【Lucene与Solr架构深度对比】:揭秘两者间的关系与区别
发布时间: 2024-12-29 14:21:05 阅读量: 10 订阅数: 10 

lucene-solr-sandbox:Apache Lucene和Solr开源搜索软件插件模块沙箱
# 摘要
本文旨在深入探讨搜索引擎的基础知识,重点介绍Lucene的架构、核心组件、工作原理及其与Solr的关系与对比。首先,介绍了搜索引擎的基本概念和Lucene的简介。接着,详细阐述了Lucene索引的构建过程、查询处理机制以及性能优化策略。然后,文章转向对Solr的架构和特点的分析,包括其分布式架构、高级查询特性以及用户界面和插件生态。在此基础上,本文对Lucene与Solr在功能、性能以及未来发展趋势方面进行了比较分析。最后,结合实际案例和应用场景,提出了选择Lucene还是Solr的决策指南。本文不仅为读者提供了搜索引擎技术的全面视角,还为技术选型和实施策略提供了实用的指导。
# 关键字
搜索引擎;Lucene;索引构建;查询处理;Solr;性能优化
参考资源链接:[Apache Solr入门与下载指南](https://wenku.csdn.net/doc/799ip3ee4y?spm=1055.2635.3001.10343)
# 1. 搜索引擎基础与Lucene简介
## 1.1 搜索引擎的工作原理
搜索引擎是通过索引来快速检索信息的系统。它基于用户的查询请求,通过预先构建的索引结构快速返回相关数据。搜索引擎一般包括爬虫、索引器、查询处理器和排名算法等核心组件。
## 1.2 Lucene的起源与发展
Apache Lucene是一个高性能、可伸缩的文本搜索库,由Java编写。自从2001年首次发布以来,它就因其强大而灵活的搜索能力受到开发者青睐。它作为一个底层框架,为全文搜索引擎的实现提供了基础支持。
## 1.3 Lucene的应用场景
Lucene广泛应用于各种应用程序的搜索功能中,从简单的文本文件搜索到复杂的大型网站全文搜索。由于其开源的性质,开发者可以自由地修改源代码来适应特定需求,这使其成为一个强大的搜索引擎工具。
```java
// 简单的Lucene代码示例,用于创建索引
IndexWriter writer = new IndexWriter(FSDirectory.open(path), new SimpleAnalyzer(), true);
Document doc = new Document();
doc.add(new Field("content", "The content of the document", Field.Store.YES, Field.Index.ANALYZED));
writer.addDocument(doc);
writer.optimize();
writer.close();
```
在上述代码片段中,展示了如何使用Lucene创建一个简单的索引文件。需要指出的是,代码中的`SimpleAnalyzer`用于分析文档内容,以索引之前对文本进行分词处理。这仅仅是一个基础的例子,Lucene的功能远远超出这一简单操作。在后续章节中,我们将深入了解Lucene的核心组件、构建过程以及索引与查询处理机制。
# 2. Lucene的核心组件与工作原理
Lucene作为一个功能强大的全文搜索引擎库,它提供了许多核心组件以及复杂的工作原理。接下来,我们将深入探讨Lucene的索引构建过程、查询处理机制,以及如何通过定制分词器和优化策略来实现扩展性和性能优化。
## 2.1 Lucene索引的构建过程
### 2.1.1 文档的处理和分析
Lucene的索引构建首先从文档的处理和分析开始。文档处理阶段的核心任务是将原始文本转换成一个适合索引的格式。在此过程中,Lucene使用分词器(Tokenizer)来拆分文本成独立的词汇(Tokens)。分词器的选择和配置对于索引的质量至关重要。
Lucene提供了多种内置的分词器,如标准分词器、简单分词器、停词分词器等。除了使用内置分词器,开发者还可以创建自定义分词器来满足特定的需求,例如处理特定语言或者特定领域的文本。
```java
// 示例代码:创建一个简单的自定义分词器
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.standard.StandardTokenizer;
public class CustomAnalyzer extends Analyzer {
@Override
protected TokenStreamComponents createComponents(String fieldName) {
final StandardTokenizer src = new StandardTokenizer();
TokenStream tok = new CustomFilter(src);
return new TokenStreamComponents(src, tok) {
@Override
protected void setReader(Reader reader) {
super.setReader(reader);
}
};
}
}
```
在上述代码中,`CustomAnalyzer`继承自Lucene的`Analyzer`类,并重写了`createComponents`方法。在这个方法中,使用了`StandardTokenizer`作为基础分词器,并在之后添加了一个自定义的`CustomFilter`(未展示代码),该过滤器可以在文档分析过程中进一步处理生成的词汇。
### 2.1.2 索引文件的创建和存储
文档分析完成后,下一步是创建索引文件。Lucene利用一系列的索引结构来存储和检索数据,这些结构包括倒排索引(Inverted Index)、词汇表(Vocabulary)、文档号列表(Document Number List)和字段信息(Field Information)等。在索引构建过程中,文档会转化为一系列键值对,其中键是词汇,值是词汇出现的位置信息(例如文档ID、词频、偏移量等)。
```java
// 示例代码:使用IndexWriter将文档添加到索引中
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory;
// 创建文档
Document doc = new Document();
doc.add(new StringField("id", "123", Field.Store.YES));
doc.add(new TextField("content", "Lucene is very easy to use", Field.Store.YES));
// 索引配置
IndexWriterConfig iwc = new IndexWriterConfig();
iwc.setOpenMode(IndexWriterConfig.OpenMode.CREATE_OR_APPEND);
// 索引目录
Directory dir = new RAMDirectory();
// 创建并配置IndexWriter
IndexWriter writer = new IndexWriter(dir, iwc);
writer.addDocument(doc); // 添加文档到索引
// 关闭writer释放资源
writer.close();
```
在这段代码中,首先创建了一个包含字段的`Document`对象。每个字段通过`Field`类的不同构造器被添加到文档中。接着,创建了`IndexWriter`对象并配置它来添加文档到索引。这里使用了`RAMDirectory`,这意味着索引将被存储在内存中,这在开发和测试环境中很有用,因为处理速度快。在生产环境中,通常会使用基于磁盘的目录,如`FSDirectory`。
## 2.2 Lucene的查询处理机制
### 2.2.1 查询语言的解析
Lucene支持一种灵活的查询语言,允许用户通过特定的查询表达式来精确地搜索索引。查询表达式可以非常简单,如关键词搜索,也可以包含多个条件、布尔运算符、通配符和短语搜索等复杂查询。
```java
// 示例代码:使用IndexSearcher进行关键词查询
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import java.io.IOException;
public class SearcherExample {
public static void main(String[] args) throws IOException {
// 假设dir是之前构建的索引目录
Directory dir = ...;
// 创建DirectoryReader并打开它
DirectoryReader reader = DirectoryReader.open(dir);
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询
Query query = new QueryParser("content", analyzer).parse("search terms");
// 执行查询并获取命中结果
TopDocs docs = searcher.search(query, 10);
ScoreDoc[] hits = docs.scoreDocs;
// 输出结果
for (ScoreDoc hit : hits) {
Document doc = searcher.doc(hit.doc);
System.out.println("Score: " + hit.score + ", " + doc.get("id"));
}
// 关闭reader释放资源
reader.close();
}
}
```
在上述代码中,使用`IndexSearcher`和`QueryParser`来构建并执行一个简单的关键词查询。`QueryParser`的构造函数中需要提供字段名(用于搜索的字段)和分析器(用于分析查询语句的分词器)。查询通过`parse`方法解析用户输入的查询字符串,然后`IndexSearcher`使用这个查询来搜索索引并返回结果。
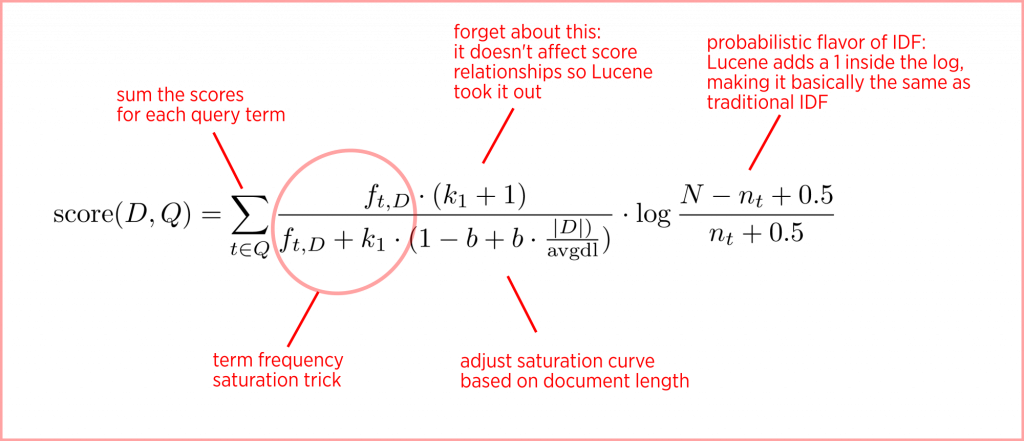
### 2.2.2 排序、过滤与评分
除了关键词搜索之外,Lucene还允许对搜索结果进行排

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Solr 下载合集,您的企业级搜索引擎构建指南。本专栏汇集了全面且深入的教程,涵盖 Solr 的各个方面,从初学者指南到高级优化技术。无论您是刚接触 Solr 还是经验丰富的开发人员,本专栏都将为您提供构建和管理高效、可扩展且安全的搜索解决方案所需的所有知识。从部署和索引管理到搜索性能优化和集群搭建,本专栏将带您踏上从零到英雄的 Solr 之旅。此外,您还将深入了解 Solr 与 Lucene 的关系、数据安全策略、查询解析器和云环境中的部署与优化。通过本专栏,您将掌握 Solr 的精髓,并构建出满足您业务需求的强大搜索引擎。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【深入剖析STC12C5A60S2】:工作原理深度解读及其高级应用
# 摘要
STC12C5A60S2微控制器作为一款功能强大的8051系列单片机,广泛应用于嵌入式系统开发中。本文首先对STC12C5A60S2进行概述,随后详细解读其硬件架构,包括CPU核心、内存管理、I/O端口、外设接口以及时钟系统和电源管理策略。接着,探讨了软件开发环境,包括开发工具、编译器选择、程序下载、调试技术以及实时时钟和中断管理。在编程实践部分,通过基础外设操作、高级功能模块应用、性能优化与故障诊断的实践案例,展示了如何有效利用STC12C5A60S2的特性。最后,讨论了该微控制器在嵌入式系统中的应用,强调了设计原则、资源管理、典型应用案例以及安全性与可靠性设计的重要性,为工程技术
【信号处理与传输】:TP9950芯片,视频监控的传输保障
# 摘要
本文首先介绍了信号处理与传输的基础知识,随后详细探讨了TP9950芯片的技术规格、性能参数和在视频监控系统中的应用。通过对信号处理理论的阐述和实际应用案例分析,本文揭示了实时视频信号处理和传输过程中的关键技术和挑战,特
紧急疏散秘籍:AnyLogic行人流动模拟在危机中的应用

# 摘要
本文深入探讨了紧急疏散的理论基础以及AnyLogic软件在行人流动模拟中的应用和实践。首先介绍了紧急疏散模拟的重要性及其理论基础,然后详细阐述了A
【空间数据校正秘籍】:精通ERDAS 9.2精确制图技术
# 摘要
本文详细介绍了ERDAS 9.2在空间数据校正方面的应用,涵盖从基础知识到高级技巧的完整流程。首先,概述了ERDAS 9.2的基本功能及其在空间校正中的重要性,随后深入分析了空间校正工具的使用和相关的数学模型与算法。文章接着讨论了高级校正技术,包括精准定位、链式校正以及误差分析等关键环节。在实践应用部分,本文通过具体案例展示了ERDAS 9
华为API管理策略:促进服务共享与创新的有效途径

# 摘要
华为API管理策略是一套全面的方案,旨在提升服务共享、创新推动和API安全。本文概述了华为API管理的策略,并从理论和实践两个角度进行了深入分析。通过华为API市场和服务共享平台的实际案例,展示了其在服务共享和创新项目孵化中的应用。文章还讨论了API技术标准、API网关与微服务架构的结合,以及API性能优化与监控的实践。此外,本文对华为API管理策略的未来展望进行了探
【编译原理深度解析】:词法与语法分析的六大误区及解决策略
# 摘要
本文详细探讨了编译原理中词法与语法分析的重要性及其实施中的常见误区和解决策略。通过分析字符集和编码选择、正则表达式的合理使用以及状态机设计等关键点,本研究提出了提升词法分析准确性的具体方法。随后,针对语法分析部分,文章识别并解决了混淆BNF与EBNF、性能问题及错误恢复机制不足等误区,并
RDPWrap-v1.6.2性能分析:多用户环境下的表现与优化策略

# 摘要
RDPWrap-v1.6.2作为一款在多用户环境中提供远程桌面协议(RDP)支持的软件,通过其创新的核心机制,实现了多用户的并发管理及系统优化。本文全面解析了RDPWrap-v1.6.2的工作原理,包括其系统架构、组件功能以及如何处理RDP通信协议和会话管理。同时,研究了用户认证、授权机制
【Allegro实战突破】:一小时快速解决设计冲突,提高设计效率
# 摘要
本文系统介绍了Allegro PCB设计的全面知识体系,从基础入门到高级应用,涵盖了设计工具的掌握、设计冲突的解析、设计流程的优化,以及高级功能的应用。通过对界面布局、元件封装设计、原理图绘制基础、设计冲突类型及其预防和解决策略的详细阐述,为PCB设计者提供了一套完善的学习路径。此外,文中还探讨了Allegro在高密度互联板设计中的应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )