SLF4J的配置文件详解:logback.xml
发布时间: 2024-01-20 11:13:45 阅读量: 86 订阅数: 26 

slf4j,logback.xml
# 1. 引言
## 1.1 什么是SLF4J
SLF4J(Simple Logging Facade for Java)是一个Java日志抽象层,通过提供统一的日志接口,使得应用程序可以方便地切换不同的日志实现框架,而不需要修改源代码。SLF4J 提供了一套简洁的日志门面和适配器,可以与不同的日志框架(如Logback、Log4j、java.util.logging等)无缝集成,简化了日志框架的使用和配置。
## 1.2 为什么需要配置文件
在使用SLF4J进行日志输出时,我们需要通过配置文件来指定日志的格式、输出目标、输出级别等信息。配置文件可以帮助我们灵活地控制日志的行为,满足不同需求,同时也方便了后续的日志管理和维护。
## 1.3 logback.xml简介
在SLF4J中,Logback是一个优秀的日志框架,它是对传统日志框架(如log4j)的改进和增强。logback.xml是Logback的配置文件,通过配置logback.xml,我们可以灵活地控制日志的输出行为,并且支持动态修改配置。
接下来,我们将详细介绍logback.xml的基本结构和常用配置,以帮助您更好地使用SLF4J进行日志输出。
# 2. 配置文件基本结构
配置文件是用来指导日志系统如何输出日志信息的重要文件,它决定了日志的格式、输出路径、级别等方面的设置。logback.xml文件是SLF4J的配置文件,下面我们将详细介绍它的基本结构和各部分的作用。
### 2.1 根节点及其属性
配置文件的根节点为\<configuration>,它可以包含多个属性来配置整个logback系统的行为。常见的属性包括debug、scan、scanPeriod等,它们可以控制logback的调试模式、扫描周期等行为。
```xml
<configuration debug="true">
<!-- 其他配置内容 -->
</configuration>
```
### 2.2 可选节点及其用途
配置文件中还可以包含\<appender>、\<logger>、\<root>等节点,它们分别用来配置日志输出地、日志记录器、根日志记录器等。
- \<appender>节点用于指定日志输出的目的地和格式。
- \<logger>节点用于指定特定包名的日志输出级别等设置。
- \<root>节点用于指定根日志记录器的设置。
```xml
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!-- appender相关配置 -->
</appender>
<logger name="com.example" level="DEBUG">
<!-- logger相关配置 -->
</logger>
<root level="INFO">
<!-- root相关配置 -->
</root>
</configuration>
```
### 2.3 例子:一个简单的logback.xml文件示例
下面是一个简单的logback.xml文件示例,它包含了根节点和一个控制台输出的appender节点。
```xml
<configuration debug="true">
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="DEBUG">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
```
这个示例中,我们指定了一个名为CONSOLE的appender,它将日志信息输出到控制台,并且配置了日志的输出格式为时间、线程ID、日志级别、日志记录器名称、日志消息等信息。
以上是配置文件基本结构的介绍,接下来我们将详细讨论各项配置的内容和作用。
# 3. 日志输出配置
日志输出是日志记录的最终结果,通过配置文件可以控制日志输出的格式、位置和级别等参数。在logback.xml中,可以通过配置节点来进行日志输出的相关设置。
#### 3.1 选择日志输出格式
在配置文件中,可以通过`<pattern>`节点来指定日志输出的格式。可以使用一系列的占位符来表示不同的日志信息,比如时间戳、日志级别、类名、方法名等。下面是一个示例:
```xml
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%date [%level] %logger{10} - %msg%n</pattern>
</encoder>
</appender>
```
在上面的例子中,使用`%date`表示时间戳,`%level`表示日志级别,`%logger{10}`表示最多显示10个字符的类名,`%msg`表示日志信息。`%n`表示换行符。
#### 3.2 设置日志输出文件名和路径
除了将日志输出到控制台,在大多数情况下,我们还需要将日志输出到文件中。通过配置`<file>`节点,可以指定日志文件的名称和输出路径。示例如下:
```xml
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>/var/log/myapp.log</file>
<encoder>
<pattern>%date [%level] %logger{10} - %msg%n</pattern>
</encoder>
</appender>
```
在上面的例子中,日志会被输出到`/var/log/myapp.log`文件中。
#### 3.3 控制日志输出级别
通过配置`<level>`节点,可以控制日志的输出级别。只有大于等于指定级别的日志才会被输出。示例如下:
```xml
<root level="INFO">
<appender-ref ref="STDOUT" />
<appender-ref ref="FILE" />
</root>
```
在上面的例子中,指定了根节点的日志级别为INFO,只有INFO、WARN、ERROR级别的日志才会被输出。
#### 3.4 配置日志滚动策略
日志文件会随着时间的推移不断增大,为了避免日志文件占用过多的磁盘空间,通常会配置一个日志滚动策略。通过配置`<rollingPolicy>`节点和`<triggeringPolicy>`节点,可以指定日志滚动的方式和触发条件。以下是一个示例:
```xml
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/var/log/myapp.log</file>
<encoder>
<pattern>%date [%level] %logger{10} - %msg%n</pattern>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/var/log/myapp.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
<triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<maxFileSize>10MB</maxFileSize>
</triggeringPolicy>
</appender>
```
在上面的例子中,通过`<rollingPolicy>`节点配置了基于时间的滚动策略,每天产生一个新的日志文件,并保留最近30天的日志文件。通过`<triggeringPolicy>`节点配置了基于文件大小的触发条件,当日志文件大小达到10MB时,会触发滚动操作。
通过以上配置,可以灵活而又方便地控制日志的输出方式和内容。
# 4. 错误日志配置
在开发过程中,经常会遇到各种错误和异常情况。为了更好地定位和解决这些问题,需要配置日志框架来捕获和记录错误信息。本章将介绍如何配置SLF4J和logback来处理错误日志。
#### 4.1 捕获异常信息
在日志框架中,可以配置捕获异常信息并输出到日志文件中。这样可以方便地记录错误栈轨迹,以便后续排查和分析。下面是一个简单的示例代码:
```java
try {
// 执行可能抛出异常的代码
} catch (Exception e) {
LOGGER.error("An error occurred: {}", e.getMessage(), e);
}
```
在上面的代码中,通过`LOGGER.error`方法将错误信息输出到日志文件中,第一个参数表示错误信息的格式,后面的参数是具体的错误信息和异常对象。
#### 4.2 定位异常发生的位置
为了更好地定位错误和异常的发生位置,可以使用`LoggerFactory`的`getCallerClass`方法来获取调用日志框架的类名。下面是一个示例代码:
```java
import org.slf4j.LoggerFactory;
public class MyService {
private static final org.slf4j.Logger LOGGER = LoggerFactory.getLogger(MyService.class);
public void doSomething() {
LOGGER.info("Method doSomething called from {}", LoggerFactory.getCallerClass().getSimpleName());
}
}
```
在上面的代码中,通过`LoggerFactory.getCallerClass().getSimpleName()`方法获取调用`doSomething`方法的类名,并将其输出到日志中。
#### 4.3 设置错误日志输出格式和级别
通过配置文件,可以灵活地设置错误日志的输出格式和级别。例如,可以将错误日志的级别设为ERROR,使其只记录严重的错误信息。下面是一个示例logback.xml配置文件:
```xml
<configuration>
<appender name="ERROR_FILE" class="ch.qos.logback.core.FileAppender">
<file>/path/to/error.log</file>
<encoder>
<pattern>%-5level [%thread] %logger{0} - %msg%n</pattern>
</encoder>
</appender>
<logger name="com.example" level="error">
<appender-ref ref="ERROR_FILE"/>
</logger>
</configuration>
```
上面的配置文件中,定义了一个名为`ERROR_FILE`的文件输出器,指定了输出文件的路径和日志格式。然后,通过`<logger>`标签将日志级别设为error,并将该输出器添加到该logger中。
通过上述配置,只有日志级别为error的日志会被记录到`/path/to/error.log`文件中,并且日志消息格式为`%-5level [%thread] %logger{0} - %msg%n`。
以上是错误日志的基本配置方法,通过合理的配置,可以更好地捕获并记录错误信息,为后续排查和修复问题提供更多的帮助。接下来,我们将介绍如何配置运行时日志。
# 5. 运行时日志配置
在实际应用程序中,有时我们需要在运行时根据不同情况来调整日志配置,比如动态修改日志级别、配置日志分割策略或者利用上下文信息定制日志。SLF4J和logback提供了一些功能和方法来满足这些需求。
### 5.1 动态修改日志级别
有时候我们希望能够在运行时动态地修改日志的输出级别,以便在不同阶段或不同场景下得到更详细或更简洁的日志信息。使用SLF4J和logback,我们可以通过以下方式实现动态修改日志级别:
```java
import org.slf4j.LoggerFactory;
import ch.qos.logback.classic.Level;
import ch.qos.logback.classic.Logger;
public class LogLevelModifier {
public static void modifyLogLevel(String loggerName, Level newLevel) {
Logger logger = (Logger) LoggerFactory.getLogger(loggerName);
logger.setLevel(newLevel);
}
}
// 示例用法
LogLevelModifier.modifyLogLevel("com.example.MyLogger", Level.DEBUG);
```
上述示例中,我们定义了一个`modifyLogLevel`方法,传入要修改级别的日志记录器名称以及要设置的新级别。然后,我们通过SLF4J和logback获取到对应的日志记录器,将其级别设置为新的级别。
### 5.2 配置日志分割策略
在某些情况下,我们希望能够将日志文件按照时间或大小进行分割,避免单个日志文件过大或日志混乱。logback提供了`RollingFileAppender`来满足这个需求,我们可以通过配置logback.xml来设置日志的分割策略。
下面是一个简单的例子,配置一个每天生成一个新日志文件的分割策略:
```xml
<appender name="ROLLING_FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>%d [%thread] %-5level %logger{35} - %msg%n</pattern>
</encoder>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>logs/application-%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
</appender>
```
上述配置中,`fileNamePattern`指定了生成的日志文件名的格式,`%d{yyyy-MM-dd}`表示按照年月日生成日志文件名。`maxHistory`指定了保留的历史日志文件个数。通过配置这个`RollingFileAppender`,我们可以实现按照时间来分割日志文件。
### 5.3 利用上下文信息定制日志
有时我们需要在日志中添加一些上下文信息,比如当前请求的用户ID、IP地址等,来更好地定位问题。在SLF4J和logback中,可以通过MDC(Mapped Diagnostic Context)来实现。
下面是一个使用MDC的示例:
```java
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC;
public class CustomLogger {
private static final Logger LOGGER = LoggerFactory.getLogger(CustomLogger.class);
public static void logRequest(String userId, String ipAddress) {
MDC.put("userId", userId);
MDC.put("ipAddress", ipAddress);
LOGGER.info("Received request from user: {} with IP: {}", userId, ipAddress);
MDC.clear();
}
}
// 示例用法
CustomLogger.logRequest("user123", "127.0.0.1");
```
上述示例中,我们使用MDC的`put`方法来设置上下文信息,然后通过SLF4J的Logger来记录日志,使用了占位符来动态替换上下文信息。最后,通过调用`clear`方法清除上下文,避免上下文信息在其他地方被使用。
通过上述方式,我们可以在日志中添加上下文信息,便于定制化日志记录。
总之,SLF4J和logback提供了一些配置和方法,使得我们可以在运行时动态修改日志级别、配置日志分割策略以及利用上下文信息定制日志。这些功能可以帮助我们更好地管理和定制日志输出。
# 6. 高级配置
在本章中,我们将介绍如何进行高级的SLF4J和logback配置,包括使用过滤器控制日志输出、自定义日志格式以及配置异步日志输出。
#### 6.1 使用过滤器控制日志输出
在某些情况下,我们可能需要根据特定的条件来控制日志的输出,这时可以使用logback内置的过滤器来实现。例如,我们可以通过条件过滤器仅输出特定级别的日志,或者根据日志消息的内容进行过滤。
下面是一个通过条件过滤器仅输出ERROR级别日志的示例:
```xml
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
<encoder>
<pattern>%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
```
这样配置后,只有ERROR级别的日志会被输出到控制台。
#### 6.2 自定义日志格式
除了使用内置的日志格式外,我们还可以根据实际需求自定义日志格式。通过配置自定义的encoder,可以完全控制日志消息的输出格式。
```xml
<encoder>
<pattern>%date [%thread] %-5level %logger{35} - %msg%n</pattern>
</encoder>
```
在这个例子中,我们定义了一个自定义的日志格式,包括日期、线程名、日志级别、logger名和消息内容。
#### 6.3 配置异步日志输出
在高并发的场景下,同步的日志输出可能会成为性能瓶颈。为了提升性能,logback提供了异步日志输出的功能,可以将日志的写操作放入独立的线程中进行,从而减少对主线程的影响。
```xml
<appender name="ASYNC_FILE" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="FILE" />
</appender>
<root level="DEBUG">
<appender-ref ref="ASYNC_FILE" />
</root>
```
通过以上配置,我们将日志的输出操作放入了名为ASYNC_FILE的异步Appender中,从而提升了日志输出的性能。
在本节中,我们介绍了如何利用过滤器控制日志输出、自定义日志格式以及配置异步日志输出,这些高级配置可以根据实际需求来使用,以提升日志系统的灵活性和性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏《日志记录-SLF4J/Java编程》旨在介绍和探索SLF4J日志框架及其在Java编程中的应用。首先,我们将详细介绍SLF4J的基本使用方法和特点,以及与Log4j等其他常见日志框架的比较。然后,我们会深入讲解SLF4J的配置文件logback.xml,以及如何使用SLF4J来管理和控制日志级别。接着,我们将探讨如何在实际项目中配置和使用SLF4J,以及与Logback和Log4j2的比较和选择。此外,我们还会分享使用SLF4J进行日志打印的最佳实践,以及如何使用SLF4J的MDC进行诊断上下文的详细解释。我们还将介绍如何使用SLF4J切割和归档日志文件,以及SLF4J的异步日志记录和性能优化技巧。此外,我们将探讨如何使用SLF4J打印异常堆栈和解决线程安全问题,并演示如何基于SLF4J自定义日志格式和样式。最后,我们将探索SLF4J与AOP的结合,以及如何利用SLF4J进行日志统计与分析。此外,本专栏还将涵盖SLF4J对日志输出格式的定制化配置、使用SLF4J进行日志记录的性能分析与优化、SLF4J与数据库集成的日志记录,以及SLF4J中的日志模块化与组件化开发。通过阅读本专栏,您将深入了解SLF4J日志框架及其在Java编程中的重要作用,并掌握相关的技巧和最佳实践。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
操作系统实验九深度解析:9个关键步骤助你实现理论到实践的飞跃

# 摘要
本文旨在对操作系统的基础理论与核心机制进行深入分析,并提供了实验操作与环境搭建的具体指南。首先,概述了操作系统的基本理论,并进一步探讨了进程管理、内存分配与回收、文件系统以及I/O管理等核心机制。接着,文章详细阐述了实验环境的配置,包括虚拟化技术的应用、开发工具的准备及网络安全设置。最后,通过操作系统实验九的具体操作,回顾理论知识,并针对
一步到位配置银河麒麟V10:新手必看环境搭建教程

# 摘要
本文全面介绍了银河麒麟V10操作系统的功能特点,重点探讨了基础环境配置、开发环境搭建、网络配置与安全、系统优化与定制以及高级操作指南。从系统安装与启动的基本步骤到软件源和包管理,再到开发工具、虚拟化环境及性能分析工具的配置,文章详细阐述了如何为开发和维护工作搭建一个高效的银河麒麟V10平台。此外,还讲解了网络配置、高级网络功能以及系统安全加固,提供了用户权限
微机原理与接口技术深度剖析:掌握楼顺天版课后题的系统理解(10个必须掌握的关键点)
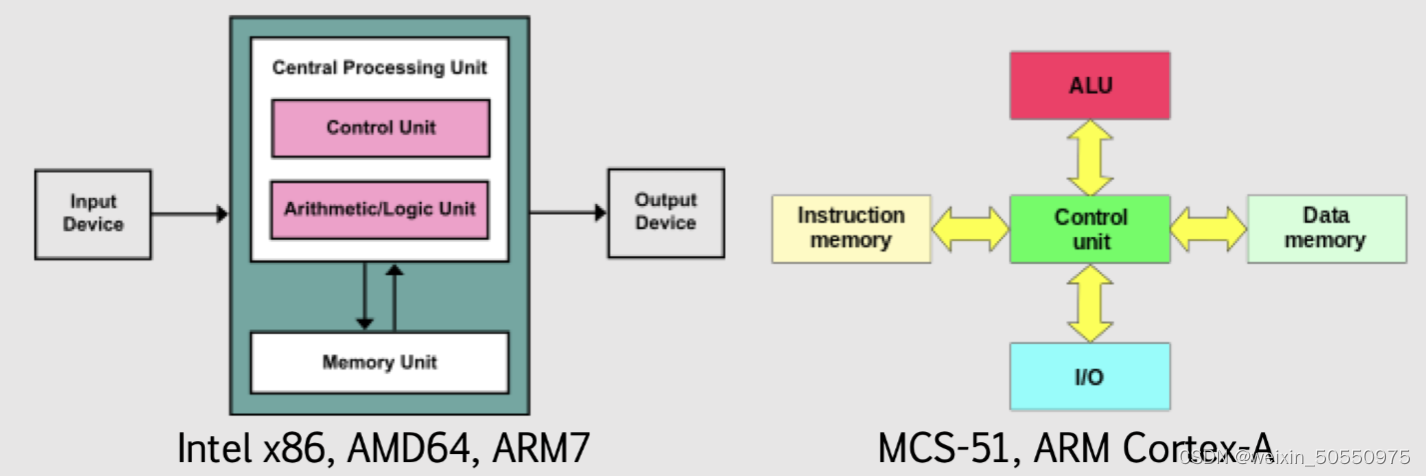
# 摘要
本文详细探讨了微机原理与接口技术,涵盖了微处理器架构、指令集解析、存储系统、输入输出设备和系统总线等关键技术领域。文章首先对微处理器的基本组成和工作原理进行了介绍,并对指令集的分类、功能以及寻址模式进行了深入分析。随后,本文探讨了存储器系统的层次结构、接口技术和I/O接口设计实践。在此基础上,文章分析了输入输出设备的分类与接口技术,以及系统总线的工作原理和I/O接
【SIL9013芯片全面解读】:解锁SIL9013芯片的20个核心秘密与应用技巧
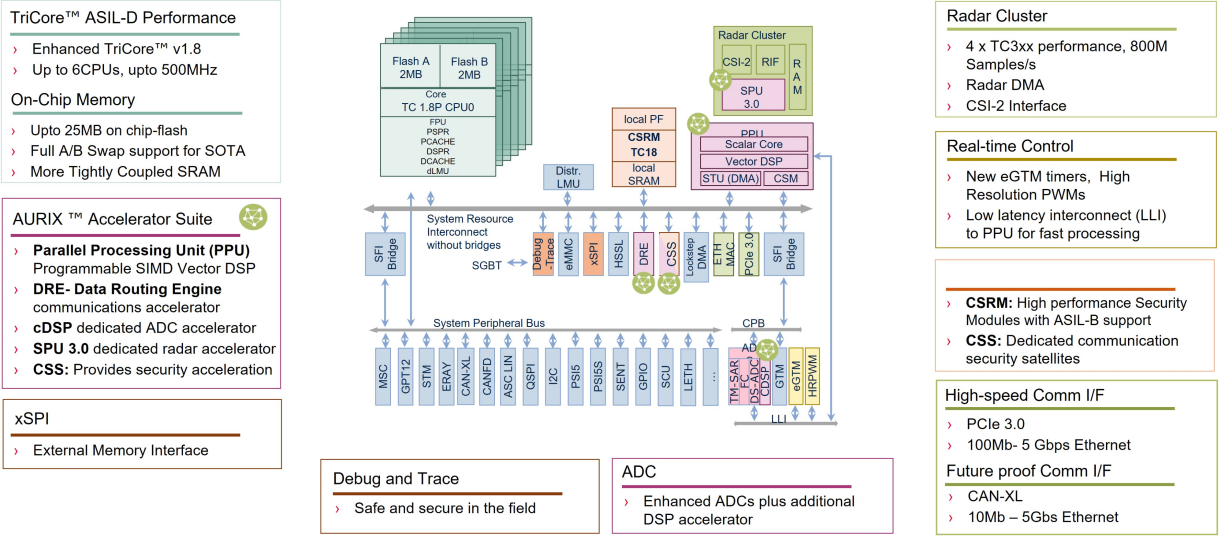
# 摘要
SIL9013芯片作为一款先进的半导体产品,在嵌入式系统、物联网设备和多媒体处理领域中具有广泛的应用。本文首先概述了SIL9013芯片的基本架构设计,包括其硬件组成、功能模块、数据传输机制和编程接口。随后,文章深入分析了SIL9013的电源管理策略
一步到位:掌握Citrix联机插件的终极安装与配置指南(附故障排查秘籍)

# 摘要
本文全面探讨了Citrix联机插件的安装、配置、故障排查以及企业级应用。首先介绍了Citrix插件的基本概念及安装前的系统要求。接着,详细阐述了安装过程、高级配置技巧和多用户管理方法。此外,本文还讨论了故障排查和性能优化的实践,包括利用日志文件进行故障诊断和系统资源监控。最后,本文探索了Citrix插件在不同行业中的应用案例,特别是大规模部署和管理策略,并展望了与
【深入解析】:揭秘CODESYS中BufferMode优化多段速运行的3大设置
# 摘要
CODESYS作为工业自动化领域的重要软件平台,其BufferMode功能对多段速运行和性能优化起到了关键作用。本文首先介绍了CODESYS基础和多段速运行的概念,随后深入探讨了BufferMode的理论基础、配置方法、性能优化以及在实践中的应用案例。通过分析实际应用中的性能对比和优化实践,本文总结了BufferMode参数调整的技巧,并探讨了其在复杂系
华为B610-4e路由器升级实战指南:R22 V500R022C10SPC200操作步骤

# 摘要
本文为华为B610-4e路由器的升级实战操作提供了一份全面的指南。从升级前的准备工作开始,涵盖了硬件检查、软件准备和升级计划的制定。接着,详细介绍了升级操作步骤,包括系统登录、固件升级前的准备、执行升级以及升级后的验证和调试。此外,本文还讨论了升级后的维护工作,如配置恢复与优化、性能监控与问题排除,并通过成功与失败案例分析,提炼了升级经验。最后,对华为B610-4e路由器升级的未来展望进行了探讨,包括技术发展、市场趋势和用
【内存管理黄金法则】:libucrt内存泄漏预防与性能优化秘籍
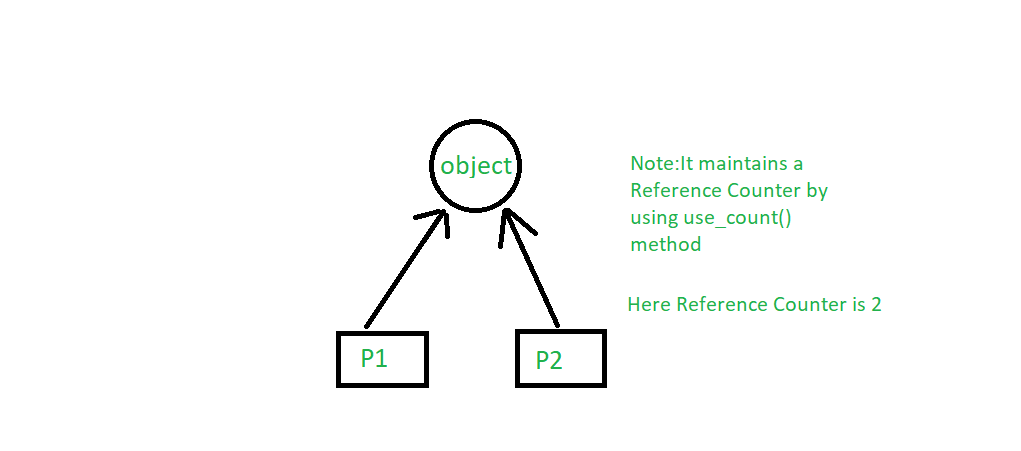
# 摘要
本文针对内存管理黄金法则进行概述,并深入探讨内存泄漏的识别与预防策略。通过分析内存泄漏的概念、危害、检测技术以及预防措施,本文旨在为开发者提供有效的内存管理工具和实践方法。文章还详细解析了libucrt内存管理机制,并通过实例和监控工具展示如何排查和解决内存泄漏问题。此外,本文探讨了性能优化的原则和方法,特别是针对libucrt内存管理的优化技巧,并分
【提升效率:Cadence CIS数据库性能优化】:实战秘籍,让你的数据库飞速响应
# 摘要
Cadence CIS数据库在高性能计算领域具有广泛应用,但其性能优化面临诸多挑战。本文从理论基础到实践技巧,系统性地介绍了性能优化的方法与策略。首先概述了数据库的架构特点及其性能挑战,随后分析了数据库性能优化的基本概念和相关理论,包括系统资源瓶颈和事务处理。实践章节详细讨论了索引、查询和存储的优化技巧,以及硬件升级对性能的提升。高级章节进一步探讨了复合索引、并发控制和内
【流程优化之王】:BABOK业务流程分析与设计技巧
# 摘要
随着企业对业务流程管理重视程度的提升,业务流程分析成为确保业务效率和优化流程的关键环节。本文从BABOK(Business Analysis Body of Knowledge)的角度,对业务流程分析的重要性和核心方法进行了全面探讨。首先,文章概括了业务流程的基础知识及其在商业成功中的作用。接着,深入分析了业务流程分析的核心技术,包括流程图和模型的制作、分析技术从数据流到价值流的应用,以及如何准确识别和定义业务需求。在设计阶段,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )