Hadoop序列文件进阶:深入了解压缩机制与性能优化


西门子S7-200 Smart PLC与昆仑通态触摸屏控制三台台达变频器通讯方案,西门子S7-200 Smart PLC与昆仑通态触摸屏控制三台台达变频器通讯方案,西门子s7 200smart与3台台
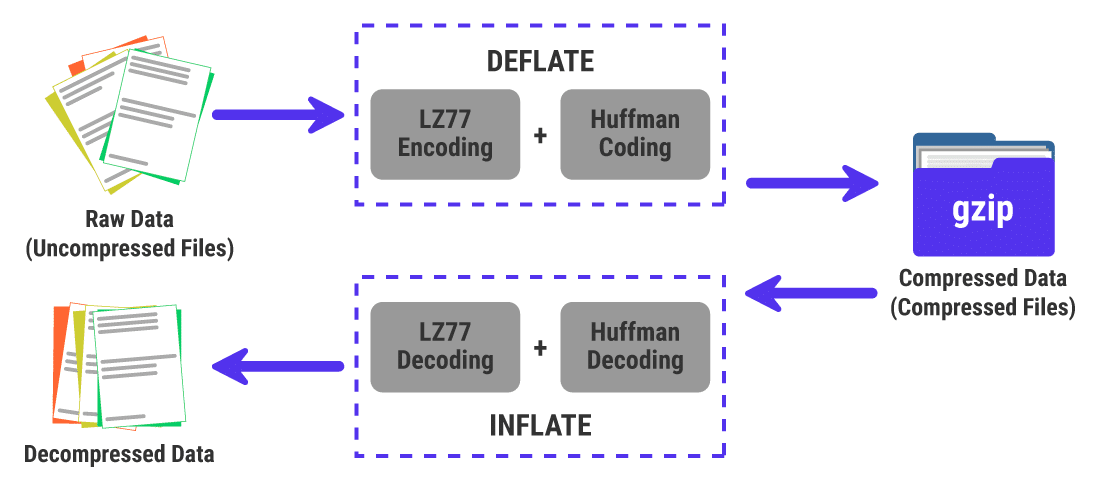
1. Hadoop序列文件概览
在本章中,我们将对Hadoop序列文件进行基础性的介绍,目的是为读者提供一个全面的理解框架,从而为进一步深入探讨序列文件的压缩机制和性能优化打下坚实的基础。
1.1 Hadoop序列文件的定义
Hadoop序列文件是由Hadoop框架提供的一种特定格式的文件,用于存储二进制键值对。这种文件格式在大数据处理中非常常见,尤其是在Hadoop生态系统中进行数据交换时。
1.2 序列文件的优点
序列文件的主要优点是其对连续数据的高效存储和读写性能,这对于大数据环境下的存储和检索操作来说是非常重要的。此外,它们还支持记录分隔符,这使得数据更易于分割和处理。
1.3 序列文件的使用场景
序列文件被广泛应用于Hadoop的MapReduce作业中,特别是在需要快速序列化和反序列化大量数据时。它们也经常在HBase和MapFile中使用,从而提供了一个高效的存储机制。
- 在下一章,我们将深入探讨序列文件的压缩机制,包括压缩技术的重要性以及Hadoop支持的各种压缩算法。
在接下来的章节中,我们将详细探讨压缩技术在Hadoop中的应用,以及如何通过压缩来提升序列文件的存储效率和处理性能。
2. 序列文件压缩机制的理论基础
在当今的大数据时代,数据量的爆炸式增长要求我们不仅要关注数据的存储,更要注重数据的传输效率和处理速度。Hadoop作为一个分布式存储和计算平台,其对数据压缩的支持,能显著减少存储空间和提高数据处理性能。在这一章节,我们将深入探讨序列文件压缩机制的理论基础。
2.1 压缩技术在Hadoop中的应用
2.1.1 压缩技术的重要性
在分布式系统中,数据压缩不仅有助于节省存储成本,还能有效减少网络传输负载。这对于Hadoop这样的平台尤为重要,因为Hadoop处理的是PB级别的数据,而网络带宽通常是有限的。
使用压缩技术可以带来以下优势:
- 减少磁盘I/O操作,由于磁盘读写是数据处理中的瓶颈之一,压缩可以减少这一瓶颈。
- 提高数据传输效率,通过网络传输压缩后的数据能够减少带宽消耗。
- 降低存储成本,随着数据量的增加,存储成本是不可忽视的问题,压缩数据能够存储更多的信息。
2.1.2 Hadoop支持的压缩算法概览
Hadoop支持多种压缩算法,并为不同的使用场景提供了各种压缩选项。其中一些广泛使用的包括:
Gzip:是一种流行的压缩格式,支持较快的压缩和解压缩速度,但压缩比例较低。Bzip2:提供较高的压缩比,但压缩和解压缩速度较慢。Snappy:由Google开发,专为速度而设计,压缩速度非常快,适合实时数据处理。
Hadoop通过集成这些压缩库,提供了在数据处理流程中对数据进行压缩和解压缩的能力。开发者可以根据不同的需求选择合适的压缩算法。
2.2 序列文件的压缩策略
2.2.1 压缩前的数据准备
在进行数据压缩之前,需要对数据进行适当的整理和预处理,以确保压缩的效率和效果。这可能包括:
- 数据清洗:移除冗余和不必要的信息。
- 数据排序:对数据进行排序可以提高压缩算法的效率,尤其是对于那些利用数据模式进行压缩的算法。
- 数据类型转换:针对特定数据类型选择合适的压缩方式。
2.2.2 压缩算法的选择与配置
选择合适的压缩算法对于性能优化至关重要。选择算法时,需要考虑以下几个因素:
- 压缩比:需要在压缩效率和解压缩速度之间找到平衡点。
- CPU使用率:某些压缩算法会占用较多的CPU资源。
- 并行处理能力:不同的压缩算法对并行计算的支持程度不一。
例如,如果对压缩速度要求不高,可以考虑使用Bzip2。如果对实时处理有较高要求,则Snappy可能是更好的选择。
2.2.3 压缩对序列文件性能的影响
压缩对性能的影响可以从多个维度来分析:
- CPU负载:压缩和解压缩需要消耗CPU资源,因此,如果CPU资源有限,可能需要平衡压缩程度和计算资源。
- 网络带宽:在网络传输方面,压缩可以显著降低传输数据量,提高网络效率。
- 存储成本:压缩能够显著减少存储空间需求,从而降低存储成本。
通过合理配置压缩策略,可以达到优化存储和提升处理速度的目的。
在下面的章节中,我们将深入探讨序列文件压缩实践,并提供实际操作的例子,以便读者更好地理解如何应用这些理论知识来优化Hadoop中的数据处理流程。
3. 序列文件压缩实践
3.1 压缩算法的实际应用
3.1.1 不同压缩算法的测试与比较
在Hadoop环境中,不同压缩算法的性能差异会直接影响序列文件的整体效率。本节将通过实验,比较几种主流压缩算法的压缩率、压缩速度和解压缩速度。
实验设置与方法
首先,我们需要准备一定量的文本文件和序列文件,然后使用不同的压缩算法进行测试。常见的压缩算法包括Gzip, Bzip2, Lzop, Snappy和Deflate。
实验中,我们将记录每种算法在压缩和解压缩过程中的耗时,以及压缩后的文件大小。此外,我们还将使用Hadoop自带的性能测试工具mrjob,来模拟真实环境下大数据处理时的性能表现。
实验数据与分析
假设我们得到如下实验结果表格:
| 压缩算法 | 压缩时间 (s) | 解压时间 (s) | 压缩前大小 (MB) | 压缩后大小 (MB) | 压缩比 |
|---|---|---|---|---|---|
| Gzip | 320 | 45 | 1000 | 150 | 6.67 |
| Bzip2 | 580 | 90 | 1000 | 120 | 8.33 |
| Lzop | 160 | 30 | 1000 | 180 | 5.56 |
| Snappy | 110 | 40 | 1000 | 400 | 2.5 |
| Deflate | 190 | 50 | 1000 | 200 | 5 |
通过对比分析,我们可以得出以下结论:
Snappy提供了最快的压缩速度,这对于实时或近实时处理非常有利。Bzip2提供了最高的压缩比,但压缩和解压缩速度相对较慢,更适合于不频繁读写的场景。Gzip和Deflate的表现较为平衡,但Gzip在压缩比上稍胜一筹。Lzop的压缩速度和压缩比表现都不错,是一个折中的选择。
为了更直观地展示这些算法在Hadoop作业中的性能影响,我们可以使用mermaid流程图来表示:

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【EDEM仿真非球形粒子专家】:揭秘提升仿真准确性的核心技术
SGMII传输层优化:延迟与吞吐量的双重提升技术
社交网络分析工具大比拼:Gephi, NodeXL, UCINET优劣全面对比
【矩阵求逆的历史演变】:从高斯到现代算法的发展之旅
【信号异常检测法】:FFT在信号突变识别中的关键作用
雷达数据压缩技术突破:提升效率与存储优化新策略
Python环境监控高可用构建:可靠性增强的策略
SaTScan软件的扩展应用:与其他统计软件的协同工作揭秘
Java SPI与依赖注入(DI)整合:技术策略与实践案例
原型设计:提升需求沟通效率的有效途径


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )










