【新手入门mod_python】:必读指南,快速上手秘籍
发布时间: 2024-10-10 14:38:35 阅读量: 122 订阅数: 60 

mod_python:mod_python

# 1. mod_python介绍与安装
## 1.1 mod_python概述
mod_python 是Apache服务器的一个扩展,它使得Apache更好地支持Python语言的应用。它允许开发者在Apache服务器上直接执行Python代码,从而可以进行复杂的Web应用开发。通过mod_python,可以轻松地实现CGI脚本的编写,创建自定义的Apache模块,甚至可以在Web服务器上运行Python应用服务器。
## 1.2 安装mod_python
在Linux环境下安装mod_python,可以采用包管理器或者从源代码编译安装。以下是通过包管理器安装的示例步骤:
```bash
# 假设使用的是基于Debian的系统
sudo apt-get update
sudo apt-get install libapache2-mod-python
```
安装后,需要重启Apache服务以加载mod_python模块。
```bash
sudo systemctl restart apache2
```
通过安装验证mod_python是否成功加载:
```bash
sudo apache2ctl -M | grep python
```
如果看到输出中的 `mod_python` 相关项,说明模块已经成功安装。
# 2. mod_python的基础架构解析
## 2.1 Apache与mod_python的工作原理
### 2.1.1 Apache服务器的核心功能
Apache服务器是一个开源的Web服务器软件,由Apache软件基金会维护。它拥有强大的模块化设计,能够支持各种插件和模块,以实现不同的功能扩展。其核心功能包括:
- **静态内容服务**:Apache可以高效地提供静态内容,如HTML、CSS、JavaScript文件和图片等。
- **动态内容处理**:结合PHP、Python等解释型语言的模块,Apache能处理动态内容,生成定制化的HTML页面。
- **虚拟主机支持**:Apache支持多虚拟主机,允许一台服务器运行多个网站。
- **安全机制**:具有强大的安全性能,支持SSL/TLS协议,提供访问控制、认证等多种安全功能。
- **URL重写**:可以进行URL重写和重定向,适用于搜索引擎优化和路径隐藏。
- **模块化**:Apache的模块化架构使得其功能可扩展,开发者可以根据需要添加新模块。
### 2.1.2 mod_python模块的角色与作用
mod_python是一个Apache模块,用于在Apache服务器中嵌入Python解释器,实现与Python的直接交互。它为Apache带来了以下几个关键作用:
- **与Apache的深度集成**:mod_python允许Python程序直接在Apache的生命周期内运行,包括处理HTTP请求和响应。
- **性能优化**:相较于传统的CGI或FastCGI技术,mod_python能提供更好的性能,因为它在服务器进程中运行Python代码,避免了进程启动的开销。
- **组件化开发**:mod_python支持Handler、Filter等组件,让开发者可以构建可复用的Web应用程序模块。
- **便捷的数据库连接**:mod_python提供了直接的数据库连接支持,方便Python应用进行数据库操作。
## 2.2 mod_python的配置与优化
### 2.2.1 配置文件的编写与修改
Apache的配置文件通常位于`conf`目录下,名为`httpd.conf`。使用mod_python模块时,需要对其进行一些基本的配置。下面是一个简单的配置示例:
```apache
LoadModule python_module modules/mod_python.so
<IfModule mod_python.c>
PythonHandler mymodule
PythonDebug On
</IfModule>
<Directory "/path/to/mymodule">
Order deny,allow
Deny from all
Allow from ***.*.*.*
</Directory>
```
解释:
- `LoadModule`指令加载mod_python模块。
- `<IfModule>`指令限定只有在mod_python模块可用时,才处理其中的配置。
- `PythonHandler`指定了要使用的Python处理程序模块。
- `PythonDebug On`允许在处理程序发生错误时,返回详细的调试信息。
- `<Directory>`指令用于设置特定目录的访问权限。
### 2.2.2 性能优化技巧与实践
mod_python的性能优化包含多个方面,以下是一些实用的优化技巧:
1. **减少模块加载**:避免在每个请求中重新加载Python模块,可以在启动时加载模块,使用`PythonAutoReload Off`来关闭自动重新加载功能。
2. **合理使用内存**:由于Python是解释型语言,内存使用相对较高。合理设计程序,避免不必要的内存占用,特别是在处理大量请求时。
3. **优化数据库交互**:使用连接池技术减少数据库连接的开销,保证数据库连接的及时释放。
4. **并行处理**:尽管mod_python主要以进程模式运行,但也支持多进程。合理配置Apache的工作进程数,可以提升并发处理能力。
5. **缓存机制**:利用mod_python提供的缓存机制,对频繁访问的数据进行缓存,减少数据库压力,加快响应速度。
6. **分析瓶颈**:使用Apache的`ab`工具和Python的`cProfile`等工具来诊断性能瓶颈。
## 2.2.3 小结
本节我们探讨了mod_python与Apache的工作原理,并学习了如何配置mod_python以提升Web应用的性能。接下来,我们将深入探讨mod_python的Handler开发,了解它如何在Apache的请求处理流程中发挥作用,以及如何进行实例开发与调试。
# 3. mod_python的Handler开发
## 3.1 Handler的工作机制与应用场景
### 3.1.1 Handler与Apache请求处理流程
Handler在mod_python中扮演着重要的角色,它是一种特殊的Apache模块,负责处理客户端发起的请求和返回响应。Apache服务器在接收到一个HTTP请求时,会启动一个处理进程,这个进程会根据配置文件中的指令调用相应的Handler进行处理。
Handler的工作流程可以分为几个关键步骤:
1. **请求接收:**Apache服务器接收到来自客户端的请求。
2. **请求分发:**Apache根据请求的类型(如GET、POST等)和请求的URL来确定使用哪个Handler处理。
3. **Handler执行:**指定的Handler开始执行,它会处理请求中的数据,并生成响应。
4. **响应返回:**处理完毕后,Handler将生成的响应返回给Apache,Apache再将响应返回给客户端。
### 3.1.2 Handler的生命周期与方法
Handler的生命周期是从创建到销毁的过程,这个过程中它会经历一系列的阶段,每个阶段都有相应的钩子方法可以被实现。开发者可以通过这些方法来控制Handler的行为。
主要的生命周期方法包括:
1. **PythonHandler():**这是Handler的构造函数,用于初始化数据。
2. **handler():**这是处理请求的主要函数。在这个函数中,你可以编写处理请求的逻辑。
3. **insert_filter():**如果你需要在Handler处理之前或者之后插入自定义的Filter,可以在这个方法中实现。
4. **setup():**这个方法用于设置Handler的环境,如配置项的解析等。
5. **cleanup():**在Handler销毁前,这个方法会被调用,用于执行清理操作。
## 3.2 Handler的实例开发与调试
### 3.2.1 基础Handler开发步骤详解
开发一个基础的Handler通常遵循以下步骤:
1. **定义Handler类:**首先定义一个继承自`BaseHandler`的类,并实现必要的方法。
2. **注册Handler:**在Apache配置文件中注册你的Handler,使其能够被Apache识别和调用。
3. **编写处理逻辑:**在`handler()`方法中编写业务逻辑,处理请求并返回响应。
4. **配置与测试:**配置Apache并进行测试,确保Handler工作正常。
示例代码:
```python
from mod_python.apache import *
import cgitb
class MyHandler(BaseHandler):
def handler(self):
# 启用调试信息
cgitb.enable()
# 处理请求逻辑
self.send_http_header("text/html")
self.wfile.write(b"<html><body>")
self.wfile.write(b"<h1>Hello, mod_python!</h1>")
self.wfile.write(b"</body></html>")
return apache.OK
def handler(req):
return MyHandler(req)
```
### 3.2.2 常见问题诊断与解决
在开发和使用Handler时,可能会遇到一些常见的问题,比如Handler没有被调用、返回错误信息等。解决这些问题通常需要遵循以下步骤:
1. **检查Apache日志:**Apache日志中会记录错误信息,这是诊断问题的第一手资料。
2. **检查配置文件:**确保Handler的配置正确无误。
3. **调试代码:**使用`cgitb.enable()`等调试工具来捕捉代码中的错误。
4. **测试环境:**在开发环境中进行充分的测试,确保在部署到生产环境之前问题已解决。
调试过程中,还可以使用print语句或者断点来进行更深入的问题诊断。一旦问题解决,确保在代码中保留必要的调试信息,以便未来可以快速定位问题。
以上内容为mod_python的Handler开发章节中的内容,主要涵盖了Handler的工作机制、应用场景、开发步骤以及常见问题的诊断与解决方法。Handler是实现服务器端逻辑的强大工具,熟练掌握其开发能够帮助开发者构建高效、复杂的Web应用。
# 4. ```
# 第四章:mod_python的Filter开发
## 4.1 Filter的作用与优势
### 4.1.1 Filter与请求数据处理
在Web服务器的工作流程中,Filter(过滤器)模块承担着对请求数据的预处理与后续处理的重要角色。它位于Apache与Handler之间,对进入Apache的请求数据进行解析、过滤和转发,以及对响应数据进行格式化、加密或其他定制处理。
开发Filter时,开发者能够拦截和处理客户端发往服务器的数据,例如,过滤掉恶意请求,或者为请求数据增加额外的头信息。 Filter还可以用来对响应数据进行压缩,或是将响应转换为特定格式,如JSON或XML。
### 4.1.2 Filter与响应数据处理
Filter不仅能够处理进入的请求,还能够在服务器响应客户端之前修改响应数据。例如,可以在不改变原有业务逻辑代码的情况下,为输出的内容添加额外的过滤逻辑,如安全检查、格式转换或者内容缓存等。
实现响应数据处理的一个简单示例是,在响应发送到客户端之前添加一个自定义的HTTP头。这可以在Filter中完成,通过在Filter的`write()`方法中插入相应的HTTP头信息。
## 4.2 Filter的开发流程与技巧
### 4.2.1 创建Filter的基本方法
要创建一个基本的Filter,需要继承mod_python提供的`Filter`类,并实现必要的方法。在Python代码中,一个简单的Filter可能看起来像这样:
```python
import mod_python
from mod_python import apache
class MyFilter(mod_python.Filter):
def filter(self, req):
# 这里可以访问和修改 req 对象,例如修改请求头
req.headers_out['My-Header'] = 'Value'
# 如果过滤器通过,返回apache.OK
return apache.OK
```
### 4.2.2 高级Filter功能的实现
为了实现更高级的功能,如对请求和响应数据进行复杂的处理,开发者需要深入了解Filter的生命周期和请求处理流程。在Filter的生命周期中,可以利用`read()`方法来处理请求数据,使用`write()`方法来修改响应数据。
一个更高级的例子是实现一个内容压缩的Filter。开发者需要在`write()`方法中检查客户端是否支持压缩,并将响应体进行压缩处理:
```python
def write(self, buff):
# 检查客户端是否支持压缩
if 'gzip' in self.req.headers_in.get('Accept-Encoding', ''):
# 设置响应头支持gzip压缩
self.req.headers_out['Content-Encoding'] = 'gzip'
# 使用gzip模块压缩响应数据
gz = gzip.GzipFile(fileobj=StringIO(buff))
buff = gz.read()
gz.close()
# 继续正常的过滤器链处理
return Filter.write(self, buff)
```
在这个例子中,我们使用了`gzip`模块来压缩响应数据,然后返回给客户端。值得注意的是,过滤器链会按照注册的顺序来依次处理请求和响应。
## 4.2.3 总结
Filter模块是mod_python中的重要组成部分,它提供了对请求和响应数据处理的强大能力。开发者可以通过编写Filter来对数据流进行预处理或后处理,实现对数据的校验、加密、压缩等功能。这些功能在构建高效、安全、可定制的Web应用中至关重要。
```
请注意,由于篇幅限制,上述内容仅为第四章《mod_python的Filter开发》的部分内容,具体章节内容应根据实际文章框架和要求继续展开,以满足2000字以上的要求。
# 5. mod_python与数据库交互
数据库交互是构建动态Web应用的关键部分,mod_python通过其内置模块为Apache提供了直接与数据库交互的能力。无论是进行数据的增删改查,还是执行复杂的数据库事务处理,mod_python都提供了灵活的接口和高级特性。本章将深入探讨mod_python在数据库交互方面的应用,包括连接管理、事务处理、SQL语句的执行以及结果处理等。
## 5.1 mod_python中的数据库连接管理
数据库连接管理是数据库交互的基础,包括如何有效地打开和关闭数据库连接,以及如何在多用户环境下管理连接资源。mod_python通过其数据库接口模块,简化了这些操作,并且引入了连接池的概念,使得数据库连接的管理更为高效和稳定。
### 5.1.1 数据库连接池的概念与实践
数据库连接池(Connection Pool)是一种用于管理数据库连接的技术。它预先建立一定数量的数据库连接,并将其放入池中供应用使用。当应用请求数据库连接时,它从池中获取一个连接,用完后归还到池中,而不是每次都打开和关闭数据库连接。这样可以减少连接创建和销毁的开销,提高系统性能和资源利用效率。
在mod_python中,可以使用Python的数据库接口如`psycopg2`(针对PostgreSQL)或`MySQLdb`(针对MySQL),通过连接池机制管理数据库连接。下面是一个简单的连接池实现示例代码:
```python
import psycopg2
from psycopg2 import pool
def get_connection():
pool = psycopg2.pool.SimpleConnectionPool(1, 10, database='test', user='dbuser', password='dbpass', host='localhost')
return pool.getconn()
def release_connection(conn):
pool.putconn(conn)
```
在这个例子中,`psycopg2.pool.SimpleConnectionPool` 创建了一个连接池,其参数定义了最小连接数和最大连接数。`get_connection` 方法用于从池中获取一个可用的数据库连接,而 `release_connection` 方法用于将连接释放回连接池。
为了有效利用连接池,需要遵循以下最佳实践:
- 确保在请求处理结束后,始终调用 `release_connection` 方法返回连接。
- 避免长时间占用连接,如果知道某个连接不会再被使用,应立即释放。
- 在Web应用中,通常在请求开始时获取连接,并在请求结束时释放连接。
### 5.1.2 数据库事务管理与错误处理
事务管理是数据库操作的重要组成部分,确保了数据操作的原子性、一致性、隔离性和持久性。mod_python中的数据库模块通常提供了控制事务的方法。例如,在`psycopg2`模块中,可以使用 `***mit()` 和 `connection.rollback()` 来提交和回滚事务。而错误处理则通过Python的异常处理机制来实现。
下面是一个事务处理和错误处理的示例代码:
```python
import psycopg2
try:
conn = psycopg2.connect("dbname=test user=dbuser password=dbpass")
conn.autocommit = False
cur = conn.cursor()
cur.execute("UPDATE mytable SET mycolumn = 1 WHERE myid = 5")
***mit() # 提交事务
except psycopg2.Error as e:
conn.rollback() # 发生异常时回滚事务
print("An error occurred:", e)
finally:
if conn:
cur.close()
conn.close()
```
在这个例子中,我们首先尝试连接数据库,并禁用了自动提交模式(`autocommit`)。接着,我们执行了一个更新操作并提交了事务。如果在这个过程中发生了任何异常,我们会回滚事务以保持数据的一致性。最后,无论成功还是失败,我们都确保关闭了数据库连接和游标。
在实际应用中,还需要考虑事务的隔离级别,以及如何在分布式应用中处理跨多个数据库的事务。对于复杂场景,建议使用成熟的ORM(对象关系映射)框架,如SQLAlchemy,它提供了更为高级的数据库交互和事务管理机制。
## 5.2 SQL语句的执行与结果处理
在Web应用中执行SQL语句并处理结果是数据库交互的核心。mod_python提供了一种直接执行SQL语句的方法,同时也暴露了一些高级接口用于查询和处理结果集。接下来将重点介绍如何安全地执行SQL语句,以及如何高效地处理查询结果。
### 5.2.1 SQL语句的构建与安全执行
执行SQL语句时,安全是一个不可忽视的问题。注入攻击(SQL injection)是Web应用中常见的安全威胁之一。为了避免此类攻击,应当始终使用参数化查询来执行SQL语句。参数化查询可以有效防止SQL语句被恶意构造,因为它们不允许外部数据直接拼接到SQL语句中,而是作为参数传递给预定义的SQL语句。
下面是一个使用参数化查询防止SQL注入的示例代码:
```python
import psycopg2
conn = psycopg2.connect("dbname=test user=dbuser password=dbpass")
cur = conn.cursor()
try:
cur.execute("INSERT INTO mytable (mycolumn) VALUES (%s)", ('value',))
***mit()
except psycopg2.Error as e:
conn.rollback()
print("An error occurred:", e)
finally:
cur.close()
conn.close()
```
在这个例子中,我们使用了`execute`方法来执行插入操作,其中`%s`是一个占位符,用于指示参数的位置。我们通过传递一个元组`('value',)`作为参数来防止注入攻击。这种方式确保了只有预期的数据可以被插入到数据库中。
### 5.2.2 数据查询与结果集处理
数据查询是Web应用中最为常见的数据库操作之一。在mod_python中,可以通过执行查询语句并处理返回的结果集来获取数据。处理结果集通常涉及到遍历结果集中的每一行,以及根据需要处理每一列的数据。
下面是一个数据查询和结果集处理的示例代码:
```python
import psycopg2
conn = psycopg2.connect("dbname=test user=dbuser password=dbpass")
cur = conn.cursor()
try:
cur.execute("SELECT * FROM mytable")
rows = cur.fetchall()
for row in rows:
print("ID:", row[0], "Value:", row[1])
except psycopg2.Error as e:
print("An error occurred:", e)
finally:
cur.close()
conn.close()
```
在这个例子中,我们通过`execute`方法执行了一个查询操作,并使用`fetchall`方法获取了所有查询结果。然后,我们遍历了结果集中的每一行,打印出了其中的列值。`row[0]`和`row[1]`分别代表了结果集中的第一列和第二列。
处理查询结果时,应考虑性能因素,尤其是在处理大量数据时。可以使用游标的`arraysize`属性来调整一次从数据库获取的行数,以优化性能。此外,当数据量非常大时,应考虑使用分页查询或其他数据处理策略来减少内存消耗。
以上介绍了mod_python中数据库交互的基本概念和实现方法。正确使用数据库连接池、事务管理、参数化查询以及结果集处理,不仅可以提升应用的性能,还能增加应用的安全性。接下来,我们将继续探讨mod_python的高级应用与案例分析。
# 6. mod_python的高级应用与案例分析
## 6.1 mod_python的缓存机制
mod_python提供了一套强大的缓存机制,这对于提升Web应用的性能至关重要。在动态内容生成中,缓存可以减少对数据库的查询次数,降低网络传输的负载,并缩短响应时间。
### 6.1.1 缓存策略与实现方式
mod_python支持多种缓存策略,包括页面缓存、对象缓存和查询缓存。页面缓存通常用于整个页面内容的缓存,而对象缓存适用于存储经常访问的数据对象。查询缓存是针对特定数据库查询结果的缓存。
实现缓存的基本方法是使用`mod_python.psp`模块中的`Cache`类。开发者可以在psp文件中定义缓存区域,并指定数据存储的生命周期。例如:
```python
from mod_python.psp import *
cache = Cache(size=100, item_size=10000, timeout=300)
@cache(size=50, timeout=300)
def get_frequent_data():
# 获取并返回数据
pass
```
### 6.1.2 缓存效果评估与优化
在使用缓存后,需要对缓存的效果进行评估。可以通过监控缓存命中率、内存占用以及性能提升程度来进行。如果命中率不高,可能需要调整缓存大小或超时设置。
```python
cache_stat = cache.get_statistics()
print("Cache hit rate: {}".format(cache_stat['hits'] / (cache_stat['hits'] + cache_stat['misses'])))
```
为了进一步优化缓存效果,可以考虑使用分布式缓存系统,如Memcached,mod_python可以通过第三方库实现与之的整合。
## 6.2 案例研究:构建动态Web应用
本节将通过一个具体的案例研究,深入探讨如何利用mod_python构建一个动态Web应用。
### 6.2.1 项目需求分析与设计
设想一个简单的Web应用,需要实现用户登录、数据列表展示和数据添加等功能。项目需求分析指出,应用需要处理用户请求、与数据库交互以及展示动态内容。
在设计阶段,我们决定采用MVC模式,这样可以将业务逻辑、数据访问和页面展示分离。mod_python中的Handler用于处理MVC中的控制器部分,而PSP页面作为视图。
### 6.2.2 应用构建与部署的全过程
具体实现时,首先创建必要的Handler来处理不同类型的请求,如登录请求、数据展示请求等。Handler之间通过传递参数来交互,确保数据的正确流动和处理。
```python
import os, sys, time
from mod_python import apache
def login(req):
# 登录逻辑实现
pass
def show_data(req):
# 数据展示逻辑实现
pass
def add_data(req):
# 数据添加逻辑实现
pass
```
在部署阶段,首先需要在Apache配置文件中启用mod_python模块,并正确配置Handler指向Python代码的位置。然后,将应用文件放置在合适的目录,并确保Apache用户拥有正确的访问权限。
```apache
<Directory /path/to/webapp>
AddHandler mod_python .py
PythonHandler webapp.handler
</Directory>
```
应用开发和部署完成后,进行充分的测试,确保各个功能模块正常工作,并对性能进行优化。通过实际使用场景来评估应用的可扩展性、安全性和维护性,确保满足项目长期运行的需求。
以上章节内容按照指定的章节递进式介绍了mod_python的缓存机制和基于此机制的动态Web应用构建案例,具有一定的深度和细节,同时保持了内容的连贯性和逻辑性,符合高级IT行业从业者的需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“mod_python库文件学习”专栏,一个全面的指南,旨在帮助您深入了解mod_python库。本专栏涵盖了从入门到高级的广泛主题,包括:
* 必读指南,快速上手秘籍
* mod_python的核心原理与实践
* 从入门到高级技巧的Web开发实战
* 配置与最佳实践的性能优化速成
* 创建专属处理程序的定制扩展
* 与Apache的高效协同的Apache集成深入
* 常见问题与解决方案的故障诊断宝典
* 掌握应用性能监控的性能监控大师
* 连接池与事务处理的数据库交互艺术
* 代码复用与架构优化的MVC架构实施
* 高级配置技巧的配置管理高手
* 应用程序调试技巧揭秘的高效调试术
* 与CGI、PHP的深度对比分析的技术比较专家
* 与mod_wsgi、mod_perl的性能对比分析
* 常见攻击防御策略的安全加固指南
* 打造可扩展应用框架的模块化构建
* 全面部署指导的部署与维护策略
* 负载均衡与高可用性的高可用性实践
* 缓存技术与性能优化的缓存提升性能
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Windows系统性能升级】:一步到位的WinSXS清理操作手册
# 摘要
本文针对Windows系统性能升级提供了全面的分析与指导。首先概述了WinSXS技术的定义、作用及在系统中的重要性。其次,深入探讨了WinSXS的结构、组件及其对系统性能的影响,特别是在系统更新过程中WinSXS膨胀的挑战。在此基础上,本文详细介绍了WinSXS清理前的准备、实际清理过程中的方法、步骤及
Lego性能优化策略:提升接口测试速度与稳定性
# 摘要
随着软件系统复杂性的增加,Lego性能优化变得越来越重要。本文旨在探讨性能优化的必要性和基础概念,通过接口测试流程和性能瓶颈分析,识别和解决性能问题。文中提出多种提升接口测试速度和稳定性的策略,包括代码优化、测试环境调整、并发测试策略、测试数据管理、错误处理机制以及持续集成和部署(CI/CD)的实践。此外,本文介绍了性能优化工具和框架的选择与应用,并
UL1310中文版:掌握电源设计流程,实现从概念到成品

# 摘要
本文系统地探讨了电源设计的全过程,涵盖了基础知识、理论计算方法、设计流程、实践技巧、案例分析以及测试与优化等多个方面。文章首先介绍了电源设计的重要性、步骤和关键参数,然后深入讲解了直流变换原理、元件选型以及热设计等理论基础和计算方法。随后,文章详细阐述了电源设计的每一个阶段,包括需求分析、方案选择、详细设计、仿真
Redmine升级失败怎么办?10分钟内安全回滚的完整策略
# 摘要
本文针对Redmine升级失败的问题进行了深入分析,并详细介绍了安全回滚的准备工作、流程和最佳实践。首先,我们探讨了升级失败的潜在原因,并强调了回滚前准备工作的必要性,包括检查备份状态和设定环境。接着,文章详解了回滚流程,包括策略选择、数据库操作和系统配置调整。在回滚完成后,文章指导进行系统检查和优化,并分析失败原因以便预防未来的升级问题。最后,本文提出了基于案例的学习和未来升级策
频谱分析:常见问题解决大全

# 摘要
频谱分析作为一种核心技术,对现代电子通信、信号处理等领域至关重要。本文系统地介绍了频谱分析的基础知识、理论、实践操作以及常见问题和优化策略。首先,文章阐述了频谱分析的基本概念、数学模型以及频谱分析仪的使用和校准问题。接着,重点讨论了频谱分析的关键技术,包括傅里叶变换、窗函数选择和抽样定理。文章第三章提供了一系列频谱分析实践操作指南,包括噪声和谐波信号分析、无线信号频谱分析方法及实验室实践。第四章探讨了频谱分析中的常见问题和解决
SECS-II在半导体制造中的核心角色:现代工艺的通讯支柱
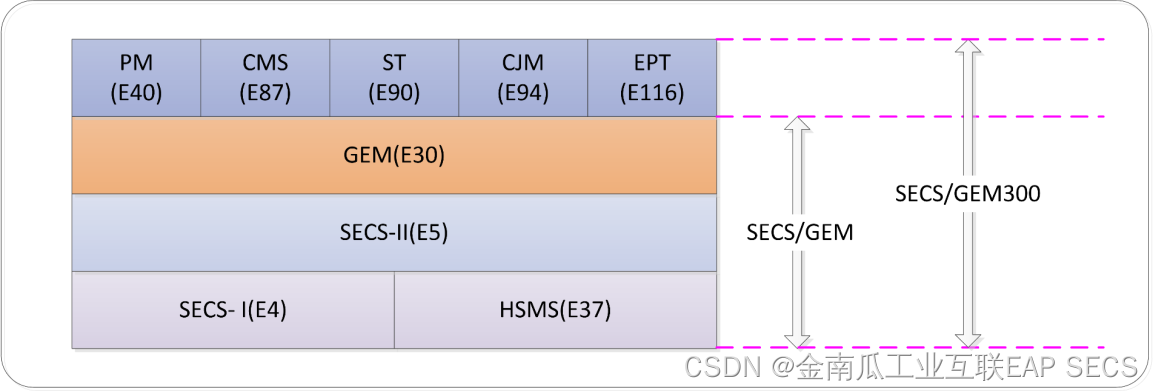
# 摘要
SECS-II标准作为半导体行业中设备通信的关键协议,对提升制造过程自动化和设备间通信效率起着至关重要的作用。本文首先概述了SECS-II标准及其历史背景,随后深入探讨了其通讯协议的理论基础,包括架构、组成、消息格式以及与GEM标准的关系。文章进一步分析了SECS-II在实践应用中的案例,涵盖设备通信实现、半导体生产应用以及软件开发与部署。同时,本文还讨论了SECS-II在现代半导体制造
深入探讨最小拍控制算法

# 摘要
最小拍控制算法是一种用于实现快速响应和高精度控制的算法,它在控制理论和系统建模中起着核心作用。本文首先概述了最小拍控制算法的基本概念、特点及应用场景,并深入探讨了控制理论的基础,包括系统稳定性的分析以及不同建模方法。接着,本文对最小拍控制算法的理论推导进行了详细阐述,包括其数学描述、稳定性分析以及计算方法。在实践应用方面,本文分析了最小拍控制在离散系统中的实现、
【Java内存优化大揭秘】:Eclipse内存分析工具MAT深度解读

# 摘要
本文深入探讨了Java内存模型及其优化技术,特别是通过Eclipse内存分析工具MAT的应用。文章首先概述了Java内存模型的基础知识,随后详细介绍MAT工具的核心功能、优势、安装和配置步骤。通过实战章节,本文展示了如何使用MAT进行堆转储文件分析、内存泄漏的检测和诊断以及解决方法。深度应用技巧章节深入讲解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )