i << " has value " << num << "\n";
}
```
这里使用了 C++20 的 `std::views::enumerate`,它是一个范围适配器,可以与结构化绑定一起使用来访问索引和值。
## 3.2 结构化绑定与自定义类型
### 3.2.1 类和结构体的结构化绑定
对于自定义类型,结构化绑定也可以极大地简化代码。考虑一个简单的类,包含多个数据成员:
```cpp
struct Employee {
std::string name;
int id;
double salary;
};
std::vector<Employee> employees = {{"John", 1, 50000.0}, {"Alice", 2, 60000.0}};
```
使用结构化绑定,可以直接将 `Employee` 类的成员直接绑定到变量上:
```cpp
for (const auto& [name, id, salary] : employees) {
std::cout << "Name: " << name << ", ID: " << id << ", Salary: " << salary << "\n";
}
```
这样的代码不仅简洁,而且读起来就像自然语言一样。
### 3.2.2 应用实例:简化数据库查询结果处理
在数据库操作中,结构化绑定可以大幅简化结果处理。考虑以下数据库查询示例,其中从数据库中检索员工信息:
```cpp
// 假设数据库查询返回了如下结构化数据
std::vector<std::tuple<std::string, int, std::string>> query_results;
// 填充数据
```
在C++17之前,我们需要按照如下方式进行处理:
```cpp
for (const auto& result : query_results) {
std::string name = std::get<0>(result);
int id = std::get<1>(result);
std::string department = std::get<2>(result);
// 处理数据
}
```
而结构化绑定使得我们能够直接将查询结果解构为有意义的变量名:
```cpp
for (const auto& [name, id, department] : query_results) {
// 处理数据
}
```
这种方式不仅提高了代码的可读性,也减少了出错的可能性。
## 3.3 结构化绑定与lambda表达式
### 3.3.1 在lambda中使用结构化绑定
Lambda表达式是C++11引入的一种简洁的函数对象创建方式,结构化绑定使得在lambda表达式中使用复杂对象成为可能。举个简单的例子:
```cpp
std::vector<std::pair<std::string, int>> scores = {{"Alice", 100}, {"Bob", 95}};
std::for_each(scores.begin(), scores.end(), [](const auto& [name, score]) {
std::cout << name << " scored " << score << std::endl;
});
```
在本例子中,lambda的参数使用结构化绑定来直接访问每个 `pair` 中的 `name` 和 `score`。
### 3.3.2 结构化绑定与事件驱动编程
结构化绑定还可以用于事件驱动编程的场景,比如在监听某些事件并处理返回的数据时。在某些GUI框架或网络库中,回调函数可能会接收到包含多种数据的元组,通过结构化绑定,可以在回调中直接处理这些数据:
```cpp
// 假设有一个事件监听器,它在接收到一个事件时调用以下函数
void onEvent(const std::tuple<std::string, int>& event) {
const auto& [type, value] = event;
if (type == "data") {
// 根据数据进行处理
std::cout << "Received data with value: " << value << std::endl;
}
}
```
通过这种方式,事件处理代码更加清晰易懂。
结构化绑定的引入,为C++的日常使用带来了巨大的方便。无论是在处理容器数据,还是在定义和使用自定义类型,以及事件驱动编程中,结构化绑定都能提供简洁直观的语法,显著提升了代码的可读性和开发效率。随着C++语言的不断演进,我们可以预见结构化绑定将会在更多场景中发挥重要的作用。
# 4. 结构化绑定在系统编程中的应用
## 4.1 结构化绑定与多线程编程
### 4.1.1 用于线程同步机制的结构化绑定
在多线程编程中,同步机制如互斥锁(mutexes)和条件变量(condition variables)是管理并发访问共享资源的常用工具。传统的线程同步代码可能因为变量多而显得凌乱,而结构化绑定提供了一种更为简洁的访问方式。
```cpp
#include <mutex>
#include <thread>
#include <string>
std::mutex m;
std::string shared_data;
void producer() {
std::string data = "Some data";
std::lock_guard<std::mutex> lock(m);
shared_data = data; // Using structured binding to unpack the value.
}
void consumer() {
std::string data;
std::lock_guard<std::mutex> lock(m);
data = shared_data; // Again, structured binding simplifies access.
// Use data...
}
int main() {
std::thread prod(producer);
std::thread cons(consumer);
prod.join();
cons.join();
}
```
在这个例子中,`std::lock_guard` 负责在构造时自动获取互斥锁,并在析构时释放。通过结构化绑定,`lock_guard` 对象 `lock` 在作用域结束时自动释放锁,并且锁的值可以直接赋给 `data` 变量,使得代码更清晰。
### 4.1.2 提高并发编程效率的实际案例
考虑一个更加复杂的实际案例,例如使用结构化绑定来简化线程池中任务的执行。线程池负责管理一组线程,并将提交给它的任务分配给这些线程执行。
```cpp
#include <thread>
#include <vector>
#include <functional>
#include <tuple>
// A simple task struct to hold a function pointer and its arguments.
struct Task {
std::function<void()> func;
std::tuple<> args;
};
// Thread pool class with a function to distribute tasks to threads.
class ThreadPool {
public:
void DistributeTask(Task task) {
std::lock_guard<std::mutex> lock(mtx);
tasks.push_back(task);
cv.notify_one(); // Notify a waiting thread to start working.
}
// Main function to run the thread pool.
void Run() {
while (true) {
Task task;
{
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, [this] { return !tasks.empty(); });
task = tasks.front();
tasks.pop_front();
}
// Unpack task into function and arguments.
auto [f, args] = task;
f();
}
}
private:
std::mutex mtx;
std::condition_variable cv;
std::deque<Task> tasks;
};
// Example usage of thread pool
int main() {
ThreadPool pool;
pool.DistributeTask({[]{std::cout << "Task 1 executed" << std::endl; }, {}});
pool.DistributeTask({[]{std::cout << "Task 2 executed" << std::endl; }, {}});
// The thread pool will execute tasks concurrently.
return 0;
}
```
在这个例子中,线程池的 `Run` 方法通过等待条件变量 `cv` 来处理任务。它使用结构化绑定来解构任务 `Task`,并直接执行其中的函数 `f`。这使得代码更加紧凑和易于理解,因为任务的每个组成部分都直接对应到其在代码中的使用方式。
## 4.2 结构化绑定与网络编程
### 4.2.1 结构化绑定在套接字编程中的应用
在套接字编程中,经常需要处理多个相关的值,例如地址族、套接字类型和协议等。结构化绑定提供了一种直观的方式来处理这些值。
```cpp
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <iostream>
int main() {
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
std::cerr << "Error creating socket." << std::endl;
return -1;
}
struct sockaddr_in serverAddr;
std::tie(serverAddr.sin_family, serverAddr.sin_port, serverAddr.sin_addr) =
std::make_tuple(AF_INET, htons(8080), inet_addr("***.*.*.*"));
if (bind(sockfd, reinterpret_cast<struct sockaddr*>(&serverAddr), sizeof(serverAddr)) < 0) {
std::cerr << "Error binding to socket." << std::endl;
return -1;
}
listen(sockfd, 3);
// Continue with accepting connections...
return 0;
}
```
这段代码创建了一个TCP套接字,并将地址族(family)、端口号和IP地址用结构化绑定来解包赋值,以初始化 `serverAddr` 结构。这样的处理更加直观,并且减少了几余的赋值语句。
### 4.2.2 网络数据处理的简化策略
在处理网络数据时,经常需要对数据包进行解析。结构化绑定可以用来简化数据包字段的解包过程。
```cpp
#include <netinet/in.h>
#include <arpa/inet.h>
#include <iostream>
#include <tuple>
int main() {
char buffer[256];
// Assume buffer contains a properly formatted IPv4 header
auto [version, ihl, tos, tot_len, id, frag_off, ttl, proto, check, saddr, daddr] =
*reinterpret_cast<std::tuple<int, int, int, int, int, int, int, int, short, uint32_t, uint32_t>*>(buffer);
std::cout << "Version: " << version << "\n";
std::cout << "Header Length: " << ihl << "\n";
// Continue to print out all the other fields...
return 0;
}
```
上述代码演示了如何将接收到的网络数据包,直接解包到相关字段中,使其更加易于管理和访问。当然,实际应用中需要考虑字节序和对齐等问题,但这里仅作为展示结构化绑定语法的应用。
## 4.3 结构化绑定与文件系统
### 4.3.1 文件系统的遍历与数据检索
在文件系统的遍历操作中,通常需要处理多个相关的值,比如文件名和路径。结构化绑定可以提供一种简洁的方法来提取这些信息。
```cpp
#include <filesystem>
namespace fs = std::filesystem;
int main() {
for (const auto& entry : fs::directory_iterator("/path/to/directory")) {
auto [path, status] = entry;
// Use path and status to process the entry.
std::cout << "File name: " << path.filename() << std::endl;
// ...
}
}
```
在这个例子中,`fs::directory_iterator` 的每一个迭代结果都被结构化绑定解包到 `path` 和 `status`。这种语法不仅使代码更易于阅读,而且减少了冗余的变量声明。
### 4.3.2 提高文件处理效率的技巧
文件处理时,可能需要从文件中读取多个值。结构化绑定可以用来简化这一过程。
```cpp
#include <fstream>
#include <tuple>
int main() {
std::ifstream file("data.txt");
std::string line;
while (std::getline(file, line)) {
auto [key, value] = ParseLine(line); // Assume this function returns a std::pair.
// Process the key-value pair.
}
file.close();
}
std::pair<std::string, std::string> ParseLine(const std::string& line) {
// Dummy function to split line into key and value.
std::string key = "default";
std::string value = line;
// Real logic goes here.
return {key, value};
}
```
这个例子演示了如何在处理文本文件时,使用结构化绑定来接收解析后的键值对。通过使用结构化绑定,代码更具有可读性和易管理性。
结构化绑定在系统编程中提供了优雅的方式来处理复杂的多值数据结构,无论是多线程环境下的同步,还是网络和文件系统操作中的数据解包。随着C++编程范式的演进,结构化绑定的这些应用案例正在变得更加普及和高效。
# 5. 探索结构化绑定的边界和未来
## 5.1 结构化绑定在其他编程语言中的应用
### 5.1.1 与C++17特性的对比
在C++17之前,许多其他编程语言已经提供了类似结构化绑定的特性。例如,Python自1.4版本开始就允许迭代字典元素并直接获取键值对,这可以看作是结构化绑定的一种早期形式。Swift语言中的case语句处理枚举时也表现出了结构化绑定的特性,允许开发者直接在case语句中声明对应的常量或变量。
结构化绑定在C++17中的实现,实际上是对这些特性的总结和吸收。与Python和Swift相比,C++的结构化绑定更加严格和类型安全,因为它要求在绑定时必须保证类型的一致性,并且不允许隐式类型转换。
### 5.1.2 其他语言中类似特性的实现和效果
在JavaScript中,ES6引入了解构赋值(Destructuring assignment),它允许从数组或对象中提取数据,并赋值给变量。这一特性与C++的结构化绑定在功能上有相似之处,但形式上更加灵活,因为它不需要声明新的变量,而是可以将已存在的变量解构赋值。
Go语言没有内置类似结构化绑定的特性,但是通过其优秀的并发模型以及通道(channel)和选择器(select)的使用,开发者可以实现高效的数据处理。不过,Go社区对于是否应该添加类似结构化绑定的特性也进行了广泛的讨论。
### 代码示例对比
让我们来看一个简单的代码示例,比较不同语言中结构化绑定或类似特性的使用方式。
Python:
```python
person = {'name': 'John', 'age': 30}
name, age = person['name'], person['age']
print(name, age)
```
Swift:
```swift
struct Person {
let name: String
let age: Int
}
let person = Person(name: "John", age: 30)
let (name, age) = person
print("\(name), \(age)")
```
JavaScript:
```javascript
const person = { name: 'John', age: 30 };
const { name, age } = person;
console.log(name, age);
```
通过对比,我们可以看到不同编程语言在实现类似结构化绑定功能时的异同点。在C++中,结构化绑定是通过`auto`关键字或者具体类型来声明变量,然后直接将结构化数据绑定到这些变量上。
## 5.2 结构化绑定的未来发展和可能的扩展
### 5.2.1 标准库中的进一步应用和集成
随着C++标准的不断演进,结构化绑定在未来版本中可能会有更多集成到标准库中的应用。例如,在处理大量数据时,标准库的算法可以利用结构化绑定来简化代码编写,提供更直观的数据操作方式。一个可能的改进是使得标准库中的迭代器返回的不仅仅是元素本身,还包括一个结构化的数据视图,从而直接绑定到多个变量上。
### 5.2.2 C++20及以后版本的可能改进
C++20带来了诸如概念(Concepts)、协程(Coroutines)等重要特性,结构化绑定也可能在这种新特性中扮演重要的角色。比如,协程中可能会使用结构化绑定来简化状态机的设计,使得异步编程更加直观。
在后续的C++标准中,我们也可能会看到结构化绑定在元编程中的应用,比如在模板元编程中,通过结构化绑定来简化模板参数的传递和处理。
## 5.3 结构化绑定对编程范式的影响
### 5.3.1 现代化C++编程的推进作用
结构化绑定的引入对于C++编程范式产生了积极的推进作用。它鼓励程序员使用更现代的C++特性来编写简洁且类型安全的代码。随着C++17及之后版本的广泛采用,开发者将越来越倾向于使用结构化绑定来简化数据访问,提高代码的可读性和维护性。
### 5.3.2 编程思维模式的转变探讨
结构化绑定不仅仅是一种语法糖,它的引入促使开发者重新思考数据的访问模式,进而可能引发编程思维模式的转变。以前开发者可能习惯于将数据包装在一个或多个对象中,而结构化绑定提供了另外一种思考角度,即直接操作数据本身,而非通过对象间接访问。
这种转变可能会导致开发者更加关注数据本身和数据处理逻辑,而不是过分强调对象的封装和继承。随着函数式编程在C++中的不断推广,结构化绑定作为函数式特性的一部分,可能会和高阶函数、lambda表达式等一起,推动C++向更为函数式和声明式的编程范式发展。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
C++17为C++语言带来了众多激动人心的新特性,引领着现代化编程的新趋势。从结构化绑定到模板编程的升级,再到并行算法的威力和文件系统库的简化,C++17为开发者提供了强大的工具,提升了代码效率和性能。此外,编译时条件逻辑、自动类型推导、变长模板参数包和统一初始化语法等特性,进一步增强了代码简洁性和一致性。函数式编程效率提升、字符串处理新选择、处理任意类型数据和可选值容器等特性,为开发者提供了更多灵活性和表达力。用户定义字面量扩展、非受限联合体和编译器诊断能力增强等特性,则进一步提升了类型安全性和编译器可靠性。总之,C++17的新特性全面提升了C++语言的各个方面,为开发者提供了更强大、更灵活、更易用的编程工具。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【SGP.22_v2.0(RSP)中文版深度剖析】:掌握核心特性,引领技术革新
# 摘要
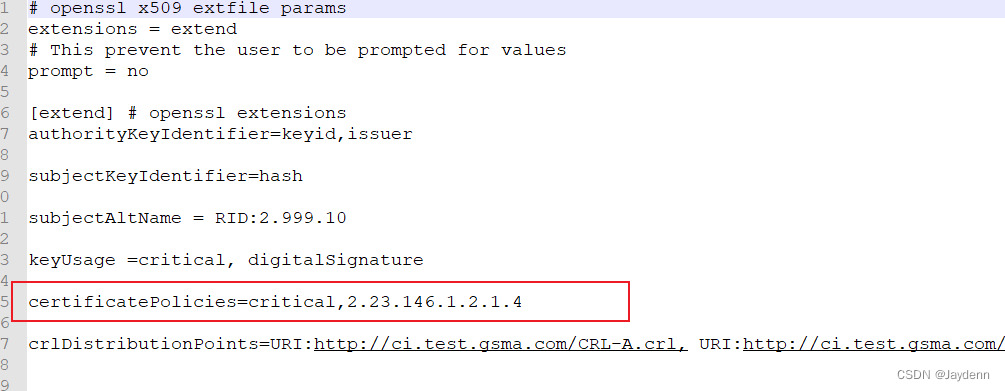
SGP.22_v2.0(RSP)作为一种先进的技术标准,在本论文中得到了全面的探讨和解析。第一章概述了SGP.22_v2.0(RSP)的核心特性,为读者提供了对其功能与应用范围的基本理解。第二章深入分析了其技术架构,包括设计理念、关键组件功能以及核心功能模块的拆解,还着重介绍了创新技术的要点和面临的难点及解决方案。第三章通过案例分析和成功案例分享,展示了SGP.22_v2.0(RSP)在实际场景中的应用效果、
小红书企业号认证与内容营销:如何创造互动与共鸣
# 摘要
本文详细解析了小红书企业号的认证流程、内容营销理论、高效互动策略的制定与实施、小红书平台特性与内容布局、案例研究与实战技巧,并展望了未来趋势与企业号的持续发展。文章深入探讨了内容营销的重要性、目标受众分析、内容创作与互动策略,以及如何有效利用小红书平台特性进行内容分发和布局。此外,通过案例分析和实战技巧的讨论,本文提供了一系列实战操作方案,助力企业号管理者优化运营效果,增强用户粘性和品牌影响力
【数字电路设计】:优化PRBS生成器性能的4大策略
# 摘要
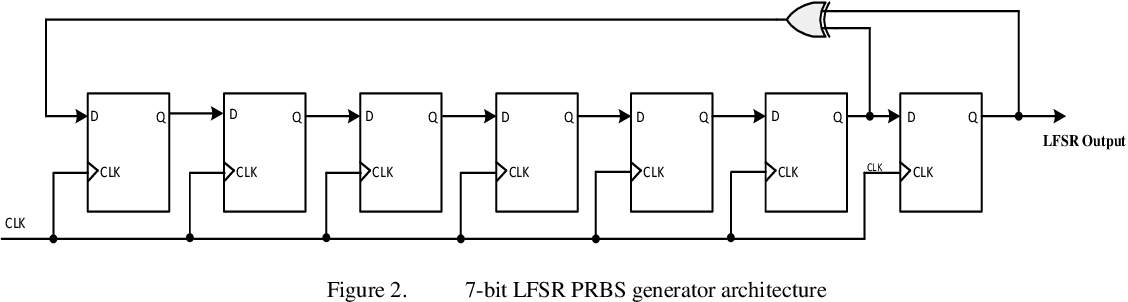
本文全面介绍了数字电路设计中的PRBS生成器原理、性能优化策略以及实际应用案例分析。首先阐述了PRBS生成器的工作原理和关键参数,重点分析了序列长度、反馈多项式、时钟频率等对生成器性能的影响。接着探讨了硬件选择、电路布局、编程算法和时序同步等多种优化方法,并通过实验环境搭建和案例分析,评估了这些策
【从零到专家】:一步步精通图书馆管理系统的UML图绘制

# 摘要
统一建模语言(UML)是软件工程领域广泛使用的建模工具,用于软件系统的设计、分析和文档化。本文旨在系统性地介绍UML图绘制的基础知识和高级应用。通过概述UML图的种类及其用途,文章阐明了UML的核心概念,包括元素与关系、可视化规则与建模。文章进一步深入探讨了用例图、类图和序列图的绘制技巧和在图书馆管理系统中的具体实例。最后,文章涉及活动图、状态图的绘制方法,以及组件图和
【深入理解Vue打印插件】:专家级别的应用和实践技巧
# 摘要
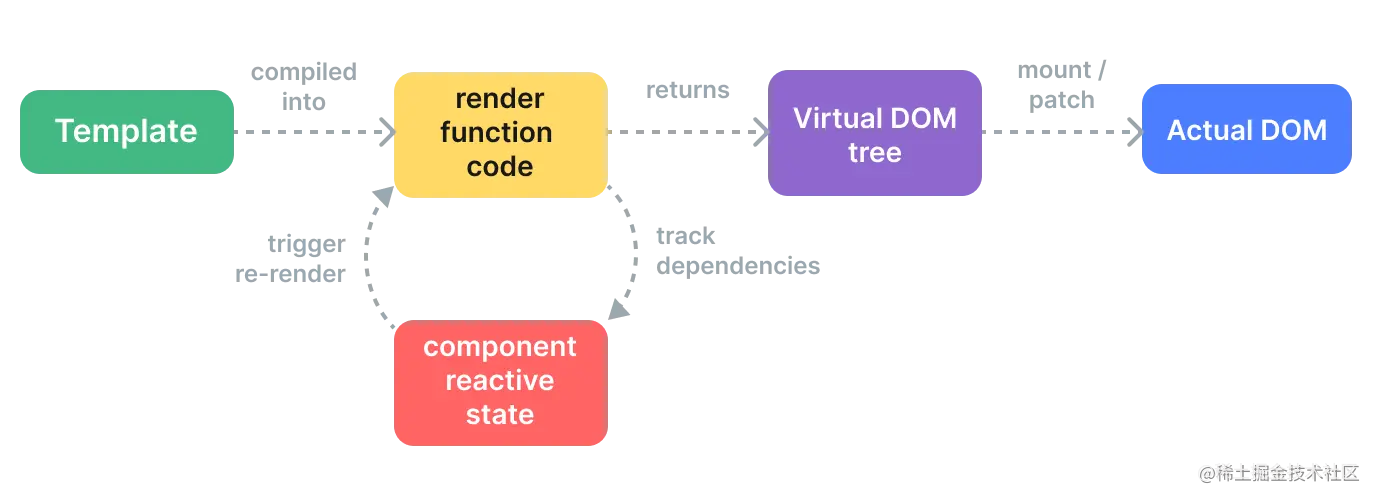
本文深入探讨了Vue打印插件的基础知识、工作原理、应用配置、优化方法、实践技巧以及高级定制开发,旨在为Vue开发者提供全面的打印解决方案。通过解析Vue打印插件内部的工作原理,包括指令和组件解析、打印流程控制机制以及插件架构和API设计,本文揭示了插件在项目
【Origin图表深度解析】:隐藏_显示坐标轴标题与图例的5大秘诀

# 摘要
本文旨在探讨Origin图表中坐标轴标题和图例的设置、隐藏与显示技巧及其重要性。通过分析坐标轴标题和图例的基本功能,本文阐述了它们在提升图表可读性和信息传达规范化中的作用。文章进一步介绍了隐藏与显示坐标轴标题和图例的需求及其实践方法,包括手动操作和编程自动化技术,强调了灵活控制这些元素对于创建清晰、直观图表的重要性。最后,本文展示了如何自定义图表以满足高级需求,并通过
【GC4663与物联网:构建高效IoT解决方案】:探索GC4663在IoT项目中的应用
# 摘要
GC4663作为一款专为物联网设计的芯片,其在物联网系统中的应用与理论基础是本文探讨的重点。首先,本文对物联网的概念、架构及其数据处理与传输机制进行了概述。随后,详细介绍了GC4663的技术规格,以及其在智能设备中的应用和物联网通信与安全机制。通过案例分析,本文探讨了GC4663在智能家居、工业物联网及城市基础设施中的实际应用,并分
Linux系统必备知识:wget命令的深入解析与应用技巧,打造高效下载与管理

# 摘要
本文旨在深入介绍Linux系统中广泛使用的wget命令的基础知识、高级使用技巧、实践应用、进阶技巧与脚本编写,以及在不同场景下的应用案例分析。通过探讨wget命令的下载控制、文件检索、网络安全、代理设置、定时任务、分段下载、远程文件管理等高级功能,文章展示了wget
EPLAN Fluid故障排除秘籍:快速诊断与解决,保证项目顺畅运行
# 摘要
EPLAN Fluid作为一种工程设计软件,广泛应用于流程控制系统的规划和实施。本文旨在提供EPLAN Fluid的基础介绍、常见问题的解决方案、实践案例分析,以及高级故障排除技巧。通过系统性地探讨故障类型、诊断步骤、快速解决策略、项目管理协作以及未来发展趋势,本文帮助读者深入理解EPLAN Fluid的应用,并提升在实际项目中的故障处理能力。
华为SUN2000-(33KTL, 40KTL) MODBUS接口故障排除技巧

# 摘要
本文旨在全面介绍MODBUS协议及其在华为SUN2000逆变器中的应用。首先,概述了MODBUS协议的起源、架构和特点,并详细介绍了其功能码和数据模型。随后,对华为SUN2000逆变器的工作原理、通信接口及与MODBUS接口相关的设置进行了讲解。文章还专门讨论了MODBUS接口故障诊断的方法和工具,以及如
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )