高级语言程序设计(Python)- 列表操作和操作符
发布时间: 2024-01-25 22:36:27 阅读量: 47 订阅数: 46 
# 1. Python列表概述
## 1.1 什么是Python列表
Python中的列表(List)是一种有序、可变、可以包含任意数据类型的集合。列表通过方括号`[]`来表示,其中的元素用逗号分隔。
## 1.2 列表的特点和优势
- **有序性**:列表中的元素是有序排列的,可以通过索引访问。
- **可变性**:列表中的元素可以随时添加、删除或修改。
- **灵活性**:列表中可以包含不同类型的元素。
- **功能丰富**:Python提供了丰富的列表操作方法,方便对列表进行操作和处理。
## 1.3 列表的基本操作
- 创建列表:通过方括号`[]`来创建一个空列表或包含初始元素的列表。
- 访问元素:使用索引来访问列表中的元素。
- 修改元素:可以通过索引对列表中的元素进行修改。
- 删除元素:可以通过索引或特定方法删除列表中的元素。
以上是Python列表的基本概述和操作,接下来我们将深入了解列表的操作符。
# 2. 列表的操作符
列表操作符是用来对列表进行操作的常用工具。下面分别介绍列表的连接和重复、比较以及成员关系操作符。
### 2.1 列表的连接和重复
#### 列表的连接
列表的连接是指将两个或多个列表合并成一个新的列表。可以使用加号(+)运算符将列表连接起来。示例如下:
```python
list1 = [1, 2, 3]
list2 = [4, 5, 6]
list3 = list1 + list2
print(list3) # 输出:[1, 2, 3, 4, 5, 6]
```
#### 列表的重复
列表的重复指的是将一个列表的元素重复多次,形成一个新的列表。可以使用乘号(*)运算符进行列表的重复操作。示例如下:
```python
list1 = [1, 2, 3]
list2 = list1 * 3
print(list2) # 输出:[1, 2, 3, 1, 2, 3, 1, 2, 3]
```
### 2.2 列表的比较
列表的比较操作可以用来比较两个列表的大小关系,主要有以下几种比较运算符:
- 等于(==):判断两个列表是否相等;
- 不等于(!=):判断两个列表是否不相等;
- 大于(>):判断一个列表是否大于另一个列表;
- 小于(<):判断一个列表是否小于另一个列表;
- 大于等于(>=):判断一个列表是否大于等于另一个列表;
- 小于等于(<=):判断一个列表是否小于等于另一个列表。
示例如下:
```python
list1 = [1, 2, 3]
list2 = [1, 2, 3]
list3 = [4, 5, 6]
print(list1 == list2) # 输出:True
print(list1 != list3) # 输出:True
print(list1 > list3) # 输出:False
print(list1 < list3) # 输出:True
print(list1 >= list2) # 输出:True
print(list1 <= list2) # 输出:True
```
### 2.3 列表的成员关系操作符
列表的成员关系操作符用于判断一个元素是否属于列表,有以下两个操作符:
- `in`:判断元素是否在列表中;
- `not in`:判断元素是否不在列表中。
示例如下:
```python
list1 = [1, 2, 3]
print(1 in list1) # 输出:True
print(4 not in list1) # 输出:True
```
通过以上的介绍,我们了解了列表的操作符,包括列表的连接和重复、比较以及成员关系操作符的使用。在实际编程中,能够熟练应用这些操作符可以提高列表的处理效率和灵活性。
# 3. 列表的基本操作
#### 3.1 创建列表
在Python中,可以通过方括号来创建列表,例如:
```python
# 创建一个空列表
empty_list = []
# 创建一个包含整数的列表
numbers = [1, 2, 3, 4, 5]
# 创建一个包含字符串的列表
fruits = ['apple', 'banana', 'orange']
# 创建一个混合类型的列表
mixed = [1, 'hello', 3.14, True]
```
#### 3.2 添加元素
可以使用`append()`方法向列表末尾添加新元素,例如:
```python
fruits = ['apple', 'banana', 'orange']
fruits.append('grape')
print(fruits) # ['apple', 'banana', 'orange', 'grape']
```
也可以使用`insert()`方法在指定位置插入新元素,例如:
```python
fruits.insert(1, 'kiwi')
print(fruits) # ['apple', 'kiwi', 'banana', 'orange', 'grape']
```
#### 3.3 删除元素
使用`remove()`方法可以删除列表中的指定元素,例如:
```python
fruits.remove('banana')
print(fruits) # ['apple', 'kiwi', 'orange', 'grape']
```
另外,使用`pop()`方法可以删除指定位置的元素,并返回该元素的值,例如:
```python
popped_fruit = fruits.pop(2)
print(popped_fruit) # 'orange'
print(fruits) # ['apple', 'kiwi', 'grape']
```
以上是列表的基本操作,包括创建列表、添加元素和删除元素的常见方法。
# 4. 列表的高级操作
### 4.1 列表切片操作
列表切片操作是指通过指定索引范围来截取原列表的部分元素,得到一个新的列表。使用列表切片操作可以方便地获取或修改列表中的一部分元素。
```python
# 创建一个列表
lst = [1, 2, 3, 4, 5]
# 使用切片操作获取列表的部分元素
sub_list = lst[1:4]
print(sub_list) # 输出:[2, 3, 4]
# 使用切片操作修改列表的部分元素
lst[2:4] = [6, 7]
print(lst) # 输出:[1, 2, 6, 7, 5]
```
代码解析:
- 第1行:创建一个包含5个元素的列表。
- 第4行:使用切片操作获取索引1到索引4之间的元素,生成一个新的子列表。
- 第6行:输出子列表。
- 第9行:使用切片操作修改索引2到索引4之间的元素。
- 第11行:输出修改后的列表。
### 4.2 列表的迭代
迭代是指遍历一个可迭代对象的所有元素,对每个元素进行相应的操作。在Python中,可以使用for循环来迭代列表中的元素。
```python
# 创建一个列表
lst = [1, 2, 3, 4, 5]
# 使用for循环迭代列表中的元素
for num in lst:
print(num)
# 输出:
# 1
# 2
# 3
# 4
# 5
```
代码解析:
- 第1行:创建一个包含5个元素的列表。
- 第4行:使用for循环迭代列表中的元素,对每个元素进行操作。
- 第5行:打印每个元素。
### 4.3 列表解析
列表解析是一种快速创建列表的方法,它通过简洁的语法将一个可迭代对象转换为一个新的列表。
```python
# 创建一个列表
nums = [1, 2, 3, 4, 5]
# 使用列表解析创建新列表
squared_nums = [x * x for x in nums]
print(squared_nums) # 输出:[1, 4, 9, 16, 25]
```
代码解析:
- 第1行:创建一个包含5个元素的列表。
- 第4行:使用列表解析将原列表中的每个元素进行平方操作,并生成一个新的列表。
- 第6行:输出新的列表。
通过列表切片操作、列表迭代和列表解析,我们可以方便地对列表进行高级操作,实现更加灵活和高效的编程。
# 5. 列表的常见方法
列表是Python中最常用的数据结构之一,具有丰富的内置方法,可以方便地对列表进行排序、反转和拷贝等操作。本章将介绍列表的常见方法,包括列表的排序、反转和拷贝操作。
#### 5.1 列表的排序
在实际应用中,经常需要对列表进行排序操作,Python提供了多种方法来对列表进行排序。
```python
# 使用sort()方法对列表进行原地排序
fruits = ['apple', 'banana', 'orange', 'pear']
fruits.sort()
print(fruits) # 输出:['apple', 'banana', 'orange', 'pear']
# 对列表进行反向排序
fruits.sort(reverse=True)
print(fruits) # 输出:['pear', 'orange', 'banana', 'apple']
# 使用sorted()函数对列表进行排序,不改变原列表,并返回一个新的已排序列表
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
sorted_numbers = sorted(numbers)
print(sorted_numbers) # 输出:[1, 1, 2, 3, 3, 4, 5, 5, 5, 6, 9]
```
#### 5.2 列表的反转
除了排序,有时还需要对列表进行反转操作,Python提供了reverse()方法来实现列表的原地反转。
```python
# 使用reverse()方法对列表进行原地反转
vowels = ['a', 'e', 'i', 'o', 'u']
vowels.reverse()
print(vowels) # 输出:['u', 'o', 'i', 'e', 'a']
```
#### 5.3 列表的拷贝
对于列表的拷贝,有时需要创建一个列表的副本,以防止对原列表的修改影响到拷贝的列表。可以使用切片操作或者copy()方法来实现列表的拷贝。
```python
# 使用切片操作进行列表的拷贝
original_list = ['a', 'b', 'c', 'd', 'e']
copied_list = original_list[:]
original_list[0] = 'z' # 修改原列表的第一个元素
print(original_list) # 输出:['z', 'b', 'c', 'd', 'e']
print(copied_list) # 输出:['a', 'b', 'c', 'd', 'e']
```
以上是列表的常见方法,通过这些方法可以方便地对列表进行排序、反转和拷贝操作,提高了对列表数据的处理效率和灵活性。
# 6. 高级列表操作
在本章中,我们将深入讨论列表的高级操作,包括深浅拷贝、列表的内置函数以及列表的应用实例。
### 6.1 列表的深浅拷贝
在Python中,列表的复制涉及到深拷贝和浅拷贝的概念。浅拷贝创建了一个新的列表,这个新列表包含了原始列表中的元素的引用。深拷贝则是创建了一个全新的列表,并且递归地复制原始列表中的所有元素。
#### Python中的浅拷贝
```python
# 浅拷贝示例
import copy
old_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
new_list = copy.copy(old_list)
old_list[0][1] = 'two'
print(old_list) # 输出: [[1, 'two', 3], [4, 5, 6], [7, 8, 9]]
print(new_list) # 输出: [[1, 'two', 3], [4, 5, 6], [7, 8, 9]]
```
#### Python中的深拷贝
```python
# 深拷贝示例
import copy
old_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
new_list = copy.deepcopy(old_list)
old_list[0][1] = 'two'
print(old_list) # 输出: [[1, 'two', 3], [4, 5, 6], [7, 8, 9]]
print(new_list) # 输出: [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
```
### 6.2 列表的内置函数
Python的列表提供了多个内置函数,用于对列表进行操作和处理。
#### `append()`函数
```python
# append()函数示例
fruits = ['apple', 'banana', 'cherry']
fruits.append("orange")
print(fruits) # 输出: ['apple', 'banana', 'cherry', 'orange']
```
#### `extend()`函数
```python
# extend()函数示例
fruits = ['apple', 'banana']
cars = ['Ford', 'BMW', 'Volvo']
fruits.extend(cars)
print(fruits) # 输出: ['apple', 'banana', 'Ford', 'BMW', 'Volvo']
```
#### `pop()`函数
```python
# pop()函数示例
fruits = ['apple', 'banana', 'cherry']
fruits.pop()
print(fruits) # 输出: ['apple', 'banana']
```
### 6.3 列表的应用实例
列表在实际应用中具有广泛的用途,比如在数据处理、算法实现和Web开发中都扮演着重要角色。以下是一个简单的示例,展示了如何利用列表来实现一个简单的待办事项应用。
```python
# 待办事项应用示例
todo_list = []
def add_todo(item):
todo_list.append(item)
def remove_todo(item):
todo_list.remove(item)
def show_todos():
for index, item in enumerate(todo_list, start=1):
print(f"{index}. {item}")
add_todo('购买牛奶')
add_todo('写邮件给客户')
add_todo('学习Python列表操作')
show_todos()
# 输出:
# 1. 购买牛奶
# 2. 写邮件给客户
# 3. 学习Python列表操作
remove_todo('写邮件给客户')
show_todos()
# 输出:
# 1. 购买牛奶
# 2. 学习Python列表操作
```
以上是关于列表的高级操作的内容,通过学习这些内容,可以更好地运用列表来解决实际问题,提升编程效率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏“高级语言程序设计(Python)”深入探讨了Python语言的各个方面,从基础的变量和简单I_O操作开始,逐步深入讨论了选择结构和条件语句、循环结构和迭代等内容。通过编程练习和实践,读者可以系统地学习递归函数和递归算法、函数和函数参数的运用,以及字符串、列表、元组、字典和集合的操作方法。此外,专栏还介绍了文件操作和处理的技巧,并深入探讨了面向对象编程概念、类和对象的定义,以及数据库编程基础。无论是初学者还是有一定编程基础的读者,都可以通过本专栏系统地学习和掌握Python高级语言程序设计的知识和技能,从而为日后的编程实践打下坚实的基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
datasheet解读速成课:关键信息提炼技巧,提升采购效率

# 摘要
本文全面探讨了datasheet在电子组件采购过程中的作用及其重要性。通过详细介绍datasheet的结构并解析其关键信息,本文揭示了如何通过合理分析和利用datasheet来提升采购效率和产品质量。文中还探讨了如何在实际应用中通过标准采购清单、成本分析以及数据整合来有效使用datasheet信息,并通过案例分析展示了datasheet在采购决策中的具体应用。最后,本文预测了datasheet智能化处
【光电传感器应用详解】:如何用传感器引导小车精准路径

# 摘要
光电传感器在现代智能小车路径引导系统中扮演着核心角色,涉及从基础的数据采集到复杂的路径决策。本文首先介绍了光电传感器的基础知识及其工作原理,然后分析了其在小车路径引导中的理论应用,包括传感器布局、导航定位、信号处理等关键技术。接着,文章探讨了光电传感器与小车硬件的集成过程,包含硬件连接、软件编程及传感器校准。在实践部分,通过基
新手必看:ZXR10 2809交换机管理与配置实用教程
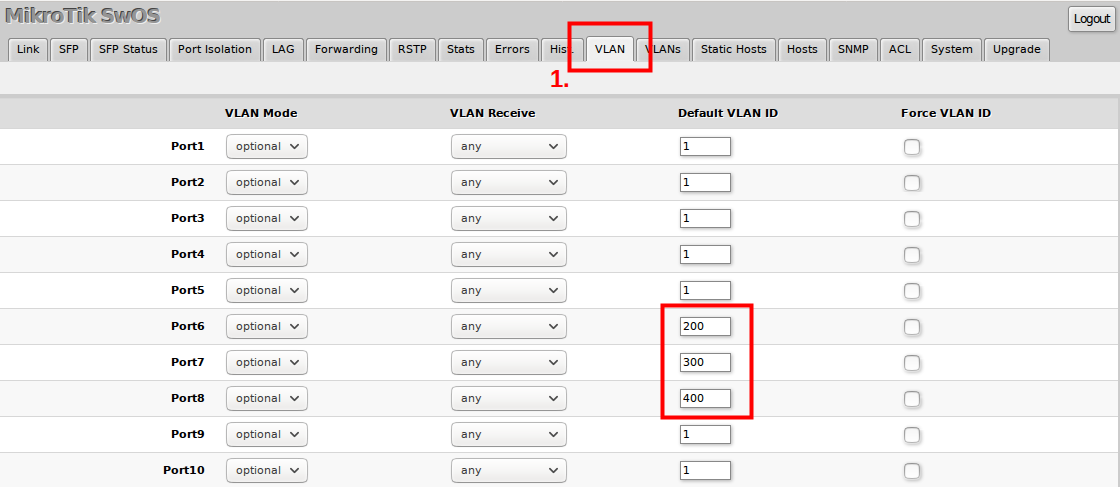
# 摘要
ZXR10 2809交换机作为网络基础设施的关键设备,其配置与管理是确保网络稳定运行的基础。本文首先对ZXR10 2809交换机进行概述,并介绍了基础管理知识。接着,详细阐述了交换机的基本配置,包括物理连接、初始化配置、登录方式以及接口的配置与管理。第三章深入探讨了网络参数的配置,VLAN的创建与应用,以及交换机的安全设置,如ACL配置和端口安全。第四章涉及高级网络功能,如路由配置、性能监控、故障排除和网络优
加密技术详解:专家级指南保护你的敏感数据
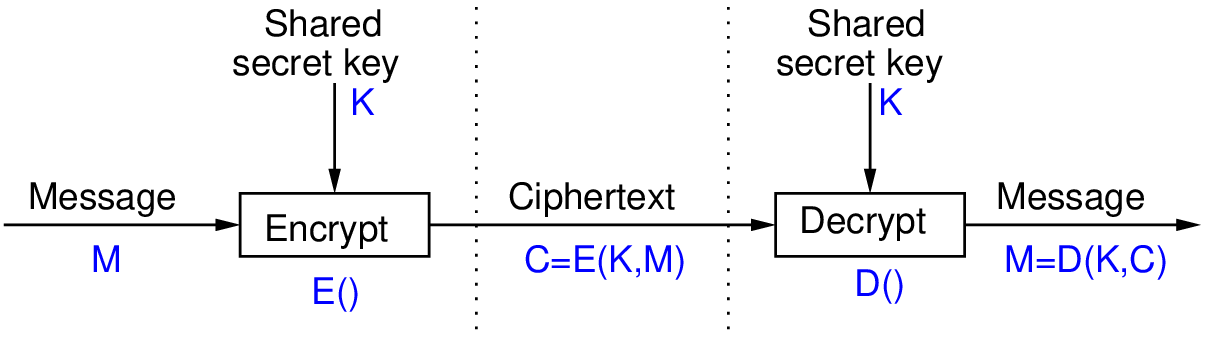
# 摘要
本文系统介绍了加密技术的基础知识,深入探讨了对称加密与非对称加密的理论和实践应用。分析了散列函数和数字签名在保证数据完整性与认证中的关键作用。进一步,本文探讨了加密技术在传输层安全协议TLS和安全套接字层SSL中的应用,以及在用户身份验证和加密策略制定中的实践。通过对企业级应用加密技术案例的分析,本文指出了实际应用中的挑战与解决方案,并讨论了相关法律和合规问题。最后,本文展望了加密技术的未来发展趋势,特别关注了量
【16串电池监测AFE选型秘籍】:关键参数一文读懂

# 摘要
本文全面介绍了电池监测AFE(模拟前端)的原理和应用,着重于其关键参数的解析和选型实践。电池监测AFE是电池管理系统中不可或缺的一部分,负责对电池的关键性能参数如电压、电流和温度进行精确测量。通过对AFE基本功能、性能指标以及电源和通信接口的分析,文章为读者提供了选择合适AFE的实用指导。在电池监测AFE的集成和应用章节中
VASPKIT全攻略:从安装到参数设置的完整流程解析

# 摘要
VASPKIT是用于材料计算的多功能软件包,它基于密度泛函理论(DFT)提供了一系列计算功能,包括能带计算、动力学性质模拟和光学性质分析等。本文系统介绍了VASPKIT的安装过程、基本功能和理论基础,同时提供了实践操作的详细指南。通过分析特定材料领域的应用案例,比如光催化、
【Exynos 4412内存管理剖析】:高速缓存策略与性能提升秘籍
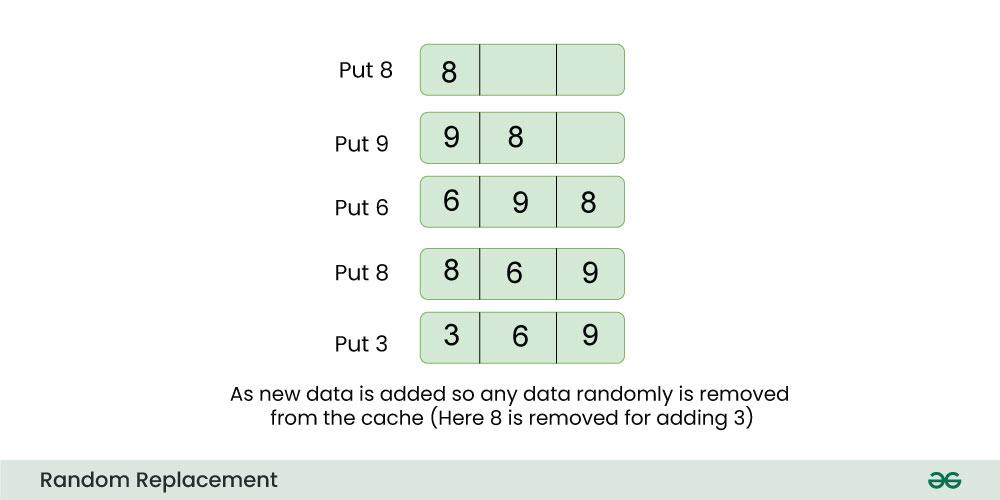
# 摘要
本文对Exynos 4412处理器的内存管理进行了全面概述,深入探讨了内存管理的基础理论、高速缓存策略、内存性能优化技巧、系统级内存管理优化以及新兴内存技术的发展趋势。文章详细分析了Exynos 4412的内存架构和内存管理单元(MMU)的功能,探讨了高速缓存架构及其对性能的影响,并提供了一系列内存管理实践技巧和性能提升秘籍。此外,
慧鱼数据备份与恢复秘籍:确保业务连续性的终极策略(权威指南)
# 摘要
本文全面探讨了数据备份与恢复的基础概念,备份策略的设计与实践,以及慧鱼备份技术的应用。通过分析备份类型、存储介质选择、备份工具以及备份与恢复策略的制定,文章提供了深入的技术见解和配置指导。同时,强调了数据恢复的重要性,探讨了数据恢复流程、策略以及慧鱼数据恢复工具的应用。此
【频谱分析与Time Gen:建立波形关系的新视角】:解锁频率世界的秘密
# 摘要
本文旨在探讨频谱分析的基础理论及Time Gen工具在该领域的应用。首先介绍频谱分析的基本概念和重要性,然后详细介绍Time Gen工具的功能和应用场景。文章进一步阐述频谱分析与Time Gen工具的理论结合,分析其在信号处理和时间序列分析中的作用。通过多个实践案例,本文展示了频谱分析与Time Gen工具相结合的高效性和实用性,并探讨了其在高级应用中的潜在方向和优势。本文为相关领域的研究人员和工程师
【微控制器编程】:零基础入门到编写你的首个AT89C516RD+程序
# 摘要
本文深入探讨了微控制器编程的基础知识和AT89C516RD+微控制器的高级应用。首先介绍了微控制器的基本概念、组成架构及其应用领域。随后,文章详细阐述了AT89C516RD+微控制器的硬件特性、引脚功能、电源和时钟管理。在软件开发环境方面,本文讲述了Keil uVision开发工具的安装和配置,以及编程语言的使用。接着,文章引导读者通过实例学习编写和调试AT89C516RD+的第一个程序,并探讨了微控制器在实践应用中的接口编程和中断驱动设计。最后,本文提供了高级编程技巧,包括实时操作系统的应用、模块集成、代码优化及安全性提升方法。整篇文章旨在为读者提供一个全面的微控制器编程学习路径,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )