【数据库逆向工程全解析】:从现有数据库快速生成ER图的技巧


ERStudio逆向工程从sql server 2000中导出jbpm数据库的idef1x图
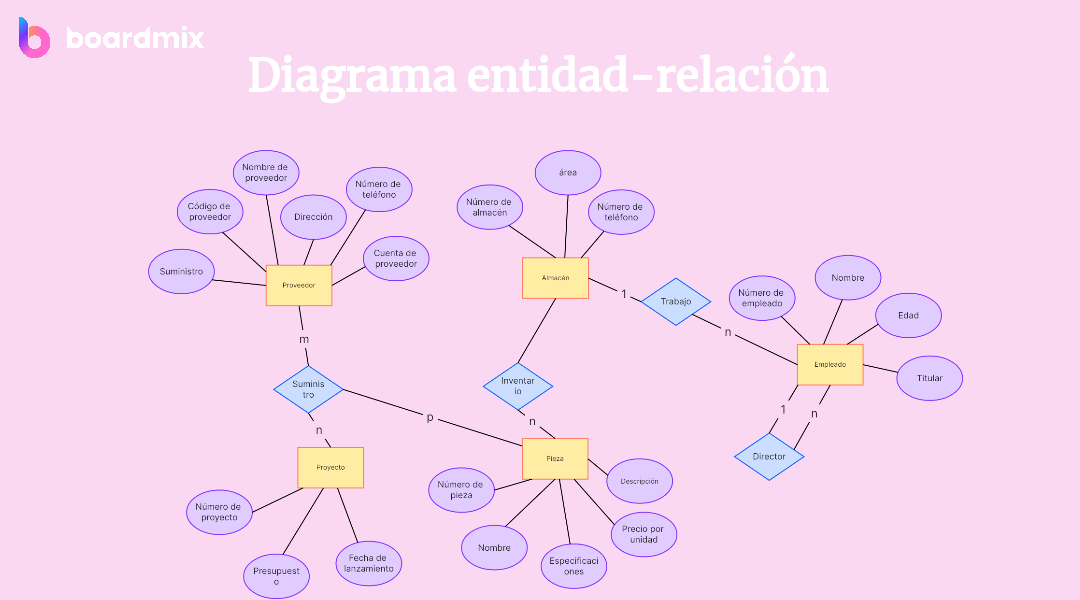
参考资源链接:数据库ER图讲解ppt课件.ppt
1. 数据库逆向工程概述
1.1 数据库逆向工程的定义
数据库逆向工程是将现有的数据库结构、数据内容和应用逻辑转换成高级模型的过程。简单地说,就是通过分析数据库的物理结构和数据来重建其概念模型或逻辑模型。
1.2 数据库逆向工程的必要性
在软件开发和数据库管理过程中,逆向工程有助于理解旧系统的结构,是数据迁移、系统重构、维护历史数据和迁移至新平台的关键步骤。它能够显著提高开发效率,降低项目风险。
1.3 数据库逆向工程的应用场景
它在多种场景中广泛应用,包括但不限于遗留系统的现代化、不同数据库之间的数据迁移、以及在系统维护和升级过程中对数据结构的理解。
逆向工程不仅帮助开发者快速掌握复杂系统的数据库结构,还能为新系统的构建提供参考模型。不过,逆向工程也存在一定的挑战,如模型的准确性、复杂关系的解析、以及保持逆向工程过程的自动化和高效性。
在下一章中,我们将详细介绍数据库设计理论、逆向工程概念以及逆向工程流程。这些理论基础是掌握数据库逆向工程的基石。
2. 理论基础
2.1 数据库设计理论
2.1.1 数据库范式
数据库范式化是数据库设计中的一个核心概念,它是一组规则和指导方针,用于组织数据库表的结构,以减少数据冗余并提高数据的一致性。范式理论从低到高包括第一范式(1NF)、第二范式(2NF)、第三范式(3NF),以及更高级别的BCNF(巴克斯-科德范式)、第四范式(4NF)和第五范式(5NF)等。
- **第一范式(1NF)**要求一个表中的所有字段值都是不可分割的最小数据单元,且每个字段只包含原子值。也就是说,每个表的每个列都是不可再分的数据项。
- **第二范式(2NF)**在1NF的基础上,要求表中的所有非主键字段必须完全依赖于主键。如果主键由多个字段组成,那么非主键字段必须依赖于整个主键,而不是主键的一部分,以消除部分依赖。
- **第三范式(3NF)**要求非主键字段只依赖于主键,而不是依赖于其他非主键字段。这有助于消除传递依赖,其中非主键字段依赖于另一个非主键字段,后者又依赖于主键。
2.1.2 实体关系模型(ER模型)
实体关系模型是一种用于描述现实世界信息的数据模型。在ER模型中,数据被组织成实体、属性和关系。实体通常映射为数据库中的表,而实体的属性映射为表中的列。关系描述了实体间的关联,可以是一对一(1:1)、一对多(1:N)或多对多(M:N)的关系。
ER模型的三个主要组成部分是:
- 实体:现实世界中可以区分的事物或对象,比如员工、部门等。
- 属性:描述实体的特征,每个属性都有其数据类型,例如员工的名字和ID。
- 关系:实体之间的联系,定义了实体间的逻辑联系和约束。
2.2 逆向工程概念
2.2.1 逆向工程定义
逆向工程是一种分析工程过程,通过观察产品来推断产品的设计和实现方式。在数据库领域,逆向工程通常涉及分析现有的数据库系统,以理解和重建其结构、功能或组织结构。它可以通过程序代码、数据库架构、用户接口等来执行。
2.2.2 数据库逆向工程的目标与意义
数据库逆向工程的目标是自动或半自动地从现有的数据库系统中提取信息,生成清晰、结构化的逻辑模型。通过这一过程,可以创建数据库的文档化,有助于理解现有系统的结构,为系统维护、迁移、重构或集成提供支持。
逆向工程的意义在于:
- 提高可维护性:通过文档化现有数据库,开发者能更快理解系统架构,减少维护成本。
- 系统迁移:逆向工程有助于迁移数据到新的数据库管理系统。
- 性能优化:分析现有数据库的结构可以帮助发现性能瓶颈,并进行优化。
- 数据迁移与整合:逆向工程使得数据从一个数据库转移到另一个数据库变得可行,这在合并多个数据源时尤为重要。
2.3 逆向工程流程
2.3.1 数据库结构的识别与分析
逆向工程的第一步是对现有数据库结构进行识别和分析。这包括理解表结构、数据类型、索引、约束和存储过程等数据库对象。通常这一步是自动化工具协助完成的,例如通过查询数据字典,解析数据库元数据来获得这些信息。
2.3.2 ER图的自动生成技术
自动化工具可以使用提取的数据来生成实体关系图(ER图)。ER图是数据库设计的关键部分,它可以直观地展示实体间的关联和表间的关系。自动生成ER图的过程包括:
- 识别实体:通过表名和主键识别实体。
- 定义关系:通过外键约束和表间的连接来定义实体之间的关系。
- 属性映射:将表的列映射为实体的属性。
- 确定主键和外键:明确实体的标识符和与其他实体的关联键。
生成ER图的技术不断演进,目前已有的工具能够直接从数据库中提取元数据并迅速生成ER图,一些高级工具甚至允许用户在生成的ER图上进行直接编辑,并同步更新数据库结构。这大大简化了数据库文档化和维护过程。
接下来的章节将探讨在逆向工程的实践中,如何选择合适的工具,连接数据库,提取信息,并生成和优化ER图。
3. 逆向工程实践操作
3.1 工具选择与安装
在开始逆向工程之前,选择合适的工具是至关重要的一步。本章节将介绍如何选择和安装适合的逆向工程工具,包括开源工具和商业工具的比较,以及安装和配置的步骤。
3.1.1 开源工具与商业工具比较
开源工具通常具备灵活性高、成本低的优点,但可能需要用户具备较高的技术能力,并且在一些情况下可能缺乏足够的技术支持。商业工具则相反,它们提供丰富的功能和专业的客户支持,但成本相对较高。
开源工具例子包括 dbForge Studio、SQL

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CAXA电子图版尺寸标注属性编辑:7大常见问题的快速解决之道
医疗设备安全性确认:ISO 80601-2-67:2020验证与确认关键步骤
【轮播图的SEO优化】:提高搜索引擎排名的7大技巧
并发编程挑战:C++线程同步与死锁问题的解决之道
ABB RVC编程入门:为定制化应用打下基础
Flus模型模拟软件性能优化:5大关键技巧立竿见影提升模拟效率
【ST7701S显示技术在物联网应用案例】:深入分析与实践指南
【处理器设计核心课程】:哈尔滨工业大学计算机实践课深度剖析
【STM32编程精进】:深入烟雾探测器集成与数据加密技术
【模拟验证的完整流程】:MCNP教程带你从实验到验证


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )










