拥抱敏捷和可移植性:Oracle实例与数据库容器化实践
发布时间: 2024-07-26 14:35:09 阅读量: 34 订阅数: 36 

# 1. 数据库容器化的理论基础
数据库容器化是一种将数据库软件打包到标准化容器中的技术,使数据库能够在任何支持容器的平台上快速、轻松地部署和管理。容器化提供了许多优势,包括:
- **敏捷性提升:**容器化简化了数据库的部署和管理,使开发人员能够更快地交付新功能和更新。
- **可移植性增强:**容器化使数据库可以跨不同的平台和环境轻松移动,从而提高了可移植性。
# 2. Oracle实例容器化的实践指南
### 2.1 容器化环境的搭建和配置
#### 2.1.1 Docker容器引擎的安装和使用
**Docker安装**
1. 在目标服务器上安装Docker引擎:
```bash
sudo apt-get update
sudo apt-get install docker.io
```
2. 验证Docker安装:
```bash
docker --version
```
**Docker镜像管理**
1. 拉取官方Oracle数据库镜像:
```bash
docker pull oracle/database:19.3.0-ee
```
2. 查看本地镜像列表:
```bash
docker images
```
3. 删除本地镜像:
```bash
docker rmi oracle/database:19.3.0-ee
```
#### 2.1.2 Kubernetes集群的部署和管理
**Kubernetes集群部署**
1. 使用Kubeadm部署Kubernetes集群:
```bash
kubeadm init --pod-network-cidr=10.244.0.0/16
```
2. 加入其他节点:
```bash
kubeadm join 192.168.1.100:6443 --token 1234567890abcdef --discovery-token-ca-cert-hash sha256:1234567890abcdef
```
**Kubernetes集群管理**
1. 查看集群信息:
```bash
kubectl get nodes
kubectl get pods --all-namespaces
```
2. 创建和管理命名空间:
```bash
kubectl create namespace oracle-db
kubectl get namespaces
```
3. 部署和管理应用程序:
```bash
kubectl create deployment oracle-db --image=oracle/database:19.3.0-ee
kubectl get deployments
kubectl scale deployment oracle-db --replicas=3
```
### 2.2 Oracle数据库容器化的实现
#### 2.2.1 Oracle容器镜像的创建和管理
**创建自定义Oracle容器镜像**
1. 创建Dockerfile:
```dockerfile
FROM oracle/database:19.3.0-ee
# 安装附加软件包
RUN yum install -y oracle-instantclient19
# 设置环境变量
ENV ORACLE_SID=orcl
ENV ORACLE_PWD=oracle
# 启动Oracle数据库
CMD ["/etc/init.d/oracle-xe", "start"]
```
2. 构建自定义镜像:
```bash
docker build -t my-oracle-db .
```
**管理Oracle容器镜像**
1. 查看本地镜像列表:
```bash
docker images
```
2. 删除本地镜像:
```bash
docker rmi my-oracle-db
```
#### 2.2.2 数据库容器的部署和启动
**部署Oracle数据库容器**
1. 在oracle-db命名空间中部署Oracle数据库容器:
```bash
kubectl create deployment oracle-db --image=my-oracle-db --namespace=oracle-db
```
2. 查看容器状态:
```bash
kubectl get pods --namespace=oracle-db
```
**启动Oracle数据库容器**
1. 进入Oracle数据库容器:
```bash
kubectl exec -it oracle-db-0 --namespace=oracle-db bash
```
2. 启动Oracle数据库:
```bash
/etc/init.d/oracle-xe start
```
3. 验证数据库连接:
```bash
sqlplus sys/oracle@//localhost:1521/orcl
```
### 2.3 容器化数据库的监控和管理
#### 2.3.1 容器化数据库的健康检查
**使用Kubernetes探针**
1. 创建Kubernetes探针:
```yaml
apiVersion: v1
kind: Pod
metadata:
name: oracle-db
namespace: oracle-db
spec:
containers:
- name: oracle-db
image: my-oracle-db
livenessProbe:
httpGet:
path: /healthz
port: 8080
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /readyz
port: 8080
scheme: HTTP
initialDelaySeconds: 15
periodSeconds: 10
timeoutSeconds: 5
```
2. 查看探针状态:
```bash
kubectl get pods --namespace=oracle-db -o jsonpath='{.items[0].status.containerStatuses[0].livenessProbe.lastProbeTime}'
```
**使用外部监控工具**
1. 集成Prometheus和Grafana:
```bash
helm install stable/prometh
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Oracle实例与数据库》专栏深入探讨了Oracle架构的各个方面,从概念解析到最佳实践指南。它涵盖了实例与数据库的管理、维护、性能优化、故障排除、备份与恢复、安全性、监控与诊断、升级与迁移、自动化管理、云端部署、容器化实践以及常见问题解答。专栏还提供了行业专家的宝贵经验和实战案例分析,帮助读者掌握Oracle实例与数据库的精髓,提升数据库效率,保障数据安全,并实现平滑过渡和业务连续性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
JLINK_V8固件烧录故障全解析:常见问题与快速解决

# 摘要
JLINK_V8作为一种常用的调试工具,其固件烧录过程对于嵌入式系统开发和维护至关重要。本文首先概述了JLINK_V8固件烧录的基础知识,包括工具的功能特点和安装配置流程。随后,文中详细阐述了烧录前的准备、具体步骤和烧录后的验证工作,以及在硬件连接、软件配置及烧录失败中可能遇到的常见问题和解决方案
【Jetson Nano 初识】:掌握边缘计算入门钥匙,开启新世界

# 摘要
本论文介绍了边缘计算的兴起与Jetson Nano这一设备的概况。通过对Jetson Nano的硬件架构进行深入分析,探讨了其核心组件、性能评估以及软硬件支持。同时,本文指导了如何搭建Jetson Nano的开发环境,并集成相关开发库与API。此外,还通过实际案例展示了Jetson Nano在边缘计算中的应用,包括实时图像和音频数
MyBatis-Plus QueryWrapper故障排除手册:解决常见查询问题的快速解决方案
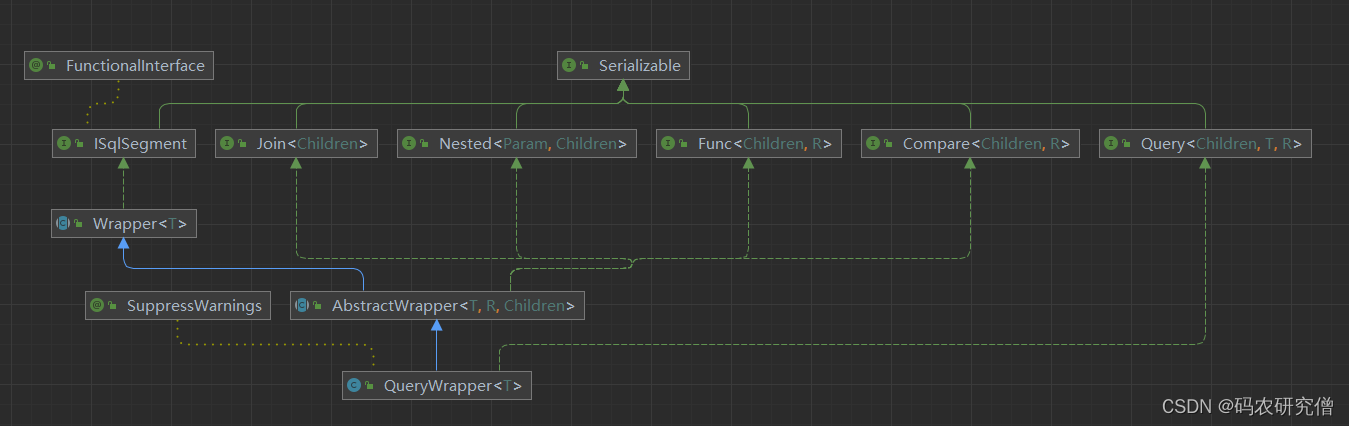
# 摘要
MyBatis-Plus作为一款流行的持久层框架,其提供的QueryWrapper工具极大地简化了数据库查询操作的复杂性。本文首先介绍了MyBatis-Plus和QueryWrapper的基本概念,然后深入解析了QueryWrapper的构建过程、关键方法以及高级特性。接着,文章探讨了在实际应用中查询常见问题的诊断与解决策略,以及在复杂场
【深入分析】SAP BW4HANA数据整合:ETL过程优化策略

# 摘要
SAP BW4HANA作为企业数据仓库的更新迭代版本,提供了改进的数据整合能力,特别是在ETL(抽取、转换、加载)流程方面。本文首先概述了SAP BW4HANA数据整合的基础知识,接着深入探讨了其ETL架构的特点以及集成方法论。在实践技巧方面,本文讨论了数据抽取、转换和加载过程中的优化技术和高级处理方法,以及性能调优策略。文章还着重讲述了ETL过
电子时钟硬件选型精要:嵌入式系统设计要点(硬件配置秘诀)

# 摘要
本文对嵌入式系统与电子时钟的设计和开发进行了综合分析,重点关注核心处理器的选择与评估、时钟显示技术的比较与组件选择、以及输入输出接口与外围设备的集成。首先,概述了嵌入式系统的基本概念和电子时钟的结构特点。接着,对处理器性能指标进行了评估,讨论了功耗管理和扩展性对系统效能和稳定性的重要性。在时钟显示方面,对比了不同显示技术的优劣,并探讨了显示模块设计和电源管理的优化策略。最后,本
【STM8L151电源设计揭秘】:稳定供电的不传之秘

# 摘要
本文对STM8L151微控制器的电源设计进行了全面的探讨,从理论基础到实践应用,再到高级技巧和案例分析,逐步深入。首先概述了STM8L151微控制器的特点和电源需求,随后介绍了电源设计的基础理论,包括电源转换效率和噪声滤波,以及STM8L151的具体电源需求。实践部分详细探讨了适合STM8L151的低压供电解决方案、电源管理策略和外围电源设计。最后,提供了电源设计的高级技巧,包括
NI_Vision视觉软件安装与配置:新手也能一步步轻松入门

# 摘要
本文系统介绍NI_Vision视觉软件的安装、基础操作、高级功能应用、项目案例分析以及未来展望。第一章提供了软件的概述,第二章详细描述了软件的安装流程及其后的配置与验证方法。第三章则深入探讨了NI_Vision的基础操作指南,包括界面布局、图像采集与处理,以及实际应用的演练。第四章着重于高级功能实
【VMware Workstation克隆与快照高效指南】:备份恢复一步到位

# 摘要
VMware Workstation的克隆和快照功能是虚拟化技术中的关键组成部分,对于提高IT环境的备份、恢复和维护效率起着至关重要的作用。本文全面介绍了虚拟机克隆和快照的原理、操作步骤、管理和高级应用,同时探讨了克隆与快照技术在企业备份与恢复中的应用,并对如何
【Cortex R52 TRM文档解读】:探索技术参考手册的奥秘
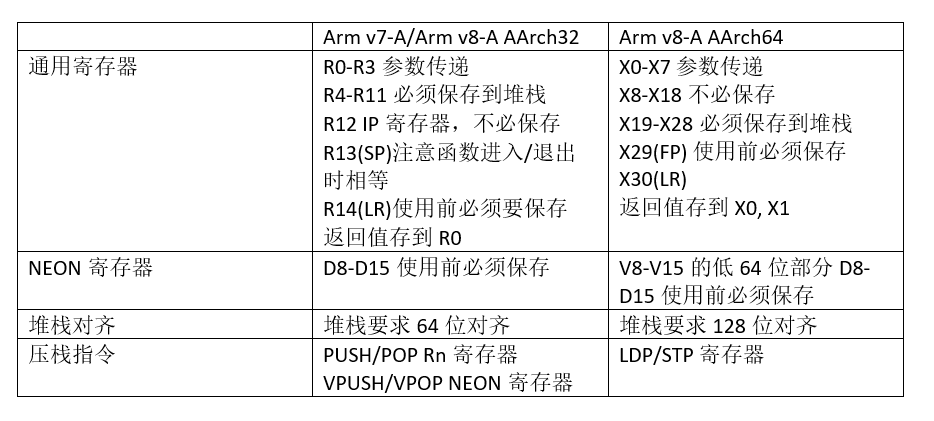
# 摘要
本文深入探讨了Cortex R52处理器的各个方面,包括其硬件架构、指令集、调试机制、性能分析以及系统集成与优化。文章首先概述了Cortex R52处理器的特点,并解析了其硬件架构的核心设计理念与组件。接着,本文详细解释了处理器的执行模式,内存管理机制,以及指令集的基础和高级特性。在调试与性能分析方面,文章介绍了Cortex R52的调试机制、性能监控技术和测试策略。最后,本文探讨了Cortex R52与外部组件的集成,实时操作系统支持,以及在特定应
西门子G120变频器安装与调试:权威工程师教你如何快速上手

# 摘要
西门子G120变频器在工业自动化领域广泛应用,其性能的稳定性与可靠性对于提高工业生产效率至关重要。本文首先概述了西门子G120变频器的基本原理和主要组件,然后详细介绍了安装前的准备工作,包括环境评估、所需工具和物料的准备。接下来,本文指导了硬件的安装步骤,强调了安装过程中的安全措施,并提供硬件诊断与故障排除的方法。此外,本文阐述了软件配置与调试的流程,包括控制面板操作、参数设置、调试技巧以及性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )