【异步I_O进阶】:wsgiref.handlers与异步I_O的完美结合
发布时间: 2024-10-13 10:00:24 阅读量: 17 订阅数: 27 

FlexPaper-js-vresion.rar_flexpaper_flexpaper_handlers_flexpaperf
# 1. 异步I/O基础与wsgiref.handlers概述
## 1.1 异步I/O基础
异步I/O是一种编程技术,它允许程序在等待I/O操作(如磁盘读写、网络通信)完成时,继续执行其他任务,而不是阻塞等待。这种技术在处理大量并发连接时尤为重要,因为它可以显著提高程序的吞吐量和响应速度。
### 1.1.1 同步与异步I/O的区别
在同步I/O模型中,程序执行一个操作,必须等待该操作完成才能继续执行后续操作。这会导致CPU空闲等待I/O完成,特别是在I/O密集型应用中效率低下。
相比之下,异步I/O允许程序在发起I/O操作后,立即继续执行其他任务,而无需等待I/O操作完成。当I/O操作完成时,程序会得到通知,并在适当的时候处理I/O结果。
### 1.1.2 异步I/O在性能上的优势
异步I/O的优势主要体现在它能够更有效地利用系统资源,尤其是在多核处理器和高并发网络服务中。通过减少线程或进程的使用,降低了上下文切换的开销,并且可以同时处理更多的连接和任务。
## 1.2 wsgiref.handlers概述
### 1.2.1 wsgiref.handlers简介
Python的`wsgiref.handlers`模块提供了一个基础框架,用于构建符合WSGI(Web Server Gateway Interface)标准的Web应用程序。WSGI是一种简单的、通用的Python Web服务器和应用程序之间的接口标准,它定义了Web服务器和Web应用程序或框架之间的交互方式。
### 1.2.2 wsgiref.handlers与WSGI协议
`wsgiref.handlers`模块实现了WSGI协议的基本要求,包括规范的环境变量、请求对象和响应对象。通过使用这个模块,开发者可以创建简单的WSGI应用程序,并且可以作为Web服务器的基础,比如在开发和测试阶段。
在本章中,我们将从基础概念开始,逐步深入理解异步I/O的工作原理,并介绍`wsgiref.handlers`模块的基础知识。这些知识为后续章节中探讨异步I/O的核心概念、实现机制以及与`wsgiref.handlers`的结合提供了坚实的基础。
# 2. 异步I/O的核心概念与理论基础
## 2.1 异步I/O的定义与优势
### 2.1.1 同步与异步I/O的区别
在深入探讨异步I/O的优势之前,我们需要先明确同步与异步I/O的区别。同步I/O操作是指当一个任务开始执行时,直到该任务完成之前,CPU不会执行其他任务。这种模式下,每个I/O操作都可能造成程序的阻塞,因为程序需要等待I/O操作完成。例如,当一个程序向磁盘写入数据时,它必须等待数据完全写入后才能继续执行后续操作。
异步I/O则允许程序发起一个I/O操作后继续执行其他任务,而无需等待I/O操作完成。这意味着CPU可以在等待I/O操作完成的同时执行其他工作,从而提高了程序的并发处理能力。异步I/O的这一特性特别适合于I/O密集型应用,如Web服务器,它们经常需要处理大量的网络请求和磁盘操作。
### 2.1.2 异步I/O在性能上的优势
异步I/O在性能上的优势主要体现在以下几个方面:
1. **提高资源利用率**:通过异步I/O,CPU和其他资源可以在I/O操作等待期间被其他任务利用,从而提高整体资源利用率。
2. **减少延迟**:异步操作不需要等待I/O操作完成即可继续执行,这减少了请求处理的延迟时间,对于需要快速响应的应用尤其重要。
3. **提升吞吐量**:由于异步I/O可以在等待I/O完成的同时处理其他任务,系统的总体吞吐量也会得到提升,这对于高并发的场景非常有利。
在本章节中,我们将详细探讨异步I/O的核心概念,并通过实例和代码示例来加深理解。接下来,我们将介绍异步I/O的实现机制,包括事件驱动模型以及回调函数与Future对象的使用。
## 2.2 异步I/O的实现机制
### 2.2.1 事件驱动模型
事件驱动模型是异步I/O实现的核心机制之一。在这种模型中,应用程序不是由CPU直接执行任务,而是由事件来驱动。这些事件通常是由I/O操作产生的,例如网络请求、文件读写等。当一个事件发生时,系统会通知相应的事件处理程序来处理该事件。
#### 事件循环
事件驱动模型的关键是事件循环,它不断地检查事件队列,等待事件发生,并将事件分发给相应的事件处理程序。在Python中,`asyncio`库提供了一个事件循环的实现,允许开发者编写异步代码。
#### 代码示例
以下是一个简单的`asyncio`事件循环的代码示例:
```python
import asyncio
async def main():
print('Hello ...')
await asyncio.sleep(1)
print('... World!')
# 运行事件循环
asyncio.run(main())
```
在这个例子中,`main()`函数是一个异步函数,它首先打印"Hello ...",然后等待`asyncio.sleep(1)`完成,最后打印"... World!"。`asyncio.run(main())`启动事件循环并运行`main()`函数。
### 2.2.2 回调函数与Future对象
回调函数和Future对象是异步编程中常用的两种模式,它们用于处理异步操作的结果。
#### 回调函数
回调函数是一种在事件发生后执行的函数。在异步编程中,回调函数通常用于处理异步操作的结果。
```python
def callback(future):
print('Callback is called with result:', future.result())
# 创建一个Future对象
future = asyncio.Future()
# 注册回调函数
future.add_done_callback(callback)
# 设置Future对象的结果
future.set_result('Done')
# 输出结果
print(future.result())
```
在这个例子中,`callback()`函数是一个回调函数,它被注册到一个Future对象上。当Future对象的结果被设置后,回调函数会被调用。
#### Future对象
Future对象代表一个可能还没有完成的异步操作的结果。开发者可以通过Future对象来获取异步操作的结果。
```python
async def main():
future = asyncio.Future()
# 启动一个异步任务
task = asyncio.create_task(some_async_function())
# 等待Future对象的结果
await future
print('Task completed:', future.result())
# 模拟一个异步函数
async def some_async_function():
await asyncio.sleep(1)
return 'Result'
asyncio.run(main())
```
在这个例子中,`main()`函数创建了一个Future对象和一个异步任务。通过`await future`,事件循环会等待异步任务完成,并将结果设置到Future对象中。
通过本章节的介绍,我们已经对异步I/O的核心概念和理论基础有了初步的了解。在下一节中,我们将深入探讨`wsgiref.handlers`的作用与功能,以及它与WSGI协议的关系。
## 2.3 wsgiref.handlers的作用与功能
### 2.3.1 wsgiref.handlers简介
`wsgiref.handlers`是Python标准库中的一个模块,它提供了一些实用的类和函数,用于创建符合WSGI(Web Server Gateway Interface)协议的Web服务器和应用程序。WSGI是一个简单的、定义良好、语言无关的接口,用于Web服务器和Python Web应用程序或框架之间的通信。
### 2.3.2 wsgiref.handlers与WSGI协议
WSGI协议定义了一个请求处理的接口,它包含两个参数:环境字典(environ)和开始响应的可调用对象(start_response)。以下是一个简单的WSGI应用程序示例:
```python
def simple_app(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/plain')])
return [b'Hello, WSGI!']
```
在这个例子中,`simple_app()`函数是一个WSGI应用程序,它接收环境字典和开始响应的函数,然后返回一个响应体。
#### wsgiref.handlers中的类
`wsgiref.handlers`模块中包含了一些用于构建WSGI服务器的类,例如`BaseHandler`、`ServerBase`等。这些类提供了构建WSGI服务器所需的基本功能,包括处理HTTP请求和响应、启动服务器等。
#### 代码示例
以下是一个使用`wsgiref.handlers`模块创建一个简单的WSGI服务器的代码示例:
```python
from wsgiref.handlers import SimpleServer
class WSGIServer(SimpleServer):
pass
def simple_app(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/plain')])
return [b'Hello, WSGI!']
if __name__ == '__main__':
httpd = WSGIServer(('', 8000))
httpd.set_app(simple_app)
print('Serving on port 8000...')
httpd.serve_forever()
```
在这个例子中,我们创建了一个自定义的`WSGIServer`类,并使用它来启动一个简单的WSGI服务器。服务器监听在本地的8000端口,并使用`simple_app()`函数作为WSGI应用程序。
通过本章节的介绍,我们已经了解了异步I/O的核心概念与理论基础,以及`wsgiref.handlers`的作用与功能。在下一章中,我们将深入探讨如何将`wsgiref.handlers`与异步I/O结合,以及如何编写异步WSGI应用程序。
# 3. wsgiref.handlers与异步I/O的实践结合
## 3.1 异步I/O在WSGI服务器中的应用
### 3.1.1 异步I/O事件循环的集成
在本章节中,我们将深入探讨如何将异步I/O事件循环集成到WSGI服务器中。异步I/O的核心在于事件循环,它负责监听和处理事件,从而无需阻塞即可进行I/O操作。在Python中,`asyncio`库提供了事件循环的实现,而`wsgiref.handlers`是WSGI标准库中的一个模块,用于处理HTTP请求和响应。
要将异步I/O集成到WSGI服务器中,首先需要创建一个异步事件循环,并在此循环中运行WSGI应用程序。以下是一个简单的示例,展示了如何使用`asyncio`和`wsgiref.handlers`来实现这一过程:
```python
import asyncio
from wsgiref.simple_server import make_server
from wsgiref.handlers import BaseHandler
class AsyncHandler(BaseHandler):
async def handle(self):
# 处理请求的逻辑
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
await self.wfile.write(b'Hello, asynchronous world!')
async def run_server():
server = make_server('', 8000, AsyncHandler)
await server.serve_forever()
loop = asyncio.get_event_loop()
loop.run_until_complete(run_server())
loop.close()
```
在这个示例中,我们定义了一个`AsyncHandler`类,它继承自`wsgiref.handlers.BaseHandler`。我们在`AsyncHandler`中重写了`handle`方法,使其成为异步函数。我们使用`asyncio`的`run_server`函数来创建服务器,并在事件循环中运行它。
### 3.1.2 wsgiref.handlers的异步支持
`wsgiref.handlers`模块本身并不直接支持异步操作,但它提供了一个基础的WSGI应用程序接口,可以通过扩展和适配来实现异步支持。在上一小节的示例中,我们通过定义一个异步的`handle`方法来实现这一点。然而,这种方法并不是最高效的,因为它需要在每次请求时都创建一个新的事件循环。
为了提高效率,我们可以使用`asyncio`和`wsgiref.simple_server`模块来创建一个异步的WSGI服务器。这需要我们自定义一个异步的WSGI应用程序接口,如下所示:
```python
import asyncio
from wsgiref.simple_server import ServerInterface
class AsyncWSGIInterface(ServerInterface):
async def get_app(self):
# 返回一个异步WSGI应用程序
async def application(environ, start_response):
# 处理请求的逻辑
await asyncio.sleep(0) # 模拟异步操作
start_response('200 OK', [('Content-Type', 'text/html')])
return [b'Hello, asynchronous world!']
return application
async def run_async_server(interface):
server = await asyncio.start_server(interface, '', 8000)
async with server:
await server.serve_forever()
loop = asyncio.get_event_loop()
loop.run_until_complete(run_async_server(AsyncWSGIInterface()))
loop.close()
```
在这个示例中,我们定义了一个`AsyncWSGIInterface`类,它继承自`wsgiref.simple_server.ServerInterface`。我们在`AsyncWSGIInterface`中重写了`get_app`方法,使其返回一个异步的WSGI应用程序。然后,我们使用`asyncio`的`run_async_server`函数来创建和启动服务器。
通过这种方式,我们可以更好地集成异步I/O事件循环和WSGI服务器,从而提高性能并减少资源消耗。
## 3.2 wsgiref.handlers

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库文件 wsgiref.handlers,从其基本概念到高级应用。通过一系列文章,您将了解 WSGI 协议的原理,掌握 wsgiref.handlers 的入门到精通知识,揭秘其工作原理和性能优化策略。此外,专栏还涵盖了异步处理、调试、错误处理、性能提升、安全防护、异步 I/O 集成、代码重构、兼容性分析和社区资源等方面,为您提供全面的 wsgiref.handlers 使用指南。无论是初学者还是经验丰富的开发者,本专栏都将帮助您充分利用 wsgiref.handlers,构建高效、可靠的 Web 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【C#网络编程揭秘】:TCP_IP与UDP通信机制全解析
# 摘要
本文全面探讨了C#网络编程的基础知识,深入解析了TCP/IP架构下的TCP和UDP协议,以及高级网络通信技术。首先介绍了C#中网络编程的基础,包括TCP协议的工作原理、编程模型和异常处理。其次,对UDP协议的应用与实践进行了讨论,包括其特点、编程模型和安全性分析。然后,详细阐述了异步与同步通信模型、线程管理,以及TLS/SSL和NAT穿透技术在C#中的应用。最后,通过实战项目展示了网络编程的综合应用,并讨论了性能优化、故障排除和安全性考量。本文旨在为网络编程人员提供详尽的指导和实用的技术支持,以应对在实际开发中可能遇到的各种挑战。
# 关键字
C#网络编程;TCP/IP架构;TCP
深入金融数学:揭秘随机过程在金融市场中的关键作用

# 摘要
随机过程理论是分析金融市场复杂动态的基础工具,它在期权定价、风险管理以及资产配置等方面发挥着重要作用。本文首先介绍了随机过程的定义、分类以及数学模型,并探讨了模拟这些过程的常用方法。接着,文章深入分析了随机过程在金融市场中的具体应用,包括Black-Scholes模型、随机波动率模型、Value at Risk (VaR)和随机控制理论在资产配置中的应
CoDeSys 2.3中文教程高级篇:自动化项目中面向对象编程的5大应用案例
# 摘要
本文全面探讨了面向对象编程(OOP)的基础理论及其在CoDeSys 2.3平台的应用实践。首先介绍面向对象编程的基本概念与理论框架,随后深入阐释了OOP的三大特征:封装、继承和多态,以及设计原则,如开闭原则和依赖倒置原则。接着,本文通过CoDeSys 2.3平台的实战应用案例,展示了面向对象编程在工业自动化项目中
【PHP性能提升】:专家解读JSON字符串中的反斜杠处理,提升数据清洗效率
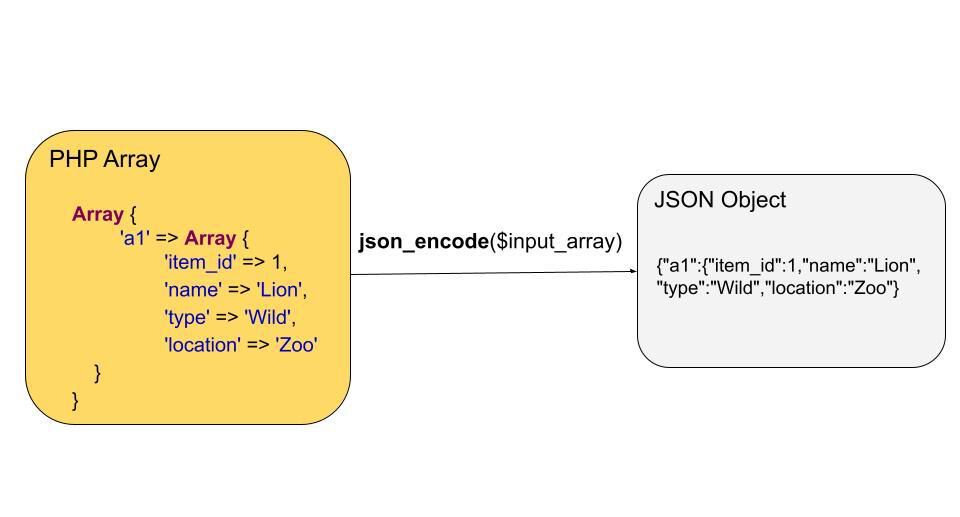
# 摘要
本文深入探讨了在PHP环境中处理JSON字符串的重要性和面临的挑战,涵盖了JSON基础知识、反斜杠处理、数据清洗效率提升及进阶优化等关键领域。通过分析JSON数据结构和格式规范,本文揭示了PHP中json_encode()和json_decode()函数使用的效率和性能考量。同时,本文着重讨论了反斜杠在JSON字符串中的角色,以及如何高效处理以避免常见的数据清洗性能
成为行业认可的ISO 20653专家:全面培训课程详解

# 摘要
ISO 20653标准作为铁路行业的关键安全规范,详细规定了安全管理和风险评估流程、技术要求以及专家认证路径。本文对ISO 20653标准进行了全面概述,深入分析了标准的关键要素,包括其历史背景、框架结构、安全管理系统要求以及铁路车辆安全技术要求。同时,本文探讨了如何在企业中实施ISO 20653标准,并分析了在此过程中可能遇到的挑战和解决方案。此外,文章还强调了持续专业发展的重要性
Arm Compiler 5.06 Update 7实战指南:专家带你玩转LIN32平台性能调优

# 摘要
本文详细介绍了Arm Compiler 5.06 Update 7的特点及其在不同平台上的性能优化实践。文章首先概述了Arm架构与编译原理,并针对新版本编译器的新特性进行了深入分析。接着,介绍了如何搭建编译环境,并通过编译实践演示了基础用法。此外,文章还
【62056-21协议深度解析】:构建智能电表通信系统的秘诀
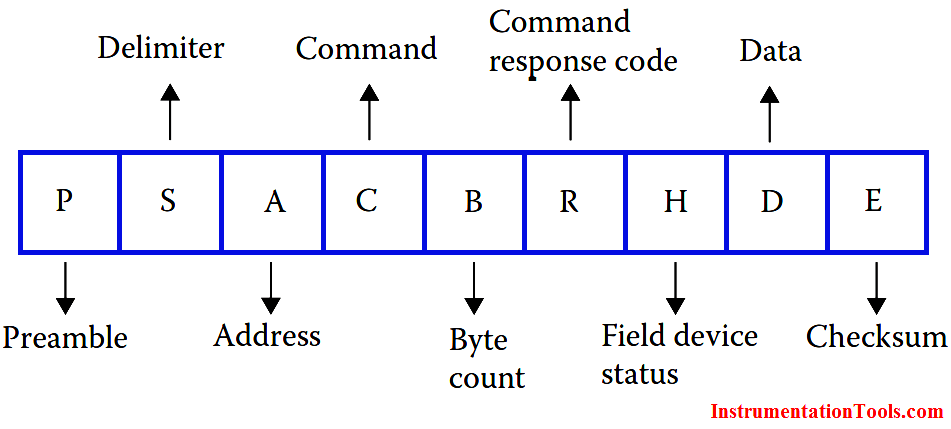
# 摘要
本文对62056-21通信协议进行了全面概述,分析了其理论基础,包括帧结构、数据封装、传输机制、错误检测与纠正技术。在智能电表通信系统的实现部分,探讨了系统硬件构成、软件协议栈设计以及系统集成与测试的重要性。此外,本文深入研究了62056-21协议在实践应用中的案例分析、系统优化策略和安全性增强措
5G NR同步技术新进展:探索5G时代同步机制的创新与挑战

# 摘要
本文全面概述了5G NR(新无线电)同步技术的关键要素及其理论基础,探讨了物理层同步信号设计原理、同步过程中的关键技术,并实践探索了同步算法与
【天龙八部动画系统】:骨骼动画与精灵动画实现指南(动画大师分享)
# 摘要
本文系统地探讨了骨骼动画与精灵动画的基本概念、技术剖析、制作技巧以及融合应用。文章从理论基础出发,详细阐述了骨骼动画的定义、原理、软件实现和优化策略,同时对精灵动画的分类、工作流程、制作技巧和高级应用进行了全面分析。此外,本文还探讨了骨骼动画与精灵动画的融合点、构建跨平台动画系统的策略,并通过案例分
【Linux二进制文件执行权限问题快速诊断与解决】:一分钟搞定执行障碍
# 摘要
本文针对Linux环境下二进制文件执行权限进行了全面的分析,概述了权限的基本概念、构成和意义,并探讨了执行权限的必要性及其常见问题。通过介绍常用的权限检查工具和方法,如使用`ls`和`stat`命令,文章提供了快速诊断执行障碍的步骤和技巧,包括文件所有者和权限设置的确认以及脚本自动化检查。此外,本文还深入讨论了特殊权限位、文件系统特性、非标准权限问题以及安全审计的重要性。通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )