【Python库文件学习之odict】:odict在实际项目中的应用案例
发布时间: 2024-10-16 00:37:30 阅读量: 27 订阅数: 24 

LABVIEW程序实例-DS写属性数据.zip
# 1. odict库概述
在Python编程中,字典是一种内置的数据结构,用于存储键值对集合。然而,标准的`dict`类型在某些情况下并不足以满足特定需求,特别是在需要保持元素插入顺序时。为了弥补这一不足,Python社区开发了`odict`库,它是一个有序字典的实现,保持键值对的插入顺序。本章将介绍`odict`库的背景、用途以及其在Python生态系统中的地位。
`odict`库的出现主要是为了解决标准`dict`在需要有序数据结构时的局限性。在数据处理、Web开发、机器学习等领域,经常需要处理大量数据,并且需要保持数据的顺序,`odict`因此成为了这些场景下的一种重要工具。
`odict`库不仅仅是一个有序的字典,它还提供了一些额外的功能和性能优化,使其在处理大量数据时更加高效。此外,它也支持与Python的其他库,如Pandas、NumPy等进行整合,为构建复杂的数据处理管道提供了便利。
在接下来的章节中,我们将深入探讨`odict`的基本操作、特点、以及在数据分析、Web开发和机器学习等领域的应用。
# 2. odict的基本操作和特点
## 2.1 odict数据结构介绍
### 2.1.1 odict的定义和初始化
在本章节中,我们将深入探讨`odict`这一特殊的字典数据结构。`odict`,全称有序字典(Ordered Dictionary),是Python中的一种特殊字典,它保持了元素的插入顺序。这与普通的Python字典不同,后者是无序的,即不保证元素的顺序。`odict`通常用于需要保持数据顺序的场景,例如在数据分析和Web开发中,维持数据的输入顺序往往很重要。
`odict`的定义和初始化非常简单,可以通过从`collections`模块导入`OrderedDict`类来创建:
```python
from collections import OrderedDict
# 创建一个空的OrderedDict对象
od = OrderedDict()
```
也可以在创建时传入一个可迭代对象,如列表或另一个字典,以初始化`odict`:
```python
# 使用列表初始化OrderedDict
od = OrderedDict([("a", 1), ("b", 2), ("c", 3)])
```
在本章节介绍中,我们已经通过两个例子展示了`odict`的定义和初始化方法。这种有序的数据结构在处理具有顺序依赖性的数据时非常有用。
### 2.1.2 odict与普通字典的区别
`odict`与普通字典的主要区别在于元素的顺序性。普通字典在Python 3.6之前的版本中是无序的,这意味着字典中的元素顺序可能会发生变化。从Python 3.7开始,普通的字典虽然保持了插入顺序,但在某些情况下,这种顺序性并不是绝对可靠的。而`odict`则始终按照元素被添加到字典中的顺序来维护元素。
例如,考虑以下代码:
```python
# 普通字典示例
d = {}
d['a'] = 1
d['b'] = 2
d['c'] = 3
print(list(d.keys())) # 输出可能是:['c', 'a', 'b']
# odict示例
od = OrderedDict()
od['a'] = 1
od['b'] = 2
od['c'] = 3
print(list(od.keys())) # 输出始终是:['a', 'b', 'c']
```
在这个示例中,普通字典`d`的键的顺序可能会因为Python版本的不同而有所不同,而`odict`的键的顺序始终是按照插入的顺序。
除了顺序性,`odict`在性能上通常比普通字典稍微逊色,特别是在大量数据处理时。这是因为`odict`需要维护元素的顺序,这需要额外的内存和处理时间。因此,如果顺序不是问题,通常推荐使用普通的字典。
## 2.2 odict的基本操作
### 2.2.1 添加和更新元素
添加和更新元素是`odict`最基本的两个操作。添加新元素到`odict`中可以像普通字典一样使用方括号:
```python
od = OrderedDict()
od['a'] = 1 # 添加元素
od['b'] = 2 # 继续添加元素
```
如果键已经存在于`odict`中,上述操作将更新该键对应的值:
```python
od['a'] = 10 # 更新键'a'的值
```
### 2.2.2 删除元素和清空字典
删除`odict`中的元素可以使用`pop`方法,这会同时删除键和对应的值。也可以使用`del`语句:
```python
# 使用pop删除元素
removed_value = od.pop('a') # 删除'a'键,并返回其值
# 使用del删除元素
del od['b'] # 删除'b'键
```
清空整个`odict`可以使用`clear`方法,这与普通字典的操作相同:
```python
od.clear() # 清空字典
```
### 2.2.3 odict的遍历和迭代
`odict`支持多种遍历和迭代方式,可以使用`keys()`、`values()`和`items()`方法来获取字典的键、值和键值对,这些方法与普通字典的工作方式相同:
```python
# 遍历键
for key in od.keys():
print(key)
# 遍历值
for value in od.values():
print(value)
# 遍历键值对
for key, value in od.items():
print(key, value)
```
### 2.3 odict的高级特性
#### 2.3.1 有序性分析
正如我们之前讨论的,`odict`的有序性是它最显著的特性。这意味着元素将按照插入顺序排列。这种特性在许多应用场景中都非常有用,比如需要保持历史记录顺序的数据。
```python
import collections
# 创建一个OrderedDict
od = collections.OrderedDict()
od['one'] = 1
od['two'] = 2
od['three'] = 3
# 打印键值对并验证顺序
for key, value in od.items():
print(key, value)
```
#### 2.3.2 默认值处理
`odict`提供了`setdefault`方法,这与普通字典的`setdefault`方法类似,但在`odict`中,它保证了新添加的键值对将被添加到字典的末尾。
```python
# 使用setdefault添加带有默认值的键
od.setdefault('four', 4) # 如果'four'不存在,则添加'four': 4
```
#### 2.3.3 深度复制和克隆
在处理复杂数据结构时,深度复制(deep copy)是非常重要的。`odict`提供了`copy`方法来实现深度复制,这对于需要保持原始`odict`结构和顺序的场景非常有用。
```python
# 创建一个OrderedDict
od = collections.OrderedDict()
od['one'] = 1
od['two'] = 2
# 深度复制OrderedDict
new_od = od.copy()
```
## 总结
在本章节中,我们介绍了`odict`的基本概念、操作和高级特性。`odict`作为一个有序字典,它的主要特点是能够保持元素的插入顺序,这使得它在许多需要顺序性的应用中非常有用。我们讨论了如何创建和初始化`odict`,如何添加、更新、删除元素,以及如何进行遍历和迭代。此外,我们还探讨了`odict`的有序性、默认值处理和深度复制等高级特性。通过本章节的介绍,读者应该对`odict`有了深入的了解,并能够在实际应用中有效地使用这种数据结构。
在接下来的章节中,我们将继续探讨`odict`在数据分析、Web开发和机器学习等领域的应用。
# 3. odict在数据分析中的应用
在数据分析领域,odict库提供了一种既有序又高效的数据处理方式。本章节我们将深入探讨odict在数据预处理、排序分组以及统计分析中的具体应用。
## 3.1 数据预处理和清洗
### 3.1.1 缺失值处理
在实际的数据分析中,处理缺失值是一项常见且重要的任务。odict由于其有序性,在处理缺失值时提供了更多的灵活性和控制力。
```python
import odict
# 假设我们有一个包含缺失值的数据集odict
data = odict.odict([
('A', [1, None, 3]),
('B', [4, 5, 6])
])
# 查找缺失值
missing_values = {key: [i for i in items if i is None] for key, items in data.items()}
print("Missing values by column:", missing_values)
# 删除缺失值
cleaned_data = odict.odict({k: [i for i in v if i is not None] for k, v in data.items()})
print("Data after removing missing values:", cleaned_data)
```
在这段代码中,我们首先创建了一个包含缺失值的odict数据集。然后,我们通过列表推导式查找每个键对应的所有缺失值。最后,我们通过另一个列表推导式删除了所有的缺失值,得到了一个清洗后的数据集。这种方式利用了odict的有序性,可以方便地对每个键值对应的列表进行操作。
### 3.1.2 异常值检测与处理
异常值检测和处理是数据预处理的另一个关键步骤。odict可以通过排序和迭代,结合统计方法来识别异常值。
```python
import numpy as np
# 检测异常值
data = odict.odict([('A', [1, 2, 100]), ('B', [4, 5, 6])])
z_scores = {}
for key, values in data.items():
mean = np.mean(values)
std = np.std(values)
z_scores[key] = [(value - mean) / std for value in values]
# 识别异常值
threshold = 3 # 通常使用3个标准差来定义异常值
outliers = {}
for key, values in z_scores.items():
outliers[key] = [value for value in values if abs(value) > threshold]
print("Detected outliers:", outliers)
```
在这段代码中,我们首先计算了每个键对应的值的z分数,然后根据z分数识别了异常值。这里的异常值是那些偏离平均值3个标准差以上的值。通过这种方式,我们可以有效地识别并处理数据中的异常值。
## 3.2 数据排序和分组
### 3.2.1 基于键的排序
odict的有序性使得基于键的排序变得简单直接。
```python
data = odict.odict([('C', [3, 2, 1]), ('A', [5, 4, 6])])
sorted_data = odict.sorted(data)
print("Sorted data by keys:", sorted_data)
```
在本例中,我们创建了一个odict数据集,并使用`odict.sorted`方法按键排序。输出结果将是键值对按照键的升序排列的odict。
### 3.2.2 基于值的排序
除了键之外,odict也可以根据值进行排序。
```python
data = odict.odict([('C', [3, 2, 1]), ('A', [5, 4, 6])])
sorted_by_values = odict.sorted(data.items(), key=lambda item: item[1])
print("Sorted data by values:", sorted_by_values)
```
这里,我们使用了Python内置的`sorted`函数和一个lambda函数作为key参数,来对数据进行基于值的排序。这将返回一个列表,其中包含按值排序的键值对元组。
### 3.2.3 分组聚合操作
数据分组是数据分析中常用的技巧,odict可以通过将值聚合成列表来实现分组。
```python
from collections import defaultdict
data = odict.odict([('A', [1, 2, 3]), ('B', [2, 3, 4])])
grouped_data = defaultdict(list)
for key, values in data.items():
for value in values:
grouped_data[value].append(key)
print("Grouped data:", dict(grouped_data))
```
在这个例子中,我们创建了一个odict数据集,并将其聚合成一个默认字典(defaultdict),其中值作为键,键的列表作为值。这种方式可以快速地将数据按值进行分组。
## 3.3 数据统计分析
### 3.3.1 计数和频率分析
计数和频率分析是理解数据分布的基础。odict可以方便地进行这些操作。
```python
from collections import Counter
data = odict.odict([('A', [1, 2, 1]), ('B', [2, 2, 3])])
counter = Counter()
for values in data.values():
counter.update(values)
print("Frequency analysis:", counter)
```
这里,我们使用了Python的`collections.Counter`类来统计odict中所有值的频率。输出结果是一个计数器对象,它包含了每个值及其出现的次数。
### 3.3.2 描述性统计分析
描述性统计分析提供了数据集的简要概览,包括中心趋势和离散程度的度量。
```python
import numpy as np
data = odict.odict([('A', [1, 2, 3]), ('B', [4, 5, 6])])
# 计算描述性统计量
mean = np.mean([value for values in data.values() for value in values])
median = np.median([value for values in data.values()])
std_dev = np.std([value for values in data.values()])
print("Mean:", mean)
print("Median:", median)
print("Standard Deviation:", std_dev)
```
在这段代码中,我们计算了odict数据集的平均值、中位数和标准差。这些描述性统计量帮助我们理解数据的中心趋势和变异程度。
### 3.3.3 高级统计模型构建
在构建高级统计模型时,odict可以作为特征和参数的容器。
```python
import pandas as pd
from sklearn.linear_model import LinearRegression
# 假设我们有一个odict,其中包含了特征和目标变量
data = odict.odict([
('feature1', [1, 2, 3]),
('feature2', [4, 5, 6]),
('target', [7, 8, 9])
])
# 将odict转换为DataFrame
df = pd.DataFrame({key: pd.Series(values) for key, values in data.items()})
# 构建线性回归模型
model = LinearRegression()
X = df[['feature1', 'feature2']]
y = df['target']
model.fit(X, y)
print("Model intercept:", model.intercept_)
print("Model coefficients:", model.coef_)
```
在这个例子中,我们首先将odict转换为Pandas的DataFrame,然后使用Scikit-learn的线性回归模型进行拟合。这演示了如何使用odict在机器学习模型构建中的应用。
通过以上示例,我们展示了odict在数据分析中的多样化应用。odict的有序性、灵活性以及与Python生态系统的无缝集成,使其成为数据预处理、排序分组和统计分析的理想工具。
# 4. odict在Web开发中的应用
## 4.1 odict与Web框架集成
在现代Web开发中,Python的Flask和Django是两个非常流行的框架,它们各自有着独特的特点和优势。odict库作为一个有序字典,不仅可以作为数据结构使用,还能在Web开发中发挥重要作用,特别是在与这些框架集成时。
### 4.1.1 Flask和Django中的使用
Flask和Django都提供了丰富的数据处理机制,但在某些情况下,我们需要更灵活的数据结构来处理特定的数据模式。odict可以作为一个替代品或补充工具,来处理一些复杂的场景。
#### Flask中的odict应用
在Flask中,我们通常会遇到需要将数据传递给模板的情况。odict可以用来保持数据的顺序,这对于渲染有序列表或者处理需要排序的数据非常有用。例如,我们可以使用odict来存储路由参数,并在视图函数中传递给模板:
```python
from flask import Flask, render_template
from odict import odict
app = Flask(__name__)
@app.route('/profile/<username>')
def profile(username):
# 假设我们有一个用户对象,需要传递多个属性给模板
user = get_user_profile(username)
user_data = odict([
('username', user.username),
('email', user.email),
('profile_pic', user.profile_picture),
])
return render_template('profile.html', user=user_data)
if __name__ == '__main__':
app.run()
```
#### Django中的odict应用
Django的视图和模板系统同样可以与odict配合使用。在某些情况下,我们需要动态构建上下文数据,odict可以帮助我们保持数据的顺序。例如,在创建响应式表格时,我们可以使用odict来保持列的顺序:
```python
from django.shortcuts import render
from odict import odict
def profile(request, username):
# 获取用户数据
user = get_user_profile(username)
user_data = odict([
('username', user.username),
('email', user.email),
('profile_pic', user.profile_picture),
])
context = {
'user': user_data,
'table_columns': ['Username', 'Email', 'Profile Picture'],
}
return render(request, 'profile.html', context)
```
### 4.1.2 RESTful API的数据处理
在构建RESTful API时,我们经常需要处理JSON数据。odict可以用来构建和解析JSON数据,保持元素的顺序。例如,在处理一个有序的列表数据时,我们可以使用odict来确保返回给客户端的数据是有序的。
```python
from flask import Flask, jsonify
from odict import odict
app = Flask(__name__)
@app.route('/api/data')
def api_data():
# 假设我们有一些数据需要返回
data = [
{'id': 1, 'name': 'Alice'},
{'id': 2, 'name': 'Bob'},
{'id': 3, 'name': 'Charlie'},
]
# 将数据转换为有序字典
ordered_data = [odict(item) for item in data]
return jsonify(ordered_data)
if __name__ == '__main__':
app.run()
```
在本章节中,我们介绍了odict在Flask和Django框架中的基本应用,包括在视图函数中构建有序数据结构,并将其传递给模板。我们还探讨了如何在RESTful API中使用odict来保持JSON数据的顺序。通过这些示例,我们可以看到odict在Web开发中的实用性和灵活性。
# 5. odict在机器学习中的应用
在本章节中,我们将深入探讨`odict`库在机器学习领域的应用。`odict`不仅仅是一个简单的有序字典,它在处理机器学习任务时能够提供更多的灵活性和效率。我们将从特征工程的应用开始,逐步深入到模型训练和参数优化,最后讨论结果分析和模型评估。
## 5.1 特征工程的应用
特征工程是机器学习中的关键步骤,它涉及到从原始数据中提取、选择和转换特征,以便更好地适应算法模型。`odict`在这个过程中可以发挥重要作用。
### 5.1.1 特征编码和转换
特征编码和转换是特征工程的基础,它将非数值型特征转换为数值型特征,以便机器学习模型能够处理。`odict`可以用来存储这些编码后的特征和对应的原始值,便于管理和迭代。
```python
import odict
# 假设我们有以下原始数据
original_data = ['cat', 'dog', 'fish', 'dog', 'cat']
# 使用odict进行特征编码
encoded_features = odict()
# 定义一个简单的编码函数
def encode_feature(feature):
if feature == 'cat':
return 0
elif feature == 'dog':
return 1
elif feature == 'fish':
return 2
else:
return None
# 遍历原始数据进行编码
for item in original_data:
encoded_features[item] = encode_feature(item)
# 输出编码后的特征
print(encoded_features)
```
在这个例子中,我们首先定义了一个简单的编码函数`encode_feature`,然后使用`odict`来存储每个原始特征及其编码后的值。这种方法不仅保持了特征的顺序,而且便于后续的特征管理和使用。
### 5.1.2 数据标准化和归一化
数据标准化和归一化是将数据缩放到特定范围或分布的技术,通常用于提高模型的收敛速度和性能。`odict`可以用来存储每个特征的标准化或归一化参数,以及对应的标准值或归一化值。
```python
import numpy as np
import odict
# 假设我们有以下特征数据
data = np.array([[1, 2], [2, 4], [3, 6]])
# 使用odict存储标准化后的数据
normalized_data = odict()
# 计算均值和标准差
mean = np.mean(data, axis=0)
std = np.std(data, axis=0)
# 标准化每个特征
for i in range(data.shape[1]):
normalized_data[i] = (data[:, i] - mean[i]) / std[i]
# 输出标准化后的数据
print(normalized_data)
```
在这个例子中,我们首先计算了数据的均值和标准差,然后使用`odict`来存储每个特征的标准值。这种方法使得标准化的过程更加清晰和易于管理。
## 5.2 模型训练和参数优化
在模型训练和参数优化阶段,`odict`可以用来存储模型的参数以及优化过程中的关键信息。
### 5.2.1 使用odict存储模型参数
模型参数是机器学习模型的核心组成部分,`odict`可以用来存储和管理这些参数。
```python
import odict
# 假设我们有一个简单的线性回归模型
class LinearRegression:
def __init__(self):
self.weights = odict()
self.bias = 0
def fit(self, X, y):
# 这里简化了参数计算过程
n_samples, n_features = X.shape
self.weights = odict([(i, 0) for i in range(n_features)])
self.bias = 0
# 创建模型实例
model = LinearRegression()
# 假设我们有一些训练数据
X = np.array([[1], [2], [3]])
y = np.array([2, 4, 6])
# 使用数据拟合模型
model.fit(X, y)
# 输出模型的权重和偏置
print('Weights:', model.weights)
print('Bias:', model.bias)
```
在这个例子中,我们定义了一个简单的线性回归模型,并使用`odict`来存储模型的权重。这种方式使得模型的参数更加结构化,便于管理和更新。
### 5.2.2 参数搜索和优化策略
参数搜索是模型训练中的一个重要步骤,它涉及到寻找最优的模型参数。`odict`可以用来存储每次迭代的参数配置和对应的性能指标,以便进行比较和选择。
```python
import numpy as np
import odict
# 假设我们有一个模型的性能评估函数
def evaluate_model(params):
# 这里简化了性能评估过程
return np.random.rand()
# 定义参数搜索空间
param_grid = {
'learning_rate': [0.01, 0.001],
'n_iterations': [100, 200]
}
# 使用odict存储每次迭代的性能指标
performance = odict()
# 遍历参数搜索空间进行模型训练和评估
for lr in param_grid['learning_rate']:
for iterations in param_grid['n_iterations']:
# 假设我们已经训练了模型并评估了性能
performance[(lr, iterations)] = evaluate_model({'learning_rate': lr, 'n_iterations': iterations})
# 输出最佳的性能指标
best_performance = max(performance.values())
print('Best performance:', best_performance)
```
在这个例子中,我们定义了一个简单的性能评估函数,并使用`odict`来存储每次迭代的参数配置和对应的性能指标。这种方式使得参数搜索的过程更加系统化和易于追踪。
## 5.3 结果分析和模型评估
模型训练完成后,我们需要对结果进行分析和评估,以确定模型的性能。
### 5.3.1 结果可视化
结果可视化是分析模型性能的重要手段,它可以帮助我们直观地理解模型的行为和趋势。`odict`可以用来存储可视化所需的原始数据和配置信息。
```python
import matplotlib.pyplot as plt
import odict
# 假设我们有一些模型评估指标
metrics = odict()
metrics['accuracy'] = [0.8, 0.85, 0.9]
metrics['loss'] = [0.2, 0.15, 0.1]
# 使用matplotlib进行可视化
fig, ax1 = plt.subplots()
color = 'tab:red'
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss', color=color)
ax1.plot(metrics['loss'], color=color)
ax1.tick_params(axis='y', labelcolor=color)
ax2 = ***inx()
color = 'tab:blue'
ax2.set_ylabel('Accuracy', color=color)
ax2.plot(metrics['accuracy'], color=color)
ax2.tick_params(axis='y', labelcolor=color)
fig.tight_layout()
plt.show()
```
在这个例子中,我们使用`matplotlib`库来可视化模型的准确率和损失。`odict`用于存储评估指标的数据,使得可视化过程更加直观和易于管理。
### 5.3.2 模型性能评估指标
模型性能评估是确定模型好坏的关键步骤。`odict`可以用来存储评估指标及其对应的值,便于进行比较和分析。
```python
import odict
# 假设我们有一些评估指标
metrics = odict()
metrics['accuracy'] = 0.85
metrics['precision'] = 0.82
metrics['recall'] = 0.80
metrics['f1_score'] = 0.83
# 输出评估指标
print('Model Performance Metrics:')
for metric, value in metrics.items():
print(f'{metric.capitalize()}: {value:.2f}')
```
在这个例子中,我们定义了一些评估指标,并使用`odict`来存储它们及其对应的值。这种方式使得模型的性能评估更加系统化和易于理解。
以上就是`odict`在机器学习中的应用。通过本章节的介绍,我们可以看到`odict`在特征工程、模型训练和参数优化、结果分析和模型评估等方面的应用,它提供了一种结构化和高效的数据管理方式,有助于提高机器学习项目的效率和性能。
# 6. odict的高级应用和性能优化
## 6.1 odict的并发编程应用
### 6.1.1 多线程和多进程环境中的使用
在多线程和多进程环境中,数据共享是一个常见且复杂的问题。由于Python的全局解释器锁(GIL),在多线程环境下进行CPU密集型任务并不会带来性能提升,但对于IO密集型任务,多线程仍然是一种有效的并发编程方式。`odict`作为一个线程安全的数据结构,可以在多线程环境中安全地共享数据。
```python
import threading
from collections import OrderedDict
from queue import Queue
def thread_task(q, key, value):
# 模拟数据处理
processed_value = value * 2
# 将处理后的数据放入队列
q.put(processed_value)
# 创建线程安全的队列
queue = Queue()
# 创建odict对象
shared_data = OrderedDict()
# 启动线程
threads = []
for i in range(5):
key = f"key{i}"
value = i
thread = threading.Thread(target=thread_task, args=(queue, key, value))
thread.start()
shared_data[key] = value
threads.append(thread)
# 等待所有线程完成
for thread in threads:
thread.join()
# 从队列中获取处理后的数据
results = []
while not queue.empty():
results.append(queue.get())
print(f"Processed values: {results}")
```
### 6.1.2 分布式计算中的数据传输
在分布式计算中,节点间的数据传输是关键。`odict`可以被序列化和反序列化,使其能够在不同的计算节点间传输。通过序列化,`odict`可以转换为JSON或其他格式,通过网络进行传输。
```python
import json
from collections import OrderedDict
# 假设这是我们需要传输的有序字典
odict_data = OrderedDict([('key1', 'value1'), ('key2', 'value2')])
# 序列化
serialized_data = json.dumps(odict_data)
# 假设这是通过网络传输后的数据
received_data = '{"key1": "value1", "key2": "value2"}'
# 反序列化
deserialized_data = json.loads(received_data)
print(f"Deserialized data: {deserialized_data}")
```
## 6.2 odict的内存和性能优化
### 6.2.1 内存优化技巧
`odict`的内存优化主要依赖于其有序性,这意味着它不会像普通字典那样在遍历时重新排序键。因此,在处理大量数据时,`odict`可以减少不必要的内存消耗。此外,使用更高效的数据类型来存储键和值也是一个常见的内存优化手段。
### 6.2.2 性能测试和调优
性能测试和调优是确保`odict`在实际应用中表现良好的关键步骤。我们可以使用Python的标准库`timeit`来测量`odict`操作的性能,并通过分析瓶颈进行优化。
```python
import timeit
# 测试添加元素的性能
setup_code = """
from collections import OrderedDict
od = OrderedDict()
test_code = """
od['new_key'] = 'new_value'
# 测试获取元素的性能
setup_code_get = """
from collections import OrderedDict
od = OrderedDict([('key1', 'value1'), ('key2', 'value2')])
test_code_get = """
value = od['key1']
# 执行性能测试
add_time = timeit.timeit(test_code, setup=setup_code, number=1000000)
get_time = timeit.timeit(test_code_get, setup=setup_code_get, number=1000000)
print(f"Time to add elements: {add_time}")
print(f"Time to get elements: {get_time}")
```
## 6.3 odict与其他Python库的整合
### 6.3.1 与Pandas、NumPy等库的协作
`odict`可以与Pandas、NumPy等库协作,进行更复杂的数据处理。例如,我们可以将Pandas的DataFrame转换为`odict`,或者将`odict`的数据用于NumPy数组的创建。
```python
import pandas as pd
import numpy as np
from collections import OrderedDict
# 创建Pandas DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 将DataFrame转换为OrderedDict
odict_data = df.to_dict(ordered=True)
# 创建NumPy数组
np_array = np.array(odict_data['A'])
print(f"NumPy array: {np_array}")
```
### 6.3.2 构建复杂数据处理管道
`odict`可以作为复杂数据处理管道中的一个组成部分,与其他Python库一起工作,提供灵活的数据处理能力。例如,我们可以使用`odict`来存储中间数据状态,或者在数据处理的不同阶段之间传递数据。
```python
from collections import OrderedDict
# 假设这是一个复杂的数据处理流程
def process_data(data):
# 第一阶段:数据清洗
cleaned_data = {k: v for k, v in data.items() if v % 2 == 0}
# 第二阶段:数据转换
transformed_data = OrderedDict((k, v**2) for k, v in cleaned_data.items())
# 第三阶段:数据分析
analysis_data = sum(transformed_data.values())
return analysis_data
# 初始数据
initial_data = OrderedDict([('A', 1), ('B', 2), ('C', 3)])
# 处理数据
final_result = process_data(initial_data)
print(f"Final result: {final_result}")
```
以上示例展示了`odict`在不同高级应用中的使用方法和性能优化策略。通过这些实践,我们可以更好地理解`odict`的特性,并将其应用于更广泛的场景中。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面深入地探讨了 Python 库文件 odict,从基本使用和特性到高级功能和技巧,再到实际项目中的应用案例。它提供了全面的问题诊断和解决指南,揭秘了 odict 内部机制的高级知识,并指导读者自定义 odict 类。此外,专栏还深入剖析了 odict 的线程安全和并发问题,探讨了序列化和反序列化的技巧和实践,以及在大型项目中的高效使用策略。专栏还重点介绍了 odict 与 JSON 数据、Pandas、机器学习、Web 开发、数据抓取、数据分析和数据可视化的交互,提供了专家级指南和最佳实践。通过深入浅出的讲解和丰富的示例,本专栏旨在帮助读者掌握 odict 的方方面面,并将其应用于各种实际场景中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【张量分解:技术革命与实践秘籍】:从入门到精通,掌握机器学习与深度学习的核心算法

# 摘要
张量分解作为数据分析和机器学习领域的一项核心技术,因其在特征提取、预测分类及数据融合等方面的优势而受到广泛关注。本文首先介绍了张量分解的基本概念与理论基础,阐述了其数学原理和优化目标,然后深入探讨了张量分解在机器学习和深度学习中的应用,包括在神经网络、循环神经网络和深度强化学习中的实践案例。进一步,文章探讨了张量分解的高级技术,如张量网络与量
【零基础到专家】:LS-DYNA材料模型定制化完全指南

# 摘要
本论文对LS-DYNA软件中的材料模型进行了全面的探讨,从基础理论到定制化方法,再到实践应用案例分析,以及最后的验证、校准和未来发展趋势。首先介绍了材料模型的理论基础和数学表述,然后阐述了如何根据应用场景选择合适的材料模型,并提供了定制化方法和实例。在实践应用章节中,分析了材料模型在车辆碰撞、高速冲击等工程问题中的应用,并探讨了如何利用材料模型进行材料选择和产品设计。最后,本论文强调了材料模型验证和校准的重要
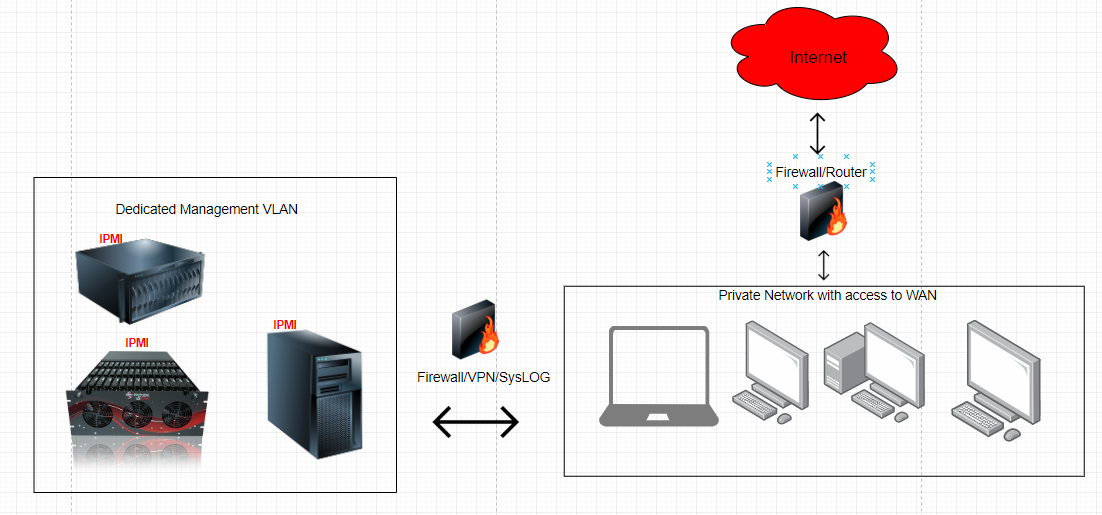
IPMI标准V2.0实践攻略:如何快速搭建和优化个人IPMI环境
# 摘要
本文系统地介绍了IPMI标准V2.0的基础知识、个人环境搭建、功能实现、优化策略以及高级应用。首先概述了IPMI标准V2.0的核心组件及其理论基础,然后详细阐述了搭建个人IPMI环境的步骤,包括硬件要求、软件工具准备、网络配置与安全设置。在实践环节,本文通过详尽的步骤指导如何进行环境搭建,并对硬件监控、远程控制等关键功能进行了验证和测试,同时提供了解决常见问题的方案。此外,本文
SV630P伺服系统在自动化应用中的秘密武器:一步精通调试、故障排除与集成优化

# 摘要
本文全面介绍了SV630P伺服系统的工作原理、调试技巧、故障排除以及集成优化策略。首先概述了伺服系统的组成和基本原理,接着详细探讨了调试前的准备、调试过程和故障诊断方法,强调了参数设置、实时监控和故障分析的重要性。文中还提供了针对常见故障的识别、分析和排除步骤,并分享了真实案例的分析。此外,文章重点讨论了在工业自动化和高精度定位应用中
从二进制到汇编语言:指令集架构的魅力
# 摘要
本文全面探讨了计算机体系结构中的二进制基础、指令集架构、汇编语言基础以及高级编程技巧。首先,介绍了指令集架构的重要性、类型和组成部分,并且对RISC和CISC架
深入解读HOLLiAS MACS-K硬件手册:专家指南解锁系统性能优化
# 摘要
本文首先对HOLLiAS MACS-K硬件系统进行了全面的概览,然后深入解析了其系统架构,重点关注了硬件设计、系统扩展性、安全性能考量。接下来,探讨了性能优化的理论基础,并详细介绍了实践中的性能调优技巧。通过案例分析,展示了系统性能优化的实际应用和效果,以及在优化过程中遇到的挑战和解决方案。最后,展望了HOLLiAS MACS-K未来的发展趋势
数字音频接口对决:I2S vs TDM技术分析与选型指南
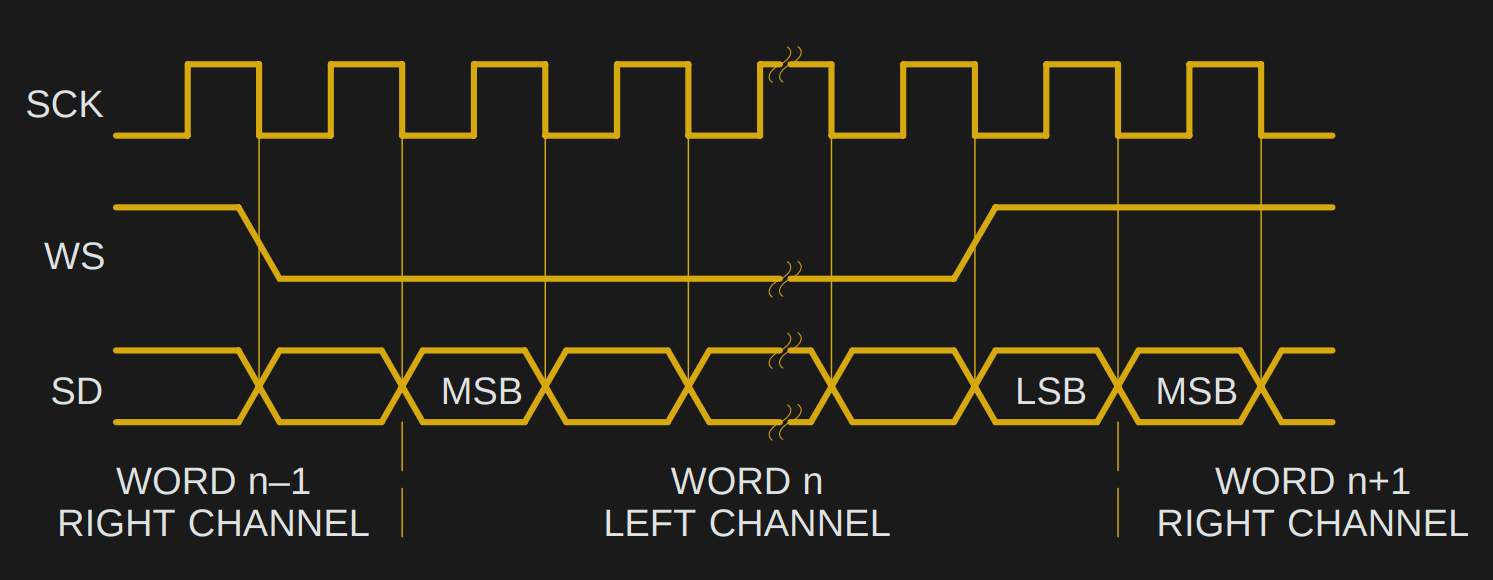
# 摘要
数字音频接口作为连接音频设备的核心技术,对于确保音频数据高质量、高效率传输至关重要。本文从基础概念出发,对I2S和TDM这两种广泛应用于数字音频系统的技术进行了深入解析,并对其工作原理、数据格式、同步机制和应用场景进行了详细探讨。通过对I2S与TDM的对比分析,本文还评估了它们在信号质量、系统复杂度、成本和应用兼容性方面的表现。文章最后提出了数字音频接口的选型指南,并展望了未来技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )