C++程序员必备:GCC编译器优化全解析,提升编译效率
发布时间: 2024-10-23 21:22:08 阅读量: 109 订阅数: 24 

详细分析一个块设备驱动程序开发过程

# 1. GCC编译器简介与安装
GCC(GNU Compiler Collection)是一个编译器集合,广泛用于C、C++、Objective-C、Fortran、Ada和其它编程语言的编译。GCC在Linux以及其它类Unix操作系统中占有主导地位,是自由软件领域的关键部分,其编译器的输出质量与编译速度都是业界的佼佼者。
## GCC编译器的安装
安装GCC编译器通常非常简单,尤其是对于使用Linux和macOS的用户。以Ubuntu为例,只需打开终端并执行以下命令:
```bash
sudo apt-get update
sudo apt-get install build-essential
```
这会安装GCC以及与之配套的工具链,包括G++(C++编译器)、make等。
对于macOS用户,可以通过安装Xcode命令行工具来获取GCC。在终端中运行:
```bash
xcode-select --install
```
这条命令会提示安装Xcode命令行工具,其中包括GCC编译器。需要注意的是,macOS上的GCC实际上是Clang的包装器,Clang作为GCC的一个替代品,与GCC有很高的兼容性。
对于Windows用户,可以使用MinGW或者Cygwin来安装GCC,或者使用Microsoft自家的编译器工具链。
在安装完成后,通过运行`gcc --version`可以检查GCC是否已正确安装,并且查看其版本号。这有助于确保编译器满足项目的需求。接下来,我们可以深入了解GCC编译器的基本用法,以及如何通过各种编译选项进行优化。
# 2. GCC编译器的基本用法
### 2.1 GCC编译器的命令行参数
GCC编译器使用一系列命令行参数来控制编译过程,从预处理到最终链接成可执行文件。了解和熟悉这些参数对于进行高效的编程和项目构建至关重要。
#### 2.1.1 常用编译选项
GCC提供了大量编译选项,下面是一些常用选项的示例和解释:
- **-c**:仅编译和汇编指定源文件,但不进行链接。这个选项常用于构建目标文件,这些文件之后可以被链接在一起形成最终的应用程序或库。
- **-o <文件名>**:指定输出文件的名称。如果省略这个选项,GCC通常会给输出文件默认名称,比如在Linux上,默认的可执行文件名为`a.out`。
- **-I<目录>**:指定搜索头文件的目录。通常在大型项目中,为了维护结构清晰,开发者会将源代码和头文件分开放置。
- **-L<目录>**:指定搜索库文件的目录。与头文件类似,库文件的位置也可能会根据项目的需要进行定制。
- **-l<库名>**:链接指定的库文件。链接库可以是静态库(.a文件)或者动态库(.so文件)。
下面是一个使用这些选项的编译命令示例:
```bash
gcc -c -o main.o main.c -I./include -L./lib -lmylib
```
这条命令将`main.c`文件编译为名为`main.o`的目标文件,并指定头文件搜索路径为当前目录下的`include`目录,库文件搜索路径为当前目录下的`lib`目录,同时链接名为`mylib`的库文件。
#### 2.1.2 链接和库文件处理
链接是编译过程中的一个重要阶段,在链接阶段将多个目标文件合并生成可执行文件。库文件分为静态库和动态库,它们有不同的特点和用途:
- **静态库**(archive library)通常在链接阶段被完全包含在最终的可执行文件中。当使用静态库时,它的内容会被复制到可执行文件中,因此静态库的变更不会影响到已经生成的可执行文件。
- **动态库**(shared library)在程序运行时被加载。这种库文件的优点是可以被多个程序共享,减少内存使用,并且允许库文件的更新而不需要重新链接整个程序。
链接时,GCC通常会自动搜索标准库路径下的库文件,而`-L`选项可以用来添加额外的库文件搜索路径。例如,链接`mylib`库:
```bash
gcc main.o -L./lib -lmylib -o myprogram
```
这条命令会链接`libmylib.so`(假设是动态链接库)或者`libmylib.a`(假设是静态链接库)来创建名为`myprogram`的可执行文件。
### 2.2 GCC编译器的版本升级与多版本管理
#### 2.2.1 升级GCC到最新版本
GCC是一个活跃的开源项目,随着新特性的添加和性能的提升,定期升级到最新版本是一个好习惯。升级可以通过安装包管理器或者从源代码编译。
- **使用包管理器升级**:很多Linux发行版都提供包管理器来安装和管理软件包。例如,在Ubuntu中可以使用以下命令升级GCC:
```bash
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt update
sudo apt upgrade gcc
```
- **从源代码编译升级**:想要获得最新版本的GCC,可能需要从源代码编译安装。从源代码编译安装步骤较为繁琐,需要安装依赖、编译、安装等步骤。
```bash
wget ***
$PWD/../gcc-11.1.0/configure --prefix=/usr/local/gcc-11.1.0
make
sudo make install
```
#### 2.2.2 同时管理多个GCC版本
由于升级可能会影响到依赖特定GCC版本的旧项目,因此在同一台机器上管理多个GCC版本是很常见的需求。可以使用`update-alternatives`来管理不同版本的GCC。
```bash
sudo update-alternatives --install /usr/bin/gcc gcc /usr/local/gcc-9.3.0/bin/gcc 50
sudo update-alternatives --install /usr/bin/gcc gcc /usr/local/gcc-11.1.0/bin/gcc 60
```
这些命令安装了两个不同版本的GCC,并通过优先级`50`和`60`来选择使用哪个版本。通过执行以下命令可以切换版本:
```bash
sudo update-alternatives --config gcc
```
此命令会列出所有安装的版本并提示用户选择一个版本。
### 2.3 GCC编译器的输出控制
#### 2.3.1 编译过程的详细输出
GCC允许控制编译过程的输出信息的详细程度。一些常用的参数如下:
- **-v**:显示编译过程的详细信息,包括每个编译步骤。
- **-Wl,<选项>**:传递选项给链接器。这对于调试链接过程特别有用。
下面是一个示例,它显示了详细的编译和链接信息:
```bash
gcc -v -Wl,-v -o myprogram main.c
```
这条命令将编译`main.c`并生成`myprogram`,同时显示所有编译步骤和链接器的详细信息。
#### 2.3.2 抑制不必要的编译信息
有时候过多的编译信息会干扰调试或查看重要信息,这时可以使用以下选项抑制它们:
- **-w**:不显示编译过程中的警告信息。
- **-q**:静默模式,不显示任何非错误信息。
例如,如果想要在编译时只显示错误信息,可以使用:
```bash
gcc -w -o myprogram main.c
```
这条命令会编译`main.c`,但是不会显示任何警告信息。
### 2.4GCC编译器的帮助信息
GCC提供了丰富的帮助选项,帮助用户了解每个编译选项的功能,这对于新用户和希望深入学习GCC的开发者来说非常有用。
- **--help**:显示GCC的通用帮助信息,提供编译器的基本使用方法和选项列表。
- **--target-help**:显示针对目标平台的特定选项。
例如,想查看特定于Intel x86架构的选项,可以使用:
```bash
gcc --target-help
```
此命令会列出所有支持目标架构的特定编译选项,便于用户根据目标平台进行优化。
这些基础的GCC编译选项和输出控制技术是每一个开发者必须要掌握的知识。掌握这些基础能够帮助开发者更好地控制编译过程,为后续章节中将讨论的优化和高级用法打下坚实的基础。
# 3. GCC编译器的优化级别
## 3.1 GCC的优化选项
### 3.1.1 优化级别概览
GCC编译器提供了一套完善的优化机制,允许开发者根据不同的需求选择不同的优化级别。这些优化级别从-O0(默认不优化)到-O3(最高优化级别)不等,每一级别都包含了不同的优化措施,旨在在编译时间、程序大小和运行速度之间寻求不同的平衡点。
- **-O0**: 此级别关闭所有优化,主要用于调试,因为它保留了源代码的结构,使得调试过程中的断点和变量查看更加容易。
- **-O1**: 这是GCC默认的优化级别,它平衡了编译时间和生成代码的运行效率。
- **-O2**: 此级别会启用更多的优化措施来提高程序的运行效率,但可能会增加编译时间。
- **-O3**: 这是最高的优化级别,它会启用所有上述优化之外的额外优化,有时会显著增加编译时间,但它可能会产生比-O2级别更快的程序。
- **-Os**: 此级别专注于减少生成代码的大小,它优化代码以最小化代码尺寸,常用于嵌入式系统。
- **-Ofast**: 此级别启用所有-O3级别的优化,并包括可能影响浮点计算结果的优化措施,可能会违反IEEE/ANSI浮点标准。
### 3.1.2 各级别优化的效果对比
选择不同的优化级别,会对程序的性能产生不同程度的影响。为了展示不同优化级别的效果,通常会使用一组基准测试(benchmarks)来衡量优化前后的性能变化。
- **运行时间**: -O2和-O3级别往往能提供显著的运行时间改进,但有时候过度优化会带来性能下降,因为编译器为了优化而做出的一些假设并不总是成立。
- **代码大小**: -Os优化级别会减少最终生成的二进制文件大小,而-O2和-O3级别的优化可能会使代码变大,因为它们更倾向于优化速度。
- **编译时间**: -O0级别编译速度最快,因为没有进行任何优化。随着优化级别的提升,编译时间会延长,特别是-O3级别。
开发者应该根据实际项目需求,测试并选择最合适的优化级别。优化不仅仅意味着提升运行速度,也可能意味着减少内存使用,或者平衡运行时间与编译时间。
## 3.2 针对不同性能的编译选项
### 3.2.1 大小优化与速度优化
在优化过程中,需要针对不同的目标选择合适的编译选项。例如,对于嵌入式系统或者资源受限的环境,大小优化(-Os)可能是首选。而对于对性能要求较高的服务器端应用,速度优化(-O2或-O3)则是更合适的选择。
#### 大小优化(-Os)
- **代码内联限制**: 在-Os级别,GCC会更少地进行函数内联操作,以减小生成代码的体积。
- **指令选择**: 编译器会更倾向于选择那些编码紧凑的指令,即使这些指令的执行速度稍慢。
- **数据对齐**: GCC会尽量减少不必要的数据对齐,有时这可以减小编译后的二进制文件大小。
#### 速度优化(-O2,-O3)
- **循环展开**: -O2级别会开始对循环进行展开,以减少循环条件检查的开销。
- **死代码消除**: -O3级别会执行更为激进的死代码消除,移除那些不会被执行到的代码路径。
- **预测分支优化**: GCC会尝试预测程序中的分支,以减少分支预测失败时的性能损失。
### 3.2.2 平台特定优化选项
平台特定的优化选项可以进一步细化对目标平台的性能提升。例如,GCC提供了针对x86架构的多种优化选项,允许开发者根据不同的CPU特性来进行针对性优化。
#### 指令集特定优化
- **-march**: 允许你指定目标CPU类型,如`-march=core2`将为Intel Core 2处理器优化。
- **-mtune**: 允许你对目标CPU的微架构进行调整,如`-mtune=haswell`将优化代码以在Haswell架构上运行得更好。
- **-mcpu**: 结合了`-march`和`-mtune`的功能,为指定的CPU优化代码。
#### 内存优化
- **-mmmx**: 启用针对MMX指令集的优化。
- **-msse**, **-msse2**, **-msse3**, **-msse4**: 分别启用SSE、SSE2、SSE3和SSE4系列指令集的优化。
开发者需要根据目标平台的特性选择合适的指令集,以确保程序在特定硬件上获得最佳性能。
## 3.3 优化选项的调试与问题排查
### 3.3.1 如何调试优化后的程序
优化后的程序在调试时可能面临挑战,因为代码结构可能因为编译器的优化而发生了变化。为此,开发者需要了解一些调试技巧和工具。
- **编译器调试信息**: 使用`-g`选项生成调试信息,这样即使代码经过优化,调试器仍然可以理解程序的执行流程。
- **反汇编工具**: 使用如`objdump`或`gdb`的反汇编功能来查看优化后的汇编代码。
- **跟踪优化选项**: 逐级提升优化级别,并使用版本控制工具跟踪代码变更,有助于发现哪一级别的优化引入了问题。
### 3.3.2 优化导致的问题及其解决方案
优化虽然可以提高性能,但有时也会引入问题,如未定义的行为、数据竞争等。开发者应当了解可能遇到的问题类型以及相应的解决方案。
- **未定义行为**: 优化可能会改变程序的执行顺序,开发者需要确保代码中没有未定义行为。
- **数据竞争**: 并行计算中,优化可能改变变量的加载与存储顺序。开发者可以使用锁或其他同步机制来避免数据竞争。
- **调试符号问题**: 有时候优化级别过高可能会导致调试符号丢失。开发者可以调整优化级别,或在编译时使用`-fkeep-debug-symbols`保留调试符号。
使用GCC的优化选项可以极大地提升程序的性能,但需要谨慎选择优化级别并进行充分的测试,以确保最终的程序既快速又稳定。
# 4. GCC编译器高级优化技术
## 4.1 高级编译选项和代码优化技术
### 4.1.1 循环优化和向量化
循环是程序中执行最频繁的操作之一,因此循环优化对于提升程序性能至关重要。GCC编译器提供了多种高级编译选项来优化循环结构,其中最重要的是向量化(Vectorization),它通过使用SIMD(单指令多数据)指令集扩展来并行处理数据。
以 `-O3` 优化选项为例,GCC会尝试自动向量化循环,以利用现代CPU的向量处理能力。向量化可以通过 `-ftree-vectorize` 选项明确启用。此外,`-funsafe-math-optimizations` 选项允许进行数学运算的优化,这可能包括对循环的变换,以利用更多并行性。
示例代码块如下:
```c
void vector_example(int *a, int *b, int *c, size_t n) {
for (size_t i = 0; i < n; ++i) {
c[i] = a[i] + b[i];
}
}
```
在启用向量化后,GCC会尝试使用SIMD指令集执行循环内的运算,从而显著提高性能。需要注意的是,向量化要求循环满足一定的条件,例如无数据依赖、迭代次数是固定的,等等。
### 4.1.2 函数内联和分支预测
函数内联是一种常见的编译器优化技术,它用函数体替换函数调用。GCC提供了 `-finline-functions` 等选项,控制内联行为。内联可以减少函数调用开销,尤其是对于小型函数非常有效。
另一个重要的优化是分支预测。GCC可以优化代码以提高分支预测的准确性。例如,通过重新排列条件分支的顺序,编译器尝试让CPU的分支预测逻辑更有效。编译器使用 `-fbranch-probabilities` 选项来启用这项优化。
示例代码块如下:
```c
if (probable_condition)
// 高概率执行的代码
else
// 低概率执行的代码
```
在上述代码中,`probable_condition` 表示一个通常为真的条件。编译器会根据这个条件,调整分支的顺序,使得高概率的分支更容易被CPU预测。
## 4.2 静态分析和性能分析工具
### 4.2.1 使用静态分析检测潜在问题
静态分析是在不实际运行代码的情况下分析程序的过程。GCC提供了 `-Wall` 和 `-Wextra` 等编译选项,用于启用额外的警告,帮助开发者发现潜在的代码问题。这些警告包括未初始化变量的使用、类型不匹配、逻辑错误等。
通过启用 `-fsyntax-only` 选项,开发者可以在不进行实际编译的情况下对代码进行静态检查。更高级的静态分析工具,如 `cppcheck` 和 `clang-tidy`,也常用于代码质量控制。
### 4.2.2 利用性能分析工具优化代码
性能分析工具是优化代码的重要辅助手段。GCC内置的 `gprof` 工具可以用来分析程序的性能瓶颈。另外,`valgrind` 的 `cachegrind` 和 `callgrind` 工具提供了更详细的性能分析数据。
开发者可以通过在编译时加入 `-pg` 选项,使程序生成性能分析数据。运行程序后,使用 `gprof` 工具对数据进行分析,找出热点函数(hotspots),即消耗了大部分执行时间的函数。
```shell
gcc -pg -O2 -o program program.c
./program
gprof program gmon.out > analysis.txt
```
在 `analysis.txt` 文件中,开发者可以获取到详细的函数调用次数、消耗时间等信息,进而针对热点函数进行优化。
## 4.3 交叉编译与多平台优化
### 4.3.1 交叉编译的基础和实践
交叉编译是指在一个平台(宿主平台)上为另一个不同的平台(目标平台)编译程序。这对于嵌入式开发尤为重要。GCC支持交叉编译,其基础是使用特定的目标三元组(例如 `arm-linux-gnueabihf-`)来指定目标平台。
开发者可以通过设置 `--target` 编译选项来指定目标平台。交叉编译工具链通常包括编译器、链接器、库等,GCC官方提供了构建交叉编译工具链的 `crosstool-NG`。
示例命令:
```shell
gcc --target=arm-linux-gnueabihf -o cross-compiled-app cross-compiled-app.c
```
### 4.3.2 针对多平台的代码优化策略
在多平台开发时,开发者需要考虑平台间的硬件差异,比如不同的处理器架构、内存限制、指令集等。GCC提供了编译选项 `-march` 和 `-mtune`,允许开发者针对特定架构进行优化,或调整代码以适应多种架构。
示例代码块:
```c
#if defined(__arm__)
// ARM架构的优化代码
#elif defined(__x86_64__)
// x86_64架构的优化代码
#endif
```
在多平台优化时,开发者应该使用条件编译来提供针对不同架构的优化代码,这样可以最大程度上保证程序的性能和兼容性。
通过上述策略,开发者可以在不同平台间迁移和优化代码,同时保证了良好的可移植性和性能。
# 5. GCC编译器在项目中的应用
GCC编译器不仅仅是一个命令行工具,它在项目构建和开发流程中扮演着关键的角色。理解如何将GCC集成到项目的不同阶段,对于提高开发效率和程序性能至关重要。本章节将深入探讨GCC在项目中的应用,包括环境配置、编译器定制、扩展开发和项目集成实践。
## 5.1 项目编译环境的配置与管理
在现代软件开发过程中,项目的编译环境需要精心配置以确保编译过程的顺利和高效。这一部分将介绍如何使用Makefile自动化编译流程和管理项目的依赖以及版本控制。
### 5.1.1 使用Makefile自动化编译流程
Makefile是一个文本文件,它定义了一系列构建软件的规则和指令。通过编写Makefile,我们可以指定依赖关系、编译选项和链接指令。GCC编译器能够通过Makefile来自动完成复杂的编译任务,而无需人工干预。
假设我们有一个简单的C项目,包含`main.c`和`utils.c`两个源文件。以下是一个简单的Makefile示例:
```makefile
CC=gcc
CFLAGS=-I./include -Wall
LDFLAGS=-L./lib
TARGET=program
all: $(TARGET)
$(TARGET): main.o utils.o
$(CC) -o $@ $^ $(LDFLAGS)
main.o: main.c
$(CC) -c -o $@ $< $(CFLAGS)
utils.o: utils.c
$(CC) -c -o $@ $< $(CFLAGS)
clean:
rm -f $(TARGET) *.o
.PHONY: all clean
```
- `CC=gcc`指定了编译器,可以替换为其他编译器如`clang`。
- `CFLAGS`包含了编译选项,`-I`用于添加头文件目录,`-Wall`开启所有警告。
- `LDFLAGS`指定了链接器选项。
- `TARGET`定义了最终目标文件。
- 规则定义了如何构建目标文件,`$@`代表目标,`$^`代表所有依赖,`$<`代表第一个依赖。
- `clean`是一个伪目标,用于清理编译产物。
通过执行`make`命令,就可以自动化编译过程。Makefile的详细使用和编写技巧可以大大提高项目构建的效率和可维护性。
### 5.1.2 项目的依赖管理和版本控制
在复杂的项目中,依赖管理变得异常重要。GCC与包管理工具(如apt、yum等)或者依赖管理工具(如vcpkg、conan等)的结合使用,可以自动化安装和管理项目依赖。
版本控制则通过工具如Git来跟踪文件的变更历史,确保团队协作的顺畅。在Makefile中,可以结合Git信息来编译版本号,例如:
```makefile
VERSION=$(shell git describe --tags --abbrev=0)
TARGET=program
all: $(TARGET)
$(TARGET): main.o utils.o
$(CC) -o $@ $^ -DVERSION=\"$(VERSION)\"
# 其他规则...
.PHONY: all
```
这段代码将Git标签(版本号)编译到程序中。当构建项目时,可以通过`-DVERSION`定义的宏获取当前的Git版本。
## 5.2 GCC编译器的定制与扩展
GCC编译器允许开发者定制其行为以满足特定项目的需求。插件机制和前端开发是GCC扩展和定制的关键途径。
### 5.2.1 GCC插件机制和扩展开发
GCC的插件系统允许开发者编写插件来扩展编译器的功能。这些插件可以用来分析代码、提供代码改进建议,甚至修改编译过程中的代码生成。
创建一个GCC插件需要对GCC内部结构有一定了解,通常需要使用GCC的插件API进行编写。下面是一个简单的插件示例框架:
```c
#include <gcc-plugin.h>
#include <plugin-version.h>
#include <tree.h>
#include <gimple.h>
#include <function.h>
int plugin_is_GPL_compatible;
static void my_plugin_function(void* event_data, void* data) {
// 插件逻辑代码
}
int plugin_init(struct plugin_name_args* plugin_info, struct plugin_gcc_version* version) {
if (!plugin_default_version_check(version, &gcc_version)) {
return 1; // 版本不兼容
}
register_callback(plugin_info->base_name, PLUGIN_START_UNIT, my_plugin_function, NULL);
return 0;
}
```
这段代码是一个GCC插件的基本结构,注册了一个在编译单元开始时被调用的回调函数。插件的详细开发涉及到GCC内部数据结构和API的理解。
### 5.2.2 自定义编译器行为和前端开发
GCC提供了丰富的选项来控制编译器的行为。了解如何自定义这些选项,可以帮助我们精细地调整编译过程以适应特定的需求。
GCC前端是指GCC处理特定编程语言的代码(如C、C++等)的部分。理解前端的工作机制,可以让我们更有效地进行语言特定的优化。GCC前端的开发通常需要深入了解LLVM IR(中间表示)或者特定语言的抽象语法树(AST)。
## 5.3 GCC编译器的项目集成实践
GCC作为编译工具链的一部分,在持续集成和持续交付(CI/CD)的流程中扮演着重要角色。本小节将探讨GCC在CI/CD流程中的集成以及在大型项目中的应用案例。
### 5.3.1 集成GCC到CI/CD流程
CI/CD流程自动化了软件开发过程中的构建、测试和部署环节。GCC的集成主要是通过脚本和配置文件来实现的。在CI/CD系统中,如Jenkins或GitLab CI,可以通过编写构建脚本来编译和测试代码。
例如,在Jenkins中,可以通过编写Shell脚本,在构建步骤中调用GCC进行编译:
```shell
#!/bin/bash
gcc -c main.c utils.c -o object_files
gcc -o my_program object_files -lm -lc
```
然后执行测试并部署到服务器。
### 5.3.2 GCC在大型项目中的应用案例
大型项目通常需要复杂的构建系统和版本控制策略。GCC在这些项目中主要负责编译代码和链接最终的可执行文件。例如,Linux内核项目就是一个使用GCC编译器的典型例子。
Linux内核的构建系统是一个复杂的Makefile集,它利用GCC的强大功能来编译数百万行代码。通过定制内核配置选项,开发者可以仅编译需要的功能模块,这体现了GCC在大型项目中的灵活应用。
在集成GCC到大型项目时,通常需要:
- 确保GCC版本的一致性,特别是在团队协作中。
- 维护一致的编译环境,例如通过Docker容器封装编译环境。
- 优化GCC的编译选项以提高编译速度和生成代码的性能。
通过这些实践,开发者可以确保GCC在项目中高效运行,并且输出高质量的代码。
本章节介绍了GCC编译器在项目中的关键应用,包括编译环境的配置、定制与扩展以及在CI/CD流程中的集成实践。这些应用使得GCC成为开发者工具箱中不可或缺的一部分,并且在构建现代软件项目中发挥了关键作用。
# 6. GCC编译器的未来发展趋势
GCC(GNU Compiler Collection)自1987年首次发布以来,一直是开源世界中最重要的编译器之一。随着技术的发展,GCC也在不断地进行改进以满足日益增长的编程需求。未来的发展趋势不仅包括自身功能的增强,还涉及与其他编译器的竞争与合作,以及面向新兴技术的优化技术探索。
## 6.1 GCC编译器的持续改进
GCC作为一款成熟的编译器,其版本迭代一直是关注的焦点。GCC社区通过引入新的特性和改进现有功能来增强编译器的竞争力。
### 6.1.1 最新版本的亮点特性
GCC的每个新版本都会带来一些显著的改进。例如,GCC 9引入了对C++20的支持,增强了对多线程、协程的支持,并改进了某些旧有编译器的性能瓶颈。这些更新不仅提高了GCC的性能,也为开发者提供了更丰富的编程工具和语言特性。
### 6.1.2 GCC社区的贡献和发展趋势
GCC社区非常活跃,大量开发者和组织贡献代码和新特性。未来,社区将继续推动GCC在编译速度、优化算法和跨平台支持上的发展。同时,社区还将重点提高编译器的易用性和改进文档,以帮助新用户更容易上手。
## 6.2 GCC编译器与其他编译器的竞争与合作
GCC不是市场上唯一的编译器,Clang就是另一个强大的竞争者。在某些方面,Clang提供了更快速的编译时间和更好的错误信息,这使得它在某些开发社区中获得了青睐。
### 6.2.1 GCC与Clang的对比分析
GCC和Clang各自有着不同的优势。GCC在优化级别和平台支持方面表现得更好,而Clang以其更友好的错误消息和更快的编译速度赢得了开发者的心。随着GCC社区与Clang社区之间的交流和合作,两者在功能上出现了越来越多的相似之处,但GCC仍然在处理老旧代码和维护稳定性的方面保持着优势。
### 6.2.2 GCC在新兴技术中的角色
在新兴技术如物联网(IoT)和边缘计算等领域的应用,对编译器提出了新的要求。GCC正通过提供针对这些领域的优化选项来增强其在新兴技术中的角色。此外,GCC也在探索与硬件制造商合作,以更好地支持新出现的硬件架构。
## 6.3 面向未来的编译器优化技术探索
随着硬件的快速发展,未来的编译器优化技术不仅要关注传统硬件,也要关注新型硬件的特性。
### 6.3.1 面向新型硬件的编译器优化
新型硬件如多核处理器、GPU以及专用AI处理器等需要编译器提供更深层次的优化。为了充分利用这些硬件的性能,GCC在优化算法上进行了大量工作,比如指令级并行、自动向量化等技术的改进。对于AI和机器学习领域,GCC也在探索如何通过扩展编译器支持更复杂的计算图和张量操作。
### 6.3.2 编译器在AI和机器学习领域的应用展望
在AI和机器学习领域,编译器需要处理非传统的编程模型和数据结构。为了适应这些领域的需求,GCC可能需要增加对新数据类型和操作的支持,并优化内存访问和并行计算。同时,将机器学习技术与编译器设计结合起来,如利用机器学习来预测优化选择,也是未来一个可能的发展方向。
GCC编译器的未来是令人期待的,它的持续改进、与其他编译器的竞争合作以及对于新技术领域的探索,都将使它保持在编译器领域的领导地位。随着编程语言和硬件的不断演进,GCC也在不断地推进,以适应新一代的开发挑战。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析 C++ 编译器,如 GCC、Clang 和 MSVC,涵盖从前端解析到后端优化的方方面面。专栏文章探讨了编译器优化策略、Clang 的现代编译技术、MSVC 的性能调优技巧、编译器前端和后端技术、编译器链接器解析、警告和错误管理、跨平台开发指南、MSVC 内部机制、调试工具比较、内存管理优化、中间代码优化和多线程编译技术。通过阅读本专栏,C++ 开发人员可以深入了解编译器的运作原理,掌握优化策略,并做出明智的编译器选择,从而提升代码质量、性能和开发效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
京瓷激光打印机故障不再怕:快速解决手册与故障诊断

# 摘要
京瓷激光打印机作为办公和商业打印的常用设备,其性能稳定性和故障处理能力对于用户来说至关重要。本文首先概述了京瓷激光打印机的基本情况,包括其工作原理及主要组件功能。随后,深入探讨了打印机故障诊断的基础知识,涵盖了诊断方法、常见故障分类以及诊断工具的使用。文章第三章集中讨论了常见的打印机故障及其快速解决方法。第四章则着重于电路、连接问题以及软件驱动问题的深入诊断和高级维修技巧。最后,本文提供了关于预防性维护和打印机保养的实用建议,并通过案
无线通信优化:RLS算法在实际中的3种高效策略

# 摘要
本文全面探讨了递归最小二乘(RLS)算法在无线通信优化中的应用。首先,介绍了RLS算法的理论基础、数学模型以及性能评估指标,详细阐述了算法的工作机制和核心数学模型。其次,深入分析了RLS算法的初始化和调整策略,包括初始权重选择、步长因子和窗口尺寸的影响,以及计算复杂度的优化方法。文章
复数世界的探险:Apostol数学分析中的复分析入门

# 摘要
本文系统性地介绍了复数及其在数学和物理中的应用,涵盖了复数与复平面的基础概念、复变函数理论、复数序列与级数的收敛性、复分析在几何和物理领域的应用以及复分析的高级主题。通过对复变函数的定义、性质、解析性以及积分定理的探讨,文中详细阐述了复分析的基本理论框架。同时,本文深入探讨了复分析在电磁学、量子力学、波动现象等物理问题中的应用,并对复流
【兼容性挑战】:深入分析银灿USB3.0 U盘电路图,应对USB3.0与2.0兼容问题
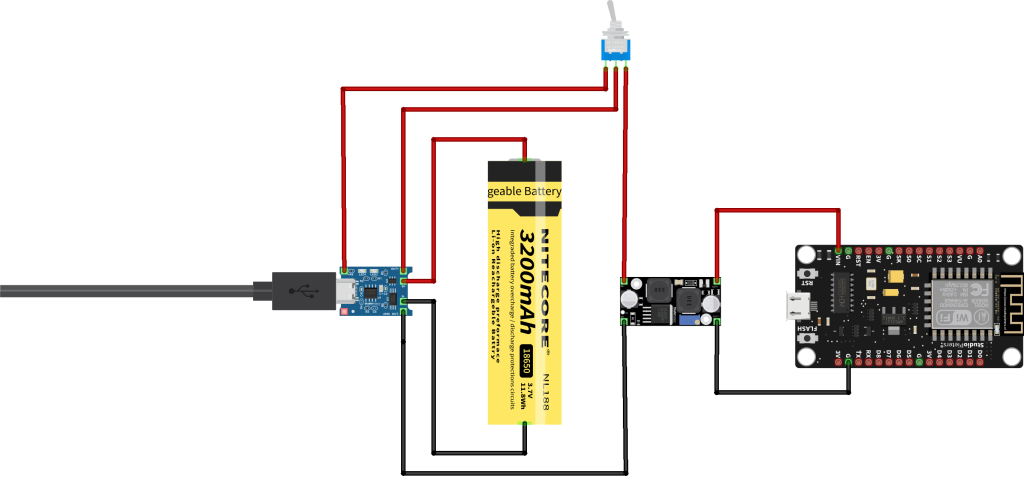
# 摘要
随着USB技术的广泛应用,兼容性问题成为影响其性能的关键挑战。本文从技术概述出发,详细分析了USB 3.0与USB 2.0在物理层、数据链路层、电源管理、端口接口以及电路图设计等方面的技术特点及其兼容性挑战。通过对比分析和案例研究,提出了优化USB 3.0 U盘兼容性的实践应用策略,并对其效果进行了评估。最后,本文展望了USB技术的未
【HFSS15启动失败终极解决指南】:操作系统更新与软件兼容性调试
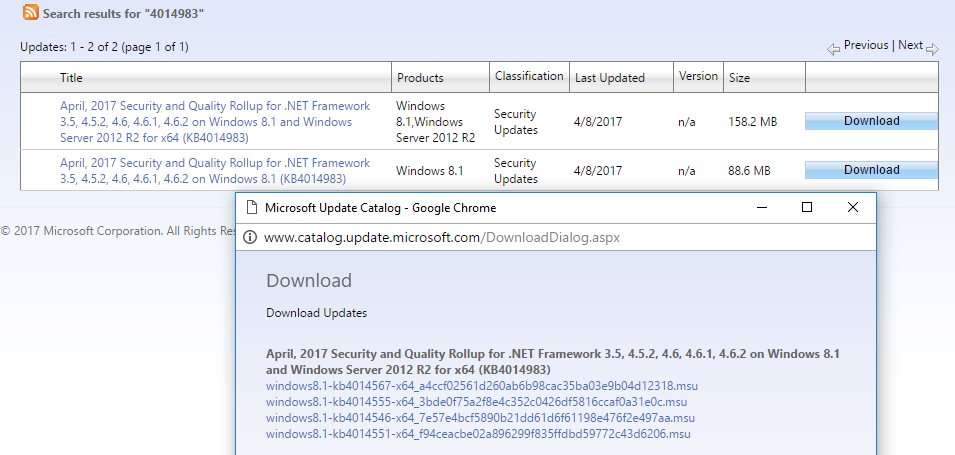
# 摘要
随着HFSS15软件在现代工程设计中的广泛应用,其启动失败问题引起了广泛关注。本文首先概述了HFSS15及其启动失败现象,随后深入分析了操作系统更新对软件兼容性的影响,特别是更新类型、系统资源变化以及软件兼容性问题的表现。文章重点探讨了HFSS15兼容性问题的理论基础、诊断方法和调试实践,包括排查步骤、调试技巧及优化措施。通过对HFSS
【MD290系列变频器应用案例精选】:分享成功经验,解锁更多使用场景(实操分享)
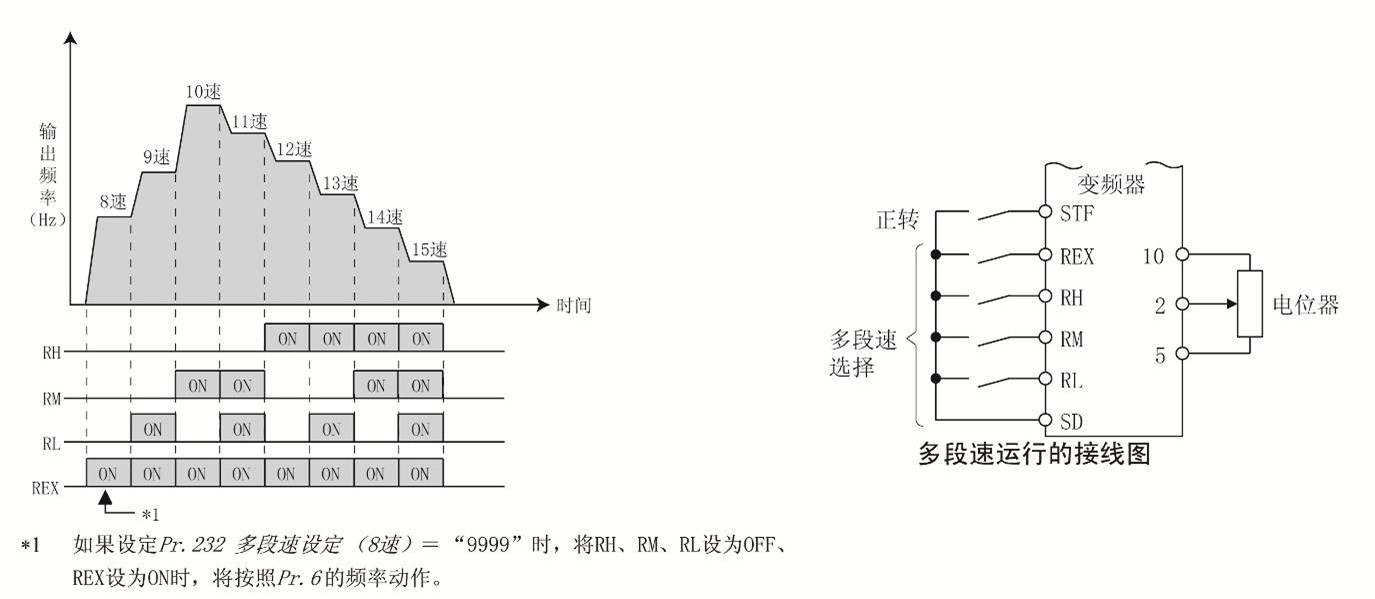
# 摘要
MD290系列变频器是工业自动化领域中广泛使用的高性能设备,本文全面介绍了该系列变频器的基础知识、核心功能、安装调试流程、行业应用案例,以及网络通信与集成的能力。文章详细解析了变频器的控制模式、参数设置、环境准备、问题诊断,并通过实际案例展示了其在工业自动化、水处理、泵站、以及HVAC系统中的优化应用。此外,还探讨了变频器的维护措施与技术发展趋势,为相关领域的工程师提供了重要的实践指导和未来改进方向。
# 关键字
【西门子S7-1200通信秘籍】:提升数据传输效率的7个关键策略

# 摘要
本论文深入探讨了西门子S7-1200 PLC的通信原理和优化策略。首先介绍了通信基础和数据传输效率理论,包括网络延迟、数据包大小、协议选择以及硬件加速技术等影响因素。随后,重点分析了通信实践策略,如优化网络配置、数据压缩和批处理技术以及通信模块性能调优。第四章详细讨论了高级通信功能,包括Profinet通信优化和S7-1200间的数据同
【ROS Bag 数据分析工具箱】:构建个性化数据分析工具集的终极秘籍

# 摘要
本文介绍了一个专门用于ROS Bag数据分析的工具箱,它提供了数据读取、预处理、可视化、交互分析、机器学习集成以及数据挖掘等一系列功能。工具箱基于ROS Bag数据结构进行了深入解析,构建了理论基础,并在实际应用中不断优化和扩展。通过实施模块化设计原则和性能优化,工具箱提高了数据处理效率,并通过开发用户友好的图形界面提升了用户体验。
安全性的温柔守护:保护用户情感与数据安全的技术策略

# 摘要
用户情感与数据安全是现代信息技术领域内的重要研究主题。本文旨在探索情感安全的理论基础、技术实现以及风险评估管理,并与数据安全的理论与实践相结合,提出融合策略。通过对情感安全与数据安全相互作用的分析,本文构建了融合策略的理论框架,并探讨了在用户界面设计、情感数据分析等方面的应用。文章还回顾了情感与数据安全融合的成功与失败案例,并对未来的技术趋势、政策法规以及安全策略提出了展望和建议。
# 关键字
用户情感;数据安全;情感
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )