深度学习在游戏AI中的应用
发布时间: 2025-01-04 10:10:47 阅读量: 19 订阅数: 12 

# 摘要
随着人工智能技术的迅猛发展,深度学习已逐步成为游戏AI领域的核心技术,提供了更加丰富和智能的游戏体验。本文首先介绍了深度学习与游戏AI的基础知识,深入探讨了深度学习算法如何在游戏中实现决策制定、角色行为建模以及游戏平衡性调整。随后,本文详述了强化学习在游戏AI中的应用,包括马尔可夫决策过程、奖励函数设计以及相关算法的选择与实现,并以AlphaGo等案例进行实际应用分析。在高级主题章节中,本文探讨了多智能体学习、游戏仿真以及模型可解释性等前沿话题,并对深度学习工具与框架进行了介绍。文章最后展望了深度学习在未来游戏AI中的前景,强调了技术交叉融合的重要性以及AI伦理和社会责任问题。
# 关键字
深度学习;游戏AI;强化学习;多智能体学习;模型可解释性;TensorFlow;PyTorch
参考资源链接:[深度学习题库详解:150道精选期末复习题目](https://wenku.csdn.net/doc/7mayiwx0nn?spm=1055.2635.3001.10343)
# 1. 深度学习与游戏AI基础
游戏作为互动艺术和娱乐的完美结合体,一直走在技术革新的前沿。随着深度学习技术的迅猛发展,游戏人工智能(AI)已经从传统的预设脚本和状态机过渡到能进行复杂决策的智能系统。本章我们将探讨深度学习在游戏AI中的基础应用,为读者搭建起对后续章节技术细节的初步认识。
## 深度学习概述
深度学习是机器学习的一个分支,通过模拟人脑的工作方式使用人工神经网络进行学习。在游戏AI中,深度学习模型能够处理大量数据,并从中提取出可用于游戏策略制定的特征和模式。例如,深度学习可以在无标记的游戏中自动学习如何有效地进行游戏,无需人工干预。
## 游戏AI的演进
游戏AI的演进可以追溯到早期的游戏中的简单算法,例如贪吃蛇的路径寻找,到现代游戏中的复杂非线性决策过程。深度学习的加入,使得AI能够自主学习游戏策略,与玩家进行更高级别的交互,从而提供更加丰富和具有挑战性的游戏体验。
## 深度学习与游戏AI的结合
当深度学习技术遇到游戏AI时,便产生了诸如深度Q网络(DQN)等能够自主学习并优化其游戏表现的算法。这些技术不仅提升了游戏的可玩性,还为研究者提供了新的工具,用于开发更高级的AI和游戏设计思路。在后续章节中,我们将深入了解如何利用这些技术实现游戏AI的自主学习和决策。
# 2. 深度学习算法及其在游戏AI中的实现
深度学习作为人工智能研究领域的一个重要分支,已经在游戏AI中得到了广泛的应用。它通过模拟人脑神经网络结构和工作机制,能够使计算机系统从大量数据中学习并做出复杂的决策。在本章中,我们将深入探讨深度学习的基础理论,探讨其在游戏AI中的应用,并讨论模型优化和实践的策略。
## 2.1 深度学习的基础理论
深度学习的基础理论是构建有效游戏AI模型的基石。理解这些理论对于设计、训练和优化深度学习模型至关重要。
### 2.1.1 人工神经网络的基本概念
人工神经网络(ANN)是深度学习的基石,其灵感来源于生物神经网络的结构和功能。ANN由大量的节点(或神经元)和它们之间的连接组成,每个连接都有一个权重,这些权重在学习过程中不断更新。一个基本的神经网络通常包括输入层、隐藏层和输出层。
在游戏AI中,神经网络可以用来模拟玩家的行为模式,预测对手的策略,甚至用来平衡游戏的难度。例如,可以通过神经网络分析玩家的移动模式,预测其下一步行动,从而调整游戏中的非玩家角色(NPC)的行为。
### 2.1.2 反向传播算法与网络训练
反向传播算法是深度学习中用于训练神经网络的关键技术。它通过计算网络输出与期望输出之间的误差,并将这个误差“反向传播”回网络,从而更新网络中的权重,使得误差最小化。
在游戏AI的训练中,反向传播算法能够使模型通过大量游戏回合的数据学习优化。例如,在开发一个自走棋AI时,通过反向传播算法可以让AI学习如何根据不同棋子的搭配和对手策略选择合适的棋子。
## 2.2 深度学习在游戏AI中的应用场景
深度学习在游戏AI中的应用多样,覆盖了游戏的各个方面,从决策制定到角色行为建模,再到游戏平衡性的调整与分析。
### 2.2.1 游戏AI中的决策制定
在游戏AI中,决策制定是核心功能之一。深度学习能够使AI根据当前游戏状态做出复杂的策略选择,而不仅仅是基于简单规则的决策。
例如,在策略游戏如《星际争霸》中,深度学习可以用来分析对手的单位配置、建筑布局和资源管理等信息,从而制定出更有针对性的战术策略。
### 2.2.2 角色行为建模与预测
角色行为建模是游戏AI的另一个重要应用场景。通过深度学习,AI可以学习人类玩家的行为模式,并在游戏世界中重现这些行为。
在角色扮演游戏(RPG)中,深度学习可以用来构建非玩家角色的个性,使其行为更加符合游戏背景和逻辑。这样不仅可以提高游戏的真实感,还能提升玩家的沉浸感。
### 2.2.3 游戏平衡性调整与分析
游戏平衡性对于确保游戏的公平性和趣味性至关重要。深度学习技术可以分析大量游戏数据,识别出可能导致游戏不平衡的因素,并提出调整建议。
例如,在多人在线战斗竞技场(MOBA)游戏中,深度学习可以用来分析不同角色和技能组合的胜率,从而帮助设计者调整平衡性,确保游戏的公平竞争环境。
## 2.3 深度学习模型的优化与实践
在游戏AI开发过程中,对深度学习模型的优化和实践是提高AI表现的关键步骤。模型训练技巧和评估方法的合理运用,能够显著提升AI的性能。
### 2.3.1 模型训练技巧与正则化方法
在深度学习模型的训练过程中,掌握一些关键的技巧对于优化模型至关重要。正则化方法,如L1和L2正则化,可以防止模型过拟合,提高模型的泛化能力。
例如,在训练用于预测玩家行为的模型时,可能会引入正则化项来防止模型学习到训练数据中的噪声,从而提高其在新玩家数据上的预测准确性。
### 2.3.2 模型评估与验证技巧
模型评估是深度学习项目中的重要环节,它涉及到验证模型性能和判断模型是否已准备好部署到实际环境中。
交叉验证是常用的模型评估技巧之一。它通过将数据集分成多个子集,在多个不同的训练/测试组合上训练和测试模型,从而获得对模型性能更全面的评估。
下面是一个简单的Python代码示例,展示了如何使用交叉验证评估一个分类模型的性能:
```python
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
# 生成一个模拟的分类数据集
X, y = make_classification(n_samples=1000, n_features=20, n_classes=2, random_state=42)
# 创建一个逻辑回归分类器
clf = LogisticRegression(random_state=42)
# 使用交叉验证计算准确率
scores = cross_val_score(clf, X, y, cv=5)
print(f"Accuracy: {scores.mean():.2f} (+/- {scores.std() * 2:.2f})")
```
在这个代码示例中,我们首先导入了必要的模块,然后创建了一个模拟的分类数据集和一个逻辑回归分类器。接着,使用5折交叉验证计算了模型的准确率,并打印出来。这种评估方法有助于确保模型在不同的数据子集上都有良好的表现,提高了模型的可靠性。
## 总结
在本章节中,我们深入了解了深度学习算法的基础理论,探索了其在游戏AI中的应用场景,并讨论了模型优化和实践中的关键技巧。通过对人工神经网络、反向传播算法和模型训练的分析,以及在游戏AI决策制定、行为建模和平衡性分析中的应用案例,我们对深度学习在游戏AI领域的潜力有了全面的认识。接下来的章节将探讨强化学习在游戏AI中的应用,继续深度剖析这一激动人心的领域。
# 3. 强化学习在游戏AI中的应用
## 3.1 强化学习的基本原理
### 3.1.1 马尔可夫决策过程与强化学习
强化学习是一种让计算机从环境中学习并作出决策的方法。它是一种无监督学习,依据于马尔可夫决策过程(MDP),来寻找最优策略以最大化预期收益。在游戏AI中,MDP可以由游戏状态、玩家动作、奖励信号以及状态转移概率所组成。
在游戏环境中,状态可以是当前的游戏画面、玩家得分、剩余生命等信息。一个动作表示游戏AI可以采取的某个特定的决策,比如向前移动、跳跃或攻击。奖励信号是游戏AI根据当前动作在游戏环境中所得到的正面或负面反馈。
为了准确模拟游戏环境,强化学习算法使用状态转移概率来描述下一个状态的概率分布,它依赖于当前状态和所采取的动作。通过多次尝试,游戏AI学会在给定状态下采取何种动作能获取最高的预期回报。
### 代码示例和逻辑分析
这里提供一个简单的Q-learning算法的伪代码,用于说明强化学习算法的基本逻辑:
```python
# 初始化Q表,其中Q(s,a)表示在状态s下采取动作a的预期回报
Q = initialize_q_table()
# 设置学习参数
alpha = 0.1 # 学习率
gamma = 0.9 # 折扣因子
# 设置环境和行为策略,这里用epsilon-greedy策略
epsilon = 0.1
action_space = ...
# 强化学习主循环
for episode in episodes:
state = env.reset()
done = False
while not done:
if random() < epsilon:
action = choose_random_action(action_space)
else:
action = choose_greedy_action(Q, state)
next_state, reward, done, _ = env.step(action)
Q[state, action] = Q[state, action] + alpha * (reward + gamma * max(Q[next_state, :]) - Q[state, action])
state = next_state
```
在该伪代码中,`Q`表示价值函数,`epsilon`表示探索的概率,`alpha`表示学习率,`gamma`表示未来奖励的折扣。每次循环中,算法选择一个动作并执行,然后更新Q表中对应状态和动作的预期回报值。
### 3.1.2 奖励函数的设计与调整
奖励函数的设计在强化学习中至关重要,因为它直接影响学习算法的性能和最终策略的质量。奖励函数需要能够精确地表达任务的目标,既不能过于稀疏,也不能过于密集。
在游戏AI中,奖励通常根据游戏的规则来设计。例如,在一个赛车游戏中,完成比赛可以给予一个固定的正奖励,而发生碰撞或掉落赛道则给予负奖励。
```python
def reward_function(game_state, action):
if action == 'finish':
return REWARD_FOR_FINISHING
elif action == 'crash':
return PENALTY_FOR_CRASHING
# 其他可能的行为和奖励
...
```
奖励函数的调整需要多次迭代。初始时,可能需要先确定一个基本的奖励结构,然后根据实际表现进行微调,确保奖励能够正确引导AI朝着游戏目标前进。
## 3.2 强化学习算法的选择与实现
### 3.2.1 Q学习与深度Q网络(DQN)
Q学习是最基础的强化学习算法之一。它直接学习一个动作价值函数,即在给定状态下采取某一动作的预期回报。Q学习通过不断更新价值函数来达到收敛,最终学习到一个最优策略。
然而,当状态空间非常大或连续时,Q学习变得不切实际,

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《深度学习题库大全-hr.docx》专栏汇集了深度学习领域的丰富知识,涵盖了广泛的主题。专栏中的文章包括:
* **深度学习框架比较**:比较了流行的深度学习框架,如 TensorFlow、PyTorch 和 Keras,以帮助读者选择最适合其需求的框架。
* **循环神经网络 (RNN) 与长短时记忆网络 (LSTM)**:深入探讨了 RNN 和 LSTM,重点关注它们的架构、训练方法和在序列数据处理中的应用。
* **深度学习模型调优**:提供了优化深度学习模型性能的实用技巧,包括超参数调整、正则化技术和数据增强。
* **深度学习中的正则化技术**:介绍了各种正则化技术,如 L1 正则化、L2 正则化和 dropout,以防止过拟合并提高模型泛化能力。
* **深度学习在游戏 AI 中的应用**:展示了深度学习在游戏 AI 中的应用,包括强化学习、图像识别和自然语言处理。
* **深度学习在生物信息学中的应用**:探索了深度学习在生物信息学中的应用,如基因组分析、蛋白质结构预测和疾病诊断。
该专栏为深度学习从业者和研究人员提供了全面的知识库,涵盖了从基础概念到高级应用的各个方面。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【IBM X230主板维修宝典】:故障诊断与解决策略大揭秘
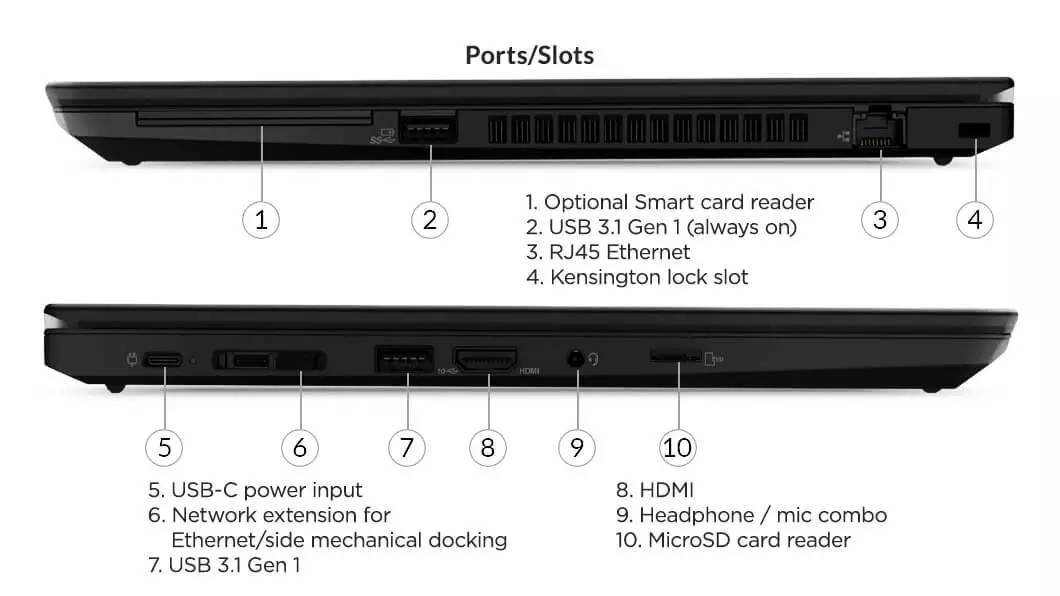
# 摘要
本文旨在全面探讨IBM X230主板的结构、故障诊断、检测与修复技巧。首先,概述了IBM X230主板的基本组成与基础故障诊断方法。随后,深入解析了主板的关键组件,如CPU插槽、内存插槽、BIOS与CMOS的功能,以及电源管理的故障分析。此外,本文详细介绍了使用硬件检测工具进行故障检测的技巧,以及在焊接技术和电子元件识别与更换过程中需要遵循的注意事项。通过对维修案例的分析,文章揭示了
ELM327中文说明书深度解析:从入门到精通的实践指南
# 摘要
ELM327设备是一种广泛应用于汽车诊断和通讯领域的接口设备,本文首先介绍了ELM327的基本概念和连接方法,随后深入探讨了其基础通信协议,包括OBD-II标准解读和与车辆的通信原理。接着,本文提供了ELM327命令行使用的详细指南,包括命令集、数据流监测与分析以及编程接口和第三方软件集成。在高级应用实践章节中,讨论了自定义脚本、安全性能优化以及扩展功能开发。最后,文章展望了ELM327的未来发展趋势,特别是在无线技术和智能汽车时代中的潜在应用与角色转变。
# 关键字
ELM327;OBD-II标准;数据通信;故障诊断;安全性能;智能网联汽车
参考资源链接:[ELM327 OBD
QNX任务调度机制揭秘:掌握这些实践,让你的应用性能翻倍

# 摘要
本文详细探讨了QNX操作系统中任务调度机制的理论基础和实践应用,并提出了一些高级技巧和未来趋势。首先概述了QNX任务调度机制,并介绍了QNX操作系统的背景与特点,以及实时操作系统的基本概念。其次,核心原理章节深入分析了任务调度的目的、要求、策略和算法,以及任务优先级与调度器行为的关系。实践应用章
CANOE工具高效使用技巧:日志截取与分析的5大秘籍
# 摘要
本文旨在提供对CANoe工具的全面介绍,包括基础使用、配置、界面定制、日志分析和高级应用等方面。文章首先概述了CANoe工具的基本概念和日志分析基础,接着详细阐述了如何进行CANoe的配置和界面定制,使用户能够根据自身需求优化工作环境。文章第三章介绍了CANoe在日志截取方面的高级技巧,包括配置、分析和问题解决方法。第四章探讨了CANoe在不同场景下的应用
【面向对象设计核心解密】:图书管理系统类图构建完全手册

# 摘要
面向对象设计是软件工程的核心方法之一,它通过封装、继承和多态等基本特征,以及一系列设计原则,如单一职责原则和开闭原则,支持系统的可扩展性和复用性。本文首先回顾了面向对象设计的基础概念,接着通过图书管理系统的案例,详细分析了面向对象分析与类图构建的实践步骤,包括类图的绘制、优化以及高级主题的应用。文中还探讨了类图构建中的高级技巧,如抽象化、泛化、关联和依赖的处理,以及约束和注释的应用。此外,本文将类图应用于图书管理
零基础到专家:一步步构建软件需求规格说明

# 摘要
软件需求规格说明是软件工程中的基
【操作系统电梯调度算法】:揭秘性能提升的10大策略和实现

# 摘要
电梯调度算法作为智能建筑物中不可或缺的部分,其效率直接影响乘客的等待时间和系统的运行效率。本文首先探讨了电梯调度算法的基础理论,包括性能指标和不同调度策略的分类。随后,文章对实现基础和进阶电梯调度算法的实践应用进行了详细介绍,包括算法编码、优化策略及测试评估方法。进一
NAND Flash固件开发必读:专家级别的4个关键开发要点
# 摘要
NAND Flash固件开发是存储技术中的关键环节,直接影响存储设备的性能和可靠性。本文首先概述了NAND Flash固件开发的基础知识,然后深入分析了NAND Flash的存储原理和接口协议。特别关注了固件开发中的错误处理、数据保护、性能优化及高级功能实现。本文通过详细探讨编程算法优化、读写效率提升
【SSD技术奥秘】:掌握JESD219A-01标准的10个关键策略

# 摘要
本论文全面概述了固态驱动器(SSD)技术,并深入探讨了JESD219A-01标准的细节,包括其形成背景、目的、影响、关键性能指标及测试方法。文章还详细讲解了SSD的关键技术要素,例如NAND闪存技术基础、SSD控制器的作用与优化、以及闪存管理技术。通过分析标准化的SSD设计与测试,本文提供了实践应用案例,同时针对JESD219A-01标准面临的挑战,提出了相应的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )