揭秘中国象棋算法:从入门到精通,解锁棋盘博弈智慧
发布时间: 2024-08-28 11:34:30 阅读量: 66 订阅数: 23 

中国象棋盘面ai识别算法
# 1. 中国象棋概述**
中国象棋,又称中国国际象棋,是一种起源于中国古代的两人策略棋盘游戏。它以其丰富的历史、独特的规则和深奥的策略而闻名。
中国象棋的棋盘由9条纵线和10条横线组成,形成90个交叉点。棋子分为红方和黑方,每方有16枚棋子,包括将(帅)、士(仕)、象(相)、车(俥)、马(傌)、炮(砲)和卒(兵)。
中国象棋的走棋规则相对简单,但策略却非常复杂。棋子只能在棋盘的交叉点上移动,每种棋子都有其独特的移动方式。将(帅)是棋盘上最重要的棋子,如果将(帅)被将军(将死),则游戏结束。
# 2. 中国象棋基本规则与策略
### 2.1 棋盘布局与棋子介绍
中国象棋的棋盘由 9 条竖线和 10 条横线组成,形成 90 个交叉点,称为“格”。棋盘两侧各有一个“九宫”,由 3 条竖线和 4 条横线组成,是将帅的活动范围。
棋子分为两方,红方和黑方,每方各有 16 枚棋子。棋子的种类和数量如下:
| 棋子 | 数量 |
|---|---|
| 将(帅) | 1 |
| 仕(士) | 2 |
| 象(相) | 2 |
| 车(俥) | 2 |
| 马(傌) | 2 |
| 炮(砲) | 2 |
| 兵(卒) | 5 |
棋盘的初始摆放如图所示:
```
楚河 汉界
0 1 2 3 4 5 6 7 8 9
10 卒 卒 卒 卒 卒
9 炮 炮 炮 炮 炮
8 马 马 马 马 马
7 车 车 车 车 车
6 士 士 士 士 士
5 相 相 相 相 相
4 将 将 将 将 将
3 士 士 士 士 士
2 车 车 车 车 车
1 马 马 马 马 马
0 卒 卒 卒 卒 卒
```
### 2.2 走棋规则与基本策略
**走棋规则:**
* 红方先走,双方轮流走棋。
* 棋子只能沿着棋盘上的线走,不能斜走。
* 棋子只能移动到空位或吃掉对方的棋子。
* 将(帅)不能离开九宫。
* 仕(士)只能在九宫内斜线走一步。
* 象(相)只能在九宫内沿对角线走两步,不能过河。
* 车(俥)可以横向或纵向走任意步数。
* 马(傌)走“日”字,先横走或纵走一步,再斜走一步。
* 炮(砲)可以横向或纵向走任意步数,但必须“隔山打牛”,即中间必须有一个棋子。
* 兵(卒)只能向前走一步,过河后可以横向走一步。
**基本策略:**
* 控制中心:棋盘中央的格子是重要的战略位置,控制中心可以限制对方的行动并扩大自己的活动范围。
* 保护将(帅):将(帅)是棋盘上最重要的棋子,必须时刻受到保护。
* 灵活调动棋子:棋子之间要互相配合,灵活调动,避免被对方孤立或围困。
* 攻击对方的弱点:观察对方的棋盘,找出对方的弱点,集中优势兵力进行攻击。
* 避免犯错:走棋时要三思而后行,避免犯下低级错误,给对方可乘之机。
### 2.3 常见开局与中局战术
**常见开局:**
* 过宫炮:将炮移到九宫外,控制中心。
* 屏风马:将马移到九宫前,保护将(帅)。
* 进三兵:将兵进到第三横线,控制中心。
**中局战术:**
* 双炮齐发:利用两门炮的射程优势,对对方进行攻击。
* 马踏连营:利用马的跳跃能力,连续攻击对方的多个棋子。
* 车马炮联动:将车、马、炮配合起来,形成强大的攻击力。
* 过河卒:将兵过河,扩大活动范围,威胁对方的底线。
* 弃子争先:牺牲一枚棋子,换取更大的优势。
# 3.1 棋盘状态表示与评估
**棋盘状态表示**
中国象棋棋盘由 9×10 个格子组成,其中 9×4 个格子为楚河汉界,不可通行。棋子共有 32 枚,分为红方和黑方各 16 枚。
棋盘状态可以用一个 9×10 的二维数组表示,其中每个元素代表该格子的棋子类型。空格子用 0 表示,红方棋子用正整数表示,黑方棋子用负整数表示。
**棋盘评估**
棋盘评估函数的作用是评估当前棋盘状态对某一方的有利程度。一个好的评估函数应该能够准确反映棋盘的形势,为搜索算法提供有用的指导。
常用的棋盘评估函数包括:
* **子力差:**计算红方和黑方的子力差,即红方棋子的价值和减去黑方棋子的价值。
* **位置优势:**评估棋子在棋盘上的位置优势,例如控制中心格、占领重要位置等。
* **活动性:**评估棋子的活动性,即棋子能够移动到的格子数。
* **将军威胁:**评估一方对另一方的将军威胁,包括直接将军和潜在将军。
**评估函数设计**
评估函数的设计需要考虑以下因素:
* **准确性:**评估函数应该能够准确反映棋盘的形势。
* **效率:**评估函数应该能够快速计算,以满足搜索算法的实时性要求。
* **可扩展性:**评估函数应该能够随着棋盘复杂度的增加而扩展,以适应不同的棋局。
### 3.2 搜索算法与剪枝策略
**搜索算法**
搜索算法是象棋算法的核心,其目的是在给定的时间内找到最佳或近似最佳的走法。常用的搜索算法包括:
* **深度优先搜索(DFS):**沿着一条路径一直搜索下去,直到达到目标或搜索深度达到限制。
* **广度优先搜索(BFS):**从根节点开始,逐层搜索所有可能的走法,直到达到目标或搜索深度达到限制。
* **迭代加深搜索(IDS):**将 DFS 算法与 BFS 算法相结合,逐渐增加搜索深度,直到找到目标或搜索深度达到限制。
**剪枝策略**
剪枝策略是一种优化搜索算法的方法,通过剪除不必要的搜索分支来提高搜索效率。常用的剪枝策略包括:
* **α-β剪枝:**利用α-β窗口来剪除不可能产生更好结果的分支。
* **置换表:**存储已经搜索过的棋盘状态,避免重复搜索。
* **历史表:**记录棋盘状态的评估值,避免重新评估相同的棋盘状态。
### 3.3 启发式评估函数设计
**启发式评估函数**
启发式评估函数是一种非精确的评估函数,它利用经验规则和直觉来快速评估棋盘状态。启发式评估函数的设计通常基于以下原则:
* **简单性:**评估函数应该简单易懂,便于实现和调整。
* **鲁棒性:**评估函数应该对棋盘的细微变化不敏感,能够提供稳定的评估结果。
* **相关性:**评估函数应该与棋盘的实际形势相关,能够反映棋盘的优劣。
**常见启发式评估函数**
常用的启发式评估函数包括:
* **加权子力差:**根据不同棋子的价值赋予不同的权重,计算子力差。
* **位置优势:**根据棋子在棋盘上的位置赋予不同的权重,计算位置优势。
* **活动性:**根据棋子能够移动到的格子数赋予不同的权重,计算活动性。
* **将军威胁:**根据一方对另一方的将军威胁赋予不同的权重,计算将军威胁。
# 4.1 深度优先搜索与广度优先搜索
### 深度优先搜索(DFS)
深度优先搜索是一种遍历算法,它从根节点开始,沿着一条路径深度遍历,直到该路径的末尾。如果该路径的末尾不是目标节点,则算法会回溯到上一个未探索的节点,并沿着另一条路径继续深度遍历。
**算法步骤:**
1. 将根节点压入栈中。
2. 只要栈不为空,就弹出栈顶元素并访问它。
3. 将该元素的所有未访问的子节点压入栈中。
4. 重复步骤 2 和 3,直到栈为空或找到目标节点。
**代码示例:**
```python
def dfs(graph, start_node):
stack = [start_node]
visited = set()
while stack:
node = stack.pop()
if node not in visited:
visited.add(node)
print(node)
for neighbor in graph[node]:
if neighbor not in visited:
stack.append(neighbor)
```
**逻辑分析:**
此代码使用栈数据结构来实现深度优先搜索。它从起始节点开始,将其压入栈中。然后,它不断弹出栈顶元素并访问它。如果该元素尚未访问过,则将其添加到已访问集合中并打印出来。接下来,它将该元素的所有未访问过的子节点压入栈中。此过程一直持续到栈为空或找到目标节点。
### 广度优先搜索(BFS)
广度优先搜索也是一种遍历算法,但它与深度优先搜索不同。BFS 从根节点开始,并沿着该层的每个节点进行广度遍历,然后再继续遍历下一层。
**算法步骤:**
1. 将根节点添加到队列中。
2. 只要队列不为空,就弹出队列首元素并访问它。
3. 将该元素的所有未访问的子节点添加到队列中。
4. 重复步骤 2 和 3,直到队列为空或找到目标节点。
**代码示例:**
```python
def bfs(graph, start_node):
queue = [start_node]
visited = set()
while queue:
node = queue.pop(0)
if node not in visited:
visited.add(node)
print(node)
for neighbor in graph[node]:
if neighbor not in visited:
queue.append(neighbor)
```
**逻辑分析:**
此代码使用队列数据结构来实现广度优先搜索。它从起始节点开始,将其添加到队列中。然后,它不断弹出队列首元素并访问它。如果该元素尚未访问过,则将其添加到已访问集合中并打印出来。接下来,它将该元素的所有未访问过的子节点添加到队列中。此过程一直持续到队列为空或找到目标节点。
### DFS 和 BFS 的比较
| 特征 | DFS | BFS |
|---|---|---|
| 遍历顺序 | 深度优先 | 广度优先 |
| 数据结构 | 栈 | 队列 |
| 空间复杂度 | O(d) | O(b^d) |
| 时间复杂度 | O(V + E) | O(V + E) |
| 优点 | 可以快速找到目标节点 | 可以找到最短路径 |
| 缺点 | 可能陷入深度路径 | 可能错过最短路径 |
其中,d 为树的深度,b 为树的平均分支因子,V 为图中的顶点数,E 为图中的边数。
# 5. 中国象棋算法实践与应用**
**5.1 象棋引擎开发与评估**
象棋引擎是计算机程序,它能够根据棋盘状态做出走棋决策。开发象棋引擎涉及以下步骤:
* **棋盘状态表示:**将棋盘状态表示为数据结构,例如二维数组或位板。
* **评估函数:**设计一个函数来评估棋盘状态,衡量其优劣。
* **搜索算法:**使用搜索算法(如深度优先搜索或广度优先搜索)来生成候选走法。
* **剪枝策略:**应用剪枝策略(如α-β剪枝)来减少搜索空间。
* **走法选择:**根据评估函数和搜索结果选择最佳走法。
象棋引擎的评估可以通过与人类棋手对弈或使用 Elo 评分系统进行。
**5.2 象棋对弈平台与人工智能挑战**
象棋对弈平台为人类棋手和象棋引擎提供了一个对弈的界面。一些流行的象棋对弈平台包括:
* **Chess.com**
* **Lichess**
* **Stockfish**
人工智能挑战赛为象棋引擎提供了一个竞争的平台,以展示其能力。著名的象棋人工智能挑战赛包括:
* **TCEC(Top Chess Engine Championship)**
* **CCC(Computer Chess Championship)**
* **WCCC(World Computer Chess Championship)**
**5.3 象棋算法在其他领域的应用**
象棋算法的原理和技术可以应用于其他领域,例如:
* **游戏设计:**开发其他棋盘游戏的算法和人工智能。
* **人工智能:**研究和开发新的搜索算法、评估函数和剪枝策略。
* **运筹学:**解决组合优化问题,如旅行商问题和背包问题。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨中国象棋算法,提供全面的实战秘籍,从入门到精通,解锁棋盘博弈智慧。专栏涵盖 Java 版算法的详细拆解,掌握算法精髓;优化秘诀,提升效率与准确性,棋盘博弈更胜一筹;与人工智能的结合,探索算法无限可能;在其他领域的应用,拓展算法边界,解锁更多可能。此外,专栏还分析算法复杂度,优化算法性能,并探讨并行化技术,多核加速,提升算法效率。通过本专栏,读者将全面了解中国象棋算法,打造智能象棋引擎,步步制胜。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【时间序列分析深度解析】:15个关键技巧让你成为数据预测大师

# 摘要
时间序列分析是处理和预测按时间顺序排列的数据点的技术。本文
【Word文档处理技巧】:代码高亮与行号排版的终极完美结合指南
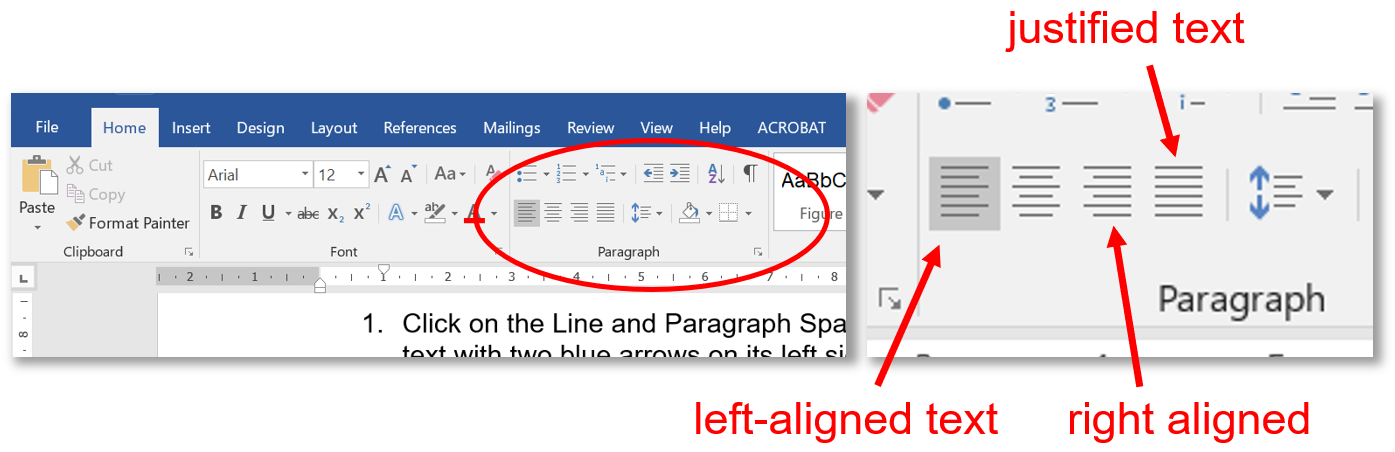
# 摘要
本文旨在为技术人员提供关于Word文档处理的深入指导,涵盖了从基础技巧到高级应用的一系列主题。首先介绍了Word文档处理的基本入门知识,然后着重讲解了代码高亮的实现方法,包括使用内置功能、自定义样式及第三方插件和宏。接着,文中详细探讨了行号排版的策略,涉及基础理解、在Word中的插入方法以及高级定制技巧。第四章讲述了如何将代码高亮与行号完美结
LabVIEW性能优化大师:图片按钮内存管理的黄金法则
# 摘要
本文围绕LabVIEW软件平台的内存管理进行深入探讨,特别关注图片按钮对象在内存中的使用原理、优化实践以及管理工具的使用。首先介绍LabVIEW内存管理的基础知识,然后详细分析图片按钮在LabVIEW中的内存使用原理,包括其数据结构、内存分配与释放机制、以及内存泄漏的诊断与预防。第三章着重于实践中的内存优化策略,包括图片按钮对象的复用、图片按钮数组与簇的内存管理技巧,以及在事件结构和循环结构中的内存控制。接着,本文讨论了LabVIEW内存分析工具的使用方法和性能测试的实施,最后提出了内存管理的最佳实践和未来发展趋势。通过本文的分析与讨论,开发者可以更好地理解LabVIEW内存管理,并
【CListCtrl行高设置深度解析】:算法调整与响应式设计的完美融合
# 摘要
CListCtrl是广泛使用的MFC组件,用于在应用程序中创建具有复杂数据的列表视图。本文首先概述了CListCtrl组件的基本使用方法,随后深入探讨了行高设置的理论基础,包括算法原理、性能影响和响应式设计等方面。接着,文章介绍了行高设置的实践技巧,包括编程实现自适应调整、性能优化以及实际应用案例分析。文章还探讨了行高设置的高级主题,如视觉辅助、动态效果实现和创新应用。最后,通过分享最佳实践与案例,本文为构建高效和响应式的列表界面提供了实用的指导和建议。本文为开发者提供了全面的CListCtrl行高设置知识,旨在提高界面的可用性和用户体验。
# 关键字
CListCtrl;行高设置
邮件排序与筛选秘籍:SMAIL背后逻辑大公开
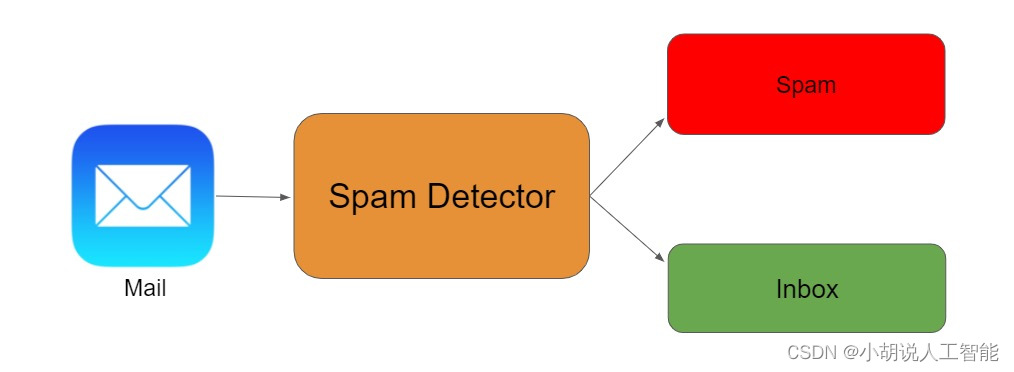
# 摘要
本文全面探讨了邮件系统的功能挑战和排序筛选技术。首先介绍了邮件系统的功能与面临的挑战,重点分析了SMAIL的排序算法,包括基本原理、核心机制和性能优化策略。随后,转向邮件筛选技术的深入讨论,包括筛选逻辑的基础构建、高级技巧和效率提升方法。文中还通过实际案例分析,展示了邮件排序与筛选在不同环境中的应用,以及个人和企业级的邮件管理策略。文章最后展望了SMAIL的未来发展趋势,包括新技术的融入和应对挑战的策
AXI-APB桥在SoC设计中的关键角色:微架构视角分析

# 摘要
本文对AXI-APB桥的技术背景、设计原则、微架构设计以及在SoC设计中的应用进行了全面的分析与探讨。首先介绍了AXI与APB协议的对比以及桥接技术的必要性和优势,随后详细解析了AXI-APB桥的微架构组件及其功能,并探讨了设计过程中面临的挑战和解决方案。在实践应用方面,本文阐述了AXI-APB桥在SoC集成、性能优化及复杂系统中的具体应用实例。此外,本文还展望了AXI-APB桥的高级功能扩展及其
CAPL脚本高级解读:技巧、最佳实践及案例应用
# 摘要
CAPL(CAN Access Programming Language)是一种专用于Vector CAN网络接口设备的编程语言,广泛应用于汽车电子、工业控制和测试领域。本文首先介绍了CAPL脚本的基础知识,然后详细探讨了其高级特性,包括数据类型、变量管理、脚本结构、错误处理和调试技巧。在实践应用方面,本文深入分析了如何通过CAPL脚本进行消息处理、状态机设计以
【适航审定的六大价值】:揭秘软件安全与可靠性对IT的深远影响
# 摘要
适航审定作为确保软件和IT系统符合特定安全和可靠性标准的过程,在IT行业中扮演着至关重要的角色。本文首先概述了适航审定的六大价值,随后深入探讨了软件安全性与可靠性的理论基础及其实践策略,通过案例分析,揭示了软件安全性与可靠性提升的成功要素和失败的教训。接着,本文分析了适航审定对软件开发和IT项目管理的影响,以及在遵循IT行业标准方面的作用。最后,展望了适航审定在
CCU6定时器功能详解:定时与计数操作的精确控制

# 摘要
CCU6定时器是工业自动化和嵌入式系统中常见的定时器组件,本文系统地介绍了CCU6定时器的基础理论、编程实践以及在实际项目中的应用。首先概述了CCU
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )