Go日志结构化输出:log包实现结构化日志记录的快速指南
发布时间: 2024-10-21 23:15:51 阅读量: 26 订阅数: 32 

# 1. 日志结构化输出概述
在现代软件开发与运维实践中,日志扮演着不可或缺的角色。日志数据是系统运行情况的直接反映,对于故障诊断、性能监控、安全审计等方面都至关重要。随着信息技术的发展,传统的非结构化日志已不能满足日益复杂的系统管理和分析需求,从而催生了日志结构化输出的概念。
结构化日志输出是指将日志信息按照预定义的格式(例如JSON、XML等)进行输出,使得日志内容可以被机器更容易地解析和处理。结构化日志相比传统的文本日志,提供了更丰富的上下文信息和更快的查询速度,便于自动化工具的使用和数据的可视化展现。
在本章中,我们将介绍日志结构化输出的基础知识,并探讨其重要性与优势。这将为后续章节深入讨论Go语言中的日志结构化实现及其高级应用打下坚实的基础。
# 2. Go语言中的log包基础
Go语言提供的log包是一个基础且功能丰富的日志库,它简化了开发者记录和管理日志的过程。本章节将详细介绍log包的基本使用方法,包括日志级别和日志文件的管理,以及如何利用Go的log包在应用程序中进行有效的日志记录。
## 2.1 log包的基本使用方法
### 2.1.1 log包提供的核心功能介绍
Go的log包提供了一组用于输出日志消息的功能。核心功能包括:
- **基本日志记录**:利用`log.Print`, `log.Printf`, `log.Println`等方法输出基本的日志消息。
- **日志级别**:支持设置日志级别,如DEBUG、INFO、WARNING、ERROR、PANIC、FATAL。
- **日志格式化**:允许自定义日志消息的格式。
- **日志文件写入**:可以将日志输出到文件而非仅限于控制台。
- **日志前缀**:可以添加前缀信息,如时间戳、文件名等,以增加日志的可读性和追踪性。
### 2.1.2 日志格式化输出的简单示例
下面是一个使用Go语言log包进行日志记录的简单示例:
```go
package main
import (
"log"
)
func main() {
log.Println("This is a simple log line.")
log.Printf("This is a formatted log line: %s", "hello world")
}
```
以上代码将输出如下日志:
```
2023/04/01 12:00:00 This is a simple log line.
2023/04/01 12:00:00 This is a formatted log line: hello world
```
## 2.2 日志级别和日志输出
### 2.2.1 Go中的日志级别定义
在Go的log包中,日志级别定义了日志的重要程度,主要有以下几种:
- **DEBUG**: 用于开发调试信息。
- **INFO**: 用于一般运行信息。
- **WARNING**: 用于警告信息。
- **ERROR**: 用于错误信息。
- **PANIC**: 当发生严重错误导致程序崩溃时输出。
- **FATAL**: 致命错误,输出后退出程序。
### 2.2.2 调整和自定义日志级别
默认情况下,log包会输出所有级别的日志。在实际应用中,我们通常会根据需要调整日志级别,忽略某些不必要记录的日志。这可以通过调用`log.SetFlags`和`log.SetPrefix`方法来实现。例如:
```go
package main
import (
"log"
)
func main() {
log.SetFlags(log.Ldate | log.Ltime | log.Lshortfile) // 输出带日期、时间和文件路径的日志
log.Println("This is a log entry with a custom format.")
}
```
## 2.3 日志文件的写入和管理
### 2.3.1 文件日志输出的配置方法
将日志输出到文件比控制台更加方便日志分析和长期存储。Go的log包支持将日志写入到文件,可以通过`log.OpenFile`函数来创建或打开一个文件,并进行日志写入。以下是一个简单的例子:
```go
package main
import (
"log"
"os"
)
func main() {
// 打开一个文件用于日志写入
file, err := os.OpenFile("app.log", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if err != nil {
log.Fatalf("Failed to open log ***", err)
}
defer file.Close()
// 创建一个logger
logger := log.New(file, "app: ", log.LstdFlags)
logger.Println("This is a log entry written to a file.")
}
```
### 2.3.2 日志文件的轮转策略与管理
在生产环境中,日志文件会逐渐增大,因此日志轮转策略变得尤为重要,它允许自动地将日志文件分割成多个文件,并按照一定策略进行管理。Go标准库的log包没有内建支持日志轮转,通常需要与第三方库(例如logrotate)或自定义脚本来实现。
接下来,让我们探索如何在Go中实现结构化日志记录。
# 3. 结构化日志的理论基础
### 3.1 结构化日志与非结构化日志的区别
结构化日志与非结构化日志是两种不同类型的数据记录方式,它们在日志管理、查询和分析中发挥着不同的作用。
#### 3.1.1 非结构化日志的局限性分析
非结构化日志是指日志内容通常以纯文本形式存在,没有固定格式和结构,其内容通常是一段可读的文本。这种日志的格式自由,但在处理和查询方面存在明显的局限性。非结构化日志的内容通常需要通过全文搜索或正则表达式进行匹配,对于复杂的查询和统计分析则相对困难。在大规模日志系统中,非结构化日志容易导致存储和索引问题,查询效率低下。另外,随着日志量的增长,日志中的关键信息也难以快速定位,这增加了问题诊断和监控的难度。
#### 3.1.2 结构化日志的优势和应用场景
结构化日志是将日志信息按照预定义的格式进行记录,通常包含时间戳、日志级别、消息和一系列键值对。与非结构化日志相比,结构化日志便于机器解析和处理,容易进行过滤、排序、聚合等操作,极大提高了日志的处理效率和分析的准确性。例如,在实时监控、日志聚合、大数据分析等场景中,结构化日志都能提供更深层次的洞察。此外,由于其格式固定,结构化日志可以被各种日志管理工具轻松处理,例如通过ELK栈进行日志的聚合、分析和可视化,极大地提高了运维效率。
### 3.2 结构化日志的数据模型
结构化日志的基础是数据模型,这个模型定义了日志内容的结构和如何表达这些内容。
#### 3.2.1 日志数据模型的定义和重要性
数据模型在结构化日志中起着至关重要的作用。它定义了日志条目的标准格式和字段,确保了日志信息的标准化和一致性。一个良好的数据模型可以促进日志数据的有效存储和快速检索,对于日志的后期分析和可视化具有重要意义。通过定义好数据模型,可以为日志中的每个字段赋予明确的意义和类型,使得日志分析过程更加直观和高效。
#### 3.2.2 日志数据模型在Go中的实践
在Go语言中,可以通过结构体和JSON等编码方式来定义结构化日志的数据模型。下面是一个使用Go语言定义日志数据模型的示例代码:
```go
type LogEntry struct {
Timestamp time.Time `json:"timestamp"`
Level string `json:"level"`
Message string `json:"message"`
Error string `json:"error,omitempty"`
Context map[string]string `json:"context,omitempty"`
}
```
上述代码定义了一个日志条目模型,包含时间戳、日志级别、消息、可选的错误信息以及上下文信息。使用结构体定义日志模型,可以方便地进行JSON序列化和反序列化,这在日志的存储和传输中非常有用。
### 3.3 结构化日志的字段和键值对
结构化日志通过键值对记录信息,键(key)是固定的标识符,值(value)是对应的数据。
#### 3.3.1 字段的命名规则和最佳实践
键(字段名)的命名应遵循一

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Go 语言中的日志处理,重点介绍了 log 包。通过一系列文章,您将了解 10 个实践技巧,掌握 log 包的精髓;了解 log 包与其他日志库的 5 大优势;掌握 3 个步骤高效使用 log 包;获取 log 包性能测试和优化的独家秘笈;学习 4 种保护敏感信息的方法;掌握 5 个步骤扩展实现自定义日志级别;快速指南实现结构化日志记录;了解日志文件自动管理的最佳实践;结合 context 包实现链式日志记录的技巧;集成告警机制的 5 个最佳实践;使用高级技巧进行日志数据分析;实现日志精细控制的 7 种方法;转换多格式日志的 6 个步骤;高并发场景下的 5 种优化策略;提升高负载性能的 4 大技巧;集成消息队列的高效方法;以及远程传输和持久化解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MTBF计算基础:从零开始,一文读懂MIL-HDBK-217F标准(附实战教程)

# 摘要
本文详细探讨了MTBF(平均无故障时间)与可靠性的基本概念,并深入解读了MIL-HDBK-217F标准,该标准广泛应用于评估电子和机械设备的可靠性。通过对MIL-HDBK-217F标准的历史背景、应用、基本假设和计算模型的解析,本文阐述了MTBF的计算方法,并提供了一个实战计算教程。此外,文章还探讨了如何通过优化策略和常见技术来提高MTBF,并通过案例研究展示这些策略的实际应用。最后,本文介绍了MTBF的测试方法、验证流
【通达信公式实战演练】:掌握高级调试技巧,最佳实践大公开

# 摘要
通达信公式是为金融市场分析设计的一套强大的工具语言,广泛应用于交易策略构建、市场指标分析以及图表分析等领域。本文首先介绍了通达信公式的概念和基础,然后深入解析了其语言的基本语法、数据类型和结构、高级特性。随后,文章通过实战应用,探讨了市场指标分析、交易策略构建与回测、高级图表应用等关键主题。进一步,本文对通达信公式的调试、性能优化以及安全性问题进行了详细讨论,并探讨
ODB++兼容性挑战:掌握不同软件间无缝转换的秘诀

# 摘要
本文综合探讨了ODB++格式在印刷电路板(PCB)设计中的应用及其与其他格式的兼容性问题。首先概述了ODB++格式及其在PCB设计中的作用,接着分析了ODB++与其他PCB设计格式如Gerber和Excellon之间的差异及兼容性挑战的原因。文章还介绍了ODB++兼容性转换的理论基础,包括数据转换模型和关键技术,并提供了实践应用中的转换工具介绍、设置与配置,以及转换过程中问题的解决方案。通过案例研究
激光对刀仪精度优化秘籍:波龙型号的精准校准
# 摘要
激光对刀仪作为制造业中重要的精密测量工具,对于提高机械加工的精确度和效率具有重要作用。本文首先介绍了激光对刀仪的技术背景及其在制造业中的应用,进而探讨了波龙型号激光对刀仪的理论基础,包括其工作原理、关键技术和精度参数。接着,本文详细阐述了精度校准的实践步骤、关键操作以及校准后的精度验证方法。进一步地,本文探讨了精度提升的技巧、设备维护策略,并通过案例分析提炼了成功经验。最后,本文展望了激光对刀仪精度优化的未来发展方向,包括人工智能、机器学习以及高精度传感器技术的应用前景,并讨论了行业发展趋势与挑战。通过对这些方面的深入分析,本文旨在为激光对刀仪的研究和应用提供有价值的参考。
# 关
【Fluent UDF高级应用技巧】:解锁复杂流体模拟的新世界

# 摘要
Fluent UDF(User-Defined Functions)为ANSYS Fluent提供了一种强大的自定义功能,使得用户能够通过编写代码来扩展Fluent内置的功能。本文首先介绍了Fluent UDF的基础知识,包括函数类型、声明、宏定义及使用,以及数据存储和管理。接着,文中探讨了流体模拟中的高级特性应用,如边界条件处理、复杂流体模型自定义和多相流、反应流模拟的U
ISO 16845-1标准物理信号传输机制:专家技术细节与实现指南

# 摘要
ISO 16845-1标准是针对物理信号传输的一套详细指南,涵盖了从理论基础到实际应用的全面内容。本文首先概述了ISO 16845-1标准,接着深入探讨了物理信号的定义、特性、传输原理以及标准中所规定的传输机制
确保Verilog除法器正确性的关键:验证与测试的最佳实践
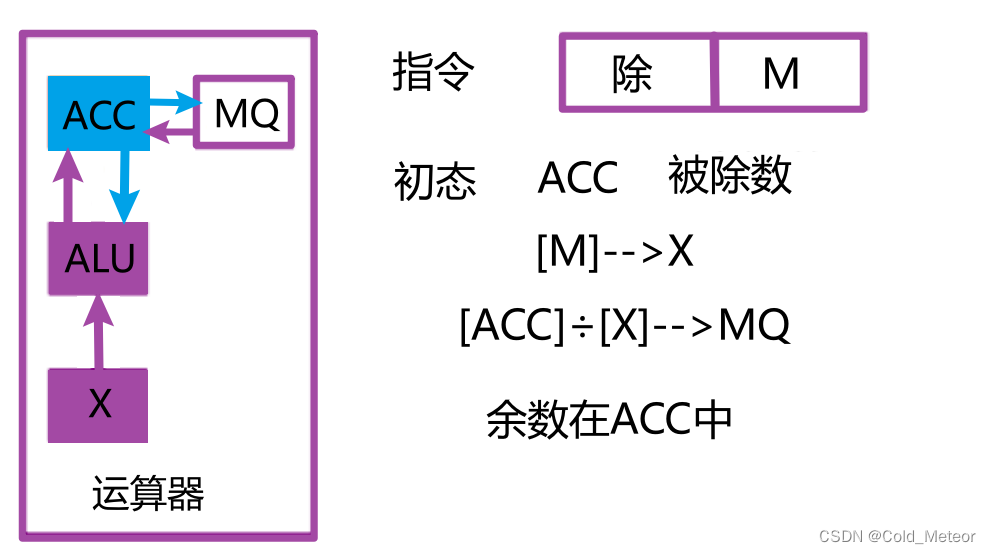
# 摘要
本文详细介绍了Verilog除法器的设计基础、理论基础、验证方法、测试策略以及高级验证技巧。首先,探讨了除法器设计的基础知识和数学原理,随后深入讨论了除法器的硬件实现,包括不同类型的除法器和硬件优化技术。接着,文章详述了除法器的验证方法,涵盖功能仿真验证和形式化验证,并解释了自动化测试框架和覆盖率分析在测试策略中的应用。文章最后介绍了断言驱动开发、跨时钟域验证以及验证计划和管理的高级技巧,为硬件设计者提供了一
【文档转换专家】:掌握Word到PDF无缝转换的终极技巧
# 摘要
文档转换是电子文档处理中的一个重要环节,尤其是从Word到PDF的转换,因其实用性广泛受到关注。本文首先概述了文档转换的基础知识及Word到PDF转换的必要性。随后,深入探讨了转换的理论基础,包括格式转换原理、Word与PDF格式的差异,以及转换过程中遇到的布局、图像、表格、特殊字符处理和安全可访问性挑战。接着,文章通过介绍常用转换工具,实践操作步骤及解决
计算机二级Python实战:文件操作与数据持久化的巧妙应用

# 摘要
本文深入探讨了Python中文件操作的基础知识、数据持久化的机制以及它们在实际应用中的结合。首先,本文介绍了Python进行文件操作的基础,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )