浮点运算在汇编中:x86与x64的对比分析及优化实践
发布时间: 2024-12-14 13:45:39 阅读量: 11 订阅数: 9 
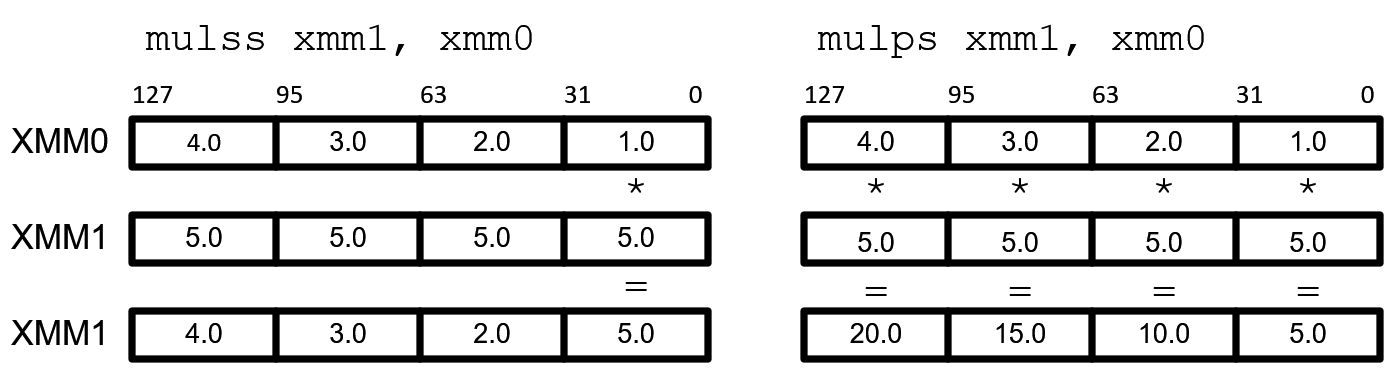
参考资源链接:[Intel x86 & x64 汇编指令集完整指南](https://wenku.csdn.net/doc/2a12ht9c0v?spm=1055.2635.3001.10343)
# 1. 汇编语言与浮点运算基础
## 1.1 汇编语言的简介与重要性
汇编语言是低级语言的一种,与机器代码极为接近,它通过助记符的方式为每一条机器指令提供一个符号名称。与高级编程语言相比,汇编语言允许开发者进行更精细的硬件控制,但也需要更深入的硬件知识和编程技巧。在需要高度优化的场合,比如操作系统内核开发、嵌入式系统、浮点密集型应用等,汇编语言仍然是不可或缺的工具。
## 1.2 浮点运算的基本概念
浮点运算涉及到的是一系列使用浮点数的算术操作,它们是计算机科学中用于近似实数的计算。浮点数由一个整数部分(尾数)和一个小数部分(基数)组成,这两个部分通过一个基数来分隔,并使用指数部分来缩放,使得数值范围和精度大幅度扩展。在计算机中,浮点运算通常通过专门的硬件单元——浮点单元(FPU)来执行,这对于需要精确计算的科学计算和工程领域至关重要。
## 1.3 汇编语言与浮点运算的关联
在汇编语言中处理浮点运算通常需要依赖于特定平台的指令集。例如,在x86架构中,FPU的指令集为开发者提供了直接操作浮点数的方法。通过汇编语言,程序员能够以极高的效率实现复杂的数值计算,并对FPU的使用进行优化。然而,由于汇编语言的复杂性,编写和调试汇编语言代码需要极其谨慎和精确,这就要求开发者不仅要有扎实的理论知识,还要有实践经验。接下来,我们将深入探讨x86架构下浮点运算的实现和优化。
# 2. x86架构下的浮点运算
在现代计算机体系结构中,x86架构以其高性能和广泛的应用而闻名。在该架构下,浮点运算的执行和优化是衡量处理器性能的关键因素之一。本章将深入探讨x86架构下的浮点运算,从基础架构到优化技术,再到实际应用案例。
## 2.1 x86架构的浮点单元介绍
x86架构的浮点单元(FPU)是专用硬件,用于执行浮点运算,它为开发者提供了一系列专用指令集。
### 2.1.1 FPU的结构和功能
FPU包括一组数据寄存器、一组状态寄存器和专用的控制寄存器,如状态寄存器(Floating-Point Status Word)和控制寄存器(Floating-Point Control Word)。数据寄存器遵循特定的堆栈结构,能够进行复杂的数学运算,例如加法、减法、乘法、除法和三角函数计算。
FPU执行的运算精度较高,其设计能够处理包括无穷大、NaN(Not a Number)、以及不同指数范围的浮点数。x86架构中,FPU的运算速度和精确度对于科学计算、财务分析、3D图形渲染等应用至关重要。
### 2.1.2 x86汇编中FPU的指令集
x86汇编语言中的FPU指令集允许开发者直接操作FPU硬件进行计算。包括但不限于以下几种指令:
- `FADD`:浮点加法
- `FSUB`:浮点减法
- `FMUL`:浮点乘法
- `FDIV`:浮点除法
- `FST`:存储FPU寄存器内容到内存
这些指令支持单精度和双精度浮点数,并且具备不同的寻址模式来处理各种数据。开发者需要精心组织代码,以确保指令的高效执行和数据的准确处理。
## 2.2 x86汇编语言中的浮点运算实现
x86汇编语言提供了强大的手段来实现复杂的浮点运算,其对浮点数的处理能力直接影响到程序的性能。
### 2.2.1 单精度和双精度浮点数的处理
在x86架构下,汇编语言中处理单精度(32位)和双精度(64位)浮点数的方法有所不同。这些浮点数按照IEEE 754标准存储在内存中,但通过FPU进行运算。单精度浮点数通常使用32位寄存器(如ST(0)到ST(7)),而双精度浮点数则使用64位寄存器。
在进行运算时,需要确保数据对齐正确,并且根据运算精度选择合适的FPU指令。对于复杂的运算,如函数计算或者数值分析,开发者往往需要编写更加复杂的算法,并利用FPU指令集优化性能。
### 2.2.2 常用的浮点运算指令和操作
x86汇编语言提供了广泛的FPU指令集,能够执行多种浮点运算。除了基本的加、减、乘、除之外,还有用于转换数据格式、计算三角函数、进行线性插值等高级操作的指令。
开发者需要根据具体应用场景选择合适的指令集。例如,如果需要计算浮点数的指数,可以使用`FLD`和`FYL2X`指令联合使用。而进行更复杂的数值计算时,则可能需要结合使用多个FPU指令,优化数据流动和计算流程。
## 2.3 x86平台的浮点运算优化
优化浮点运算是提高程序性能的一个关键方面。在x86平台上,开发者可以利用缓存优化和流水线技术提高效率。
### 2.3.1 缓存和流水线优化
现代x86处理器采用流水线技术,可以同时执行多个指令。因此,编写高效的汇编代码,需要考虑指令的并行性,避免出现流水线停顿。在进行浮点运算时,合理安排指令顺序,确保数据的快速访问,可以减少缓存未命中和流水线停顿的情况。
### 2.3.2 多线程和并发处理技巧
多线程编程可以在现代多核处理器上显著提高性能。在进行大规模浮点运算时,合理分配任务至不同线程,可以充分利用多核处理器的计算资源。在实现上,开发者需要了解线程同步机制,确保线程安全和数据一致性。
多线程还可以用于异步计算,例如,可以将一部分计算任务分派到其他线程,以避免在等待I/O操作或其他耗时任务时CPU资源的浪费。
本章详细介绍了x86架构下浮点运算的硬件基础、指令集以及优化技巧。这些内容为深入理解x86架构下的浮点运算提供了坚实的理论基础。下一章,我们将探讨x64架构下的浮点运算,包括其架构的升级和新指令集的应用。
# 3. ```
# 第三章:x64架构下的浮点运算
在处理大规模数值计算和需要高精度计算的场景中,x64架构相较于x86架构展现出其强大的浮点运算能力。本章节将深入探讨x64架构下的浮点运算特点,并分析其在实际应用中的优化策略。
## 3.1 x64架构的浮点单元升级
随着处理器技术的演进,x64架构为浮点运算提供了更多先进的指令集和优化技术。AVX指令集是其中最具代表性的技术之一,它通过更广泛的寄存器和改进的指令设计,极大地提升了浮点运算的效率。
### 3.1.1 AVX指令集对FPU的影响
高级向量扩展(AVX)指令集通过256位的寄存器和新的编码模式,增强了x64架构的浮点和向量处理能力。对比FPU指令集,AVX指令集能够支持更多的操作数和更复杂的运算,从而在相同的时间内完成更多的计算工作。
```assembly
; 示例代码展示AVX指令的使用
vmovaps ymm0, ymmword ptr [rax] ; 加载数据到AVX寄存器
vaddps ymm1, ymm0, ymmword ptr [rbx] ; 对数据进行向量加法运算
vmovaps ymmword ptr [rcx], ymm1 ; 将运算结果存储
```
在上述示例中,AVX指令集提供了对256位数据的并行处理能力。相比传统的x87 FPU指令集,AVX不仅提升数据处理的宽度,还减少了指令数量,提高了执行效率。
### 3.1.2 x64特有的浮点运算优化
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析了 Intel x86 和 x64 汇编指令集,涵盖了广泛的主题,包括:
* 指令集对比和高级技巧
* 内存管理和优化
* 系统调用和服务
* 浮点运算和优化
* 异常处理和中断管理
* 多线程编程和并发技术
* I/O 操作和端口映射
* 多媒体优化(MMX 和 SSE)
* 调试艺术和性能分析
* 宏指令的应用和性能提升策略
通过深入浅出的讲解和实战应用,本专栏旨在帮助读者全面掌握 x86 和 x64 汇编指令集,并提升其汇编编程技能。无论您是初学者还是经验丰富的程序员,本专栏都能为您提供宝贵的见解和实用技巧。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【编程更亲切】:GoLand设置中文全攻略
参考资源链接:[GoLand中文设置教程:在线与离线安装步骤](https://wenku.csdn.net/doc/645105aefcc5391368ff158e?spm=1055.2635.3001.10343)
# 1. Goland介绍与安装
## 1.1 Goland概述
GoLand是由JetBrains公司开发的专为Go语言编写的集成开发环境(IDE)。它提供了智能代码补全、代码分析
【电力系统故障模拟】:PowerWorld Simulator中电网故障与恢复的实战案例
参考资源链接:[PowerWorld Simulator中文手册:电力系统建模与分析教程](https://wenku.csdn.net/doc/6401abe7cce7214c316e9ec1?spm=1055.2635.3001.10343)
# 1. 电力系统故障模拟概述
电力系统故障模拟是电力工程领域一项重要的技术,它能够帮
【立即掌握】:12个实用技巧,精通ISO 22900-2-2017与D-PDU-API的完美融合

参考资源链接:[ISO 22900-2 D-PDU API详解:MVCI协议与车辆诊断数据传输](https://wenku.csdn.net/doc/4svgegqzsz?spm=1055.2635.3001.10343)
# 1. ISO 22900-2-2017
技术革新者速成:掌握Ambarella H22芯片的编程与功耗控制秘诀

参考资源链接:[Ambarella H22芯片规格与特性:低功耗4K视频处理与无人机应用](https://wenku.csdn.net/doc/6401abf8cce7214c316ea27b?spm=1055.2635.3001.10343)
# 1. Ambarella H22芯片概述及架构解析
## 1.1
【ADS差分滤波器原理与实践】:实现理论到实际的无缝转换
参考资源链接:[ads 差分滤波器设计及阻抗匹配](https://wenku.csdn.net/doc/6412b59abe7fbd1778d43bd8?spm=1055.2635.3001.10343)
# 1. ADS差分滤波器的基础理论
在通信系统中,差分滤波器扮演着至关重要的角色。差分滤波器能够有效地处理差分信号,保证信号在传输过程中的稳定性和抗干扰能力。本章将重点介绍ADS差分滤波器的基础理论,为后续的设计、
【CDO进阶应用】:CDO高级命令解析与实战演练

参考资源链接:[CDO气候数据操作命令详解:文件信息、合并、裁剪与插值](https://wenku.csdn.net/doc/1dcuhj0aue?spm=1055.2635.3001.10343)
# 1. CDO的基本概念和功能介绍
CDO(Climate Data Operators)是一个集合了多种命令行工具的集合,这些工具被设计用于处理气候数据。虽然它最初是为
【高性能计算中的GPGPU应用】:实战案例深度解析

参考资源链接:[GPGPU编程模型与架构解析:CUDA、OpenCL及应用](https://wenku.csdn.net/doc/5pe6wpvw55?spm=1055.2635.3001.10343)
# 1. GPGPU技术概述
## 1.1 GPGPU的定义和重要性
GPGPU,即通用计算图形处理器,是一种利用图形处理单
从LibreOffice 6到7.1.8升级全解析:技术细节与实用指南
参考资源链接:[ARM架构下libreoffice 7.1.8预编译安装包](https://wenku.csdn.net/doc/2fg8nrvwtt?spm=1055.2635.3001.10343)
# 1. LibreOffice升级概览
LibreOffice作为一款流行的开源办公套件,持续不断地进行版本迭代以提升用户体验和性能。在本章节,我们将概述LibreOffice的升级流程,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )