进阶sed:使用正则表达式进行高级文本处理
发布时间: 2024-01-18 20:17:38 阅读量: 53 订阅数: 43 

JavaScript 正则表达式高级应用
# 1. sed 简介
## 1.1 什么是sed
sed是一种流编辑器,用于对文本进行流式处理。它通过逐行读取文本,根据用户指定的命令对文本进行处理和转换。sed可以用于搜索、替换、删除和插入文本,使得文本处理变得更加高效和灵活。
## 1.2 sed 的基本用法回顾
在使用sed命令时,我们需要提供一个命令和一个文本文件作为输入。sed命令可以通过多个参数来指定操作,其中常见的参数包括:
- `-e`:指定要执行的sed命令,可以在一个sed命令中指定多个操作。
- `-f`:从指定的文件中读取sed命令,可以将多个命令保存在一个文件中,并通过该参数引用执行。
- `-i`:在源文件上进行直接修改,而不是输出到终端。
除了参数,sed还支持一些常见的命令操作,例如:
- `s`:用于搜索和替换指定的文本。
- `d`:删除指定的行或者范围内的行。
- `p`:打印指定的行或者范围内的行。
- `a`:在指定的行后面添加一行文本。
- `i`:在指定的行前面插入一行文本。
下面是一个简单的示例,演示了如何使用sed命令将文本文件中的"apple"替换为"orange":
```bash
sed 's/apple/orange/g' file.txt
```
在上面的命令中,`s/apple/orange/g`表示将文本文件中所有的"apple"都替换为"orange",`file.txt`是要处理的文本文件。
通过学习sed的基本用法,我们可以方便地进行文本的搜索、替换、删除和插入操作,提高文本处理的效率。在接下来的章节中,我们将深入研究sed的更高级的功能和用法。
# 2. 正则表达式基础
### 2.1 正则表达式简介
正则表达式是一种用来描述、匹配和操作文本的强大工具。它由一系列的字符和特殊字符组成,可以用来匹配字符串中的某种模式。在sed中,正则表达式被广泛用于搜索和替换文本中的内容。
### 2.2 常用的正则表达式语法
在使用正则表达式之前,我们需要了解一些常用的语法规则:
- 字符匹配:单个字符可以在正则表达式中直接匹配。
- 字符集:用方括号`[]`表示,用于匹配方括号中的任意一个字符。
- 元字符:具有特殊含义的字符,在正则表达式中有特定的用途,如`.`匹配任意字符,`*`匹配前面的元素0次或多次。
- 重复次数:用`{}`表示,可以指定元素重复出现的次数,如`{m,n}`表示至少出现m次,至多出现n次。
- 边界匹配:用于限定匹配字符串的边界位置,如`^`表示行首,`$`表示行尾。
### 2.3 在sed中使用正则表达式
在sed中,我们可以使用正则表达式对文本进行搜索和替换。下面是一些在sed中常用的正则表达式操作:
- 匹配行:使用`/pattern/`来匹配包含指定模式的行。
- 替换文本:使用`s/pattern/replace/`来替换指定模式的文本。
```shell
# 示例代码
# 匹配包含"apple"的行,并替换为"orange"
sed -e '/apple/s//orange/' input.txt
# 替换每行的第一个"apple"为"orange"
sed -e 's/apple/orange/' input.txt
```
总结:
在sed中使用正则表达式是进行高级文本处理的重要工具。通过掌握常用的正则表达式语法和在sed中的应用技巧,我们可以轻松地搜索、替换和处理文本中的内容。在下一章节中,我们将学习更多高级文本处理技巧。
# 3. 高级文本处理技巧
在这一章中,我们将讨论如何使用sed和正则表达式进行高级文本处理。我们将深入探讨如何对文本进行搜索和替换,删除特定行或者添加行,以及对文本进行格式化的技巧和方法。
### 3.1 使用正则表达式对文本进行搜索和替换
在实际的文本处理中,经常需要对文本进行搜索和替换。使用sed结合正则表达式可以高效地实现这一目的。
以下是一个具体场景的示例,假设我们有一个文本文件`data.txt`,内容如下:
```bash
apple
banana
cherry
date
```
现在我们希望将其中的 `banana` 替换为 `orange`,我们可以使用如下的sed命令实现:
```bash
sed -i 's/banana/orange/' data.txt
```
经过上面的命令执行后,`data.txt`的内容变为:
```bash
apple
orange
cherry
date
```
通过这个简单的示例,我们展示了如何使用sed结合正则表达式进行文本搜索和替换的基本用法。
### 3.2 删除特定行或者添加行
有时候我们需要删除文本文件中的特定行,或者在文件中添加新的行。借助sed和正则表达式,我们可以轻松实现这一操作。
假设我们有一个文本文件`data2.txt`,内容如下:
```bash
apple
banana
cherry
date
```
现在我们希望删除其中包含 `apple` 的行,并在文件末尾添加 `grape` 一行。我们可以使用如下的sed命令实现:
```bash
sed -i '/apple/d' data2.txt
sed -i '$a grape' data2.txt
```
经过上面的命令执行后,`data2.txt`的内容变为:
```bash
banana
cherry
date
grape
```
在这个示例中,我们展示了如何使用sed删除特定行以及添加新行的高级文本处理技巧。
### 3.3 对文本进行格式化
最后,我们将讨论如何使用sed和正则表达式对文本进行格式化的技巧。在实际的数据处理过程中,文本格式化是一个非常常见的需求。
假设我们有一个文本文件`data3.txt`,内容如下:
```bash
apple,100
banana,200
cherry,300
date,400
```
现在我们希望将每行的格式调整为 `fruits: apple - 100` 的形式。我们可以使用如下的sed命令实现:
```bash
sed -i 's/\(.*\),\([0-9]*\)/fruits: \1 - \2/' data3.txt
```
经过上面的命令执行后,`data3.txt`的内容变为:
```bash
fruits: apple - 100
fruits: banana - 200
fruits: cherry - 300
fruits: date - 400
```
通过这个示例,我们展示了如何使用sed和正则表达式对文本进行格式化,实现高级的文本处理功能。
在第三章中,我们介绍了使用正则表达式和sed进行高级文本处理的技巧,包括搜索和替换、删除特定行或添加行、以及文本格式化等操作。这些技巧对于日常数据处理和文本处理非常有用,能够帮助我们更高效地处理文本数据。
# 4. sed的高级功能
## 4.1 标签和分支
在sed中,标签用于标记命令的位置,分支用于跳转到标签所指示的位置。这两个功能的组合可以使sed具备更强大的处理能力。
### 4.1.1 标签
在sed的命令中,标签用`:`和标识符表示。我们可以在需要跳转的位置设置标签,然后在需要跳转的命令中使用标签进行引用。
下面是一个示例:
```shell
sed ':label1
s/abc/xyz/
t label1' file.txt
```
解释如下:
- `:label1`:设置一个名为label1的标签。
- `s/abc/xyz/`:将`abc`替换为`xyz`。
- `t label1`:如果替换操作成功,则跳转到label1标签继续处理。
### 4.1.2 分支
在sed的命令中,分支用`b`命令实现。它能够跳转到指定的标签处执行后续命令。
下面是一个示例:
```shell
sed '/pattern1/ {
s/pattern1/replace1/
b
s/pattern2/replace2/
}' file.txt
```
解释如下:
- `/pattern1/`:匹配到`pattern1`的行执行后续操作。
- `s/pattern1/replace1/`:将`pattern1`替换为`replace1`。
- `b`:跳转到下一个命令,即`s/pattern2/replace2/`。
- `s/pattern2/replace2/`:将`pattern2`替换为`replace2`。
## 4.2 控制流
除了使用标签和分支实现跳转外,sed还提供了一些控制流命令,用于更精确地控制处理流程。
### 4.2.1 循环命令
在sed中,循环命令用`while`实现。它可以重复执行一系列命令,直到指定条件不再满足。
下面是一个示例:
```shell
sed ':loop
s/abc/xyz/
t loop' file.txt
```
解释如下:
- `:loop`:设置一个名为loop的标签。
- `s/abc/xyz/`:将`abc`替换为`xyz`。
- `t loop`:如果替换操作成功,则跳转到loop标签继续处理,形成循环。
### 4.2.2 跳过命令
在sed中,跳过命令用`next`实现。它可以跳过当前行,继续处理下一行。
下面是一个示例:
```shell
sed '/pattern1/ {
s/pattern1/replace1/
n
s/pattern2/replace2/
}' file.txt
```
解释如下:
- `/pattern1/`:匹配到`pattern1`的行执行后续操作。
- `s/pattern1/replace1/`:将`pattern1`替换为`replace1`。
- `n`:跳过当前行,继续处理下一行。
- `s/pattern2/replace2/`:将`pattern2`替换为`replace2`。
## 4.3 高级替换技巧
除了基本的搜索和替换操作,sed还提供了一些高级的替换技巧,可以更加灵活和精确地进行替换。
### 4.3.1 全局替换
在sed中,可以使用`g`标志实现全局替换。它用于将所有匹配到的模式进行替换,而不仅仅是第一个匹配到的。
下面是一个示例:
```shell
sed 's/pattern/replace/g' file.txt
```
解释如下:
- `s/pattern/replace/g`:将所有匹配到的`pattern`替换为`replace`。
### 4.3.2 数字替换
在sed中,可以使用`&`符号引用匹配到的字符串,还可以使用`\n`引用匹配到的子字符串。
下面是一个示例:
```shell
sed 's/pattern/&-suffix/g' file.txt
```
解释如下:
- `s/pattern/&-suffix/g`:在匹配到的`pattern`后面添加`-suffix`。
这些是一些sed的高级功能,通过掌握这些技巧,我们可以更加灵活地处理文本数据,实现更复杂的操作。在实际使用中,根据具体的需求选择适当的sed命令和选项,可以大大提高处理效率和准确性。
参考资料:
- [GNU sed官方文档](https://www.gnu.org/software/sed/manual/sed.html)
# 5. 案例分析
## 5.1 处理日志文件
对于系统管理员来说,处理日志文件是一个常见的任务。使用sed可以快速、灵活地对日志文件进行处理和分析。下面是一个示例场景,假设我们有一个日志文件,其中记录着用户登录系统的信息,我们想要提取出登录成功的用户信息。
```bash
#!/bin/bash
# 日志文件路径
logfile="/var/log/auth.log"
# 使用sed命令匹配登录成功的行并提取用户信息
sed -n '/Accepted password for/s/.*from \(.*\) port.*/\1/p' $logfile
```
注释:上述代码中使用sed命令的 `-n` 参数表示只输出匹配到的行;正则表达式 `/Accepted password for/` 匹配含有 "Accepted password for" 字符串的行;替换模式 `s/.*from \(.*\) port.*/\1/` 提取出括号中的内容(即用户信息),并通过 `\1` 引用(`\1` 表示第一个捕获组);最后使用 `p` 参数打印匹配到的内容。
代码总结:该代码利用sed命令提取出日志文件中登录成功的用户信息。
结果说明:运行上述代码后,将输出日志文件中所有登录成功的用户信息。
## 5.2 数据清洗
数据清洗是数据分析中不可或缺的一步,sed提供了强大的功能来处理和清洗文本数据。下面是一个示例场景,将一个包含重复行的文本文件进行去重处理。
```python
# Python实现示例
# 导入必要的模块
import subprocess
# 文件路径
input_file = "input.txt"
output_file = "output.txt"
# 使用sed命令对文本文件进行去重处理
subprocess.run(["sed", "-i", "-e", "$!N; /^\(.*\)\n\1$/!P; D", input_file])
# 输出结果
with open(output_file, "r") as f:
print(f.read())
```
注释:上述代码通过调用subprocess模块中的run函数来执行sed命令。sed命令中的选项 `-i` 表示直接在原始文件上进行修改;`-e` 表示指定要执行的sed命令;sed命令中的正则表达式 `/^\(.*\)\n\1$/` 用于匹配重复行;`P` 参数表示只打印模式空间中的一部分(即去重后的内容);`D` 参数表示删除模式空间中已打印的部分,并重新加载下一行。
代码总结:该代码利用sed命令对文本文件进行去重处理。
结果说明:运行上述代码后,将输出去重后的文本文件内容。
## 5.3 格式转换和数据提取
在数据处理和分析中,经常需要对文本数据进行格式转换和数据提取。sed提供了方便的工具来实现这些操作。下面是一个示例场景,将一个以逗号分隔的文件转换为JSON格式。
```javascript
// JavaScript实现示例
// 原始数据
var data = "name,age,gender\nJohn,25,Male\nJane,30,Female";
// 使用sed命令转换为JSON格式
var result = `echo "${data}" | sed -n '1!p' | sed 's/,/","/g' | sed 's/^/["/; s/$/"]/'`;
// 输出结果
console.log(result);
```
注释:上述代码中使用sed命令的 `-n` 参数表示只输出匹配到的行;sed命令中的 `1!p` 参数表示不打印第一行;sed命令中的 `s/,/","/g` 参数表示将逗号替换为引号;sed命令中的 `s/^/["/; s/$/"]/'` 参数表示在每行的开头和结尾添加方括号和引号。
代码总结:该代码利用sed命令将逗号分隔的文件转换为JSON格式。
结果说明:运行上述代码后,将输出转换后的JSON格式数据。
以上是关于sed在案例分析中的一些应用场景,通过这些例子可以更好地理解和使用sed进行高级文本处理。在实际使用中,根据具体的需求和文本特点,可以灵活地运用sed命令来完成各种文本处理任务。
# 6. 性能优化及注意事项
在使用 sed 进行文本处理时,我们也需要考虑到性能优化和一些注意事项。本章将介绍一些关于 sed 的性能优化技巧和常见问题和注意事项。
## 6.1 sed 的性能优化技巧
在处理大规模文本时,提升 sed 的性能可以节省处理时间和资源消耗。下面是一些常见的性能优化技巧:
- 使用 `-n` 参数:在使用 sed 进行文本处理时,sed 会默认将处理过的文本打印输出,但是如果我们只需要处理而不需要输出,可以使用 `-n` 参数来关闭默认输出,从而提升性能。
```bash
sed -n 's/foo/bar/g' file.txt
```
- 尽量避免使用全局替换:使用全局替换时,sed 会在整个文本中查找并替换,这在处理大的文本时会消耗较多的资源。如果只需要替换匹配到的第一个字符串,可以使用 `/1` 参数。
```bash
sed 's/foo/bar/1' file.txt
```
- 使用更高效的字符定界符:在 sed 的替换操作中,我们可以使用不同的字符作为定界符。一般情况下,我们使用斜杠`/`作为定界符,但是如果替换内容中包含斜杠,则需要对斜杠进行转义操作。为了避免这种情况,可以使用其他字符作为定界符,例如`#`、`|`等。
```bash
sed 's#/foo#/bar#g' file.txt
```
- 尽量减少正则表达式的使用:正则表达式在处理文本时需要进行复杂的匹配和替换操作,因此尽量减少正则表达式的使用可以提升 sed 的性能。如果只是简单的字符串替换,可以不使用正则表达式来完成。
- 结合其他工具:有些情况下,sed 并不是最高效的处理工具,可以结合其他命令行工具来完成文本处理任务,例如 awk、grep 等。
## 6.2 sed 使用中的常见问题和注意事项
在使用 sed 进行文本处理时,可能会遇到一些常见的问题和需要注意的事项。下面列举了一些常见的问题和注意事项:
- 转义字符的使用:在 sed 中,一些特殊字符需要使用反斜杠进行转义,如`\`、`.`等。因此在使用这些字符进行匹配或替换时,需要特别注意转义字符的使用。
- 多行处理:默认情况下,sed 在处理文本时是基于行进行操作的,因此如果需要处理多行内容,可能会遇到一些问题。可以使用 sed 的 `-z` 参数来处理包含多行内容的文件。
```bash
sed -z 's/foo/bar/g' file.txt
```
- 文件备份:在使用 sed 进行替换操作时,默认情况下不会对原文件进行备份。如果希望对原文件进行备份,可以使用 sed 的 `-i` 参数,并指定备份文件的后缀名。
```bash
sed -i.bak 's/foo/bar/g' file.txt
```
- 脚本复杂度:当 sed 脚本变得复杂时,可能会导致维护困难和可读性差的问题。因此,在编写 sed 脚本时,要尽量保持简洁、清晰和可维护性。
- 正则表达式的理解:正则表达式是 sed 中重要的工具,但同时也容易出现错误和不准确的匹配。在使用正则表达式时,要确保对其语法和匹配特性有充分的理解。
以上是关于 sed 的性能优化技巧和一些常见问题和注意事项的介绍,希望对你在日常的文本处理中有所帮助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以“for/sed/awk”为主题,涵盖了使用for循环进行简单数值计算、进阶sed技巧、基础入门awk等多个文章。通过学习这些技术,你将能够灵活处理文本,完成删除、插入和提取文本等高级操作。此外,还将介绍字段切割、变量处理、嵌套循环等更为复杂的文本处理方法。探索for循环的原理与性能优化,并学习sed的高级技巧,如高效处理大文件与多行文本。此外,通过awk编程实现自定义函数与条件判断,还可以使用for循环实现简单文件批处理。掌握如何使用sed进行多文件操作与流编辑,以及awk进行数据处理与统计,如排序、过滤和分组。最后,你还将了解for循环的控制语句,如break、continue和嵌套,并学习如何与外部命令结合使用awk,实现更强大的文本处理。无论你是初学者还是有一定经验的开发者,本专栏都能帮助你提升文本处理的技能并更高效地处理数据。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【51单片机矩阵键盘扫描终极指南】:全面解析编程技巧及优化策略

# 摘要
本论文主要探讨了基于51单片机的矩阵键盘扫描技术,包括其工作原理、编程技巧、性能优化及高级应用案例。首先介绍了矩阵键盘的硬件接口、信号特性以及单片机的选择与配置。接着深入分析了不同的扫
【Pycharm源镜像优化】:提升下载速度的3大技巧

# 摘要
Pycharm作为一款流行的Python集成开发环境,其源镜像配置对开发效率和软件性能至关重要。本文旨在介绍Pycharm源镜像的重要性,探讨选择和评估源镜像的理论基础,并提供实践技巧以优化Pycharm的源镜像设置。文章详细阐述了Pycharm的更新机制、源镜像的工作原理、性能评估方法,并提出了配置官方源、利用第三方源镜像、缓存与持久化设置等优化技巧。进一步,文章探索了多源镜像组
【VTK动画与交互式开发】:提升用户体验的实用技巧
# 摘要
本文旨在介绍VTK(Visualization Toolkit)动画与交互式开发的核心概念、实践技巧以及在不同领域的应用。通过详细介绍VTK动画制作的基础理论,包括渲染管线、动画基础和交互机制等,本文阐述了如何实现动画效果、增强用户交互,并对性能进行优化和调试。此外,文章深入探讨了VTK交互式应用的高级开发,涵盖了高级交互技术和实用的动画
【转换器应用秘典】:RS232_RS485_RS422转换器的应用指南
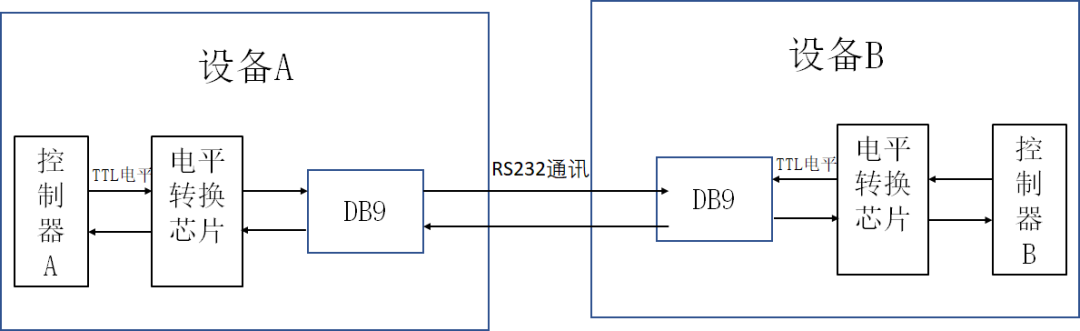
# 摘要
本论文全面概述了RS232、RS485、RS422转换器的原理、特性及应用场景,并深入探讨了其在不同领域中的应用和配置方法。文中不仅详细介绍了转换器的理论基础,包括串行通信协议的基本概念、标准详解以及转换器的物理和电气特性,还提供了转换器安装、配置、故障排除及维护的实践指南。通过分析多个实际应用案例,论文展示了转
【Strip控件多语言实现】:Visual C#中的国际化与本地化(语言处理高手)

# 摘要
本文全面探讨了Visual C#环境下应用程序的国际化与本地化实施策略。首先介绍了国际化基础和本地化流程,包括本地化与国际化的关系以及基本步骤。接着,详细阐述了资源文件的创建与管理,以及字符串本地化的技巧。第三章专注于Strip控件的多语言实现,涵盖实现策略、高级实践和案例研究。文章第四章则讨论了多语言应用程序的最佳实践和性能优化措施。最后,第五章通过具体案例分析,总结了国际化与本地化的核心概念,并展望了未来的技术趋势。
# 关
C++高级话题:处理ASCII文件时的异常处理完全指南
# 摘要
本文旨在探讨异常处理在C++编程中的重要性以及处理ASCII文件时如何有效地应用异常机制。首先,文章介绍了ASCII文件的基础知识和读写原理,为理解后续异常处理做好铺垫。接着,文章深入分析了C++中的异常处理机制,包括基础语法、标准异常类使用、自定义异常以及异常安全性概念与实现。在此基础上,文章详细探讨了C++在处理ASCII文件时的异常情况,包括文件操作中常见异常分析和异常处理策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )