【深入理解OpenID Consumer】:揭秘Python库的架构与工作机制(专家版)
发布时间: 2024-10-15 02:58:41 阅读量: 23 订阅数: 31 

Python库 | plone.app.openid-2.1.0.zip
# 1. OpenID Consumer概述
## 概念与起源
OpenID Consumer是实现OpenID协议的客户端组件,它允许用户使用单一的身份验证系统访问多个网站和服务。该技术的目标是简化用户的身份认证过程,提高用户体验,同时增强安全性。
## 技术背景
OpenID协议是由OpenID Foundation维护的一种开放标准,它允许多个服务共享同一身份验证机制。该协议的发展历程中,它从简单的HTTP协议扩展到了OAuth 2.0等更复杂的认证协议。
## OpenID Consumer的角色
OpenID Consumer在身份验证流程中扮演关键角色,它负责向OpenID Provider发送验证请求,并处理返回的身份验证结果。这一过程对终端用户而言是透明的,但对开发者来说,理解这一过程对于构建安全可靠的应用至关重要。
# 2. OpenID协议基础
OpenID协议是一个开放的身份验证协议,它允许用户使用单一的账户登录到不同的网站和服务。在本章节中,我们将深入探讨OpenID协议的基础知识,包括其主要概念、工作原理以及发展历程。
## 2.1 OpenID协议的主要概念
### 2.1.1 身份认证流程简介
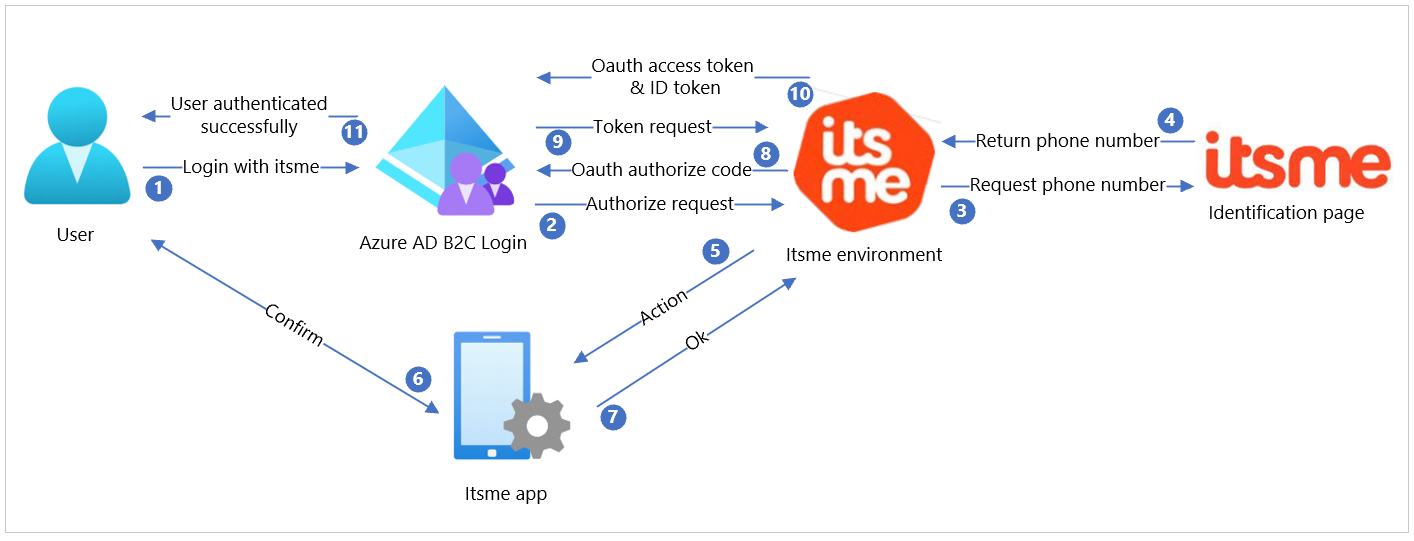
OpenID身份认证流程通常涉及三方:用户、OpenID提供者(OpenID Provider, OP)和信赖方(Relying Party, RP)。用户的OpenID通常是一个可公开访问的URL或者一个XRI(可扩展资源标识符)。以下是OpenID认证的基本步骤:
1. 用户访问信赖方网站。
2. 信赖方网站发现用户的OpenID标识符。
3. 信赖方网站向OpenID提供者发送身份验证请求。
4. 用户在OpenID提供者网站上进行身份验证。
5. OpenID提供者向信赖方发送身份验证响应。
6. 信赖方验证身份并授权用户访问。
### 2.1.2 OpenID的鉴别机制
OpenID的鉴别机制主要基于以下几种技术:
1. **HTTP重定向**:OpenID使用HTTP重定向来传递验证请求和响应。
2. **数字签名**:使用公钥/私钥机制对消息进行签名,确保消息的完整性和来源验证。
3. **加密**:对于敏感信息,如用户的认证信息,使用加密技术进行保护。
4. **信息摘要**:通过哈希算法生成信息的摘要,用于验证信息的完整性和一致性。
## 2.2 OpenID协议的工作原理
### 2.2.1 用户注册与身份识别
用户首先需要在某个OpenID提供者网站注册账户,并选择一个OpenID标识符。一旦用户注册,OpenID提供者会为其生成必要的密钥对(公钥和私钥),并存储在提供者的服务器上。
### 2.2.2 安全性考虑与最佳实践
安全性是OpenID协议的关键部分。以下是一些最佳实践:
1. **使用HTTPS**:为了保护用户数据的安全,所有OpenID的通信都应该通过HTTPS进行。
2. **密钥管理**:私钥必须安全存储,并且只有OpenID提供者知道。
3. **第三方身份验证**:信赖方可以使用第三方身份验证服务来验证OpenID提供者的身份。
4. **用户教育**:教育用户关于OpenID的优势和潜在风险,鼓励他们使用强密码和双因素认证。
## 2.3 OpenID协议的发展与版本
### 2.3.1 历史版本回顾
OpenID协议自2005年发布以来,经历了多个版本的迭代。从OpenID 1.0到OpenID 2.0,每个版本都在改进用户体验和安全性。OpenID 2.0引入了更多的安全特性,如双向SSL加密,使得协议更加可靠。
### 2.3.2 现行版本特点与比较
目前,OpenID Connect是基于OAuth 2.0协议的最新身份层,它提供了以下特点:
1. **简洁的身份层**:OpenID Connect在OAuth 2.0之上添加了一个身份层。
2. **易于集成**:与OAuth 2.0相比,OpenID Connect提供了更简单的集成方式。
3. **可扩展性**:OpenID Connect支持自定义声明,使得它可以根据不同的应用场景进行扩展。
接下来,我们将深入探讨Python库的架构,包括其模块结构、代码实现以及配置与定制。这将为理解OpenID Consumer的工作机制打下坚实的基础。
# 3. Python库架构详解
在本章节中,我们将深入探讨Python库的架构,包括模块结构、代码实现以及配置与定制。我们将通过详细的代码示例、配置文件解析以及定制化开发的策略,来展示如何构建和优化Python库,以便更好地服务于Python应用的开发。
## 3.1 Python库的模块结构
### 3.1.1 核心模块功能解析
Python库的核心模块是构建库功能的基础,它定义了库的核心功能和接口。核心模块通常包含以下几个部分:
- **初始化模块** (`__init__.py`):这个文件通常为空,但它的存在将一个目录标记为Python包。
- **主要功能模块**:这些模块提供了库的主要功能,例如数据处理、算法实现等。
- **辅助模块**:这些模块提供辅助功能,如日志记录、错误处理等。
核心模块的设计需要考虑可读性、可维护性和性能。例如,一个核心模块可能包含以下代码:
```python
# __init__.py
from .module_a import function_a
from .module_b import function_b
__all__ = ['function_a', 'function_b']
```
### 3.1.2 扩展模块与插件机制
扩展模块允许用户根据需要添加额外的功能,而不需要修改核心模块的代码。插件机制则是一种特殊的扩展方式,它允许第三方开发者贡献额外的功能,这些功能可以通过某种机制被核心库识别和加载。
```python
# extension.py
def plugin_function():
print("This is a plugin function.")
```
在核心库中,可以通过动态导入来加载插件:
```python
# core.py
def load_plugin(plugin_name):
try:
module = __import__(plugin_name)
module.plugin_function()
except ImportError:
print(f"Plugin {plugin_name} not found.")
```
## 3.2 Python库的代码实现
### 3.2.1 核心类与方法介绍
核心类是库功能的实现基础,它通常包含一些核心方法,这些方法提供了库的主要功能。例如,一个数据处理库可能有一个核心类,包含了数据处理的常用方法。
```python
# core.py
class DataProcessor:
def __init__(self, data):
self.data = data
def process(self):
# 处理数据的逻辑
return processed_data
```
### 3.2.2 代码组织与模块化策略
代码组织和模块化是提高代码可维护性和可读性的关键。良好的模块化策略可以帮助开发者更好地管理代码,使其更加模块化,易于测试和维护。
```python
# main.py
import core
import extensions
def main():
data_processor = core.DataProcessor(data)
processed_data = data_processor.process()
extensions.plugin_function()
```
## 3.3 Python库的配置与定制
### 3.3.1 配置文件解析
配置文件是Python库中常见的组件,它允许用户通过外部文件来配置库的行为,而不需要修改代码。例如,使用`json`、`yaml`或`ini`文件来存储配置信息。
```json
// config.json
{
"api_key": "your_api_key",
"timeout": 30
}
```
在Python代码中,可以使用`json`库来解析配置文件:
```python
import json
with open('config.json') as config_***
***
```
### 3.3.2 定制化开发与接口
定制化开发是Python库灵活性的体现,它允许用户根据自己的需求定制库的行为。这通常通过提供可选的接口或者钩子函数来实现。
```python
# core.py
class CustomizableDataProcessor:
def __init__(self, data, **options):
self.data = data
self.options = options
def process(self):
if self.options.get('custom_method'):
return self.options['custom_method'](self.data)
# 默认处理数据的逻辑
return processed_data
```
通过本章节的介绍,我们了解了Python库的模块结构、代码实现以及配置与定制。这些内容对于构建一个强大、灵活且易于维护的Python库至关重要。在下一章中,我们将探讨OpenID Consumer的工作机制,深入了解其身份认证流程的细节以及性能优化策略。
# 4. OpenID Consumer的工作机制
OpenID Consumer是实现OpenID协议的关键组件,它负责处理用户的身份验证请求,与OpenID Provider交互,并最终完成用户的身份验证过程。在本章节中,我们将深入探讨OpenID Consumer的工作机制,包括身份认证流程的细节、错误处理与异常管理以及性能优化策略。
## 4.1 身份认证流程细节
身份认证是OpenID Consumer的核心功能之一。本节将详细介绍身份认证流程的每个步骤,包括请求发现与重定向、身份验证与断言生成。
### 4.1.1 请求发现与重定向
在OpenID认证流程的开始,Consumer需要向用户的浏览器发送一个身份验证请求。这个请求通常包含用户的标识符和Consumer的地址等信息。Consumer的实现代码示例如下:
```python
# Python代码示例:请求发现与重定向
import requests
def discovery_request(user_identifier):
discovery_url = "***"
response = requests.get(discovery_url)
configuration = response.json()
provider_url = configuration['authorization_endpoint']
redirect_url = f"{provider_url}?response_type=code&client_id=your_client_id&redirect_uri={urllib.parse.quote('***')}&scope=openid&state=state_string&nonce=nonce_value&user_identifier={urllib.parse.quote(user_identifier)}"
return redirect(redirect_url)
```
在这段代码中,我们首先使用HTTP GET请求向OpenID Provider的发现端点发送请求,获取其配置信息。然后,我们根据这些信息构建一个重定向URL,该URL将用户浏览器重定向到Provider的授权端点。
### 4.1.2 身份验证与断言生成
用户在Provider端完成身份验证后,Provider会将用户重定向回Consumer的回调地址,并携带一个授权码。Consumer接收到授权码后,需要使用这个授权码去Provider处交换一个身份验证断言。这个过程通常涉及以下几个步骤:
1. Consumer向Provider发送一个包含授权码的请求,请求一个ID Token或其他形式的身份验证断言。
2. Provider验证请求的授权码,并返回一个ID Token或身份验证断言。
3. Consumer验证返回的ID Token或断言的有效性。
Python代码示例如下:
```python
# Python代码示例:身份验证与断言生成
import requests
import jwt
def authentication_assertion(auth_code, redirect_uri, client_id, client_secret):
token_url = "***"
data = {
'grant_type': 'authorization_code',
'code': auth_code,
'redirect_uri': redirect_uri,
'client_id': client_id,
'client_secret': client_secret,
}
response = requests.post(token_url, data=data)
token_response = response.json()
id_token = token_response['id_token']
claims = jwt.decode(id_token, verify=False)
return claims
```
在这段代码中,我们首先向Provider的令牌端点发送一个POST请求,包含了授权码、重定向URI、客户端ID和客户端密钥等信息。然后,我们解码ID Token以获取其中声明的用户信息。
## 4.2 错误处理与异常管理
在身份认证过程中,可能会遇到各种错误和异常情况。本节将介绍错误类型与处理机制,以及异常捕获与日志记录的实践。
### 4.2.1 错误类型与处理机制
OpenID协议定义了一系列的错误响应,例如:
- `invalid_request`:请求无效。
- `unauthorized_client`:客户端未授权。
- `access_denied`:访问被拒绝。
- `invalid_client`:客户端认证失败。
Python代码示例如下:
```python
# Python代码示例:错误类型与处理机制
def handle_error(error_response):
if error_response.get('error') == 'access_denied':
# 处理访问被拒绝的情况
print("Access denied.")
else:
# 其他错误处理
print("An error occurred:", error_response.get('error_description'))
```
在这段代码中,我们根据错误响应中的`error`字段来判断错误类型,并执行相应的处理逻辑。
### 4.2.2 异常捕获与日志记录
为了确保系统的稳定性,我们应该对身份认证过程中的异常进行捕获,并记录日志。Python代码示例如下:
```python
# Python代码示例:异常捕获与日志记录
import logging
def setup_logging():
logging.basicConfig(level=***)
def authenticate_user(user_identifier):
try:
# 请求发现与重定向
# ...
# 身份验证与断言生成
# ...
return claims
except Exception as e:
logging.error("Authentication error", exc_info=True)
raise e
```
在这段代码中,我们首先配置了日志记录器,然后在身份认证的函数中使用了try-except语句来捕获异常,并记录错误信息。
## 4.3 OpenID Consumer的性能优化
OpenID Consumer的性能对于用户体验至关重要。本节将介绍缓存策略与实践,以及异步处理与并发优化的实践。
### 4.3.1 缓存策略与实践
为了提高性能,我们可以采用缓存策略来存储常用的OpenID Provider信息和已验证的身份断言。Python代码示例如下:
```python
# Python代码示例:缓存策略与实践
from functools import lru_cache
import requests
@lru_cache(maxsize=100)
def get_provider_configuration(provider_url):
response = requests.get(provider_url)
return response.json()
def discovery_request(user_identifier):
# 使用缓存获取Provider配置
discovery_url = "***"
configuration = get_provider_configuration(discovery_url)
# ...
```
在这段代码中,我们使用了`functools.lru_cache`装饰器来缓存最多100个Provider配置。这样,当我们多次请求相同的Provider配置时,可以直接从缓存中获取,而无需再次发送HTTP请求。
### 4.3.2 异步处理与并发优化
为了提高并发处理能力,我们可以使用异步编程技术。Python代码示例如下:
```python
# Python代码示例:异步处理与并发优化
import aiohttp
import asyncio
async def async_discovery_request(user_identifier):
async with aiohttp.ClientSession() as session:
discovery_url = "***"
async with session.get(discovery_url) as response:
configuration = await response.json()
# ...
return configuration
```
在这段代码中,我们使用了`aiohttp`库来发起异步的HTTP请求。我们使用`asyncio`库创建了一个事件循环,并在这个循环中执行异步的HTTP请求。这样可以使得我们的程序能够同时处理多个请求,提高并发性能。
## 4.4 总结
在本章节中,我们深入探讨了OpenID Consumer的工作机制,包括身份认证流程的细节、错误处理与异常管理以及性能优化策略。我们通过具体的Python代码示例和实践,展示了如何实现这些功能。通过本章节的介绍,读者应该对OpenID Consumer有了更深入的理解,并能够根据这些知识构建自己的OpenID Consumer实现。
# 5. OpenID Consumer的实战应用
## 5.1 实战案例分析
### 5.1.1 现有应用案例研究
OpenID Consumer在实际应用中,为Web应用提供了一种简洁的身份验证方式。一个典型的案例是社交媒体平台,它允许用户通过OpenID进行身份认证,从而访问其他受保护的资源。例如,一个名为“ExampleNet”的在线论坛,它通过OpenID Consumer与多个身份提供商(如Google, Facebook等)集成,用户可以选择其中任何一个来登录论坛。
在本节中,我们将深入分析一个示例应用的部署流程,包括如何配置OpenID Consumer、如何处理身份验证请求以及如何处理验证响应。我们将通过代码块展示关键的配置和处理逻辑,并提供详细的逻辑分析和参数说明。
### 5.1.2 常见问题与解决方案
在实际部署OpenID Consumer时,开发者可能会遇到各种问题。例如,配置不当可能导致身份验证失败,或者在处理身份验证响应时出现安全漏洞。下面列出了一些常见的问题及其解决方案:
#### 问题1:身份验证失败
**分析**:身份验证失败可能由多种原因引起,包括OpenID Provider的问题、网络问题、配置错误等。
**解决方案**:
1. **检查OpenID Provider状态**:确保OpenID Provider正常运行。
2. **审查网络连接**:确保客户端可以访问OpenID Provider的服务。
3. **检查配置文件**:确保OpenID Consumer的配置文件正确无误。
#### 问题2:安全性漏洞
**分析**:安全漏洞可能由于配置不当、过时的软件版本或不安全的编码实践导致。
**解决方案**:
1. **使用HTTPS**:确保所有传输都是通过加密的HTTPS连接进行。
2. **更新依赖**:定期更新OpenID Consumer库和相关依赖到最新版本。
3. **代码审查**:进行代码审查,确保没有安全漏洞。
## 5.2 安全性考量与最佳实践
### 5.2.1 安全机制与策略
在使用OpenID Consumer时,安全性至关重要。以下是一些安全机制与策略,用于增强OpenID Consumer的安全性:
1. **使用HTTPS**:所有的OpenID请求和响应都应该通过HTTPS进行,以防止中间人攻击。
2. **状态检查**:在处理OpenID响应时,验证请求状态,确保响应是预期的、未经篡改的。
3. **时间戳验证**:验证时间戳,以防止重放攻击。
### 5.2.2 安全测试与漏洞扫描
安全测试和漏洞扫描是确保OpenID Consumer安全的重要步骤。以下是推荐的安全测试实践:
1. **代码审计**:定期进行代码审计,检查潜在的安全漏洞。
2. **漏洞扫描**:使用自动化工具进行漏洞扫描,例如OWASP ZAP、Nessus等。
3. **渗透测试**:进行渗透测试,模拟攻击者的行为,以发现潜在的安全问题。
## 5.3 OpenID Consumer的扩展与维护
### 5.3.1 扩展开发流程
OpenID Consumer的扩展开发流程涉及多个步骤,包括需求分析、设计、开发、测试和部署。以下是一个扩展开发流程的示例:
1. **需求分析**:确定扩展功能的目的和需求。
2. **设计**:设计扩展的架构和接口。
3. **开发**:编写代码实现功能。
4. **测试**:编写测试用例并执行测试。
5. **部署**:将扩展部署到生产环境。
### 5.3.2 系统升级与维护策略
随着技术的发展,OpenID Consumer可能需要定期升级以保持最新状态。以下是一个维护策略的示例:
1. **监控**:监控系统状态和性能指标。
2. **备份**:定期备份系统配置和数据。
3. **更新**:根据最新的安全威胁和补丁进行系统更新。
通过本章节的介绍,我们了解了OpenID Consumer的实战应用,包括案例分析、安全考量以及扩展与维护策略。在实际应用中,开发者需要考虑这些方面,以确保系统的安全性、可靠性和可维护性。
# 6. OpenID Consumer的未来展望
## 6.1 OpenID协议的新趋势
OpenID协议作为互联网身份认证的重要标准之一,其发展趋势和行业应用对整个IT行业有着深远的影响。随着技术的不断进步和安全意识的增强,OpenID协议也在不断地更新迭代,以适应新的需求和技术挑战。
### 6.1.1 最新协议更新与解读
OpenID Connect是OpenID协议的一个重要演进,它基于OAuth 2.0协议,并提供了一种简单身份层。最新版本的OpenID Connect引入了多项新特性,例如:
- **ID Token的增强**:新的ID Token结构提供了更丰富的用户身份信息,支持更多的声明(Claims)。
- **动态客户端注册**:允许客户端在运行时注册,提供了更大的灵活性和动态性。
- **多端点支持**:OpenID Connect允许在一个授权服务器上配置多个端点,以支持不同的需求。
### 6.1.2 行业应用与案例分析
在金融、医疗、教育等行业,OpenID协议的应用已经非常广泛。例如,许多在线银行系统都采用OpenID Connect作为用户身份验证的方式,确保用户在不同服务间可以安全地认证和授权。
**案例分析:**
- **金融机构**:某大型银行通过OpenID Connect实现了一种安全的跨平台用户身份验证机制,用户可以在多个服务之间无缝切换,同时保持了高度的安全性。
- **在线教育平台**:一家在线教育平台使用OpenID Connect为学生和教师提供统一的身份验证服务,简化了用户管理流程,提高了用户体验。
## 6.2 Python库的未来方向
Python作为编程语言,在Web开发、数据分析、人工智能等领域都有着广泛的应用。Python库的未来发展方向主要集中在性能提升、功能增强以及社区支持等方面。
### 6.2.1 性能提升与功能增强
随着Python语言的发展,其标准库和第三方库都在不断地优化和扩展功能。例如,对于异步编程的支持:
- **异步网络库**:`asyncio`库作为Python的核心异步库,正在不断地提升其性能和稳定性。
- **性能基准测试**:使用`pyperformance`等工具对Python库进行性能测试,以确保其性能满足未来的需求。
### 6.2.2 社区发展与支持策略
Python社区是推动Python语言和库发展的重要力量。社区通过开源贡献、文档编写、教程分享等方式,不断地推动Python生态的繁荣。
- **开源贡献**:鼓励开发者参与到开源项目中,通过Pull Request等形式贡献代码。
- **教程与文档**:提供高质量的文档和教程,帮助新用户快速上手,同时也为经验丰富的开发者提供参考。
## 6.3 开源贡献与社区互动
开源项目的发展离不开社区的支持和贡献。在OpenID Consumer以及相关Python库的开发过程中,社区的互动和协作是推动项目成功的关键。
### 6.3.1 如何参与开源贡献
参与开源贡献不仅可以帮助项目改进,还能提升个人的技术能力和影响力。以下是参与开源贡献的一些步骤:
1. **选择项目**:找到感兴趣的OpenID Consumer或Python库项目。
2. **了解贡献指南**:阅读项目的`CONTRIBUTING.md`文件,了解贡献流程和规范。
3. **参与讨论**:在项目的问题跟踪器(Issues)或讨论组(Discussions)中积极参与讨论。
4. **提交代码**:通过Pull Request提交代码或文档的修改。
### 6.3.2 社区交流与协作模式
社区交流和协作模式对于项目的可持续发展至关重要。以下是一些有效的社区交流和协作模式:
- **定期会议**:定期举行开发者会议,讨论项目进展和未来方向。
- **在线协作工具**:使用如GitHub、GitLab、Jira等工具进行项目管理和协作。
- **社区活动**:举办或参与相关的线上或线下活动,如编程马拉松(Hackathon)、技术研讨会等,以增强社区凝聚力。
通过以上的章节内容,我们可以看到OpenID Consumer以及相关Python库的未来发展方向,以及开源项目如何通过社区的协作和贡献来推动技术的进步。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库 openid.consumer,提供了全面的指南,涵盖其架构、工作机制、高级应用、与 OAuth 2.0 的集成、实战演练、代码解读、最佳实践、调试技巧、性能优化、Python 3 中的使用、扩展开发、故障排除、安全审计以及与 REST API 的集成。通过专家见解、代码示例和实战案例,本专栏旨在帮助开发者掌握 openid.consumer,构建安全、高效的身份验证解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
台达触摸屏宏编程:入门到精通的21天速成指南

# 摘要
本文系统地介绍了台达触摸屏宏编程的全面知识体系,从基础环境设置到高级应用实践,为触摸屏编程提供了详尽的指导。首先概述了宏编程的概念和触摸屏环境的搭建,然后深入探讨了宏编程语言的基础知识、宏指令和控制逻辑的实现。接下来,文章介绍了宏编程实践中的输入输出操作、数据处理以及与外部设备的交互技巧。进阶应用部分覆盖了高级功能开发、与PLC的通信以及故障诊断与调试。最后,通过项目案例实战,展现了如何将理论知识应用
信号完整性不再难:FET1.1设计实践揭秘如何在QFP48 MTT中实现

# 摘要
本文综合探讨了信号完整性在高速电路设计中的基础理论及应用。首先介绍信号完整性核心概念和关键影响因素,然后着重分析QFP48封装对信号完整性的作用及其在MTT技术中的应用。文中进一步探讨了FET1.1设计方法论及其在QFP48封装设计中的实践和优化策略。通过案例研究,本文展示了FET1.1在实际工程应用中的效果,并总结了相关设计经验。最后,文章展望了FET
【MATLAB M_map地图投影选择】:理论与实践的完美结合
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/3470884/1024px-Robinson_projection_SW.0.jpg)
# 摘要
M_map工具包是一种在MATLAB环境下使用的地图投影软件,提供了丰富的地图投影方法与定制选项,用
打造数据驱动决策:Proton-WMS报表自定义与分析教程
# 摘要
本文旨在全面介绍Proton-WMS报表系统的设计、自定义、实践操作、深入应用以及优化与系统集成。首先概述了报表系统的基本概念和架构,随后详细探讨了报表自定义的理论基础与实际操作,包括报表的设计理论、结构解析、参数与过滤器的配置。第三章深入到报表的实践操作,包括创建过程中的模板选择、字段格式设置、样式与交互设计,以及数据钻取与切片分析的技术。第四章讨论了报表分析的高级方法,如何进行大数据分析,以及报表的自动化
【DELPHI图像旋转技术深度解析】:从理论到实践的12个关键点

# 摘要
图像旋转是数字图像处理领域的一项关键技术,它在图像分析和编辑中扮演着重要角色。本文详细介绍了图像旋转技术的基本概念、数学原理、算法实现,以及在特定软件环境(如DELPHI)中的应用。通过对二维图像变换、旋转角度和中心以及插值方法的分析
RM69330 vs 竞争对手:深度对比分析与最佳应用场景揭秘

# 摘要
本文全面比较了RM69330与市场上其它竞争产品,深入分析了RM69330的技术规格和功能特性。通过核心性能参数对比、功能特性分析以及兼容性和生态系统支持的探讨,本文揭示了RM69330在多个行业中的应用潜力,包括消费电子、工业自动化和医疗健康设备。行业案例与应用场景分析部分着重探讨了RM69330在实际使用中的表现和效益。文章还对RM69330的市场表现进行了评估,并提供了应
无线信号信噪比(SNR)测试:揭示信号质量的秘密武器!
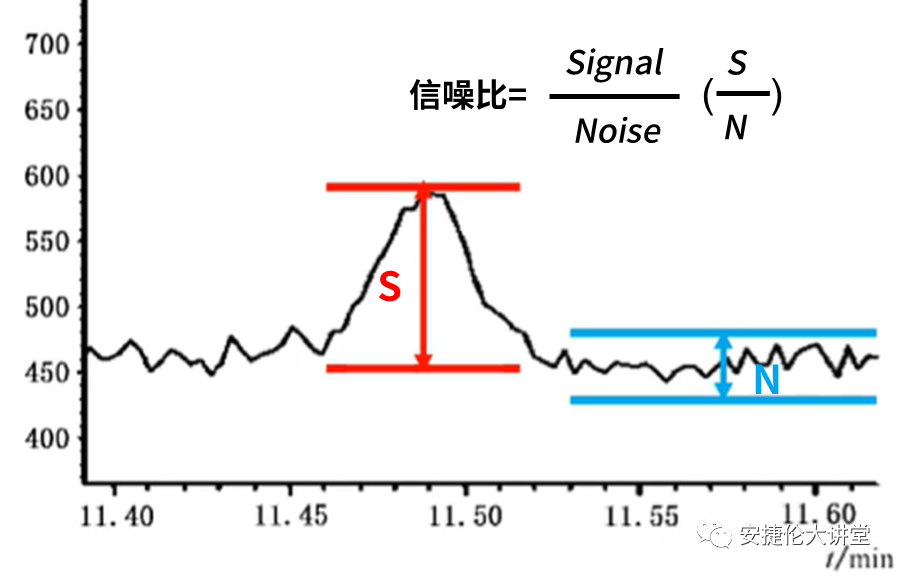
# 摘要
无线信号信噪比(SNR)是衡量无线通信系统性能的关键参数,直接影响信号质量和系统容量。本文系统地介绍了SNR的基础理论、测量技术和测试实践,探讨了SNR与无线通信系统性能的关联,特别是在天线设计和5G技术中的应用。通过分析实际测试案例,本文阐述了信噪比测试在无线网络优化中的重要作用,并对信噪比测试未来的技术发展趋势和挑战进行
【UML图表深度应用】:Rose工具拓展与现代UML工具的兼容性探索
# 摘要
本文系统地介绍了统一建模语言(UML)图表的理论基础及其在软件工程中的重要性,并对经典的Rose工具与现代UML工具进行了深入探讨和比较。文章首先回顾了UML图表的理论基础,强调了其在软件设计中的核心作用。接着,重点分析了Rose工具的安装、配置、操作以及在UML图表设计中的应用。随后,本文转向现代UML工具,阐释其在设计和配置方面的
台达PLC与HMI整合之道:WPLSoft界面设计与数据交互秘笈
# 摘要
本文旨在提供台达PLC与HMI交互的深入指南,涵盖了从基础界面设计到高级功能实现的全面内容。首先介绍了WPLSoft界面设计的基础知识,包括界面元素的创建与布局以及动态数据的绑定和显示。随后深入探讨了WPLSoft的高级界面功能,如人机交互元素的应用、数据库与HMI的数据交互以及脚本与事件驱动编程。第四章重点介绍了PLC与HMI之间的数据交互进阶知识,包括PLC程序设计基础、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )