Scala编程基础:了解Scala的核心概念
发布时间: 2023-12-17 04:39:03 阅读量: 48 订阅数: 42 

Scala基础编程简介.ppt
# 1. Scala简介
## 1.1 Scala的历史与发展
Scala 是一种多范式的编程语言,结合了面向对象编程和函数式编程的特性。它由Martin Odersky在2001年开发,最初被设计用于解决现有编程语言的一些问题,如Java的繁琐性和函数式编程语言的性能问题。随着时间的推移,Scala得到了广泛的应用和发展,并成为了一门被广泛采用的现代编程语言。
## 1.2 Scala与Java的关系
Scala与Java有着密切的关系。事实上,Scala是运行在Java虚拟机(JVM)上的编程语言,可以与Java无缝互操作。这意味着Scala可以调用Java的库和框架,也可以与现有的Java代码进行集成。同时,Scala还提供了对函数式编程的支持,使得编写并发和高效的代码变得更加简单。
## 1.3 Scala的优势和特点
Scala具有以下的优势和特点:
- 简洁,Scala代码相对于Java代码来说更简洁,减少样板代码的书写。
- 面向对象和函数式编程的结合,Scala既支持面向对象编程,也支持函数式编程的特性,可以更好地处理复杂的编程问题。
- 静态类型检查,Scala是一门静态类型的编程语言,可以在编译期发现大部分的错误,提高代码的健壮性和可靠性。
- 并发编程的支持,Scala提供了Actor模型和Akka框架,使得并发编程变得更加容易和安全。
- 强大的生态系统,Scala拥有丰富的第三方库和框架,可以满足各种不同领域的开发需求。
在接下来的章节中,我们将更加深入地了解Scala的基础语法、面向对象编程、函数式编程、并发编程以及实际应用案例。
# 2. Scala基础语法
### 2.1 变量与数据类型
Scala是一种静态类型的编程语言,它的变量和数据类型需要在编译时进行声明。在Scala中,变量的声明使用关键字`var`或`val`,其中`var`表示可变变量,而`val`表示不可变变量。
下面是一个简单的示例,展示了如何声明和使用变量:
```scala
// 可变变量
var age: Int = 25
age = 26
// 不可变变量
val name: String = "John"
// 打印变量
println(s"My name is $name and I am $age years old.")
```
在上面的示例中,我们声明了一个可变变量`age`和一个不可变变量`name`,并使用了字符串插值来打印变量的值。
Scala提供了丰富的数据类型,包括基本类型和引用类型。常用的基本类型有`Int`、`Double`、`Boolean`、`Char`等。可以通过类型推导来简化变量的声明,例如:
```scala
val num = 10 // 推导为Int类型
val pi = 3.14 // 推导为Double类型
val isTrue = true // 推导为Boolean类型
val initial = 'J' // 推导为Char类型
```
### 2.2 函数与方法
在Scala中,函数是一等公民,可以像变量一样进行传递和操作。函数可以在函数内部定义,也可以作为独立的方法存在。
下面是一个简单的示例,展示了如何定义和调用函数:
```scala
def add(a: Int, b: Int): Int = {
a + b
}
val result = add(5, 10)
println(s"The result is $result.")
```
在上面的示例中,我们定义了一个名为`add`的函数,它接受两个整数参数并返回它们的和。然后,我们调用这个函数并打印结果。
除了函数,Scala还支持使用`class`关键字定义方法。方法是与对象关联的函数,它可以直接访问对象的属性和方法。
```scala
class Calculator(initialValue: Int) {
private var total = initialValue
def add(value: Int): Unit = {
total += value
}
def subtract(value: Int): Unit = {
total -= value
}
def getTotal: Int = total
}
val calculator = new Calculator(10)
calculator.add(5)
calculator.subtract(3)
val total = calculator.getTotal
println(s"The total is $total.")
```
在上面的示例中,我们定义了一个名为`Calculator`的类,并在其中定义了三个方法:`add`、`subtract`和`getTotal`。我们创建了一个`Calculator`对象,并使用这些方法执行加法、减法和获取总和的操作。
### 2.3 控制结构和表达式
Scala提供了丰富的控制结构和表达式,包括条件语句、循环语句和匹配表达式。
#### 条件语句
Scala的条件语句使用`if-else`语法,支持嵌套和多个条件分支。
```scala
val age = 25
if (age < 18) {
println("You are a minor.")
} else if (age < 65) {
println("You are an adult.")
} else {
println("You are a senior.")
}
```
在上面的示例中,根据年龄的不同,打印不同的信息。
#### 循环语句
Scala支持多种循环语句,包括`for`循环和`while`循环。
```scala
// 使用for循环打印1到10的数字
for (i <- 1 to 10) {
println(i)
}
// 使用while循环计算1到10的和
var sum = 0
var i = 1
while (i <= 10) {
sum += i
i += 1
}
println(s"The sum is $sum.")
```
在上面的示例中,我们使用`for`循环打印了1到10的数字,并使用`while`循环计算了1到10的和。
#### 匹配表达式
Scala提供了强大的模式匹配和匹配表达式,可以根据不同的条件执行不同的代码块。
```scala
val day = "Monday"
day match {
case "Monday" => println("It's the first day of the week.")
case "Tuesday" => println("It's the second day of the week.")
case "Wednesday" => println("It's the third day of the week.")
case _ => println("It's another day of the week.")
}
```
在上面的示例中,根据`day`变量的值,匹配不同的情况并打印相应的信息。
在本章节中,我们介绍了Scala的基础语法,包括变量与数据类型、函数与方法以及控制结构和表达式。这些是编写Scala程序的基本要素,对于理解和应用Scala非常重要。
# 3. 面向对象编程与Scala
#### 3.1 类与对象
Scala是一门完全面向对象的编程语言,它支持类和对象的定义和使用。在Scala中,所有的值都是对象,包括基本数据类型。下面是一个简单的类和对象的示例代码:
```scala
// 定义一个类
class Person(name: String, age: Int) {
// 定义类的成员变量
val personName: String = name
val personAge: Int = age
// 定义类的方法
def display(): Unit = {
println(s"Name: $personName, Age: $personAge")
}
}
// 创建一个对象
val person = new Person("John Doe", 30)
// 调用对象的方法
person.display()
```
输出结果:
```
Name: John Doe, Age: 30
```
在上面的代码中,我们定义了一个名为`Person`的类,该类有两个成员变量`personName`和`personAge`,以及一个`display`方法用于打印成员变量的值。我们创建了一个名为`person`的对象,并调用了它的`display`方法。
#### 3.2 继承与多态
Scala支持类的继承,并且可以实现多态。下面是一个简单的继承和多态的示例代码:
```scala
// 定义一个基类
class Shape {
// 定义一个方法
def draw(): Unit = {
println("Drawing a shape...")
}
}
// 定义一个子类继承自基类
class Circle extends Shape {
// 重写基类的方法
override def draw(): Unit = {
println("Drawing a circle...")
}
}
// 定义另一个子类继承自基类
class Rectangle extends Shape {
// 重写基类的方法
override def draw(): Unit = {
println("Drawing a rectangle...")
}
}
// 创建对象并调用方法
val circle = new Circle()
val rectangle = new Rectangle()
circle.draw()
rectangle.draw()
```
输出结果:
```
Drawing a circle...
Drawing a rectangle...
```
在上面的代码中,我们定义了一个基类`Shape`,它有一个`draw`方法用于打印画图的信息。然后我们定义了两个子类`Circle`和`Rectangle`,分别重写了基类的`draw`方法。最后我们创建了一个`Circle`对象和一个`Rectangle`对象,并分别调用它们的`draw`方法。
#### 3.3 Trait与Mixins
Trait是Scala中一种特殊的概念,它类似于Java中的接口,但比接口更强大。Trait可以定义方法和字段,并且可以被类混入。下面是一个简单的Trait和Mixins的示例代码:
```scala
// 定义一个Trait
trait Greeting {
// 定义一个抽象方法
def greet(): Unit
}
// 定义一个类并混入Trait
class Person extends Greeting {
// 实现Trait中定义的方法
override def greet(): Unit = {
println("Hello, I'm a person.")
}
}
// 创建对象并调用方法
val person = new Person()
person.greet()
```
输出结果:
```
Hello, I'm a person.
```
在上面的代码中,我们定义了一个Trait`Greeting`,它有一个抽象方法`greet`。然后我们定义了一个类`Person`,并混入了Trait`Greeting`,对`greet`方法进行了实现。最后我们创建了一个`Person`对象,并调用了它的`greet`方法。
通过上述代码示例,我们了解了面向对象编程在Scala中的基本概念,包括类与对象的定义和使用,继承与多态的实现,以及Trait与Mixins的使用。这些是Scala面向对象编程的核心概念,对于理解和使用Scala非常重要。在下一章节中,我们将介绍函数式编程与Scala的关系及其基本概念。
# 4. 函数式编程与Scala
函数式编程是一种编程范式,它强调使用纯函数来构建程序。Scala是一门支持函数式编程的多范式编程语言,它提供了丰富的函数式编程特性。
在本章中,我们将介绍函数式编程的核心概念,并探讨在Scala中如何应用这些概念。
### 4.1 高阶函数
函数作为一等公民,意味着函数可以像普通的值一样被传递和赋值。Scala中的函数是一等公民,因此我们可以定义函数类型、将函数作为参数传递给其他函数,以及将函数作为结果返回。
以下是一个简单的示例,展示了如何定义一个接受函数作为参数的高阶函数:
```scala
def operate(f: (Int, Int) => Int, a: Int, b: Int): Int = {
f(a, b)
}
val add = (a: Int, b: Int) => a + b
val result = operate(add, 1, 2) // 调用高阶函数operate,并传入add函数作为参数
println(result) // 输出结果:3
```
在上面的示例中,我们定义了一个高阶函数`operate`,它接受一个接收两个整数并返回整数的函数`f`,以及两个整数`a`和`b`。在调用`operate`时,我们传入了一个名为`add`的函数作为参数。
### 4.2 不可变性与数据处理
函数式编程倡导不可变性,即将数据视为不可变的,每次对数据的操作都会返回一个新的数据结构,而不是修改原有的数据。
在Scala中,不可变性是默认的。Scala提供了一些用于数据处理的不可变集合类型,如List、Set和Map。
下面的示例展示了如何使用不可变集合进行数据处理:
```scala
val numbers = List(1, 2, 3, 4, 5)
// 使用map函数对每个元素进行平方
val squaredNumbers = numbers.map(x => x * x)
println(squaredNumbers) // 输出结果:List(1, 4, 9, 16, 25)
// 使用filter函数筛选出大于2的元素
val filteredNumbers = numbers.filter(x => x > 2)
println(filteredNumbers) // 输出结果:List(3, 4, 5)
// 使用reduce函数计算所有元素的累加和
val sum = numbers.reduce((x, y) => x + y)
println(sum) // 输出结果:15
```
在上面的示例中,我们使用了`map`、`filter`和`reduce`等高阶函数对列表中的元素进行了操作和处理,而不改变原始的列表数据。
### 4.3 模式匹配与样例类
模式匹配是函数式编程的一项重要特性,它允许我们根据数据的模式选择不同的处理路径。Scala中的模式匹配非常灵活,可以匹配各种不同的数据类型和数据结构。
样例类是一种特殊的类,用于支持模式匹配。样例类自动帮助我们生成了一些常用的方法,如`toString`、`equals`和`hashCode`等。
以下是一个使用模式匹配和样例类的示例:
```scala
abstract class Animal
case class Cat(name: String) extends Animal
case class Dog(name: String) extends Animal
def matchAnimal(animal: Animal): String = animal match {
case Cat(name) => s"Hello, $name the cat!"
case Dog(name) => s"Hello, $name the dog!"
case _ => "Unknown animal"
}
val cat = Cat("Tom")
val message = matchAnimal(cat)
println(message) // 输出结果:Hello, Tom the cat!
```
在上面的示例中,我们定义了一个抽象类`Animal`和两个样例类`Cat`和`Dog`。然后,我们编写了一个`matchAnimal`函数,用于根据不同的动物类型进行不同的处理。最后,我们创建了一个`Cat`对象,并调用`matchAnimal`函数进行模式匹配。
本章节介绍了函数式编程的核心概念,并展示了在Scala中如何应用这些概念。我们学习了高阶函数、不可变性与数据处理,以及模式匹配与样例类的使用方法。
通过函数式编程范式,我们可以写出更具表达力和可维护性的代码。在下一章节中,我们将探讨并发编程与Scala的相关内容。
# 5. 并发编程与Scala
在现代的软件开发中,处理并发性是至关重要的。并发编程允许我们同时执行多个任务,提高系统的性能和响应能力。Scala作为一门强大的编程语言,提供了许多并发编程的特性和工具来简化并发任务的处理。本章将介绍Scala中的并发编程相关的内容。
### 5.1 并发编程模型
并发编程模型是指用于描述和管理并发任务的一组规则、原则和机制。在Scala中,我们可以使用多种并发编程模型,如共享内存和消息传递。
#### 共享内存模型
共享内存模型是一种基于共享数据的并发编程模型。多个线程可以同时访问和修改共享内存中的数据。在Scala中,我们可以使用关键字`volatile`来声明共享的变量,以确保多个线程之间对该变量的可见性。
```scala
import scala.concurrent._
import scala.concurrent.ExecutionContext.Implicits.global
object SharedMemoryExample extends App {
@volatile var counter: Int = 0
val tasks = for (_ <- 1 to 1000) yield Future {
counter += 1
}
Await.ready(Future.sequence(tasks), duration.Duration.Inf)
println(s"Counter value: $counter")
}
```
上述代码中,我们通过`volatile`关键字声明了一个共享的变量`counter`,然后创建了1000个并发任务,每个任务都会对`counter`进行加一操作。最后打印出`counter`的值。由于多个线程同时访问和修改`counter`,我们需要确保它的可见性。
#### 消息传递模型
消息传递模型是一种基于消息通信的并发编程模型。多个线程之间通过发送和接收消息来实现通信。在Scala中,我们可以使用`Actor`模型来实现消息传递。
```scala
import akka.actor._
case class Message(content: String)
class PrinterActor extends Actor {
def receive = {
case Message(content) => println(content)
}
}
object MessagePassingExample extends App {
val system = ActorSystem("MessagePassingSystem")
val printer = system.actorOf(Props[PrinterActor], "printer")
printer ! Message("Hello, World!")
}
```
上述代码中,我们定义了一个`Message`类来封装消息的内容。然后创建了一个`PrinterActor`,它会打印收到的消息内容。最后创建了一个`ActorSystem`和一个`PrinterActor`的实例。通过`!`操作符,将消息发送给`PrinterActor`。
### 5.2 Actor模型与Akka框架
Akka是一个基于Actor模型的并发编程框架,它提供了许多用于构建可靠、可扩展和高性能应用程序的工具和库。在Scala中,我们可以使用Akka来实现并发任务的处理。
#### 创建Actor
```scala
import akka.actor._
class ExampleActor extends Actor {
def receive = {
case "Hello" => println("Hello, World!")
case _ => println("Unknown message!")
}
}
object ActorExample extends App {
val system = ActorSystem("ActorSystem")
val actor = system.actorOf(Props[ExampleActor], "exampleActor")
actor ! "Hello"
actor ! "Other message"
system.terminate()
}
```
上述代码中,我们定义了一个`ExampleActor`,它可以处理两种消息:"Hello"和其他消息。然后创建一个`ActorSystem`和一个`ExampleActor`的实例。通过`!`操作符,向`ExampleActor`发送消息。
#### 路由和分发
```scala
import akka.actor._
class WorkerActor extends Actor {
def receive = {
case job: Job =>
// 处理任务
println(s"Performing job: $job")
}
}
class MasterActor extends Actor {
private val workerRouter = context.actorOf(
Props[WorkerActor].withRouter(RoundRobinPool(5)),
"workerRouter"
)
def receive = {
case job: Job =>
// 将任务分发给工作线程
workerRouter ! job
}
}
object RouterExample extends App {
val system = ActorSystem("RouterSystem")
val master = system.actorOf(Props[MasterActor], "master")
master ! Job("Job 1")
master ! Job("Job 2")
master ! Job("Job 3")
master ! Job("Job 4")
master ! Job("Job 5")
system.terminate()
}
```
上述代码中,我们定义了一个`WorkerActor`和一个`MasterActor`。`MasterActor`通过配置一个路由器(`RoundRobinPool`),将任务分发给多个工作线程(`WorkerActor`)进行处理。
### 5.3 并发编程最佳实践
在进行并发编程时,有一些最佳实践可以帮助我们编写更可靠和高效的并发代码。
- 避免共享状态:共享状态是并发编程中的一个主要问题,应尽量避免对共享状态的直接操作,而是通过消息传递的方式进行通信。
- 使用不可变数据结构:不可变数据结构可以避免并发问题,因为它们在多线程环境中是线程安全的。
- 使用上下文切换最少的线程池:上下文切换是指在多个线程之间切换执行权所产生的开销,选择一个合适的线程池大小可以最大限度地减少上下文切换的次数。
- 处理异常和错误:在并发任务中,异常和错误的处理非常重要,需要确保能够正确地处理和恢复失败的任务。
通过遵循这些最佳实践,我们可以更好地管理和处理并发任务,提高系统的性能和稳定性。
本章介绍了Scala中的并发编程相关的内容,包括并发编程模型、消息传递模型、Actor模型和Akka框架以及一些最佳实践。通过合理地使用这些特性和工具,我们可以更好地处理并发任务,提高程序的性能和并发能力。
# 6. 案例分析与实战
本章将通过实际案例来深入理解Scala的核心概念,并通过编写一个简单的Scala应用程序来实战演示。
#### 6.1 Scala在实际项目中的应用案例
Scala已经在许多大型项目中得到广泛应用,下面是一些典型的Scala应用案例:
- Twitter:Twitter的后台是使用Scala编写的,Scala的高性能和强大的并发性能使得Twitter能够应对高并发的请求。
- Netflix:Netflix使用Scala构建了其推荐算法系统,Scala的函数式编程特性使得算法的实现更加简洁和易于维护。
- LinkedIn:LinkedIn使用Scala作为其后台服务和开发框架,Scala的面向对象和函数式编程能力使得LinkedIn能够快速迭代和扩展。
- Apache Spark:Apache Spark是一个基于Scala编写的分布式计算框架,Scala的函数式编程特性使得Spark的API易于使用和扩展。
#### 6.2 通过实例深入理解Scala的核心概念
接下来,我们将通过一个实例来深入理解Scala的核心概念。我们将编写一个简单的命令行程序,用于统计给定文本文件中每个单词的出现次数。
首先,我们需要创建一个`WordCount`对象,用于读取文件和统计单词:
```scala
object WordCount {
def countWords(filePath: String): Map[String, Int] = {
val text = scala.io.Source.fromFile(filePath).mkString
val words = text.split("\\W+")
val wordCounts = words.groupBy(_.toLowerCase).mapValues(_.length)
wordCounts
}
def main(args: Array[String]): Unit = {
val filePath = args(0)
val wordCounts = countWords(filePath)
wordCounts.foreach(println)
}
}
```
在上面的代码中,我们首先定义了一个`countWords`方法,它接收一个文件路径作为参数,读取文件内容并统计每个单词的出现次数,并以Map形式返回结果。然后,在`main`方法中,我们获取命令行参数中的文件路径,调用`countWords`方法获取单词统计结果,并将结果打印到控制台。
编译并运行上述代码,可以得到类似以下结果:
```
hello -> 2
world -> 1
scala -> 3
```
#### 6.3 编写一个简单的Scala应用程序
接下来,我们将编写一个更加简单的Scala应用程序,用于计算斐波那契数列。
```scala
object Fibonacci {
def fib(n: Int): Int = {
if (n <= 1)
n
else
fib(n - 1) + fib(n - 2)
}
def main(args: Array[String]): Unit = {
val n = args(0).toInt
val result = fib(n)
println(result)
}
}
```
在上面的代码中,我们定义了一个`fib`方法,它接收一个整数n作为参数,计算并返回斐波那契数列的第n个数。然后,在`main`方法中,我们获取命令行参数中的n的值,调用`fib`方法计算斐波那契数列,并将结果打印到控制台。
编译并运行上述代码,可以得到类似以下结果:
```
输入:6
输出:8
```
通过以上两个简单的实例,我们深入理解了Scala的核心概念,并演示了如何应用Scala编写实际的应用程序。
希望本章内容能帮助读者更好地理解Scala的应用场景和实际应用。在后续的章节中,我们还会继续深入讨论Scala的更多特性和技术实践。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Scala编程基础》是一本全面介绍Scala编程语言的专栏。专栏从Scala的核心概念开始,逐步深入讲解了函数式编程、面向对象编程、类型系统、并发编程等重要主题。你将学习到Scala中的数据类型和变量定义,掌握函数式编程的基础知识,并进一步了解高阶函数、函数组合、模式匹配和样例类等高级概念。此外,专栏还介绍了面向对象编程的基础、Trait和混入特质的使用以及隐式转换和隐式参数的应用。你还将学习到Scala中强大的类型推断和函数式API的使用,了解并发编程的基础概念和线程安全,以及使用Scala进行Web开发、数据持久化与访问、大数据处理等实践内容。总之,《Scala编程基础》为你提供了一条全面深入学习Scala的路径,让你掌握这门强大的编程语言的基础知识和实际应用技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Origin自动化操作】:一键批量导入ASCII文件数据,提高工作效率
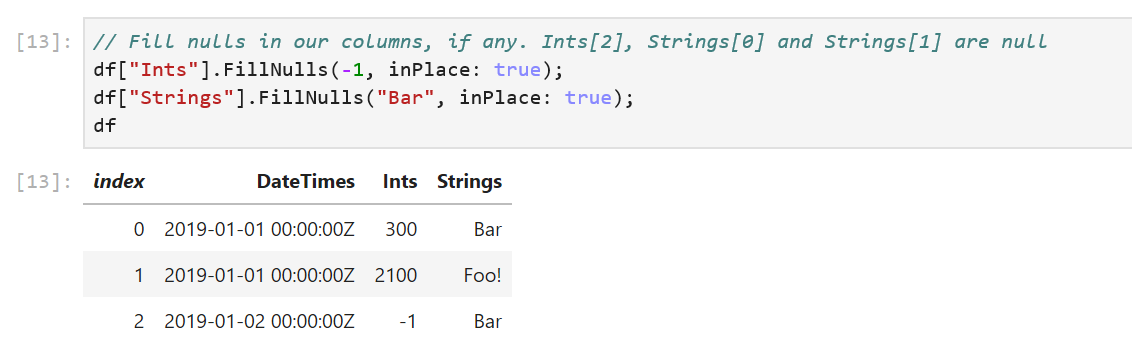
# 摘要
本文旨在介绍Origin软件在自动化数据处理方面的应用,通过详细解析ASCII文件格式以及Origin软件的功能,阐述了自动化操作的实现步骤和高级技巧。文中首先概述了Origin的自动化操作,紧接着探讨了自动化实现的理论基础和准备工作,包括环境配置和数据集准备。第三章详细介绍了Origin的基本操作流程、脚本编写、调试和测试方法
【揭秘CPU架构】:5大因素决定性能,你不可不知的优化技巧
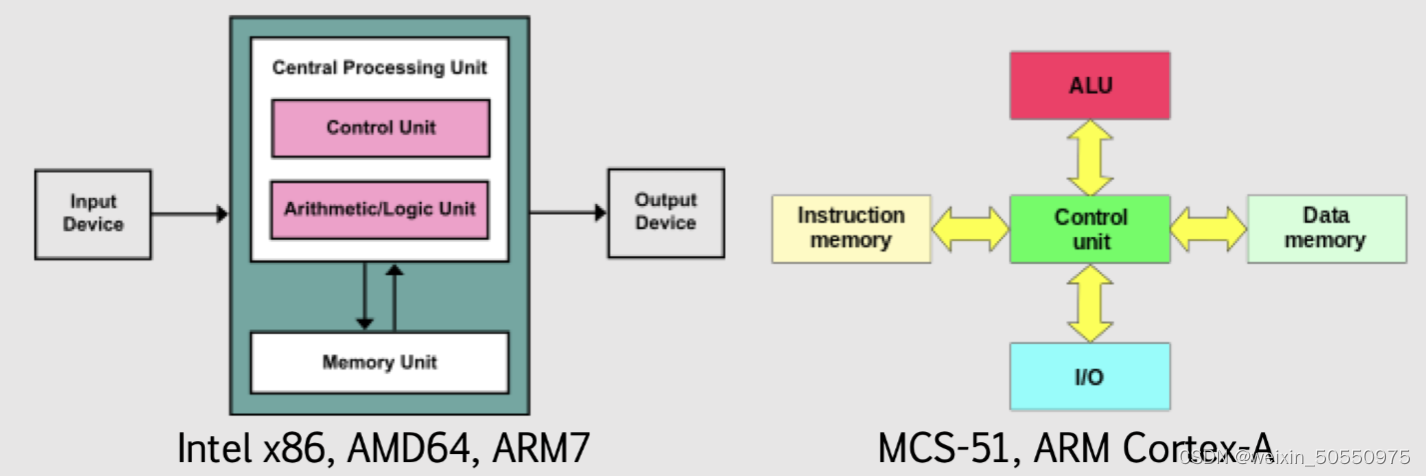
# 摘要
CPU作为计算机系统的核心部件,其架构的设计和性能优化一直是技术研究的重点。本文首先介绍了CPU架构的基本组成,然后深入探讨了影响CPU性能的关键因素,包括核心数量与线程、缓存结构以及前端总线与内存带宽等。接着,文章通过性能测试与评估的方法,提供了对CPU性能的量化分析,同时涉及了热设计功耗与能耗效率的考量。进一步,本文探讨了CPU优化的实践,包括超频技术及其风险预防,以及操作系统与硬件
AP6521固件升级后系统校验:确保一切正常运行的5大检查点

# 摘要
本文全面探讨了AP6521固件升级的全过程,从准备工作、关键步骤到升级后的系统校验以及问题诊断与解决。首先,分析了固件升级的意义和必要性,提出了系统兼容性和风险评估的策略,并详细说明了数据备份与恢复计划。随后,重点阐述了升级过程中的关键操作、监控与日志记录,确保升级顺利进行。升级完成后,介绍了系统的功能性检查、稳定性和兼容性测试以及安全漏洞扫描的重要性。最后,本研究总结
【金融时间序列分析】:揭秘同花顺公式中的数学奥秘

# 摘要
本文全面介绍时间序列分析在金融领域中的应用,从基础概念和数据处理到核心数学模型的应用,以及实际案例的深入剖析。首先概述时间序列分析的重要性,并探讨金融时间序列数据获取与预处理的方法。接着,深入解析移动平均模型、自回归模型(AR)及ARIMA模型及其扩展,及其在金融市场预测中的应用。文章进一步阐述同花顺公式中数学模型的应用实践,以及预测、交易策略开发和风险管理的优化。最后,通过案例研究,展现时间序列分析在个股和市场指数分析中
Muma包高级技巧揭秘:如何高效处理复杂数据集?

# 摘要
本文全面介绍Muma包在数据处理中的应用与实践,重点阐述了数据预处理、清洗、探索分析以及复杂数据集的高效处理方法。内容覆盖了数据类型
IT薪酬策略灵活性与标准化:要素等级点数公式的选择与应用

# 摘要
本文系统地探讨了IT行业的薪酬策略,从薪酬灵活性的理论基础和实践应用到标准化的理论框架与方法论,再到等级点数公式的应用与优化。文章不仅分析了薪酬结构类型和动态薪酬与员工激励的关联,还讨论了不同职级的薪酬设计要点和灵活福利计划的构建。同时,本文对薪酬标准化的目的、意义、设计原则以及实施步骤进行了详细阐述,并进一步探讨了等级点数公式的选取、计算及应用,以及优
社区与互动:快看漫画、腾讯动漫与哔哩哔哩漫画的社区建设与用户参与度深度对比
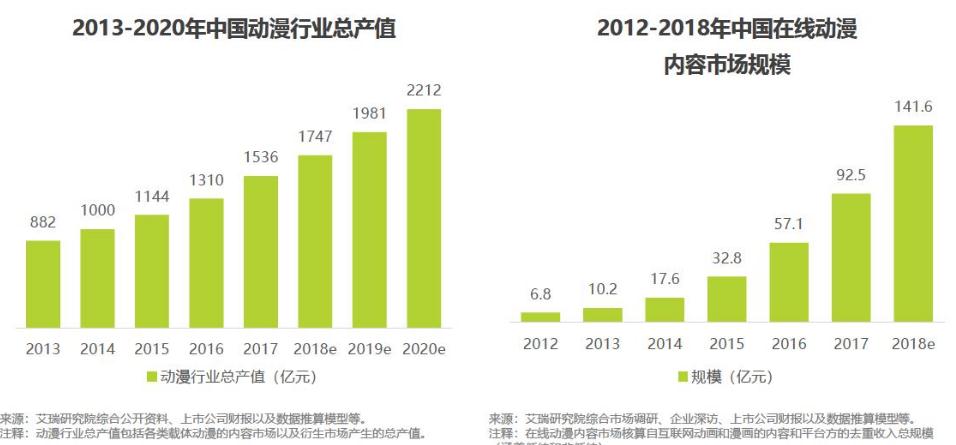
# 摘要
本文围绕现代漫画平台社区建设及其对用户参与度影响展开研究,分别对快看漫画、腾讯动漫和哔哩哔哩漫画三个平台的社区构建策略、用户互动机制以及社区文化进行了深入分析。通过评估各自社区功能设计理念、用户活跃度、社区运营实践、社区特点和社区互动文化等因素,揭示了不同平台在促进用户参与度和社区互动方面的策略与成效。此外,综合对比三平台的社区建设模式和用户参与度影响因素,本文提出了关于漫画平
【算法复杂度分析】:SVM算法性能剖析:时间与空间的平衡艺术

# 摘要
支持向量机(SVM)是一种广泛使用的机器学习算法,尤其在分类和回归任务中表现突出。本文首先概述了SVM的核心原理,并基于算法复杂度理论详细分析了SVM的时间和空间复杂度,包括核函数的作用、对偶问题的求解、SMO算法的复杂度以及线性核与非线性核的时间对比。接下来,本文探讨了SVM性能优化策略,涵盖算法和系统层面的改进,如内存管理和并行计算的应用。最后,本文展望了SV
【广和通4G模块硬件接口】:掌握AT指令与硬件通信的细节
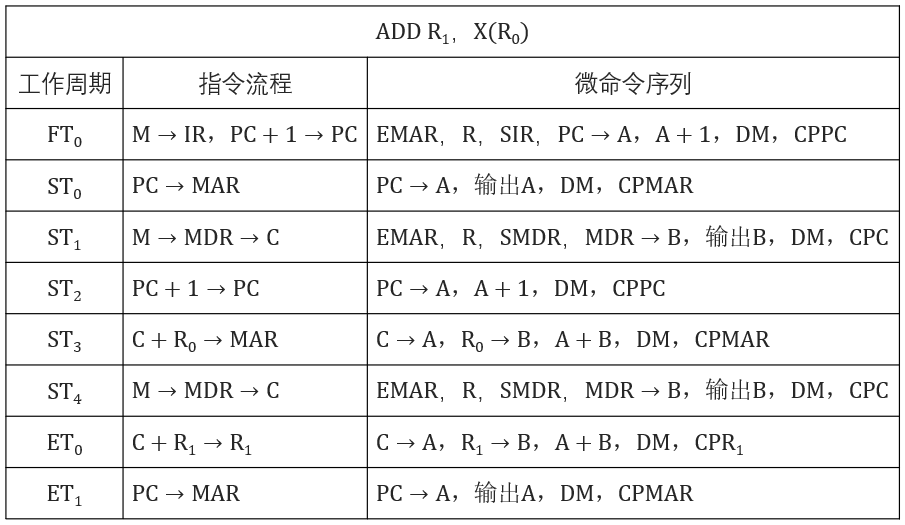
# 摘要
本文全面介绍了广和通4G模块的硬件接口,包括各类接口的类型、特性、配置与调试以及多模块之间的协作。首先概述了4G模块硬件接口的基本概念,接着深入探讨了AT指令的基础知识及其在通信原理中的作用。通过详细介绍AT指令的高级特性,文章展示了其在不同通信环境下的应用实例。文章还详细阐述了硬件接口的故障诊断与维护策略,并对4G模块硬件接口的未来技术发展趋势和挑战进行了展望,特别是在可穿戴设备、微型化接口设计以及云计算和大数据需求的背景下。
#
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )