对爬取的数据进行去重处理的策略
发布时间: 2024-04-15 17:36:46 阅读量: 15 订阅数: 13 
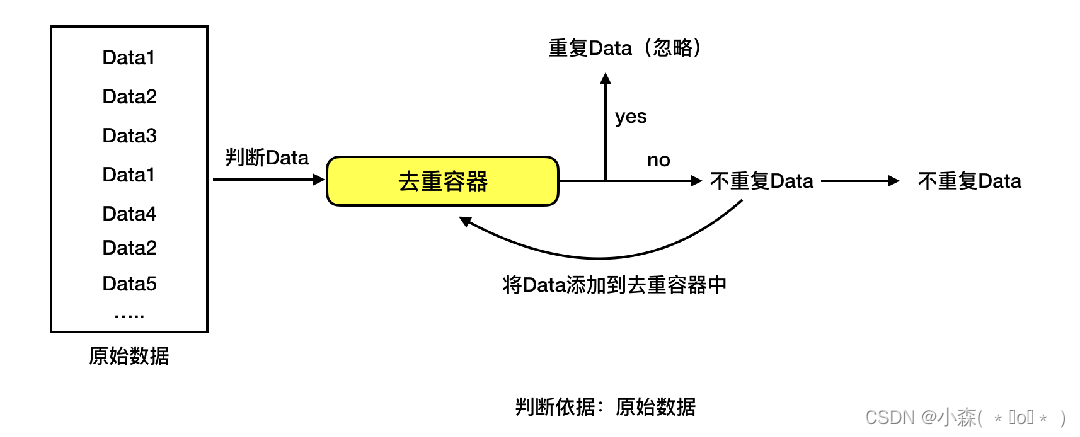
# 1. 引言
爬虫技术已经成为当今信息处理领域中的重要工具,其应用范围非常广泛。首先,爬虫技术可用于互联网数据的爬取,帮助用户快速获取所需信息。其次,爬虫也在数据挖掘与分析中发挥关键作用,通过对大量数据的收集和整理,为用户提供更深层次的数据分析。而数据去重作为爬虫技术中不可或缺的环节,其重要性不言而喻。数据去重能够提高数据质量,避免重复信息对分析结果的影响,同时也能降低存储和处理成本,提高系统的效率和性能。因此,深入研究数据去重技术对于提升爬虫系统的整体质量具有重要意义。
# 2. 数据爬取与存储
#### 网络爬虫工作原理
在网络爬虫的工作中,首先需要进行网页请求与响应。网络爬虫通过模拟浏览器向目标网站发起请求,获取网页返回的数据,并在得到响应后进行 HTML 解析与内容提取。通过解析 HTML 结构,网络爬虫能够提取所需的信息,如文本、图片等数据。
##### 网页请求与响应
网络爬虫通过发送 HTTP 请求来获取网页数据,常用的请求包括 GET、POST 等,服务器会返回相应的响应数据,包括 HTML 内容、响应状态码等。
```python
import requests
url = 'https://www.example.com'
response = requests.get(url)
html_content = response.text
print(html_content)
```
##### HTML解析与内容提取
解析 HTML 是网络爬虫工作中的关键步骤,常用的解析库包括 BeautifulSoup、PyQuery 等,通过这些库可以方便地提取页面中的信息。
```python
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
title = soup.title.text
print("Title: ", title)
# 提取链接
links = soup.find_all('a')
for link in links:
print(link.get('href'))
```
##### 数据存储策略
网络爬虫获取的数据需要进行存储,常见的存储策略包括关系型数据库存储和 NoSQL 数据库存储。关系型数据库适合结构化数据存储,如 MySQL、PostgreSQL;NoSQL 数据库适合非结构化数据存储,如 MongoDB、Redis。
#### 关系型数据库存储
关系型数据库通过表格的形式存储数据,使用 SQL 语言进行操作。可以建立数据表来存储爬取的数据,实现数据的持久化存储和查询。
```sql
CREATE TABLE articles (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(255),
content TEXT
);
```
#### NoSQL数据库存储
NoSQL 数据库以键值对、文档、列族等形式存储数据,适用于大数据量、不规则数据结构的存储需求。部分 NoSQL 数据库支持数据的自动过期,适合爬虫缓存数据的场景。
```javascript
// 使用 MongoDB 存储爬取的数据
db.articles.insertOne({ title: "Article 1", content: "Content 1" });
// 使用 Redis 缓存爬取的数据
SET article:1 "Content 1"
```
通过以上对网络爬虫工作原理及数据存储策略的介绍,可以更深入理解爬虫技术在实际应用中的重要性和复杂性。
# 3. 数据去重技术基础
- #### 数据去重概念介绍
在数据处理过程中,数据重复是一个常见问题。数据去重技术的目的是识别和删除重复的数据,以提高数据处理效率和减少存储成本。数据去重分为两种基本方法:基于哈希算法和基于比较算法。
- #### 哈希算法原
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python爬取静态网页故障排除与优化》专栏深入探讨了爬取静态网页时常见的故障排除和优化策略。文章涵盖了从设置请求头信息、解决编码问题到使用代理IP、Selenium和反验证码机制等各个方面。此外,还介绍了HTML解析库的比较和选用、数据去重、数据存储和定时爬取等技术。专栏还提供了解决403 Forbidden错误、IP封锁、限速和反爬机制的技术方案,以及分布式爬虫、多线程和多进程加速爬虫的原理。通过阅读本专栏,读者将全面掌握Python静态网页爬取的故障排除和优化技巧,提升爬虫的效率、稳定性和数据质量。
专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入了解MATLAB开根号的最新研究和应用:获取开根号领域的最新动态

# 1. MATLAB开根号的理论基础
开根号运算在数学和科学计算中无处不在。在MATLAB中,开根号可以通过多种函数实现,包括`sqrt()`和`nthroot()`。`sqrt()`函数用于计算正实数的平方根,而`nt
NoSQL数据库实战:MongoDB、Redis、Cassandra深入剖析
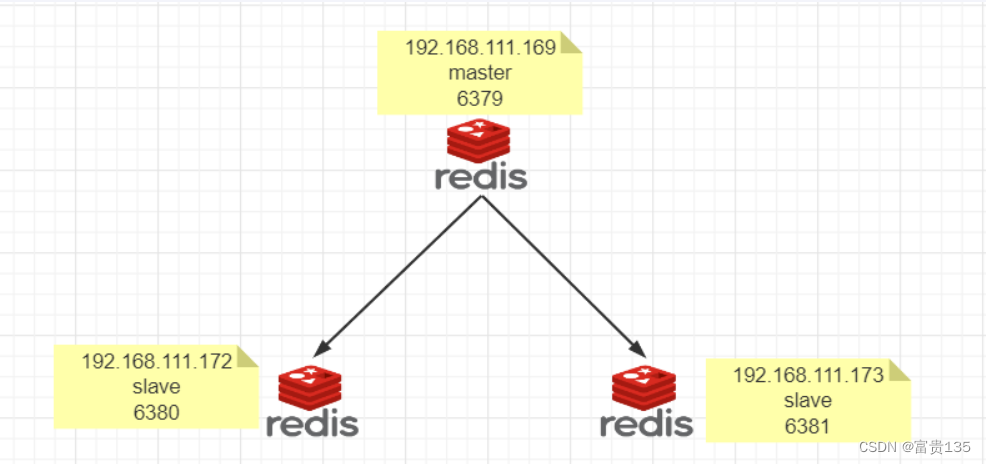
# 1. NoSQL数据库概述
**1.1 NoSQL数据库的定义**
NoSQL(Not Only SQL)数据库是一种非关系型数据库,它不遵循传统的SQL(结构化查询语言)范式。NoSQL数据库旨在处理大规模、非结构化或半结构化数据,并提供高可用性、可扩展性和灵活性。
**1.2 NoSQL数据库的类型**
NoSQL数据库根据其数据模型和存储方式分为以下
MATLAB在图像处理中的应用:图像增强、目标检测和人脸识别
# 1. MATLAB图像处理概述
MATLAB是一个强大的技术计算平台,广泛应用于图像处理领域。它提供了一系列内置函数和工具箱,使工程师
MATLAB符号数组:解析符号表达式,探索数学计算新维度

# 1. MATLAB 符号数组简介**
MATLAB 符号数组是一种强大的工具,用于处理符号表达式和执行符号计算。符号数组中的元素可以是符
MATLAB求平均值在社会科学研究中的作用:理解平均值在社会科学数据分析中的意义

# 1. 平均值在社会科学中的作用
平均值是社会科学研究中广泛使用的一种统计指标,它可以提供数据集的中心趋势信息。在社会科学中,平均值通常用于描述人口特
MATLAB字符串拼接与财务建模:在财务建模中使用字符串拼接,提升分析效率

# 1. MATLAB 字符串拼接基础**
字符串拼接是 MATLAB 中一项基本操作,用于将多个字符串连接成一个字符串。它在财务建模中有着广泛的应用,例如财务数据的拼接、财务公式的表示以及财务建模的自动化。
MATLAB 中有几种字符串拼接方法,包括 `+` 运算符、`strcat` 函数和 `sprintf` 函数。`+` 运算符是最简单的拼接
MATLAB散点图:使用散点图进行信号处理的5个步骤
# 1. MATLAB散点图简介
散点图是一种用于可视化两个变量之间关系的图表。它由一系列数据点组成,每个数据点代表一个数据对(x,y)。散点图可以揭示数据中的模式和趋势,并帮助研究人员和分析师理解变量之间的关系。
在MATLAB中,可以使用`scatter`函数绘制散点图。`scatter`函数接受两个向量作为输入:x向量和y向量。这些向量必须具有相同长度,并且每个元素对(x,y)表示一个数据点。例如,以下代码绘制
图像处理中的求和妙用:探索MATLAB求和在图像处理中的应用

# 1. 图像处理简介**
图像处理是利用计算机对图像进行各种操作,以改善图像质量或提取有用信息的技术。图像处理在各个领域都有广泛的应用,例如医学成像、遥感、工业检测和计算机视觉。
图像由像素组成,每个像素都有一个值,表示该像素的颜色或亮度。图像处理操作通常涉及对这些像素值进行数学运算,以达到增强、分
MATLAB平方根硬件加速探索:提升计算性能,拓展算法应用领域

# 1. MATLAB 平方根计算基础**
MATLAB 提供了 `sqrt()` 函数用于计算平方根。该函数接受一个实数或复数作为输入,并返回其平方根。`sqrt()` 函数在 MATLAB 中广泛用于各种科学和工程应用中,例如信号处理、图像处理和数值计算。
**代码块:**
```matlab
% 计算实数的平方根
x = 4;
sqrt_x = sqrt(x);
%
MATLAB柱状图在信号处理中的应用:可视化信号特征和频谱分析

# 1. MATLAB柱状图概述**
MATLAB柱状图是一种图形化工具,用于可视化数据中不同类别或组的分布情况。它通过绘制垂直条形来表示每个类别或组中的数据值。柱状图在信号处理中广泛用于可视化信号特征和进行频谱分析。
柱状图的优点在于其简单易懂,能够直观地展示数据分布。在信号处理中,柱状图可以帮助工程师识别信号中的模式、趋势和异常情况,从而为信号分析和处理提供有价值的见解。
# 2. 柱状图在信号处理中的应用
柱状图在信号处理
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )