深入剖析
发布时间: 2024-09-18 15:55:05 阅读量: 70 订阅数: 27 

# 1. Kubernetes资源管理概述
在当今IT行业中,Kubernetes 已经成为事实上的容器编排标准,它极大地简化了复杂分布式系统的管理。本章将带您了解 Kubernetes 资源管理的基础知识,为后续章节的深入探讨奠定基础。
## Kubernetes资源管理的重要性
Kubernetes 资源管理的核心在于确保集群中的应用程序按预期运行,并高效利用底层硬件资源。通过精确控制资源的分配,Kubernetes 可以实现应用程序的快速扩展、自动故障转移以及资源成本的有效管理。
## Kubernetes资源管理的基本概念
在 Kubernetes 中,资源被定义为集群内运行的Pods、Service、Ingress等对象,它们都具有特定的生命周期和配置。资源管理的核心是理解和配置这些资源,以确保系统的弹性和效率。
```mermaid
graph LR
A[Kubernetes资源管理] --> B[资源类型与配置]
B --> C[资源监控与优化]
C --> D[高级技巧]
D --> E[实战案例]
E --> F[未来趋势]
```
Kubernetes 的资源管理流程从定义资源开始,通过监控和优化不断调整,利用高级技巧解决实际问题,并结合实战案例逐步完善。最终,我们展望资源管理的未来趋势,以适应不断发展的技术需求。
# 2. Kubernetes资源类型和配置
## 2.1 Kubernetes核心资源概念
### 2.1.1 Pod资源的定义和生命周期
Kubernetes中,Pod 是在集群中运行的、可以包含一个或多个容器的逻辑单元。每个Pod都作为集群中的一个独立单元进行调度到节点上,并且是Kubernetes中最小的部署单元。理解Pod资源的定义和生命周期对于构建和管理Kubernetes工作负载至关重要。
在Kubernetes中,Pod的定义包含了一组容器的集合、存储资源、网络IP以及控制Pod行为的选项。每个Pod都必须具备一个唯一的ID,此外,每个Pod都会根据其镜像和配置运行一个或多个容器。
一个Pod从创建到销毁的整个过程,构成了其生命周期。Pod的生命周期包含以下阶段:
- **Pending(挂起)**:Pod已经被Kubernetes系统接受,但至少有一个容器尚未创建完成。
- **Running(运行中)**:Pod已经被绑定到一个节点上,所有容器都已创建。至少一个容器正在运行,或者正在启动或重启。
- **Succeeded(成功)**:Pod中的所有容器都已经成功终止,并且不会被重启。
- **Failed(失败)**:Pod中的所有容器都已经终止,且至少有一个容器是因为失败终止(非0状态退出)。
- **Unknown(未知)**:因为某些原因,无法获取Pod的状态,通常是与Pod所在节点通信失败。
管理Pod生命周期的核心概念之一是Init Containers,它们是Pod中按顺序运行的容器,必须在应用程序容器启动之前成功完成。
代码块示例:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
command: ['sh', '-c', 'echo This is the app! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox
command: ['sh', '-c', 'until nslookup myservice; do echo waiting for myservice; sleep 2; done']
```
在上面的YAML配置文件中,一个Pod被定义,它包含了两个容器:一个应用程序容器和一个初始化容器。初始化容器会在应用程序容器启动之前运行,确保服务“myservice”已经可用。
### 2.1.2 Service和Ingress资源的作用
Service和Ingress是Kubernetes中用于处理服务发现和负载均衡的核心资源。
**Service**提供了一种抽象,允许用户将一组运行的Pod定义为一个逻辑单元,并为这些Pod提供统一的访问入口。Service通过标签选择器关联Pod,它为一组Pod提供了一个静态的IP地址和DNS名,从而使得Pod能够在IP地址变更后继续被访问。
Service的类型大致分为以下几种:
- **ClusterIP**:默认类型,在集群内部访问,是内部负载均衡器。
- **NodePort**:在每个Node上开一个端口,集群外可通过<NodeIP>:<NodePort>访问。
- **LoadBalancer**:结合云服务提供商的负载均衡器,用于外部访问服务。
- **ExternalName**:将服务映射到指定的外部DNS名,不通过代理。
而**Ingress**提供了外部访问集群服务的API对象。Ingress定义了规则,允许外部流量进入集群内的服务。Ingress可以配置为提供负载均衡、SSL终止和基于名称的虚拟托管,实现对后端Service的路由。
Ingress资源通常与Ingress控制器一起使用,控制器负责实现Ingress规则,常见的控制器包括Nginx、HAProxy、Istio等。
```yaml
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: example-ingress
spec:
rules:
- host: ***
***
***
***
***
***
***
```
以上是一个Ingress配置示例,定义了一个简单的Ingress规则,当请求到达***时,所有路径(/)上的流量都会被路由到名为`myapp-svc`的服务上。
## 2.2 Kubernetes高级资源特性
### 2.2.1 StatefulSets和Deployments
StatefulSets和Deployments是Kubernetes用来管理Pod集合的两种不同的资源类型,它们各自有着不同的用途和特性。
**Deployments**为无状态的应用提供了一种管理Pod和ReplicaSets的方法。无状态应用不保存任何状态到本地存储中,其状态可以随时丢弃。这意味着任何Pod都可以重新创建,且不需要担心数据丢失问题。当需要更新应用时,Deployments支持滚动更新(Rolling Update),可以实现无缝的版本切换和回滚。
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
```
上面的YAML配置创建了一个名为`nginx-deployment`的Deployment,它会启动3个Pod副本,每个Pod都运行nginx:1.14.2镜像。
**StatefulSets**则是用来管理有状态的应用。有状态应用通常需要稳定的网络标识(如名称和持久化存储),并能按顺序部署和扩展。StatefulSets通过为每个Pod维护一个持久的标识来满足这些需求。StatefulSet为每个Pod生成一个唯一的序号,并保证这个序号在Pod重新调度后仍保持不变。
```yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web
spec:
serviceName: "nginx"
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
```
在这个StatefulSet配置示例中,我们创建了一个名为`web`的StatefulSet,它创建了两个Pod副本,这些副本以nginx:1.14.2镜像运行。
### 2.2.2 ConfigMaps和Secrets
在Kubernetes中,ConfigMaps和Secrets是用于存储配置数据和敏感信息的资源。它们允许将配置信息和敏感数据从容器镜像中解耦出来,实现更好的配置管理和安全性。
**ConfigMaps**用于存储非敏感的配置数据。ConfigMaps可以被Pod引用,并通过环境变量、命令行参数或作为卷挂载到Pod中。创建ConfigMap后,可以根据需要将其集成到Pod的配置中。
```yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: special-config
data:
SPECIAL_LEVEL: very
SPECIAL_TYPE: charm
apiVersion: v1
kind: Pod
metadata:
name: configmap-demo-pod
spec:
containers:
- name: demo
image: alpine
command: ["sh", "-c", "echo $(LEVEL) $(TYPE)"]
env:
- name: LEVEL
valueFrom:
configMapKeyRef:
name: special-config
key: SPECIAL_LEVEL
- name: TYPE
valueFrom:
configMapKeyRef:
name: special-config
key: SPECIAL_TYPE
volumeMounts:
- name: config-volume
mountPath: /etc/config
volumes:
- name: config-volume
configMap:
name: special-config
```
在这个例子中,我们定义了一个ConfigMap `special-config`,其中包含了两个数据项:`SPECIAL_LEVEL`和`SPECIAL_TYPE`。然后我们在Pod `configmap-demo-pod`中使用这些配置项,它们被映射为容器的环境变量。
**Secrets**用于存储敏感数据,如密码、OAuth令牌和ssh密钥。Secrets基本上与ConfigMaps类似,但它们的值是base64编码的,以便进行更安全的存储和传输。Secrets可以以多种方式使用,包括作为环境变量、数据卷中的文件,或者由Kubernetes的API直接使用。
```yaml
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4=
password: MWYyZDFlMmU2N2Rm
apiVersion: v1
kind: Pod
metadata:
name: secret-env-pod
spec:
containers:
- name: mycontainer
image: redis
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
```
在这个例子中,我们创建了一个Secret `mysecret`,包含了两个数据项:`username`和`password`。然后我们在Pod `secret-env-pod`中通过环境变量引用了这些数据项。
## 2.3 Kubernetes资源调度策略
### 2.3.1 资源请求和限制的设置
Kubernetes 允许用户为容器指定资源请求(request)和资源限制(limit)。请求确保容器有最小的资源保证,而限制防止容器消耗超出其应有份额的资源。
资源请求和限制是在容器的配置文件中通过`resources`字段设置的。例如:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: resource-request-pod
spec:
containers:
- name: my-container
image: nginx
resources:
requests:
memory: "128Mi"
cpu: "500m"
limits:
memory: "256Mi"
cpu: "1000m"
```
在上述配置中,`my-container` 容器被指定了 128MB 的内存请求和 0.5 个CPU核心的请求;同时,它还被限制使用最大 256MB 的内存和 1 个CPU核心。
### 2.3.2 节点亲和性与反亲和性的配置
节点亲和性(Node Affinity)和反亲和性(Node Anti-Affinity)使得用户能够控制Pod部署到哪些节点上。这有助于确保工作负载的调度更符合用户的实际需求,如将Pod部署到特定的地理位置或在高可用性配置中。
节点亲和性有两种类型:
- **requiredDuringSchedulingIgnoredDuringExecution**:必须满足条件,否则Pod不会被调度到对应的节点上。
- **preferredDuringSchedulingIgnoredDuringExecution**:条件优先考虑,但不是必须的,如果无法满足条件,Pod仍然可以被调度到其它节点上。
节点反亲和性是节点亲和性的对立面,它表示一个Pod不应该被调度到具有某些特定属性的节点上。
```yaml
apiVersion: v1
kind: Pod
metadata:
name: affinity-pod
spec:
containers:
- name: with-affinity
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/e2e-az-name
operator: In
values:
- e2e-az1
- e2e-az2
```
在这个例子中,我们定义了一个Pod `affinity-pod`,它带有节点亲和性规则,要求Pod被调度到标签键为`kubernetes.io/e2e-az-name`的节点上,且值为`e2e-az1`或`e2e-az2`。
通过配置节点亲和性和反亲和性,可以实现更为复杂的调度策略,比如将数据库Pod仅部署在特定的高性能节点上,或者避免将多个副本的Pod部署在同一个物理节点上。
# 3. Kubernetes资源监控与优化
Kubernetes的高效资源管理不仅在于合理的资源分配,还在于对资源使用情况的持续监控和优化。本章将详细介绍如何对Kubernetes集群中的资源进行有效监控,以及如何根据监控数据进行资源优化。
## 3.1 资源监控工具和指标
在深入资源监控之前,首先要了解Kubernetes提供的基础资源监控工具与指标。
### 3.1.1 Kubernetes Metrics Server
Metrics Server是Kubernetes集群的核心监控组件,负责收集集群内所有Pods和Nodes的资源使用情况。它是一个水平自动扩展的、高性能的、基于Metrics API的监控服务。
使用Metrics Server,可以轻松查看集群的资源使用情况,例如CPU和内存的使用率。安装Metrics Server后,可以通过kubectl top命令获取集群资源的使用情况。
```bash
# 安装Metrics Server(假设已配置好Helm)
helm install metrics-server stable/metrics-server --set args='{--kubelet-insecure-tls, --kubelet-preferred-address-types=InternalIP}'
# 查看节点的资源使用情况
kubectl top node
# 查看Pods的资源使用情况
kubectl top pod
```
### 3.1.2 资源使用指标和监控图表
资源使用指标是监控系统的基础。通过指标,可以了解到资源的实时使用状态,包括但不限于CPU、内存、存储和网络。
监控图表是将这些指标可视化的工具,如Grafana,它可以帮助运维人员快速识别资源瓶颈和问题所在。在Kubernetes集群中,可以利用Prometheus来收集和存储指标数据,而Grafana作为后端数据的前端展示。
```yaml
# 示例:在Grafana中创建一个Pod CPU使用率的仪表板配置文件
apiVersion: 1
title: Kubernetes Pod CPU Usage
panels:
- title: CPU Usage Per Pod
targets:
- expr: sum(rate(container_cpu_usage_seconds_total{image!=""}[5m]))
```
## 3.2 资源的自动扩展和调度
对于动态变化的工作负载,Kubernetes提供了自动扩展机制,以便自动调整资源的使用量。
### 3.2.1 Horizontal Pod Autoscaler(HPA)
HPA是Kubernetes中用于实现Pod水平自动扩展的组件。当CPU使用率、内存或其他指定指标超出预设的阈值时,HPA可以自动增加Pod副本数量;当负载减少时,Pod副本数量也会相应减少。
```yaml
# 示例:创建一个HPA资源定义
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: example-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
```
### 3.2.2 Cluster Autoscaler的配置和使用
Cluster Autoscaler是自动扩展节点池的工具,它可以根据Pod需求自动添加或删除节点。
```yaml
# 示例:启用Cluster Autoscaler
apiVersion: cluster.k8s.io/v1alpha4
kind: ClusterAutoscaler
metadata:
name: cluster-autoscaler
spec:
clusterName: my-cluster
scaleDown:
enabled: true
delayAfterAdd: 10m
unneededTime: 5m
scaleUp:
enabled: true
```
## 3.3 资源性能优化实践
对资源性能进行优化是一个持续的过程,需要根据实际业务需求和资源消耗情况,不断地调整策略。
### 3.3.1 容器性能分析工具的使用
使用性能分析工具是优化的第一步。例如,通过kubectl top命令获取资源使用情况,然后使用如sysdig、dstat等工具分析容器性能问题。
```bash
# 使用sysdig监控容器性能
sysdig -pc -V -A -c "k8s.pod.name CONTAINS example" -A -c "evt.type!= procexit"
```
### 3.3.2 资源优化策略和案例
资源优化策略包括合理分配Pod资源、使用高效存储方案、优化应用程序代码等。例如,通过合理设置CPU和内存的request和limit,确保Pod在保证性能的同时不会过量使用资源。
```yaml
# 示例:设置Pod资源的request和limit
apiVersion: v1
kind: Pod
metadata:
name: resource-optimized-pod
spec:
containers:
- name: my-container
image: my-app-image
resources:
requests:
cpu: "100m"
memory: "200Mi"
limits:
cpu: "500m"
memory: "500Mi"
```
通过以上示例的实践,我们可以看到Kubernetes资源监控与优化是一个涵盖多层面、多工具的复杂过程,但通过系统化和策略化的管理,可以大幅提高集群资源使用效率,降低运营成本。
以上内容仅作为章节内容的一部分,完整的章节内容将更为详细和深入,确保满足所有给定的补充要求和标准。
# 4. Kubernetes资源管理的高级技巧
Kubernetes的强大之处在于它能够管理复杂的分布式系统资源,但这一能力也伴随着需要深入理解的高级技巧。在本章中,我们将深入探讨资源配额、限制、故障排除、备份与恢复等高级技巧,并通过具体案例和最佳实践来呈现这些技巧的应用。
## 4.1 资源配额和限制
资源配额和限制是Kubernetes集群中的关键管理工具,它们确保了资源的公平使用,并防止任何单一租户或应用程序独占集群资源。
### 4.1.1 命名空间级别的资源配额
Kubernetes允许管理员为命名空间设置资源配额,这些配额定义了在该命名空间内可以被Pods使用的计算资源总量。通过这种方式,可以实现多租户环境下的资源隔离和调度。
```yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
cpu: "1"
memory: 1Gi
pods: "2"
```
在上述YAML配置中,定义了一个名为`compute-resources`的`ResourceQuota`,它限制了命名空间中CPU、内存和Pod数量的最大值。资源配额确保了一个命名空间不会消耗超过其份额的计算资源。
### 4.1.2 资源限制与安全上下文
资源限制是通过`limitRange`对象实现的,它可以在命名空间内为单个容器设置资源使用的最小和最大限制。
```yaml
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-limit-range
spec:
limits:
- type: Container
max:
cpu: "1"
memory: 1Gi
min:
cpu: 100m
memory: 20Mi
default:
cpu: "500m"
memory: 500Mi
defaultRequest:
cpu: "200m"
memory: 100Mi
maxLimitRequestRatio:
cpu: "10"
memory: "10"
```
通过这个`LimitRange`配置,我们为命名空间中的容器设置了CPU和内存的最小和最大限制,以及默认的请求和限制值。这确保了所有容器都有足够的资源可用,同时限制了它们对资源的过度消耗。
安全上下文则定义了Pod级别和容器级别的安全设置。它可以用来控制运行容器的用户ID、进程的Linux功能,以及其他安全相关的特性。
## 4.2 Kubernetes资源故障排除
在Kubernetes集群中,资源问题可能会以各种形式出现,包括但不限于资源争用、配置错误、调度问题等。
### 4.2.1 常见资源问题和诊断方法
诊断资源问题首先需要确定资源的使用情况。Kubernetes提供了命令行工具`kubectl`来检查资源使用状况,例如:
```bash
kubectl top pod
kubectl describe pod <pod-name>
```
通过这些命令,可以获取到集群中Pod的CPU和内存使用详情,以及Pod的状态信息。
### 4.2.2 资源故障恢复策略
资源故障可能需要不同的恢复策略,比如重启Pod、调整资源请求和限制,或者进行资源配额的调整。恢复策略的选择取决于故障的性质和原因。
```bash
kubectl delete pod <pod-name>
```
这个命令用于删除故障的Pod,而Kubernetes的控制器会根据定义的副本数量自动创建一个新的Pod实例。
## 4.3 Kubernetes资源的备份与恢复
在日常运维中,备份和恢复Kubernetes资源是确保业务连续性的关键部分。
### 4.3.1 使用Velero进行备份和恢复
Velero是一个开源的备份和迁移工具,用于Kubernetes集群的灾难恢复和数据迁移。
```bash
velero backup create my-backup
velero restore create --from-backup my-backup
```
通过这两个命令,我们可以创建名为`my-backup`的备份,并从该备份中恢复数据。Velero通过创建资源的快照并将其存储在云存储中来实现备份。
### 4.3.2 备份策略的设计与实施
设计备份策略需要考虑数据重要性、备份频率、保留时间等因素。备份策略的实施应确保数据的一致性和完整性,同时需要制定合适的恢复点目标(RPO)和恢复时间目标(RTO)。
一个典型的备份策略可能包含定期备份、保留一定时间周期内的多个备份、执行备份前后的验证测试以及备份数据的加密。
## 小结
在本章节中,我们深入探讨了Kubernetes资源管理的高级技巧,包括资源配额、限制、故障排除、备份与恢复。理解这些高级特性是有效管理大型Kubernetes集群的必要条件。本章节的每个知识点都配以实际操作示例和最佳实践,以便读者能够将这些技巧应用于实际工作中。
通过本章节的学习,IT专业人士应该能够更好地理解如何通过高级管理策略来优化资源利用、确保集群的稳定性和安全性,以及如何在发生故障时快速恢复服务。
# 5. Kubernetes资源管理的实战案例
## 5.1 构建高可用性应用
### 5.1.1 应用的部署与高可用性策略
在构建高可用性应用时,Kubernetes提供了多种策略来确保服务的连续性,这些策略包括但不限于副本集(ReplicaSets)、StatefulSets以及使用持久化存储。要成功部署高可用性应用,关键在于理解如何通过Kubernetes资源定义来实现这些策略。例如,通过设置ReplicaSets可以确保应用的副本数量始终符合预定值,即使个别Pod发生故障,系统也会自动创建新的Pod来保证服务的可用性。
在设计高可用性应用时,还需要考虑到服务的端点和服务发现机制。使用Kubernetes的Service资源可以帮助我们定义一组Pod的访问策略,而Headless Services和StatefulSets则特别适用于有状态应用,因为它们能够确保每个Pod拥有一个稳定的网络标识。
此外,还可以通过编写自定义控制器来扩展Kubernetes的功能,以实现特定的高可用性需求。例如,可以根据业务需求定制健康检查和故障转移逻辑,从而更精确地控制服务的高可用性行为。
### 5.1.2 使用Headless Services和StatefulSets
Headless Services提供了一种方式来定义一组Pod的网络标识,但不为这个标识配置负载均衡和自动创建DNS记录。这对于有状态应用来说非常有用,因为客户端可能需要直接访问特定Pod。通过指定`clusterIP: None`,可以告诉Kubernetes不为Service分配集群IP,而是直接使用Pod IP进行服务发现。
StatefulSets是为了解决有状态应用的部署和管理而设计的。与Deployment不同,StatefulSet维护了Pod的稳定性和唯一的网络标识。当Pod需要重新调度时,StatefulSet确保新的Pod可以获得与之前相同的名称和网络身份。这对于那些需要维护跨Pod状态的应用来说至关重要。
在构建高可用性应用时,StatefulSets和Headless Services的结合使用是一种常见且有效的策略。例如,可以使用StatefulSet来部署数据库服务,同时使用Headless Service来提供稳定的网络访问点。
## 5.2 多环境下的资源管理
### 5.2.1 开发、测试与生产环境的资源管理
在多环境部署中,资源管理是关键一环。不同的环境往往有不同的资源需求和限制,这就要求在不同环境中灵活地分配资源,同时确保环境之间的隔离和安全。
开发环境通常需要能够快速启动并提供实验性部署的能力,因此可能倾向于使用较小的资源配额和更宽松的限制策略。测试环境则需要反映生产环境的配置,以便于进行准确的测试。而生产环境则需要最严格、最优化的资源管理策略,以确保系统的稳定和性能。
在Kubernetes中,可以通过命名空间(Namespace)来隔离不同环境。每个命名空间可以有不同的资源配额和限制,这样可以为每个环境提供独立的资源视图。例如,通过定义命名空间级别的资源配额,可以限制开发环境中的资源使用,确保资源不会被无节制地消耗。
### 5.2.2 资源配额与环境隔离的最佳实践
资源配额(Resource Quotas)是Kubernetes中实现环境资源隔离的核心机制。通过为每个命名空间设置资源配额,可以限制该命名空间下所有资源的总和,比如CPU、内存和存储等。这样可以防止某个环境的资源使用对其他环境造成影响。
在实际操作中,最佳实践包括:
- **设置命名空间级别的资源配额**:对于不同的环境如开发、测试和生产,根据其业务需求和容量规划,设置合适的资源配额。
- **使用LimitRange限制单个Pod资源**:LimitRange可以帮助管理员为命名空间内所有Pod设置默认资源限制,也可以限制最小和最大资源请求。
- **资源配额监控和分析**:持续监控资源使用情况,并根据实际用量调整资源配额策略。
- **使用准入控制器(Access Control)进行安全隔离**:使用Kubernetes的准入控制器,比如Network Policies,可以进一步对不同命名空间的网络通信进行控制和隔离。
为了实现这些最佳实践,可以使用如下的YAML文件来设置资源配额:
```yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: dev-quota
spec:
hard:
requests.cpu: "1000m"
requests.memory: 2Gi
limits.cpu: "2000m"
limits.memory: 4Gi
```
以上YAML文件为开发环境设置了一个资源配额,确保该环境的资源使用不超过CPU 1000m,内存2GB的请求和CPU 2000m,内存4GB的限制。
## 5.3 案例研究:大规模集群资源优化
### 5.3.1 资源优化前后对比分析
在大规模集群资源优化案例中,我们首先要进行的是全面的资源使用现状分析。这通常包括资源请求和限制的设置,以及集群资源利用率的度量。通过Kubernetes的 Metrics Server 和自定义的监控图表,管理员可以获取到各个资源的实时使用数据。
在实施优化之前,需要进行以下步骤的分析:
1. **度量并记录每个Pod的CPU和内存使用**:通过 Metrics Server 收集数据,绘制时间序列图来观察资源使用的变化趋势。
2. **识别资源使用不均衡的情况**:分析数据,查找是否存在资源浪费或资源争夺的情况。
3. **设定合理的资源请求和限制**:为每个Pod分配合适的资源请求和限制,以避免资源不足或过度分配。
优化实施后,对比优化前后的数据,可以看到资源利用率的提高和成本的节约。例如,经过调整Pod资源限制,可以减少因资源不足导致的Pod异常重启,从而提高服务的稳定性。
### 5.3.2 优化过程中的关键决策点
在大规模集群资源优化过程中,关键决策点包括:
1. **自动伸缩的策略选择**:考虑是否使用HPA(Horizontal Pod Autoscaler)进行自动扩展,以及如何设置合适的伸缩阈值。
2. **资源配额的动态调整**:根据实时监控数据,动态调整资源配额,以适应不断变化的工作负载。
3. **应用资源优化**:对应用进行压力测试,识别瓶颈,优化应用代码或配置以减少资源消耗。
4. **基础设施优化**:评估是否需要升级硬件或改进集群的底层基础设施,以更好地支持资源密集型应用。
5. **备份与恢复策略的调整**:根据资源优化后的配置,更新备份策略,确保数据的安全和业务的连续性。
例如,通过使用Cluster Autoscaler,可以根据Pod的CPU和内存使用情况动态调整节点数量。当集群资源不足时,Cluster Autoscaler会自动添加节点,而资源过剩时则会移除不必要的节点。这样不仅提高了资源利用率,同时也降低了成本。
为了更好地说明决策过程,我们可以创建一个mermaid流程图来描述资源优化的决策流程:
```mermaid
graph LR
A[开始资源优化] --> B[收集资源使用数据]
B --> C[分析资源使用模式]
C --> D[确定资源限制和请求]
D --> E[实施资源限制和请求优化]
E --> F[监控优化后的资源使用]
F --> G{是否需要进一步调整?}
G -- 是 --> D
G -- 否 --> H[结束资源优化]
```
这个流程图展示了优化过程中的主要步骤和决策点,确保了优化过程的连续性和动态性。
# 6. Kubernetes资源管理的未来趋势
Kubernetes作为一个持续演进的容器编排平台,它的未来趋势和新特性对于IT行业具有重要的指导意义。接下来,让我们深入了解Kubernetes资源管理的未来走向,并探讨在云原生环境下,资源管理的挑战以及未来发展的技术方向。
## 6.1 Kubernetes资源管理的新特性
Kubernetes社区持续活跃,不断地在各个版本中推出新特性以增强其功能。本节我们将探索最新的版本中引入的新特性,以及社区对于资源管理未来发展的新提案。
### 6.1.1 Kubernetes 1.20及以后版本的新特性
Kubernetes 1.20版本之后的更新中,一些核心资源的管理和调度能力得到了增强。例如:
- **Ephemeral Containers**: 为用户提供了一种临时调试Pod的方法,它允许用户在现有的Pod中添加一个临时的容器,而不必修改Pod的配置。
- **Pod Overhead**: 此特性允许集群管理员为Pod指定额外资源消耗的配置,这对于资源预算和费用计算很有用。
- **Topology Aware Hints**: 这是一个Beta特性,它允许调度器更智能地了解拓扑结构,并做出更佳的调度决策。
### 6.1.2 社区对于资源管理的新提案
社区针对资源管理提出的新的API和特性,其中包括:
- **Vertical Pod Autoscaler (VPA)**: 自动调整Pod的CPU和内存需求。
- **Pod Resource Policy**: 引入更细粒度的资源控制,包括对Pod内部容器资源使用的限制。
## 6.2 云原生环境下的资源管理
Kubernetes作为云原生计算的基础,其资源管理与云服务提供商的集成程度决定了它的灵活性和扩展性。
### 6.2.1 与云服务商的集成和扩展性
云服务商如AWS、Azure和GCP都在其云服务中集成了Kubernetes,提供了如EKS、AKS和GKE这样的托管Kubernetes服务。这种集成实现了更好的资源管理:
- **服务发现和负载均衡**: 与云平台提供的服务发现和负载均衡集成,使得资源分配更加高效。
- **弹性资源**: 可以根据需求弹性地增加或减少资源。
### 6.2.2 多云和混合云环境中的资源管理挑战
多云和混合云的配置带来了新的管理挑战:
- **数据一致性**: 如何保持不同云环境中的数据一致性。
- **网络连接**: 不同云服务提供商之间的网络连接配置和优化。
- **安全性**: 在多云环境中保持数据和通信的安全性。
## 6.3 资源管理技术的发展方向
未来资源管理技术的发展将趋向于自动化、智能化,并将更加关注可持续计算。
### 6.3.1 自动化和智能化资源管理展望
自动化和智能化资源管理意味着:
- **智能调度器**: 能够理解工作负载和资源需求,并自动做出最优化的调度决策。
- **预测性分析**: 使用机器学习算法来预测资源需求,并进行相应调整。
### 6.3.2 可持续计算和资源管理的未来趋势
可持续计算与资源管理的结合关注:
- **能源效率**: 优化资源配置,减少能源消耗。
- **资源回收**: 更智能的资源回收机制,比如自动回收未使用或低效使用的资源。
- **绿色计算**: 通过软件优化来减少硬件需求,进一步降低对环境的影响。
这些未来趋势和挑战不仅为开发者和运维人员提供了新的视角,也为整个云计算和容器化领域的发展指明了方向。随着技术的不断进步,我们可以预见Kubernetes将在资源管理方面扮演越来越重要的角色。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Python pip》专栏深入探讨了 Python 包管理工具 pip 的方方面面。从基础知识到高级技巧,专栏涵盖了广泛的主题,包括:
* pip 的深入剖析,揭示其工作原理和最佳实践
* Python 开发者的必备攻略,提供使用 pip 管理依赖项的全面指南
* pipx 工具使用秘籍,介绍了管理 Python 应用程序的强大工具
* pip freeze 与 requirements.txt 的对比,帮助您了解这两种管理依赖项方法之间的差异
* Python pip 升级指南,让您轻松掌握 pip 升级的技巧
* Python pip 性能提升之道,提供优化 pip 安装和使用性能的实用建议
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【时间序列分析】:如何在金融数据中提取关键特征以提升预测准确性

# 1. 时间序列分析基础
在数据分析和金融预测中,时间序列分析是一种关键的工具。时间序列是按时间顺序排列的数据点,可以反映出某
【交互特征的影响】:分类问题中的深入探讨,如何正确应用交互特征

# 1. 交互特征在分类问题中的重要性
在当今的机器学习领域,分类问题一直占据着核心地位。理解并有效利用数据中的交互特征对于提高分类模型的性能至关重要。本章将介绍交互特征在分类问题中的基础重要性,以及为什么它们在现代数据科学中变得越来越不可或缺。
## 1.1 交互特征在模型性能中的作用
交互特征能够捕捉到数据中的非线性关系,这对于模型理解和预测复杂模式至关重要。例如
【复杂数据的置信区间工具】:计算与解读的实用技巧
# 1. 置信区间的概念和意义
置信区间是统计学中一个核心概念,它代表着在一定置信水平下,参数可能存在的区间范围。它是估计总体参数的一种方式,通过样本来推断总体,从而允许在统计推断中存在一定的不确定性。理解置信区间的概念和意义,可以帮助我们更好地进行数据解释、预测和决策,从而在科研、市场调研、实验分析等多个领域发挥作用。在本章中,我们将深入探讨置信区间的定义、其在现实世界中的重要性以及如何合理地解释置信区间。我们将逐步揭开这个统计学概念的神秘面纱,为后续章节中具体计算方法和实际应用打下坚实的理论基础。
# 2. 置信区间的计算方法
## 2.1 置信区间的理论基础
### 2.1.1
探索性数据分析:训练集构建中的可视化工具和技巧
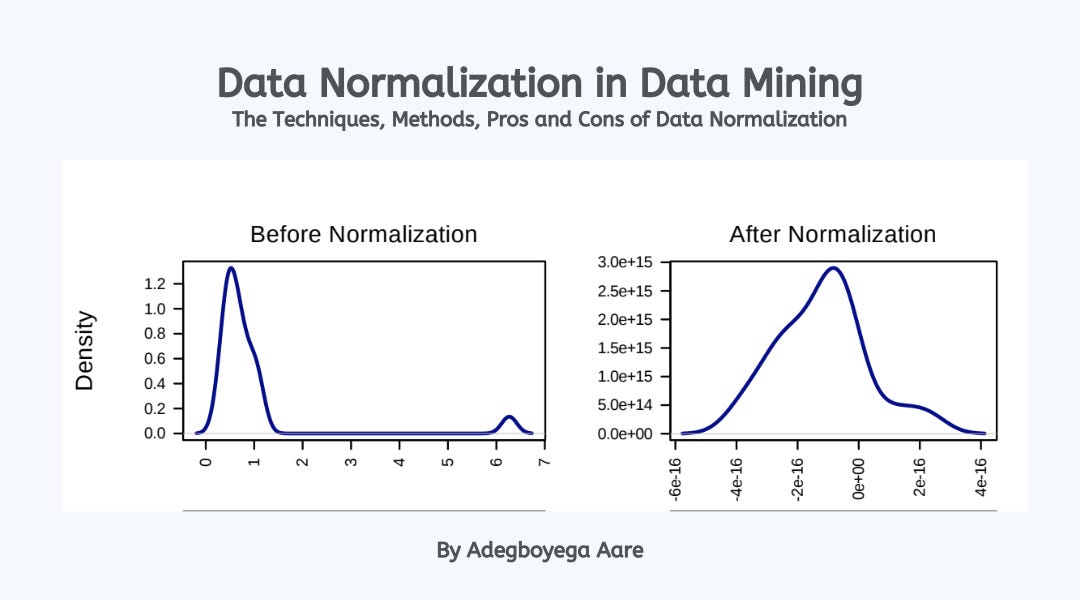
# 1. 探索性数据分析简介
在数据分析的世界中,探索性数据分析(Exploratory Dat
p值在机器学习中的角色:理论与实践的结合

# 1. p值在统计假设检验中的作用
## 1.1 统计假设检验简介
统计假设检验是数据分析中的核心概念之一,旨在通过观察数据来评估关于总体参数的假设是否成立。在假设检验中,p值扮演着决定性的角色。p值是指在原
自然语言处理中的独热编码:应用技巧与优化方法
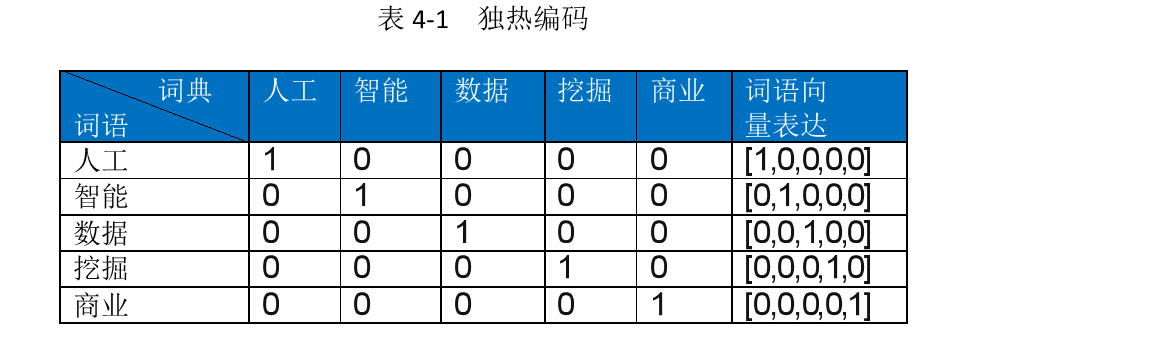
# 1. 自然语言处理与独热编码概述
自然语言处理(NLP)是计算机科学与人工智能领域中的一个关键分支,它让计算机能够理解、解释和操作人类语言。为了将自然语言数据有效转换为机器可处理的形式,独热编码(One-Hot Encoding)成为一种广泛应用的技术。
## 1.1 NLP中的数据表示
在NLP中,数据通常是以文本形式出现的。为了将这些文本数据转换为适合机器学习模型的格式,我们需要将单词、短语或句子等元
测试集在探索性测试中的应用:发现未知的缺陷

# 1. 探索性测试的基本概念和重要性
在软件开发的世界里,探索性测试(Exploratory Testing)是一种结合了测试设计与执行的方法。它允许测试人员在有限的时间内自由地探索软件,发现错误,同时理解产品特性和功能。探索性测试的重
【特征工程稀缺技巧】:标签平滑与标签编码的比较及选择指南
# 1. 特征工程简介
## 1.1 特征工程的基本概念
特征工程是机器学习中一个核心的步骤,它涉及从原始数据中选取、构造或转换出有助于模型学习的特征。优秀的特征工程能够显著提升模型性能,降低过拟合风险,并有助于在有限的数据集上提炼出有意义的信号。
## 1.2 特征工程的重要性
在数据驱动的机器学习项目中,特征工程的重要性仅次于数据收集。数据预处理、特征选择、特征转换等环节都直接影响模型训练的效率和效果。特征工程通过提高特征与目标变量的关联性来提升模型的预测准确性。
## 1.3 特征工程的工作流程
特征工程通常包括以下步骤:
- 数据探索与分析,理解数据的分布和特征间的关系。
- 特
【特征选择工具箱】:R语言中的特征选择库全面解析

# 1. 特征选择在机器学习中的重要性
在机器学习和数据分析的实践中,数据集往往包含大量的特征,而这些特征对于最终模型的性能有着直接的影响。特征选择就是从原始特征中挑选出最有用的特征,以提升模型的预测能力和可解释性,同时减少计算资源的消耗。特征选择不仅能够帮助我
【PCA算法优化】:减少计算复杂度,提升处理速度的关键技术

# 1. PCA算法简介及原理
## 1.1 PCA算法定义
主成分分析(PCA)是一种数学技术,它使用正交变换来将一组可能相关的变量转换成一组线性不相关的变量,这些新变量被称为主成分。
## 1.2 应用场景概述
PCA广泛应用于图像处理、降维、模式识别和数据压缩等领域。它通过减少数据的维度,帮助去除冗余信息,同时尽可能保
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )