R语言数据仪表板制作速成:flexdashboard一站式解决方案
发布时间: 2024-11-09 21:36:19 阅读量: 65 订阅数: 21 
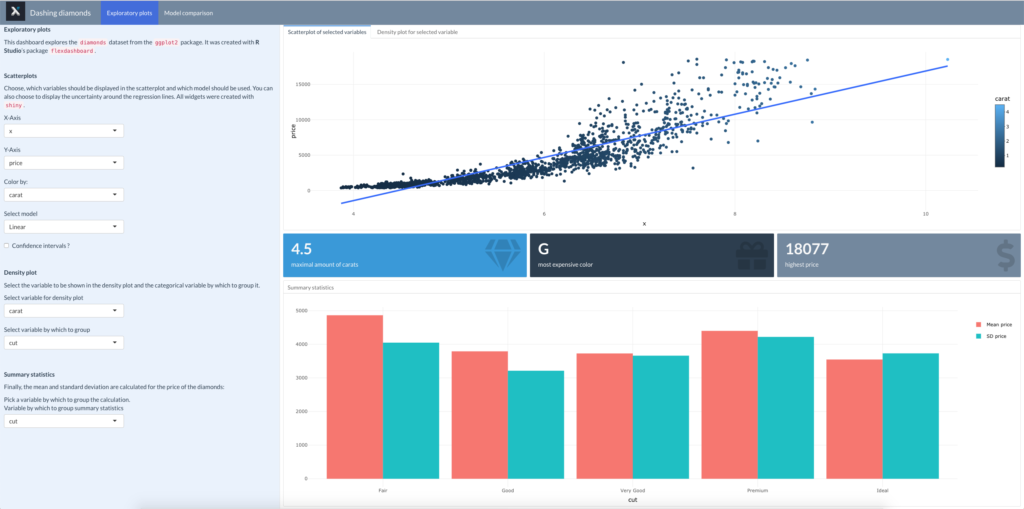
# 1. R语言与数据仪表板简介
在数据科学领域,R语言因其强大的统计分析和数据可视化能力而广受欢迎。然而,将数据展示给非专业的观众时,单纯的代码输出或图表往往难以满足需求。为了构建直观且易用的数据仪表板,R语言提供了多种解决方案。数据仪表板是一个将关键性能指标(KPIs)、图表、数据表格和报告汇总在一起的用户界面,允许用户与之互动并快速洞察数据。随着企业对于数据驱动决策的需求日益增长,创建交互式的数据仪表板已成为数据分析师的一项必备技能。
数据仪表板的构建不仅仅是技术的展示,更是沟通数据故事的平台。它将复杂的数据转化为易于理解的视觉元素,使得用户可以轻松地访问、理解并根据数据作出决策。在本章中,我们将探讨R语言在构建数据仪表板中的作用,以及它与一些流行工具如flexdashboard包的协同工作方式。通过逐步深入,我们将揭开R语言构建数据仪表板的神秘面纱。
# 2. flexdashboard基础
### 2.1 flexdashboard的基本概念
#### 2.1.1 什么是flexdashboard
flexdashboard是R语言的一个扩展包,它允许用户利用R Markdown创建交互式数据仪表板。这个包简化了复杂数据的可视化和分享过程,提供了简洁的界面和丰富的定制选项,使得数据呈现更加直观和动态。flexdashboard特别适用于生成响应式设计的网页仪表板,它能够自适应不同尺寸的屏幕,使得用户无论是在手机、平板还是桌面浏览器上都能有良好的浏览体验。
#### 2.1.2 安装和设置flexdashboard
安装flexdashboard包非常简单,只需在R控制台运行以下命令:
```R
install.packages("flexdashboard")
```
一旦安装完成,您可以通过RStudio的菜单栏创建一个新的flexdashboard项目,或者在R控制台使用命令行进行设置:
```R
library(flexdashboard)
```
安装完毕后,您需要熟悉flexdashboard的基本结构。一个flexdashboard通常由多个“页”组成,每个页可以包含多个“小部件”,如图表、表格和其他数据可视化元素。在R Markdown文件中,您可以使用特定的标记来定义布局和小部件,flexdashboard会自动将这些标记转换为动态的网页内容。
### 2.2 flexdashboard的页面布局
#### 2.2.1 布局选项和格式化
flexdashboard提供了几种布局选项,包括列布局、行布局和混合布局。每种布局选项都有其特定的标记语法,允许您灵活地控制仪表板的视觉呈现方式。例如,您可以使用三列布局来展示三个独立的图表,或者使用行布局来创建复杂的表格和图表组合。
格式化方面,flexdashboard支持多种主题,并允许用户自定义CSS,以便于用户可以根据个人品味和品牌指南调整仪表板的外观。您可以使用主题选项卡来选择内置主题,或者编辑自定义CSS文件以进一步调整页面的样式。
#### 2.2.2 列表和网格的使用
在flexdashboard中,列表和网格是组织和展示小部件的两种常用方式。列表布局适用于展示一系列相关联的小部件,而网格布局适用于展示小部件之间的独立性更强的场景。
使用列表布局时,每个小部件会垂直排列,这对于展示一系列连续的信息或流程非常有效。而网格布局则允许多个小部件并排展示,这适合于需要展示并列数据或比较不同小部件的情况。
列表和网格布局都可以通过简单的YAML头部配置来实现,您可以根据实际内容的需求,灵活选择和调整布局方式。
### 2.3 flexdashboard的交互式组件
#### 2.3.1 使用plotly生成交互图表
plotly是一个强大的绘图库,它支持创建交互式图表,能够在网页上提供丰富的用户交互体验,如缩放、悬停提示以及数据点选择等。在flexdashboard中,plotly可以与R中的ggplot2图形系统无缝集成,以制作动态和交互式的图表。
要使用plotly创建图表,您需要先在R Markdown文档中加载plotly包,然后使用`plot_ly()`函数来绘制图表。例如,以下是一个简单的散点图示例:
```R
library(plotly)
data <- read.csv("your_data.csv")
plot_ly(data, x = ~ColumnX, y = ~ColumnY, type = "scatter", mode = "markers")
```
图表绘制完成后,您可以将plotly图表嵌入到flexdashboard的页面中,用户在浏览时就可以与图表进行互动。
#### 2.3.2 利用DT包显示交互式表格
DT包提供了在R Markdown文档中创建交互式表格的方法。与普通的静态表格不同,使用DT包生成的表格允许用户进行排序、过滤和搜索操作,非常适合在数据密集型的应用场景中使用。
要在flexdashboard中使用DT包显示交互式表格,您需要先安装DT包,并在R Markdown文档的代码块中调用DT包的`datatable()`函数。下面是一个将数据框转换为交互式表格的示例:
```R
library(DT)
data <- read.csv("your_data.csv")
datatable(data)
```
生成的表格会自动嵌入到flexdashboard中,提供动态的交互功能,使得数据探索变得更加便捷。
通过灵活地运用plotly和DT包,flexdashboard可以为用户提供丰富的交互式数据可视化体验,这不仅增强了数据分析的表达力,也提升了用户体验。
# 3. 数据导入与处理
## 3.1 数据的导入方法
### 3.1.1 使用readr和readxl包导入数据
在R语言中,数据导入是分析前的重要步骤。`readr`和`readxl`是R语言中用于导入数据的两个常用包,它们分别用于读取文本文件和Excel文件。`readr`是`tidyverse`的一部分,而`readxl`可以独立于`tidyverse`运行。使用这两个包可以更高效、更快速地导入数据。
```r
# 安装readr和readxl包
install.packages("readr")
install.packages("readxl")
# 载入包
library(readr)
library(readxl)
# 使用read_csv()函数从CSV文件中导入数据
csv_data <- read_csv("path/to/your/csvfile.csv")
# 使用read_excel()函数从Excel文件中导入数据
excel_data <- read_excel("path/to/your/excelfile.xlsx")
```
导入数据后,常常需要对数据进行初步的探索和清洗,这包括查看数据结构、确定数据类型、剔除异常值或填充缺失值等。`readr`包在导入数据时会自动推测每列的数据类型,使导入过程更加智能化。
### 3.1.2 数据的初步探索和清洗
R语言提供了一系列函数和包来进行数据的初步探索和清洗。数据探索可以使用`str()`、`summary()`、`head()`和`tail()`等函数来快速了解数据集的结构和内容。数据清洗则需要处理缺失值、重复数据以及数据类型转换等问题。
```r
# 查看数据结构
str(csv_data)
# 查看数据集摘要信息
summary(csv_data)
# 查看数据集的前6行和后6行数据
head(csv_data)
tail(csv_data)
```
处理缺失数据时,`readr`包通常会将缺失值转换为NA,我们可以使用`na.omit()`函数来剔除含有缺失值的行,或者使用`mutate()`和`ifelse()`函数来填充缺失值。
```r
# 剔除含有NA的行
clean_data <- na.omit(csv_data)
# 填充缺失值为0
csv_data <- mutate(csv_data, column_name = ifelse(is.na(column_name), 0, column_name))
```
## 3.2 数据的预处理
### 3.2.1 数据类型转换
在数据导入之后,可能需要对某些列的数据类型进行转换,以便进行更准确的分析。例如,字符型数据如果被误读为因子型,可能会影响后续的统计分析。`readr`包可以正确地读取日期时间信息,而`as.Date()`和`as.POSIXct()`函数则用于转换日期时间数据类型。
```r
# 将字符型转换为因子型
csv_data$factor_column <- as.factor(csv_data$factor_column)
# 将字符型日期转换为日期类型
csv_data$date_column <- as.Date(csv_data$date_column, format = "%Y-%m-%d")
# 将字符型时间转换为POSIXct时间类型
csv_data$time_column <- as.POSIXct(csv_data$time_column, format = "%H:%M:%S")
```
### 3.2.2 缺失值处理
在数据分析中,处理缺失值是一个重要环节。缺失值的处理方式有多种,包括删除含有缺失值的行或列,填充缺失值(例如使用均值、中位数或众数等),或使用模型预测缺失值。`tidyr`包中的`drop_na()`和`fill()`函数可以用来处理缺失值。
```r
# 删除含有NA的列
clean_data <- select_if(clean_data, function(x) !any(is.na(x)))
# 使用前一个值填充NA
csv_data <- fill(csv_data, column_name)
# 使用均值填充NA
csv_data$column_name[is.na(csv_data$column_name)] <- mean(csv_data$column_name, na.rm = TRUE)
```
## 3.3 数据的可视化处理
### 3.3.1 使用ggplot2绘图基础
`ggplot2`是R语言中非常流行的图形绘制系统,基于“图层”的概念,使得绘图过程清晰而灵活。使用`ggplot2`可以创建各种静态的、分面的和交互式的图形。
创建基本的ggplot图形需要指定数据集、aes(映射到图形属性的变量)以及一个或多个geom(几何对象,如点、线、条形等)。
```r
# 安装ggplot2包
install.packages("ggplot2")
# 载入ggplot2包
library(ggplot2)
# 基础绘图
ggplot(data = csv_data, aes(x = column1, y = column2)) +
geom_point() # 添加点图层来创建散点图
```
### 3.3.2 图表的个性化定制
`ggplot2`提供了多种方法来自定义图表的外观,包括颜色、填充、形状、标签、图例和主题等。个性化定制是数据可视化中吸引观众的关键。
```r
# 使用颜色区分分类变量
ggplot(data = csv_data, aes(x = column1, y = column2, color = category)) +
geom_point()
# 使用标签添加数据点的说明
ggplot(data = csv_data, aes(x = column1, y = column2, label = data_label)) +
geom_point() +
geom_text() # 添加文本标签图层
# 自定义主题来改变图形的整体风格
ggplot(data = csv_data, aes(x = column1, y = column2)) +
geom_point() +
theme_minimal() # 使用简洁主题
```
通过`ggplot2`的`scale_`系列函数可以定制颜色、大小、形状等属性。而`theme()`函数则允许用户调整图形的非数据元素,如标题、注释、坐标轴、背景等。
```r
# 自定义颜色映射
ggplot(data = csv_data, aes(x = column1, y = column2, color = category)) +
geom_point() +
scale_color_manual(values = c("red", "blue", "green"))
# 自定义主题
ggplot(data = csv_data, aes(x = column1, y = column2)) +
geom_point() +
theme(
plot.title = element_text(hjust = 0.5),
axis.line = element_line(color = "blue")
)
```
下一章节将会探讨flexdashboard的高级特性,介绍如何利用R Markdown的扩展功能来丰富和增强数据仪表板的展示效果。
# 4. flexdashboard的高级特性
在第三章中,我们学习了数据导入、处理和可视化处理的基础知识。接下来,本章节将带领读者深入了解flexdashboard的高级特性,包括如何使用R Markdown的扩展功能,创建自定义主题和外观,以及如何将Shiny应用集成到我们的仪表板中,从而制作出功能更加强大的交互式数据仪表板。
## 4.1 使用R Markdown的扩展功能
### 4.1.1 R Markdown基础语法
R Markdown是R语言的一个扩展包,它将R代码和Markdown文本结合起来,生成格式化的报告。flexdashboard就是基于R Markdown构建的,因此理解基础的R Markdown语法是构建复杂仪表板的前提。
R Markdown文档通常以`.Rmd`为扩展名,其中包含三个主要部分:YAML头部、R代码块和Markdown文本。在YAML头部中,用户可以设置输出格式、主题等参数。例如:
```yaml
title: "我的数据仪表板"
output:
flexdashboard::flex_dashboard:
orientation: columns
vertical_layout: fill
```
在文档主体中,使用三个反引号和相应的语言标识符来创建代码块:
```{r}
# 这是一个R代码块
summary(cars)
```
Markdown文本部分则用于描述性内容,支持多种格式如粗体、斜体、链接和图片等。
### 4.1.2 R Markdown进阶应用
进阶应用涉及到R Markdown文档的参数化、代码执行控制、输出格式化等高级特性。参数化允许在YAML头部定义参数,并在文档中引用这些参数,以便动态生成内容:
```yaml
title: "动态内容的仪表板"
output:
flexdashboard::flex_dashboard:
runtime: shiny
params:
min_year: 2010
max_year: 2020
```
然后在文档中使用这些参数:
```{r}
# 假设有一个名为df的数据框
df_filtered <- subset(df, year >= params$min_year & year <= params$max_year)
```
此外,代码执行控制提供了对代码块执行时机的更精细控制。例如,我们可以指定仅在文档编译时执行代码块,或者根据参数化来控制执行。
## 4.2 创建自定义主题和外观
### 4.2.1 自定义主题的创建
flexdashboard允许开发者通过CSS(层叠样式表)来自定义仪表板的外观。创建自定义主题涉及编辑或创建一个`.css`文件,其中定义了各种HTML元素的样式。
下面是一个简单的CSS示例,用于改变仪表板的背景颜色和字体:
```css
body {
background-color: #f2f2f2;
font-family: "Arial", sans-serif;
}
```
然后,在R Markdown文件中指定这个自定义CSS文件:
```yaml
title: "带自定义主题的仪表板"
output:
flexdashboard::flex_dashboard:
css: custom-theme.css
```
### 4.2.2 应用自定义外观和样式
一旦CSS文件创建好,就可以使用它来自定义仪表板的每一个细节。例如,可以改变图表的字体大小、颜色,以及图表标题的样式。使用CSS的class选择器可以精确地定位到特定的元素,并对其应用样式。
假设我们的仪表板有一个交互式图表,我们想要改变它的标题样式:
```css
.plotly-title {
font-size: 24px;
color: #333;
}
```
由于flexdashboard生成的HTML文档遵循特定的ID和类命名规则,因此可以轻松地为特定组件编写CSS规则。
## 4.3 集成Shiny应用
### 4.3.1 Shiny简介和基本组件
Shiny是R的一个交互式Web应用框架,允许开发者创建动态Web应用,而无需深入了解HTML、CSS或JavaScript。Shiny应用由两部分组成:用户界面(UI)和服务器逻辑。
Shiny的UI负责定义用户如何与应用互动,例如通过滑块、按钮、单选按钮等组件。服务器逻辑则处理用户的输入,并根据输入生成输出。
### 4.3.2 在flexdashboard中嵌入Shiny应用
在flexdashboard中嵌入Shiny应用可以极大地扩展仪表板的功能。嵌入的方法是在R Markdown文档中设置`runtime: shiny`参数,然后使用`fluidPage`来定义UI,并在代码块中添加服务器逻辑。
以下是一个简单的例子,展示如何在仪表板中嵌入一个Shiny应用,该应用有一个滑块来控制点的大小:
```{r}
library(shiny)
ui <- fluidPage(
sidebarLayout(
sidebarPanel(
sliderInput("size", "点的大小", min = 1, max = 5, value = 2)
),
mainPanel(
plotlyOutput("scatter")
)
)
)
server <- function(input, output, session) {
output$scatter <- renderPlotly({
plot_ly(data = iris, x = ~Sepal.Width, y = ~Sepal.Length,
type = 'scatter', mode = 'markers',
marker = list(size = input$size)) %>%
layout(title = '通过滑块调整点大小')
})
}
shinyApp(ui, server)
```
通过这种方式,我们可以将Shiny的强交互功能和flexdashboard的布局灵活性结合起来,创建出既美观又功能强大的数据仪表板。
本章节介绍了flexdashboard的高级特性,包括R Markdown的扩展功能、自定义主题和外观的创建及应用,以及Shiny应用的集成。通过掌握这些技能,读者可以进一步提高仪表板的实用性和交互性,从而提供更加丰富和动态的数据可视化体验。
# 5. 实践案例:构建自定义数据仪表板
## 5.1 项目准备和数据准备
### 5.1.1 确定仪表板目标和受众
在构建一个自定义数据仪表板之前,首先需要明确仪表板旨在服务的目标和预期的受众群体。目标可能涉及到数据的可视化呈现、数据分析、决策支持或者实时监控等方面。一个明确的目标将帮助我们定位仪表板的风格、功能和数据内容,以及选择合适的技术和工具来实现目标。
受众群体的确定则关系到仪表板设计的复杂程度、数据的呈现方式和交互元素的使用。不同受众可能对数据的理解能力和技术的适应性存在差异,因此在设计时需要考虑到受众的技术背景和使用习惯。
例如,对于一个面向商业分析师的仪表板,可以设计较多的数据分析工具和高级数据操作功能;而如果是面向管理层的仪表板,则应注重数据的直观展示和易于理解的交互设计。
### 5.1.2 数据收集和整理
数据是构建仪表板的基础。在确定了仪表板的目标和受众后,下一步是收集和整理需要在仪表板中使用的数据。数据收集可以来自于内部数据库、公开的数据集、第三方API接口,或者在线调查等多种渠道。数据来源的多样性增加了收集过程的复杂性,因此需要对数据来源进行评估,确保数据的准确性和可靠性。
收集到的数据需要进行清洗和整理,以确保仪表板上的展示能够准确反映信息。数据清洗的常见步骤包括去除重复数据、处理缺失值、纠正错误、统一数据格式和类型,以及转换数据结构以适应可视化需求等。
在本环节中,R语言的`dplyr`包提供了非常强大的数据操作工具,可以帮助我们高效完成数据的整理工作。
```r
# 代码示例:使用dplyr进行数据清洗
library(dplyr)
# 加载数据集
data <- read.csv("your_data.csv")
# 数据清洗操作
cleaned_data <- data %>%
mutate(column1 = as.factor(column1)) %>% # 转换数据类型
filter(!is.na(column2)) %>% # 过滤缺失值
distinct() %>% # 去重
arrange(desc(column3)) # 排序
# 保存清洗后的数据
write.csv(cleaned_data, "cleaned_data.csv", row.names = FALSE)
```
在上述代码块中,我们首先加载了`dplyr`包和目标数据集。通过一系列管道操作(`%>%`),我们将数据转换为因子类型、过滤掉含有缺失值的行、去除重复数据,并对数据按某一列进行排序。最终,将清洗后得到的数据保存为新的CSV文件。
这个环节不仅是为了准备数据,同时也是对数据的一个初步探索。在清洗过程中,我们可能会发现数据集的异常情况,如异常值、偏态分布等,这些都需要在后续的数据分析和可视化过程中加以考虑。
## 5.2 设计仪表板布局
### 5.2.1 确定页面结构和元素分布
一旦数据准备就绪,下一步就是设计仪表板的页面布局。设计时要考虑到用户如何最高效地获取信息,同时也要保证界面的美观和可用性。在Flexdashboard中,我们通常使用列(columns)和行(rows)来构建布局,并通过不同的页面(page)来组织内容。
确定页面结构时,首先需要明确仪表板的主要内容和功能模块。例如,一个典型的仪表板可能包括概览、详情、历史数据和预测等多个部分。每个部分可以对应一个页面,页面之间通过链接或导航按钮进行切换。
元素分布上,要特别注意信息的层次性和视觉焦点。常用的设计原则是“F”模式(从上到下、从左到右的阅读顺序)和“Z”模式(扫描完页面左上角后,视线会沿着页面的中轴线向右移动,然后再次从左到右扫描底部)。将最重要的信息放在用户最可能看到的位置,次要信息可以适当安排在视线移动的轨迹上。
### 5.2.2 使用Flexbox布局工具进行排版
在Flexdashboard中,我们可以利用Flexbox的布局特性来实现响应式设计。Flexbox布局工具允许我们以更灵活的方式对内容进行排布,适应不同的屏幕尺寸和设备。
在进行排版时,要注意合理使用容器、栅格系统以及对齐和分布属性来创建清晰、有序的布局。容器(如栅格布局中的`fluidRow`和`column`)能够帮助我们对内容进行分组和区域划分,而栅格系统则提供了定义内容宽度和布局的结构。
使用Flexbox时,我们可以通过指定flex容器的`flex-flow`属性来控制子元素的排列方向和换行方式,通过`justify-content`和`align-items`等属性来调整子元素的对齐和分布。
## 5.3 实现交互式元素
### 5.3.1 插入交互式图表和表格
在设计好布局和排版后,下一步是插入交互式图表和表格,以增强仪表板的可用性和用户参与感。在flexdashboard中,使用plotly包可以创建交互式图表,而DT包则可以用来展示交互式表格。
在本小节中,我们将介绍如何使用plotly创建一个交互式图表,并将其嵌入到Flexdashboard中。我们会使用plotly绘制一个基本的散点图,并添加一些交互特性,如悬停信息、缩放和平移。
```r
# 代码示例:使用plotly创建交互式图表
library(plotly)
# 准备数据
df <- data.frame(
x = rnorm(100),
y = rnorm(100),
label = paste("Point", 1:100)
)
# 创建交互式散点图
plot <- plot_ly(df, x = ~x, y = ~y, type = 'scatter', mode = 'markers',
text = ~label, hoverinfo = 'text') %>%
layout(title = "Interactive Scatter Plot with Plotly")
# 在flexdashboard中使用plotly图表
# 在flexdashboard的代码块中嵌入plotly图表
```
在上述代码块中,我们首先准备了一些模拟数据,并使用`plot_ly`函数创建了一个散点图。图表中的每个点都绑定了一个标签,并设置了悬停时显示的信息。通过`layout`函数,我们还可以自定义图表的标题。
### 5.3.2 使用Shiny组件增强交互性
为了进一步增强仪表板的交互性,我们可以将Shiny组件集成到flexdashboard中。Shiny是一个强大的R包,用于创建交互式Web应用程序。通过集成Shiny,我们可以实现数据的动态更新、用户输入的实时响应,以及更复杂的交互逻辑。
例如,我们可以创建一个用户可以自定义的数据筛选器。当用户更改筛选条件时,仪表板上的图表和表格将根据新的筛选结果动态更新。
```r
# 代码示例:在flexdashboard中嵌入Shiny组件
# Shiny组件示例代码
library(shiny)
# Shiny UI
ui <- fluidPage(
titlePanel("My Dashboard"),
sidebarLayout(
sidebarPanel(
selectInput("dataset", "Choose a dataset:",
choices = c("mtcars", "iris"))
),
mainPanel(
tabsetPanel(
tabPanel("Plot", plotlyOutput("plot")),
tabPanel("Summary", verbatimTextOutput("summary")),
tabPanel("Table", tableOutput("table"))
)
)
)
)
# Shiny server逻辑
server <- function(input, output) {
output$plot <- renderPlotly({
dataset <- switch(input$dataset,
"mtcars" = mtcars,
"iris" = iris)
p <- ggplot(dataset, aes_string(x = names(dataset)[1], y = names(dataset)[2])) + geom_point()
ggplotly(p)
})
output$summary <- renderPrint({
dataset <- switch(input$dataset,
"mtcars" = mtcars,
"iris" = iris)
summary(dataset)
})
output$table <- renderTable({
dataset <- switch(input$dataset,
"mtcars" = mtcars,
"iris" = iris)
dataset
})
}
# 运行Shiny应用程序
shinyApp(ui, server)
```
在上述代码中,我们构建了一个包含侧边栏的Shiny应用UI,用户可以在侧边栏选择数据集,并通过不同的tab面板查看图表、摘要和数据表。在Shiny服务器逻辑中,我们根据用户的选择动态生成对应的图表和表格内容,并通过`renderPlotly`、`renderPrint`和`renderTable`函数分别渲染到对应的输出端。
Shiny组件的集成使得仪表板能够提供更加丰富的交互体验,用户可以实时看到数据分析的结果,并根据需求进行探索式的数据分析。这种深度的用户参与是静态数据仪表板所无法提供的。
# 6. 仪表板的优化与发布
## 6.1 仪表板的测试和调试
### 6.1.1 解决常见问题
在开发和部署仪表板的过程中,难免会遇到各种问题。这些可能包括布局不一致、组件不响应以及性能瓶颈等。解决这些问题的关键在于细致的测试和有效的调试技术。
测试仪表板时,可以遵循以下步骤:
- **单元测试**: 使用`testthat`包来测试仪表板的各个组件功能。
- **集成测试**: 验证各个组件和图表如何协同工作。
- **性能测试**: 使用工具如`profvis`来分析代码的运行时间和内存使用,找出性能瓶颈。
例如,当你在使用Shiny组件时,可能会遇到响应性不好的问题。这种情况下,你需要检查Shiny的`reactive`表达式和`observe`事件是否编写得当,以确保它们仅在必要时重新计算。
### 6.1.2 仪表板的性能优化
性能优化可以从多个角度进行:
- **代码优化**: 确保所有的R代码都是高效和优化的。使用`microbenchmark`包来比较不同代码片段的性能。
- **资源优化**: 减少加载的图片大小,优化JavaScript和CSS文件。
- **缓存策略**: 对于不需要实时更新的数据,可以实施缓存策略来加速数据加载。
例如,如果你发现某个交互式图表加载非常缓慢,可以考虑以下策略:
- 使用`plotly`的`layout`函数来设置`AUTOSIZE`为`true`,允许图表自动调整大小。
- 在Shiny中使用`shinyjs`包来减少不必要的页面刷新。
## 6.2 发布与分享仪表板
### 6.2.1 部署到RPubs和GitHub Pages
部署是让仪表板可供公众访问的重要步骤。以下是部署的两种方法:
- **RPubs**: RStudio提供了将R Markdown文档发布到RPubs的功能。只需要在RStudio中点击“Publish”按钮,并遵循向导即可。
- **GitHub Pages**: 可以将仪表板部署到GitHub Pages。首先需要将仪表板的HTML文件和相关资源推送到GitHub仓库,然后按照GitHub Pages的设置来激活页面。
部署过程需要注意一些细节,比如确保所有外部资源链接都是相对路径,以便在不同的环境下能正确加载资源。
### 6.2.2 设置仪表板的访问权限和分享方式
发布后,你可能需要对访问权限进行管理。这可以通过以下几种方式实现:
- **RPubs**: RPubs允许你选择是否公开分享你的文档,或者仅限知道链接的人访问。
- **GitHub Pages**: 可以在GitHub仓库设置中,调整分支设置,使用特定分支作为GitHub Pages的源。此外,你可以利用GitHub的权限系统来管理访问权限。
确保在分享之前,仪表板的内容是符合预期的,没有敏感信息被错误地展示。
## 6.3 持续维护和更新
### 6.3.1 定期更新数据和内容
仪表板的更新通常涉及两个方面:
- **数据更新**: 如果仪表板依赖于实时数据或周期性更新的数据,需要定期重新导入和处理数据。
- **内容更新**: 当业务逻辑或展示需求发生变化时,需要更新代码和文档。
可以通过设置定时任务(例如使用R的`cron`包)来自动化更新数据的过程。
### 6.3.2 监控仪表板的运行状态
最后,仪表板需要持续监控以确保其正常运行。这包括:
- **错误监控**: 使用如`tryCatch`在代码中捕获潜在错误。
- **性能监控**: 监控响应时间和资源使用,确保用户体验。
监控可以使用第三方工具来实现,也可以利用Shiny内置的监控功能。
```r
# 示例代码:使用tryCatch来处理可能出现的错误
result <- tryCatch({
# 这里放置可能出错的代码
}, error = function(e) {
# 这里处理错误情况
print(e)
})
```
上述内容详细说明了如何在仪表板开发周期的不同阶段进行测试、调试、部署和维护。每个步骤都有详细的分析和操作指引,以保证仪表板的稳定运行和及时更新。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供 R 语言数据包的详细教程和实战应用指南,涵盖从基础到高级的广泛主题。从必备数据包到机器学习、时间序列处理、文本挖掘和网络分析,本专栏旨在帮助读者掌握 R 语言的强大功能。通过深入解析和案例分析,读者将学习如何加载、操作和可视化数据,执行统计分析,构建机器学习模型,处理文本和网络数据,以及并行计算。本专栏是数据分析师、研究人员和 R 语言初学者提升技能的宝贵资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
解决组合分配难题:偏好单调性神经网络实战指南(专家系统协同)

# 摘要
本文旨在探讨解决组合分配难题的方法,重点关注偏好单调性理论在优化中的应用以及神经网络的实战应用。文章首先介绍了偏好单调性的定义、性质及其在组合优化中的作用,接着深入探讨了如何
WINDLX模拟器案例研究:3个真实世界的网络问题及解决方案

# 摘要
本文对WINDLX模拟器进行了全面概述,并深入探讨了网络问题的理论基础与诊断方法。通过对比OSI七层模型和TCP/IP模型,分析了网络通信中常见的问题及其分类。文中详细介绍了网络故障诊断技术,并通过案例分析方法展示了理论知识在实践中的应用。三个具体案例分别涉及跨网络性能瓶颈、虚拟网络隔离失败以及模拟器内网络服务崩溃的背景、问题诊断、解决方案实施和结果评估。最后,本文展望了W
【FREERTOS在视频处理中的力量】:角色、挑战及解决方案

# 摘要
FreeRTOS在视频处理领域的应用日益广泛,它在满足实时性能、内存和存储限制、以及并发与同步问题方面面临一系列挑战。本文探讨了FreeRTOS如何在视频处理中扮演关键角色,分析了其在高优先级任务处理和资源消耗方面的表现。文章详细讨论了任务调度优化、内存管理策略以及外设驱动与中断管理的解决方案,并通过案例分析了监控视频流处理、实时视频转码
ITIL V4 Foundation题库精讲:考试难点逐一击破(备考专家深度剖析)
# 摘要
ITIL V4 Foundation作为信息技术服务管理领域的重要认证,对从业者在理解新框架、核心理念及其在现代IT环境中的应用提出了要求。本文综合介绍了ITIL V4的考试概览、核心框架及其演进、四大支柱、服务生命周期、关键流程与功能以及考试难点,旨在帮助考生全面掌握ITIL V4的理论基础与实践应用。此外,本文提供了实战模拟
【打印机固件升级实战攻略】:从准备到应用的全过程解析

# 摘要
本文综述了打印机固件升级的全过程,从前期准备到升级步骤详解,再到升级后的优化与维护措施。文中强调了环境检查与备份的重要性,并指出获取合适固件版本和准备必要资源对于成功升级不可或缺。通过详细解析升级过程、监控升级状态并进行升级后验证,本文提供了确保固件升级顺利进行的具体指导。此外,固件升级后的优化与维护策略,包括调整配置、问题预防和持续监控,旨在保持打印机最佳性能。本文还通过案
【U9 ORPG登陆器多账号管理】:10分钟高效管理你的游戏账号

# 摘要
本文详细探讨了U9 ORPG登陆器的多账号管理功能,首先概述了其在游戏账号管理中的重要性,接着深入分析了支持多账号登录的系统架构、数据流以及安全性问题。文章进一步探讨了高效管理游戏账号的策略,包括账号的组织分类、自动化管理工具的应用和安全性隐私保护。此外,本文还详细解析了U9 ORPG登陆器的高级功能,如权限管理、自定义账号属性以及跨平台使用
【编译原理实验报告解读】:燕山大学案例分析
# 摘要
本文是关于编译原理的实验报告,首先介绍了编译器设计的基础理论,包括编译器的组成部分、词法分析与语法分析的基本概念、以及语法的形式化描述。随后,报告通过燕山大学的实验案例,深入分析了实验环境、工具以及案例目标和要求,详细探讨了代码分析的关键部分,如词法分析器的实现和语法分析器的作用。报告接着指出了实验中遇到的问题并提出解决策略,最后展望了编译原理实验的未来方向,包括最新研究动态和对
【中兴LTE网管升级与维护宝典】:确保系统平滑升级与维护的黄金法则

# 摘要
本文详细介绍了LTE网管系统的升级与维护过程,包括升级前的准备工作、平滑升级的实施步骤以及日常维护的策略。文章强调了对LTE网管系统架构深入理解的重要性,以及在升级前进行风险评估和备份的必要性。实施阶段,作者阐述了系统检查、性能优化、升级步骤、监控和日志记录的重要性。同时,对于日常维护,本文提出监控KPI、问题诊断、维护计划执行以及故障处理和灾难恢复措施。案例研究部分探讨了升级维护实践中的挑战与解决方案。最后,文章展望了LT
故障诊断与问题排除:合泰BS86D20A单片机的自我修复指南
# 摘要
本文系统地介绍了故障诊断与问题排除的基础知识,并深入探讨了合泰BS86D20A单片机的特性和应用。章节二着重阐述了单片机的基本概念、硬件架构及其软件环境。在故障诊断方面,文章提出了基本的故障诊断方法,并针对合泰BS86D20A单片机提出了具体的故障诊断流程和技巧。此外,文章还介绍了问题排除的高级技术,包括调试工具的应用和程序自我修复技术。最后,本文就如何维护和优化单片
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )