Kafka与大数据生态系统集成技术探究
发布时间: 2024-02-24 16:00:59 阅读量: 44 订阅数: 33 

java全大撒大撒大苏打
# 1. Kafka简介与基本概念
## 1.1 Kafka的作用和原理
Kafka是一个开源的分布式流处理平台,最初由LinkedIn开发,后成为Apache的顶级项目。其主要作用是提供高吞吐量的数据汇总、存储和传输服务。Kafka基于发布/订阅模式,通过Topic(主题)将消息发布到多个订阅者,实现了解耦和高效数据传输。
Kafka的核心原理包括消息持久化、分布式架构和水平扩展等。消息以分区的方式存储在Kafka的Broker节点上,每个分区都可以复制到多个Broker,以实现容错和高可用性。生产者将消息发布到Topic,而消费者则可以订阅Topic并实时消费消息。
## 1.2 Kafka的主要特点
- **高吞吐量**:Kafka能够处理大规模数据并实现高吞吐量的消息传输。
- **水平扩展**:通过增加Broker节点或分区数量,Kafka能够轻松水平扩展以处理更多的数据。
- **持久化**:Kafka能够持久化存储消息,即使消息被消费,仍然可以在Broker上进行保留,支持数据的回溯和重放。
- **低延迟**:Kafka能够在毫秒级别内实现消息的传输和消费。
- **分布式和可靠性**:Kafka的分布式架构保证了系统的可靠性和容错性。
## 1.3 Kafka与消息队列的区别与联系
Kafka与传统消息队列的最大区别在于其持久化特性和分布式架构。Kafka不同于传统消息队列,如RabbitMQ或ActiveMQ,它的设计目标更倾向于分布式的流处理,更适合大规模数据的实时处理和传输。同时,Kafka也能够作为消息队列进行使用,提供了类似于传统消息队列的功能,如保证消息顺序性和至少一次交付保证。
# 2. Kafka与Hadoop集成
Apache Kafka和Hadoop是两个流行的大数据工具,它们的集成为数据传输和处理提供了很多优势。在本章中,我们将深入探讨Kafka与Hadoop的集成,包括集成方式、优势以及Kafka Connect与Hadoop生态系统的整合。
### 2.1 Kafka与HDFS的集成
Kafka可以与Hadoop分布式文件系统(HDFS)集成,实现高吞吐量的数据传输和持久化存储。通过Kafka的Producer将数据发送到Kafka集群,并利用Kafka Connect将数据从Kafka主题传输到HDFS中进行保存。以下是一个简单的Python示例,演示如何将数据从Producer发送到Kafka集群,并通过Kafka Connect将数据传输到HDFS。
```python
from kafka import KafkaProducer
from kafka import KafkaConsumer
import json
# 连接Kafka集群
producer = KafkaProducer(bootstrap_servers='localhost:9092',
value_serializer=lambda v: json.dumps(v).encode('utf-8'))
# 发送数据到Kafka主题
producer.send('hadoop_topic', {'data': 'example_data'})
# 从Kafka消费数据
consumer = KafkaConsumer('hadoop_topic', bootstrap_servers='localhost:9092',
value_deserializer=lambda m: json.loads(m.decode('utf-8')))
for message in consumer:
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
```
### 2.2 使用Kafka作为Hadoop数据传输的优势
- **高吞吐量**: Kafka的分布式架构和横向扩展能力使其能够处理大规模数据,并提供高吞吐量的数据传输和存储。
- **持久化存储**: Kafka的主题可以配置为保留数据,结合HDFS的文件持久化存储,确保数据不会丢失。
- **实时数据传输**: Kafka能够实现实时数据的传输,与Hadoop生态系统中的实时数据处理工具(如Spark Streaming和Flink)结合,实现实时数据处理和分析。
### 2.3 Kafka Connect与Hadoop生态系统的整合
Kafka Connect是一个可伸缩且可靠的工具,可用于管道化和数据传输。它提供了许多连接器,用于将Kafka与Hadoop生态系统的各种组件集成。结合Kafka Connect,可以轻松地将Kafka与Hadoop生态系统(包括HDFS、Hive、HBase等)进行集成,实现数据的高效传输和处理。
综上所述,Kafka与Hadoop的集成为大数据处理提供了高性能、实时性和可靠性的优势,使得数据传输和存储变得更加高效。
# 3. Kafka与Spark集成
Apache Spark是一个快速、通用的大数据处理引擎,可以与Kafka集成以进行实时数据处理和分析。本章将重点介绍如何将Kafka与Spark进行集成,包括将Kafka作为数据源提供给Spark Streaming,以及实时数据处理案例和最佳实践。
#### 3.1 利用Kafka提供数据给Spark Streaming
在实现Kafka与Spark Streaming集成之前,需要确保已经安装配置好Kafka和Spark环境。接下来,我们将演示如何使用Python代码从Kafka主题中读取数据,并将其传送给Spark Streaming进行处理。
```python
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
sc = SparkContext(appName="KafkaSparkIntegration")
ssc = StreamingContext(sc, 5)
kafkaParams = {"metadata.broker.list": "localhost:9092"}
topics = ["topic1"]
kafkaStream = KafkaUtils.createDirectStream(ssc, topics, kafkaParams)
lines = kafkaStream.map(lambda x: x[1])
counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(l
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探索Apache Kafka消息队列的各个方面,从简介及基本概念解析到消息生产与消费机制,再到消息持久性、复制机制以及分区机制、数据分发策略的详细讲解。我们将介绍如何使用Apache Kafka Consumer API接收消息,理解Kafka中的Offset和Consumer Group,以及消息队列的可靠性保证机制。此外,我们还会探讨Kafka Streams流处理框架的入门指南,监控和管理Kafka集群的方法,性能调优与优化策略,以及与大数据生态系统集成技术。最后,我们将揭示Kafka在实时数据处理中的关键角色,为您全面理解和应用Apache Kafka提供有力支持。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32F030C8T6专攻:最小系统扩展与高效通信策略
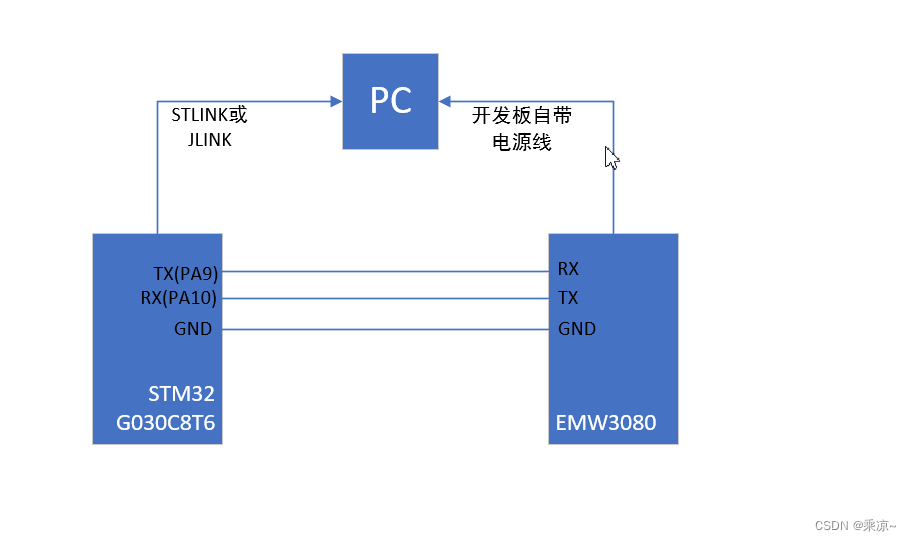
# 摘要
本文首先介绍了STM32F030C8T6微控制器的基础知识和最小系统设计的要点,涵盖硬件设计、软件配置及最小系统扩展应用案例。接着深入探讨了高效通信技术,包括不同通信协议的使用和通信策略的优化。最后,文章通过项目管理与系统集成的实践案例,展示了如何在实际项目中应用这些技术和知识,进行项目规划、系统集成、测试及故障排除,以提高系统的可靠性和效率。
# 关键字
STM32F030C8T6;
【PyCharm专家教程】:如何在PyCharm中实现Excel自动化脚本

# 摘要
本文旨在全面介绍PyCharm集成开发环境以及其在Excel自动化处理中的应用。文章首先概述了PyCharm的基本功能和Python环境配置,进而深入探讨了Python语言基础和PyCharm高级特性。接着,本文详细介绍了Excel自动化操作的基础知识,并着重分析了openpyxl和Pandas两个Python库在自动化任务中的运用。第四章通过实践案
ARM处理器时钟管理精要:工作模式协同策略解析

# 摘要
本文系统性地探讨了ARM处理器的时钟管理基础及其工作模式,包括处理器运行模式、异常模式以及模式间的协同关系。文章深入分析了时钟系统架构、动态电源管理技术(DPM)及协同策略,揭示了时钟管理在提高处理器性能和降低功耗方面的重要性。同时,通过实践应用案例的分析,本文展示了基于ARM的嵌入式系统时钟优化策略及其效果评估,并讨论了时钟管理常见问题的
【提升VMware性能】:虚拟机高级技巧全解析
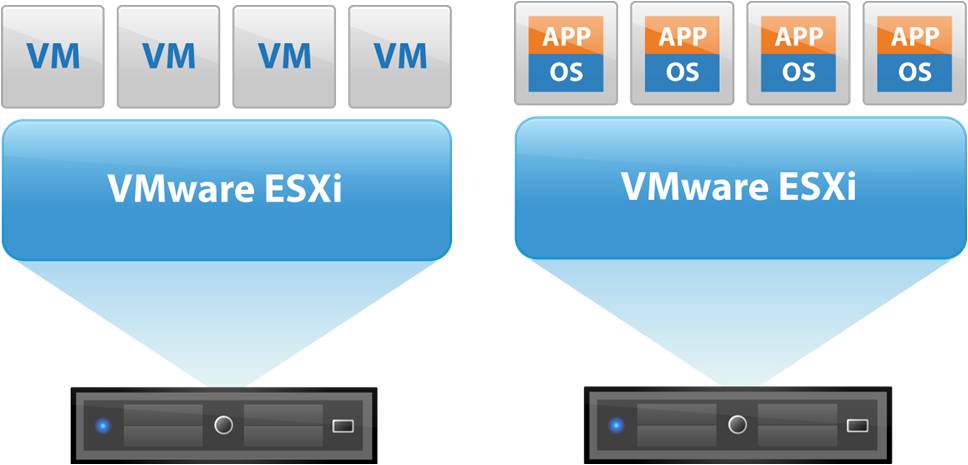
# 摘要
随着虚拟化技术的广泛应用,VMware作为市场主流的虚拟化平台,其性能优化问题备受关注。本文综合探讨了VMware在虚拟硬件配置、网络性能、系统和应用层面以及高可用性和故障转移等方面的优化策略。通过分析CPU资源分配、内存管理、磁盘I/O调整、网络配置和操作系统调优等关键技术点,本文旨在提供一套全面的性能提升方案。此外,文章还介绍了性能监控和分析工具的运用,帮助用户及时发
【CEQW2数据分析艺术】:生成报告与深入挖掘数据洞察
# 摘要
本文全面探讨了数据分析的艺术和技术,从报告生成的基础知识到深入的数据挖掘方法,再到数据分析工具的实际应用和未来趋势。第一章概述了数据分析的重要性,第二章详细介绍了数据报告的设计和高级技术,包括报告类型选择、数据可视化和自动化报告生成。第三章深入探讨了数据分析的方法论,涵盖数据清洗、统计分析和数据挖掘技术。第四章探讨了关联规则、聚类分析和时间序列分析等更高级的数据洞察技术。第五章将
UX设计黄金法则:打造直觉式移动界面的三大核心策略

# 摘要
随着智能移动设备的普及,直觉式移动界面设计成为提升用户体验的关键。本文首先概述移动界面设计,随后深入探讨直觉式设计的理论基础,包括用户体验设计简史、核心设计原则及心理学应用。接着,本文提出打造直觉式移动界面的实践策略,涉及布局、导航、交互元素以及内容呈现的直觉化设计。通过案例分析,文中进一步探讨了直觉式交互设计的成功与失败案例,为设
数字逻辑综合题技巧大公开:第五版习题解答与策略指南

# 摘要
本文旨在回顾数字逻辑基础知识,并详细探讨综合题的解题策略。文章首先分析了理解题干信息的方法,包括题目要求的分析与题型的确定,随后阐述了数字逻辑基础理论的应用,如逻辑运算简化和时序电路分析,并利用图表和波形图辅助解题。第三章通过分类讨论典型题目,逐步分析了解题步骤,并提供了实战演练和案例分析。第四章着重介绍了提高解题效率的技巧和避免常见错误的策略。最后,第五章提供了核心习题的解析和解题参考,旨在帮助读者巩固学习成果并提供额外的习题资源。整体而言,本文为数字逻辑
Zkteco智慧云服务与备份ZKTime5.0:数据安全与连续性的保障
# 摘要
本文全面介绍了Zkteco智慧云服务的系统架构、数据安全机制、云备份解决方案、故障恢复策略以及未来发展趋势。首先,概述了Zkteco智慧云服务的概况和ZKTime5.0系统架构的主要特点,包括核心组件和服务、数据流向及处理机制。接着,深入分析了Zkteco智慧云服务的数据安全机制,重点介绍了加密技术和访问控制方法。进一步,本文探讨了Zkteco云备份解决方案,包括备份策略、数据冗余及云备份服务的实现与优化。第五章讨论了故障恢复与数据连续性保证的方法和策略。最后,展望了Zkteco智慧云服务的未来,提出了智能化、自动化的发展方向以及面临的挑战和应对策略。
# 关键字
智慧云服务;系统
Java安全策略高级优化技巧:local_policy.jar与US_export_policy.jar的性能与安全提升

# 摘要
Java安全模型是Java平台中确保应用程序安全运行的核心机制。本文对Java安全模型进行了全面概述,并深入探讨了安全策略文件的结构、作用以及配置过程。针对性能优化,本文提出了一系列优化技巧和策略文件编写建议,以减少不必要的权限声明,并提高性能。同时,本文还探讨了Java安全策略的安全加固方法,强调了对local_po
海康二次开发实战攻略:打造定制化监控解决方案

# 摘要
海康监控系统作为领先的视频监控产品,其二次开发能力是定制化解决方案的关键。本文从海康监控系统的基本概述与二次开发的基础讲起,深入探讨了SDK与API的架构、组件、使用方法及其功能模块的实现原理。接着,文中详细介绍了二次开发实践,包括实时视频流的获取与处理、录像文件的管理与回放以及报警与事件的管理。此外,本文还探讨了如何通过高级功能定制实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )