数据存储与管理:使用数据库存储爬取数据
发布时间: 2023-12-18 23:15:49 阅读量: 36 订阅数: 27 
# 第一章:数据爬取简介
## 1.1 数据爬取的概念和应用
数据爬取(Web scraping)指的是通过程序从网页中提取信息的自动化过程。它在各个领域都有广泛的应用,如市场调研、舆情监控、数据分析等。通过数据爬取,可以获取海量的数据并进行后续的处理和分析。
```python
# 示例代码
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 提取网页中的信息并进行处理
```
数据爬取的挑战在于网页结构多变、反爬手段多样,需要不断应对各种挑战。
## 1.2 数据爬取的挑战和需求
数据爬取面临着网站反爬虫机制、数据质量保证、数据更新频率等挑战。用户对于数据的实时性、准确性和全面性也有着不同的需求。
```java
// 示例代码
HttpClient httpClient = HttpClientBuilder.create().build();
HttpGet request = new HttpGet("http://example.com");
HttpResponse response = httpClient.execute(request);
// 解析并处理返回的数据
```
## 1.3 数据爬取技术的发展与趋势
随着人工智能、大数据等技术的发展,数据爬取技术也在不断演进。例如,基于机器学习的智能爬虫、使用分布式系统进行大规模数据爬取等,都是当前的发展趋势。
```javascript
// 示例代码
fetch('http://example.com')
.then(response => response.text())
.then(data => {
// 对数据进行处理
});
```
数据爬取技术的发展趋势将更加注重数据隐私保护、智能化、自动化等方向。
## 第二章:数据库存储概述
在数据爬取过程中,选择合适的数据库作为数据存储介质至关重要。本章将介绍数据库存储的基本概念、各类数据库的特点和适用场景,以及数据库在数据存储与管理中的作用。让我们一起来深入了解数据库存储相关的知识。
### 第三章:选择合适的数据库
在进行数据爬取后,选择合适的数据库作为数据的存储介质至关重要。本章将讨论如何选择合适的数据库,包括关系型数据库与非关系型数据库的选择、数据库性能、扩展性和容量考量,以及数据库安全性与备份策略。
#### 3.1 关系型数据库与非关系型数据库的选择
在选择数据库时,首先需要考虑的是数据的结构和需求。关系型数据库(如MySQL、PostgreSQL)适用于具有固定结构和关联性强的数据存储,可以保证数据的一致性和完整性。非关系型数据库(如MongoDB、Redis)则更适合于无固定模式和需要高度扩展性的数据存储。
##### 示例代码(Python):
```python
# 使用关系型数据库MySQL存储爬取的数据
import mysql.connector
# 连接数据库
db = mysql.connector.connect(
host="localhost",
user="username",
password="password",
database="mydatabase"
)
# 创建数据表
cursor = db.cursor()
cursor.execute("CREATE TABLE products (id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(255), price DECIMAL(10, 2))")
# 插入数据
sql = "INSERT INTO products (name, price) VALUES (%s, %s)"
val = ("Computer", 1000)
cursor.execute(sql, val)
# 提交更改
db.commit()
```
代码总结:以上示例演示了使用Python的mysql.connector库连接MySQL数据库,并创建数据表以及插入数据的过程。
结果说明:通过以上代码,我们可以利用关系型数据库MySQL存储爬取的数据,并执行数据的插入操作。
#### 3.2 数据库性能、扩展性和容量考量
除了数据的类型和结构外,还需要考虑数据库的性能、扩展性和容量。关系型数据库通常具有较高的一致性和完整性,但在面对大规模数据和高并发访问时,可能性能受限。非关系型数据库则可以水平扩展,适合大数据量和高并发访问场景。
##### 示例代码(Java):
```java
// 使用非关系型数据库MongoDB存储爬取的数据
import org.bson.Document;
import com.mongodb.client.MongoClient;
import com.mongodb.client.MongoClients;
import com.mongodb.client.MongoCollection;
import com.mongodb.client.MongoDatabase;
public class MongoDBExample {
public static void main(String[] args) {
// 连接MongoDB
MongoClient mongoClient = MongoClients.create("mongodb://localhost:27017");
// 选择数据库和集合
MongoDatabase database = mongoClient.getDatabase("mydb");
MongoCollection<Document> collection = database.getCollection("products");
// 插入文档
Document doc = new Document("name", "Keyboard").append("price", 50);
collection.insertOne(doc);
}
}
```
代码总结:以上示例使用Java连接MongoDB,选择数据库和集合并插入文档,实现了使用非关系型

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏以"爬虫开发基础"为主题,通过一系列文章,将帮助读者系统地掌握Python爬虫的基本技术和进阶知识。内容包括使用Requests库发起HTTP请求,利用Beautiful Soup解析HTML和XML,深入理解Scrapy框架等。此外,您还将学习到爬虫中常见的问题及解决方案,遇到的反爬机制及应对策略,以及如何将爬虫数据进行存储、清洗、可视化和分析。此外,专栏还介绍了如何提高爬虫性能、如何防护爬虫安全等相关主题。通过学习本专栏,您将能够对Python爬虫技术有一个全面的了解,并能够将其应用于实际项目中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
微机接口技术深度解析:串并行通信原理与实战应用
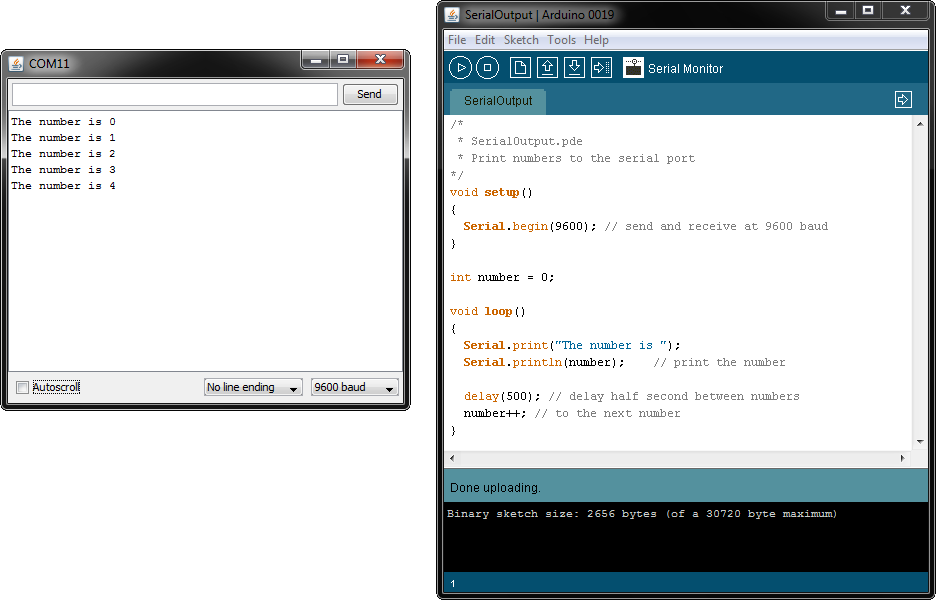
# 摘要
微机接口技术是计算机系统中不可或缺的部分,涵盖了从基础通信理论到实际应用的广泛内容。本文旨在提供微机接口技术的全面概述,并着重分析串行和并行通信的基本原理与应用,包括它们的工作机制、标准协议及接口技术。通过实例介绍微机接口编程的基础知识、项目实践以及在实际应用中的问题解决方法。本文还探讨了接口技术的新兴趋势、安全性和兼容
【进位链技术大剖析】:16位加法器进位处理的全面解析
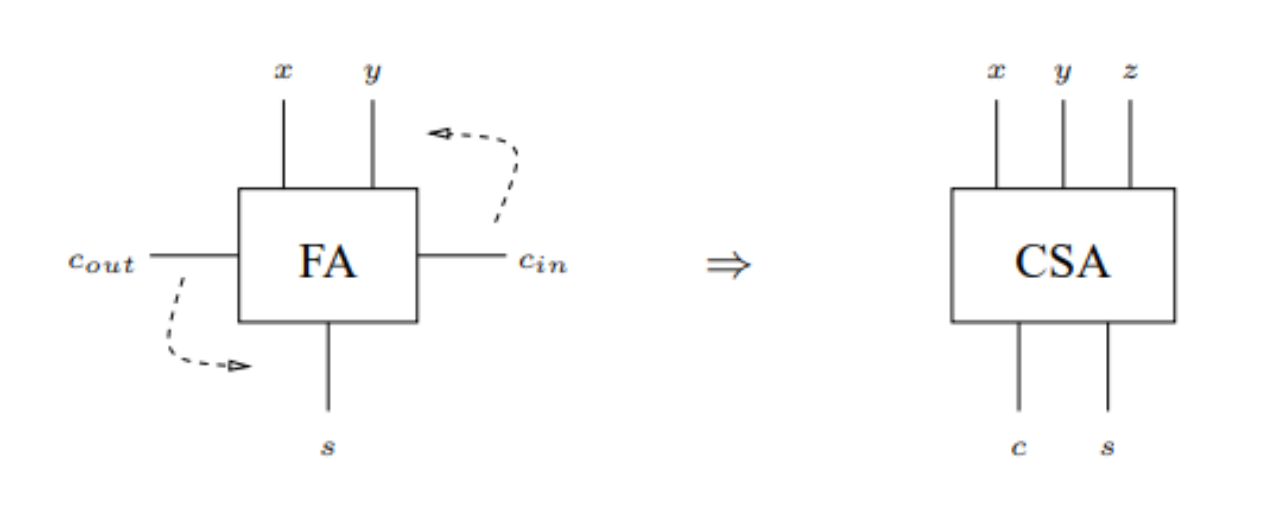
# 摘要
进位链技术是数字电路设计中的基础,尤其在加法器设计中具有重要的作用。本文从进位链技术的基础知识和重要性入手,深入探讨了二进制加法的基本规则以及16位数据表示和加法的实现。文章详细分析了16位加法器的工作原理,包括全加器和半加器的结构,进位链的设计及其对性能的影响,并介绍了进位链优化技术。通过实践案例,本文展示了进位链技术在故障诊断与维护中的应用,并探讨了其在多位加法器设计以及多处理器系统中的高级应用。最后,文章展望了进位链技术的未来,
【均匀线阵方向图秘籍】:20个参数调整最佳实践指南
# 摘要
均匀线阵方向图是无线通信和雷达系统中的核心技术之一,其设计和优化对系统的性能至关重要。本文系统性地介绍了均匀线阵方向图的基础知识,理论基础,实践技巧以及优化工具与方法。通过理论与实际案例的结合,分析了线阵的基本概念、方向图特性、理论参数及其影响因素,并提出了方向图参数调整的多种实践技巧。同时,本文探讨了仿真软件和实验测量在方向图优化中的应用,并介绍了最新的优化算法工具。最后,展望了均匀线阵方向图技术的发展趋势,包括新型材料和技术的应用、智能化自适应方向图的研究,以及面临的技术挑战与潜在解决方案。
# 关键字
均匀线阵;方向图特性;参数调整;仿真软件;优化算法;技术挑战
参考资源链
ISA88.01批量控制:制药行业的实施案例与成功经验

# 摘要
ISA88.01标准为批量控制系统提供了框架和指导原则,尤其是在制药行业中,其应用能够显著提升生产效率和产品质量控制。本文详细解析了ISA88.01标准的概念及其在制药工艺中的重要
实现MVC标准化:肌电信号处理的5大关键步骤与必备工具

# 摘要
本文探讨了MVC标准化在肌电信号处理中的关键作用,涵盖了从基础理论到实践应用的多个方面。首先,文章介绍了
【FPGA性能暴涨秘籍】:数据传输优化的实用技巧
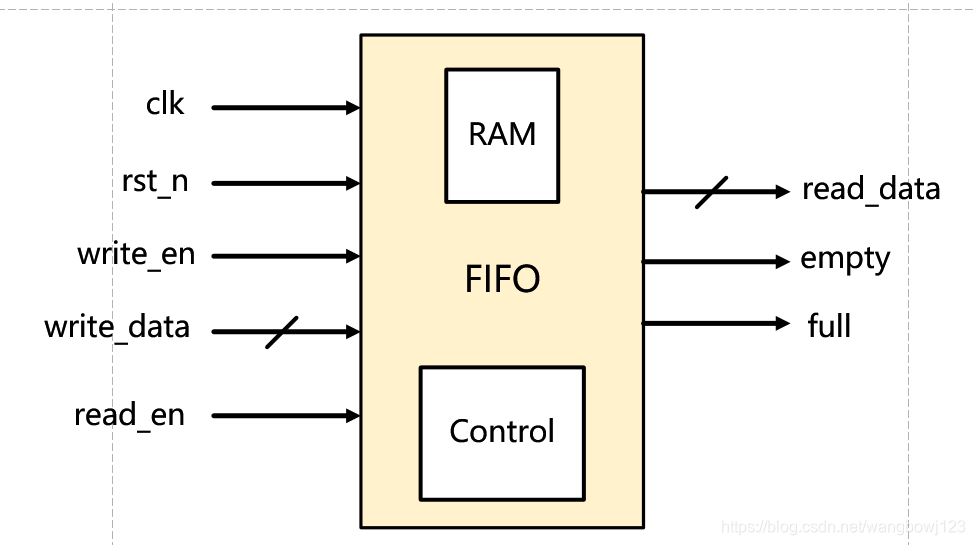
# 摘要
本文全面介绍了FPGA在数据传输领域的应用和优化技巧。首先,对FPGA和数据传输的基本概念进行了介绍,然后深入探讨了FPGA内部数据流的理论基础,包
PCI Express 5.0性能深度揭秘:关键指标解读与实战数据分析

# 摘要
PCI Express(PCIe)技术作为计算机总线标准,不断演进以满足高速数据传输的需求。本文首先概述PCIe技术,随后深入探讨PCI Express 5.0的关键技术指标,如信号传输速度、编码机制、带宽和吞吐量的理论极限以及兼容性问题。通过实战数据分析,评估PCI Express
CMW100 WLAN指令手册深度解析:基础使用指南揭秘
# 摘要
CMW100 WLAN指令是业界广泛使用的无线网络测试和分析工具,为研究者和工程师提供了强大的网络诊断和性能评估能力。本文旨在详细介绍CMW100 WLAN指令的基础理论、操作指南以及在不同领域的应用实例。首先,文章从工作原理和系统架构两个层面探讨了CMW100 WLAN指令的基本理论,并解释了相关网络协议。随后,提供了详细的操作指南,包括配置、调试、优化及故障排除方法。接着,本文探讨了CMW100 WLAN指令在网络安全、网络优化和物联网等领域的实际应用。最后,对CMW100 WLAN指令的进阶应用和未来技术趋势进行了展望,探讨了自动化测试和大数据分析中的潜在应用。本文为读者提供了
三菱FX3U PLC与HMI交互:打造直觉操作界面的秘籍

# 摘要
本论文详细介绍了三菱FX3U PLC与HMI的基本概念、工作原理及高级功能,并深入探讨了HMI操作界面的设计原则和高级交互功能。通过对三菱FX3U PLC的编程基础与高级功能的分析,本文提供了一系列软件集成、硬件配置和系统测试的实践案例,以及相应的故障排除方法。此外,本文还分享了在不同行业应用中的案例研究,并对可能出现的常见问题提出了具体的解决策略。最后,展望了新兴技术对PLC和HMI
【透明度问题不再难】:揭秘Canvas转Base64时透明度保持的关键技术

# 摘要
本文旨在全面介绍Canvas转Base64编码技术,从基础概念到实际应用,再到优化策略和未来趋势。首先,我们探讨了Canvas的基本概念、应用场景及其重要性,紧接着解析了Base64编码原理,并重点讨论了透明度在Canvas转Base64过程中的关键作用。实践方法章节通过标准流程和技术细节的讲解,提供了透明度保持的有效编码技巧和案例分析。高级技术部分则着重于性能优化、浏览器兼容性问题以及Ca
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )