数据驱动决策:【中国卓越团队的分析与应用】
发布时间: 2024-12-27 02:42:01 阅读量: 7 订阅数: 9 

2021-2025年中国金属连接件行业基于产业痛点研究与战略决策咨询报告.pdf
# 摘要
数据驱动决策作为一种现代决策模式,在企业与公共服务领域发挥着至关重要的作用。本文首先概述了数据驱动决策的重要性及其数据收集、管理的基础知识,包括数据质量的控制、存储优化与治理。随后,详细探讨了数据分析与处理的技术手段,如描述性统计、高级分析方法和数据质量预处理策略。通过分析企业在市场营销和人力资源管理,以及政府在公共政策制定与城市管理中的具体案例,本文揭示了数据科学工具与技术的实际应用。最后,本文针对数据隐私与安全、伦理和社会责任等挑战进行了讨论,并对未来数据驱动决策的发展趋势与策略提出了建议。
# 关键字
数据驱动决策;数据收集与管理;数据分析处理;数据科学工具;数据隐私与安全;伦理与社会责任
参考资源链接:[字节跳动STE团队:90后死磕Linux内核,构建互联网基石](https://wenku.csdn.net/doc/125t0tnm7k?spm=1055.2635.3001.10343)
# 1. 数据驱动决策概述
在当今信息化高度发展的社会,数据已成为企业战略决策的重要资源。数据驱动决策是指在企业运营和管理中,利用收集到的数据进行分析,并根据分析结果来指导决策过程。这一决策模式相较于传统的直觉或经验驱动模式,更加注重客观数据的分析和解读。
## 1.1 数据驱动决策的意义
数据驱动决策能够帮助企业通过数据洞察发现潜在问题,预测市场趋势,优化产品和服务。通过定量分析代替定性判断,企业能够在复杂多变的商业环境中,找到更加科学和精准的解决路径。此外,数据驱动的决策体系也帮助企业更有效地评估决策效果,实现持续优化。
## 1.2 数据驱动决策的运作流程
数据驱动决策不是孤立的,它涉及到数据的采集、存储、处理、分析,直至最终应用。在这一流程中,数据不仅需要被有效地管理,而且需要被转化为可操作的见解。这通常包括了明确决策目标、数据收集、数据处理、分析方法的应用、结果的解释和应用等步骤。而这一切的基础,都建立在数据质量的保证之上。
通过本章,我们将为读者构建数据驱动决策的整体框架,为深入理解后续章节打下坚实基础。
# 2. 数据收集与管理基础
## 2.1 数据收集方法论
### 从传统到现代的数据收集工具
在数据驱动的决策过程中,数据收集是迈出的第一步,也是关键一步。传统的数据收集方法包括纸质问卷、面对面访谈、电话调查等,这些方法在特定条件下依然有其价值,尤其是在需要深入交流和理解受访者的场景中。然而,随着技术的发展,现代数据收集工具正变得越来越多样化和高效。这些新工具包括在线调查平台、社交媒体分析、物联网设备数据收集等。它们不仅可以自动化数据收集过程,还能实时获取大量数据。
例如,通过社交媒体分析工具,我们可以收集到用户的言论、喜好、行为模式等信息,这为市场研究提供了前所未有的丰富数据源。物联网设备,如智能家居或工业传感器,可以收集温度、湿度、压力等各种实时数据,为决策提供科学依据。
#### 代码块示例
在实际的数据收集过程中,我们可能使用Python脚本来自动从网页上抓取数据。这里是一个使用`requests`库和`BeautifulSoup`库的基本示例:
```python
import requests
from bs4 import BeautifulSoup
# 目标网页URL
url = 'http://example.com'
# 发送HTTP请求获取网页内容
response = requests.get(url)
# 使用BeautifulSoup解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 找到所有需要的数据并保存
data = []
for item in soup.find_all('div', class_='data-point'):
data.append(item.text)
```
#### 参数说明与逻辑分析
在上面的代码中,我们首先导入了`requests`和`BeautifulSoup`库。使用`requests.get(url)`发送HTTP请求,然后利用`BeautifulSoup`解析返回的HTML内容。通过`find_all`方法,我们提取了所有带有`data-point`类的`div`元素中的文本,假设这些文本是我们需要收集的数据点。这个过程可以自动化,定期执行脚本,实时收集最新的数据。
### 数据质量控制与验证技巧
收集到的数据质量直接影响决策的有效性。高质量的数据应该是准确、完整、一致和及时的。数据质量控制包括多个步骤:数据清洗、数据验证、异常值处理等。
- **数据清洗**:移除重复记录、纠正错误和缺失值处理。
- **数据验证**:确保数据符合预期格式和业务规则,例如邮箱地址的正确性、日期的有效性等。
- **异常值处理**:识别和处理偏离标准差范围的异常值。
#### 代码块示例
下面的Python代码片段使用Pandas库进行了数据清洗的一些基本操作:
```python
import pandas as pd
# 加载数据到DataFrame
df = pd.read_csv('data.csv')
# 删除重复的记录
df = df.drop_duplicates()
# 填充缺失值
df.fillna(df.mean(), inplace=True)
# 数据验证,确保特定列的数据类型正确
df['price'] = df['price'].astype(float)
df['date'] = pd.to_datetime(df['date'], errors='coerce')
# 异常值处理
# 删除超出3个标准差的记录
df = df[(df['price'] > df['price'].mean() - 3 * df['price'].std()) &
(df['price'] < df['price'].mean() + 3 * df['price'].std())]
```
#### 参数说明与逻辑分析
代码首先导入了Pandas库,然后加载数据到DataFrame中。使用`drop_duplicates`方法删除重复记录。`fillna`方法用于填充缺失值,这里我们用相应列的平均值填充。然后,将"price"列的数据类型转换为浮点数,并将"date"列转换为日期时间格式。对于异常值的处理,我们保留了价格在平均值加减三倍标准差范围内的记录。
## 2.2 数据存储与数据库管理
### 关系型与非关系型数据库选择
随着业务需求和数据量的增长,选择合适的数据存储解决方案变得至关重要。关系型数据库(如MySQL、PostgreSQL)以其强大的事务处理能力和结构化查询语言(SQL)支持,长久以来一直是数据存储的主流选择。然而,当数据变得多样化、非结构化、或者需要水平扩展时,非关系型数据库(如MongoDB、Redis)的灵活性和高可扩展性就显得更为重要。
#### 表格示例
| 类别 | 关系型数据库 | 非关系型数据库 |
|------|--------------|----------------|
| 数据模型 | 表格,行和列 | 键值对、文档、宽列存储、图数据库 |
| 查询语言 | SQL | 不同类型数据库各有不同 |
| 扩展性 | 通常垂直扩展 | 多数支持水平扩展 |
| 事务支持 | 强 | 较弱或不支持 |
| 数据一致性 | ACID | BASE |
#### 逻辑分析
从上表可以看出,关系型数据库和非关系型数据库各有优劣。关系型数据库适合结构化数据和事务性操作,而非关系型数据库则在处理半结构化或非结构化数据时更为灵活。如果业务场景需要大规模分布式处理,非关系型数据库的水平扩展能力可能更适合。选择时需考虑应用的具体需求,比如数据结构的复杂性、数据访问模式以及系统的可扩展性。
### 数据库的优化与安全性管理
随着数据量的增长,数据库性能优化和安全性成为重要考量。性能优化涉及查询优化、索引管理、数据库配置调整等方面。安全性管理需要对数据库进行定期的漏洞扫描、访问控制、数据加密、备份和恢复等操作。
#### 代码块示例
下面的SQL脚本示例演示了如何为数据库创建索引,以优化查询性能:
```sql
CREATE INDEX idx_customers_name ON customers(name);
```
#### 参数说明与逻辑分析
索引能够提高查询数据的速度,尤其是在处理大量数据时。这里,我们创建了一个名为`idx_customers_name`的索引,针对`customers`表的`name`列。索引使得数据库能够快速定位到包含特定名称的客户记录,而不是扫描整个表。但是,索引也会占用额外的存储空间,并可能在数据更新时增加写操作的开销。
## 2.3 数据治理与合规性
### 数据治理框架建立
数据治理框架定义了数据管理和使用过程中的责任、流程、标准和监督机制。一个良好的数据治理框架能够确保数据的准确性、一致性和可靠性,以及合规性。它通常包括数据质量、数据安全、元数据管理、数据存档等多个方面。
#### mermaid格式流程图示例
```mermaid
graph TD;
A[开始数据治理] --> B[定义数据治理政策]
B --> C[建立数据治理组织结构]
C --> D[确定数据标准和流程]
D --> E[实施和监督]
E --> F[定期审查和改进]
```
#### 逻辑分析
从流程图可以看出,建立数据治理框架是一个循环的过程,从定义政策开始,到建立组织结构,再到确定标准和流程,最后是实施、监督和定期审查改进。整个框架强调的是持续性和可适应性,以应对不断变化的数据环境和业务需求。
### 遵循法规的数据管理实践
不同的行业和地区可能有不同的数据保护法规,比如GDPR、HIPAA等。遵守这些法规是企业不可逃避的义务。数据管理实践应涵盖数据的访问控制、透明度、数据主体权利保护、数据泄露应对策略等方面。
#### 代码块示例
下面是一个简单的Python脚本,用于模拟数据主体请求删除个人信息的过程:
```python
# 假设有一个用户请求删除其个人信息
def delete_user_data(user_id):
# 在数据库中删除用户记录
# 删除与用户相关的所有个人信息
# 记录删除操作的
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《中国卓越技术团队访谈录·2022第四季》专栏深入探究了中国领先技术团队的成功秘诀。通过对成功案例的分析,专栏揭示了技术创新如何推动业务增长。专栏还分享了项目管理、团队文化建设、跨部门协作、应对行业变革、领导者职业发展等方面的最佳实践。此外,专栏还探讨了持续学习、危机管理、绩效评估、产品思维转型和数据驱动决策等关键主题,为技术团队提供了全面的见解和指导。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CTS模型:从基础到高级,构建地表模拟的全过程详解

# 摘要
本文对CTS模型进行了全面介绍,从基础理论到实践操作再到高级应用进行了深入探讨。CTS模型作为一种重要的地表模拟工具,在地理信息系统(GIS)中有着广泛的应用。本文详细阐述了CTS模型的定义、组成、数学基础和关键算法,并对模型的建立、参数设定、迭代和收敛性分析等实践操作进行了具体说明。通过对实地调查数据和遥感数据的收集与处理,本文展示了模型在构建地表模拟时的步
【升级前必看】:Python 3.9.20的兼容性检查清单

# 摘要
Python 3.9.20版本的发布带来了多方面的更新,包括语法和标准库的改动以及对第三方库兼容性的挑战。本文旨在概述Python 3.9.20的版本特点,深入探讨其与既有代码的兼容性问题,并提供相应的测试策略和案例分析。文章还关注在兼容性升级过程中如何处理不兼容问题,并给出升级后的注意事项。最后,
【Phoenix WinNonlin数据可视化】:结果展示的最佳实践和技巧

# 摘要
本文旨在全面介绍Phoenix WinNonlin软件在数据可视化方面的应用,概念与界面功能概览,以及数据可视化技术的深入探讨。通过章节内容对软件界面的核心组件、功能操作流程进行解析,强调了数据图表化和高级数据处理技巧的重要性。实践案例分析
【Allegro脚本编程:自动化设计的终极指南】

# 摘要
Allegro脚本作为一种强大的自动化工具,广泛应用于电子设计自动化领域。本文从脚本的基础知识讲起,深入探讨了其语法、高级特性以及在实践中的具体应用,包括自动化流程设计、数据管理、交互式脚本编写。随后,文章详细介绍了脚本优化与调试技巧,以提升执行效率和故障处理能力。最后,文章探索了Allegro脚本在PCB设计自动化、IC封装设计等不同领域的
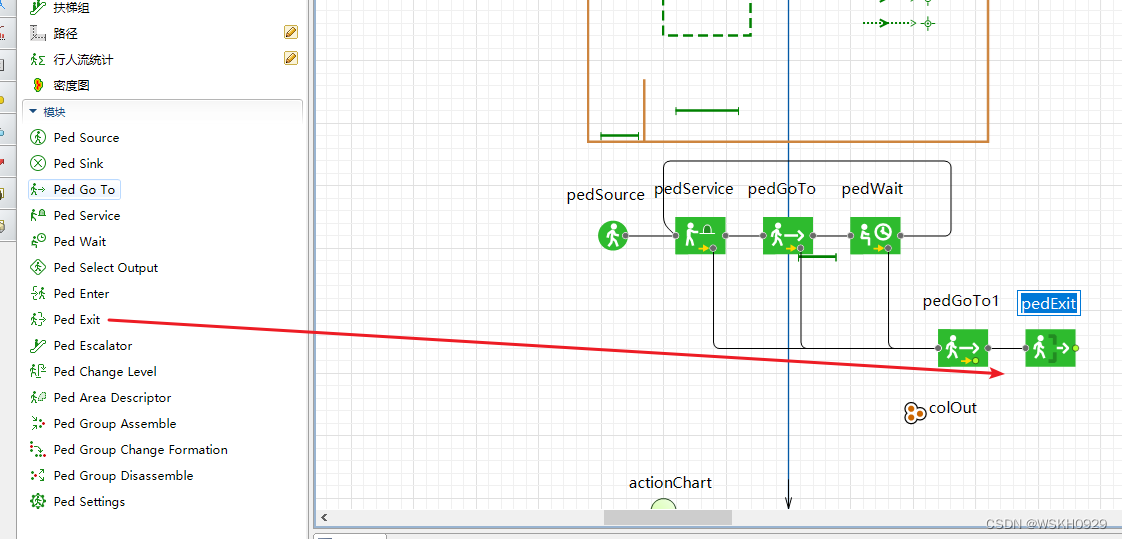
AnyLogic工作流与决策模拟:精通业务流程设计只需72小时
# 摘要
本文全面概述了业务流程模拟与决策分析的理论与实践,特别聚焦于AnyLogic软件的应用。首先,对AnyLogic的基础知识和界面布局进行了介绍,并探讨了创建新模拟项目的步骤。接着,文章深入探讨了业务流程模拟的理论基础和建模技术,以及如何通过流程图和模拟分析来支持决策。此外,还详细讲解了面向对象模拟方法在AnyLogic中的实现,构建高级决策模型的技巧,以及仿真实验的设计与结果分析。最后,文章探讨了AnyLogi
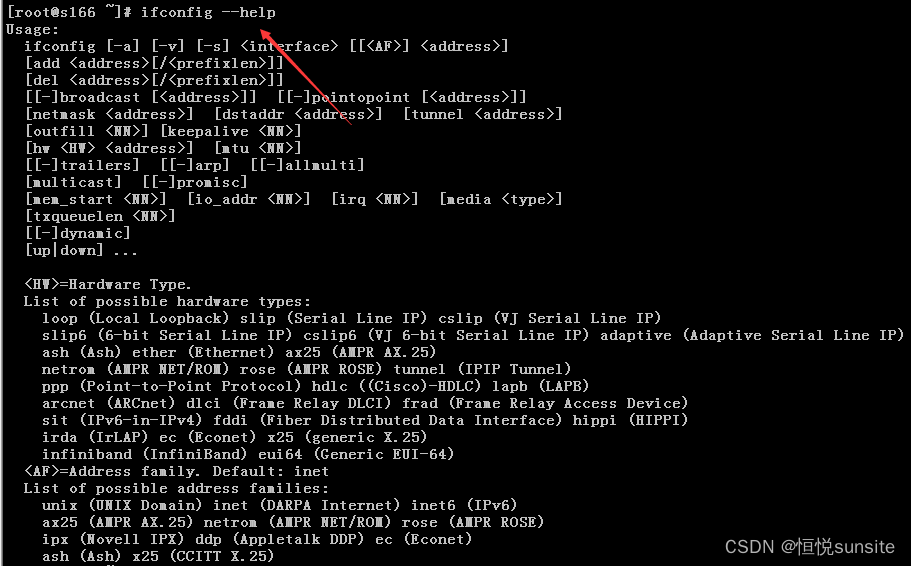
【网络性能调优实战】:ifconfig在加速Linux网络中的10大应用
# 摘要
本文全面介绍了网络性能调优的基础知识,并着重探讨了Linux系统中广泛使用的网络配置工具ifconfig在性能加速和优化配置中的关键应用。通过对网络接口参数的优化、流量控制与速率调整以及网络故障的诊断与监控,本文提供了一系列实用的ifconfig应用技巧。进一步,本文讨论了ifconfig的高级应用,包括虚拟网络接口配置、多网络环境性能优化和安全性能提升。最后,本文比较了i
CMW500-LTE自动化测试脚本编写:从零基础到实战,提升测试效率

# 摘要
随着移动通信技术的快速发展,CMW500-LTE作为一款先进的测试设备,在无线通信领域占据重要地位。本文系统性地介绍了CMW500-LTE的自动化测试方法,涵盖了测试概述、基础理论、实践操作、性能优化、实战案例以及未来展望。通过对CMW500-LTE设备和接口的介绍,自动化测试环境的搭建,测试脚本编写理论与实践的深入
S4 ABAP编程数据处理

# 摘要
本文对S4 ABAP编程进行了全面的介绍和分析,从基础的数据定义与类型到数据操作与处理,再到数据集成与分析,以及实际应用和性能调优。特别指出S4 ABAP在供应链管理和财务流程中数据处理的重要性,并提供了性能瓶颈诊断和错误处理的策略。文章还探讨了面向对象编程在ABAP中的应用和S4 ABAP的未来创新技术趋势,强调了HANA数据库和云平台对AB
【BK2433高级定时器应用宝典】:定时器配置与应用手到擒来

# 摘要
定时器技术是嵌入式系统和实时操作系统中的核心组件,本文首先介绍了定时器的基础配置和高级配置策略,包括精确度设置、中断管理以及节能模式的实现。随后,文中详细探讨了定时器在嵌入式系统中的应用场景,如实时操作系统中的多任务调度集成
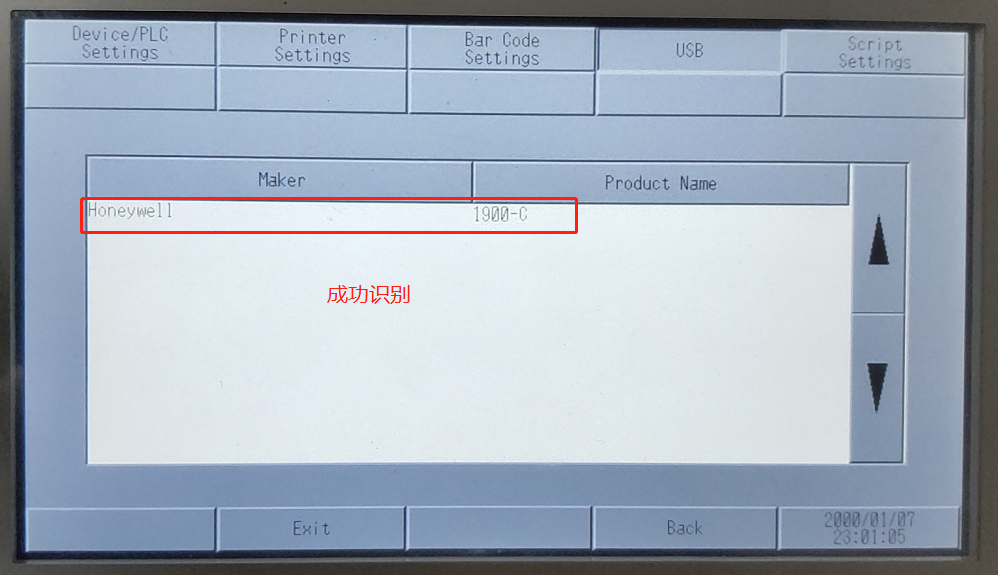
Eclipse MS5145扫码枪维护必修课:预防常见问题
# 摘要
Eclipse MS5145扫码枪作为一款广泛使用的条码读取设备,在日常使用和维护中需要特别关注其性能和可靠性。本文系统地概述了Eclipse MS5145扫码枪的维护基础,并深入探讨了其硬件组成部分及其工作原理,包括传感器、光源、解码引擎,以及条码扫描和数据传输机制。同时,本文详细介绍了日常维护流程、故障诊断与预防措施,以及如何实施高级维护技术如性能测试
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )